Training Language Agents to Learn from Experience
Pith reviewed 2026-05-21 07:07 UTC · model grok-4.3
The pith
Language agents can be trained via reinforcement learning to generate system prompts that improve their performance on future unseen tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
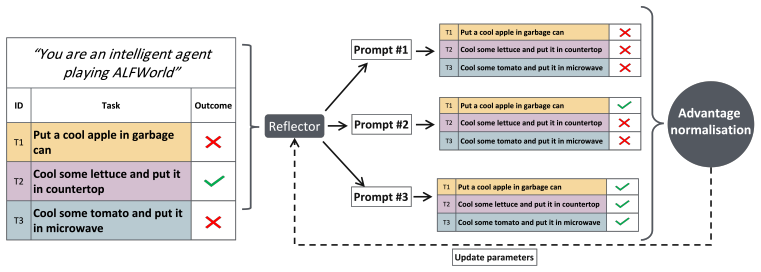
By training a reflector model with reinforcement learning on trajectories from an actor, the model learns to output system prompts that enhance the actor's success rate on held-out tasks in environments like ALFWorld and MiniHack, proving that cross-task self-improvement can be achieved through experience alone.
What carries the argument
The In-context Training (ICT) task, in which the reflector generates system prompts from actor trajectories to enable performance gains on unseen tasks.
If this is right
- Trained reflectors outperform baselines on most held-out task families in ALFWorld and MiniHack.
- Generalization to substantially different environments occurs in some cases.
- The MetaGym library supports building meta-environments for studying self-improving agents.
- The ability to learn from experience can be acquired through direct training rather than hand-crafted methods.
Where Pith is reading between the lines
- If this holds, agents could accumulate improvements over many interactions without needing new human input each time.
- This training method might extend to other interactive settings where agents must adapt across varied scenarios.
- Continuous application of the reflector could create agents that evolve their own instructions over time.
Load-bearing premise
Trajectories collected by the actor contain enough useful information for the reflector to create system prompts that work on future unseen tasks without human examples or tuning.
What would settle it
Running the trained reflector on held-out tasks and finding no improvement or worse performance compared to the untrained baseline would show that the RL training does not successfully teach cross-task learning.
Figures



read the original abstract
Language agents can adapt from experience in interactive environments, but current reflection-based methods can only self-correct within a single task instance. Whether such experience can be distilled into reusable lessons that improve performance on future unseen tasks remains unclear. We address this problem by introducing the In-context Training (ICT) task, a framework for evaluating cross-task self-improvement in language agents. In ICT, a reflector model observes trajectories collected by an actor model and generates system prompts intended to improve the actor's performance on future unseen tasks. We then propose an RL-based training pipeline for learning such reflections directly from experience, without human-provided examples. Across ALFWorld and MiniHack, our trained reflectors outperform an untrained baseline on most held-out task families, showing that the ability to learn from experience can itself be learned. In some cases, we observe generalisation beyond the benchmark on which the reflector was trained, to substantially different environments. Finally, we introduce MetaGym, a generic Python library for constructing meta-environments, enabling future research on self-improving language agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the In-context Training (ICT) framework to train language agents for cross-task self-improvement. A reflector model observes trajectories generated by an actor model and is trained via RL (without human examples) to produce system prompts that improve the actor's performance on future unseen tasks. Empirical evaluation on ALFWorld and MiniHack shows trained reflectors outperforming an untrained baseline on most held-out task families, with some observed generalization to substantially different environments. The work also releases MetaGym, a Python library for constructing meta-environments.
Significance. If the empirical claims are supported by detailed, reproducible metrics, this could meaningfully advance research on autonomous self-improving agents by demonstrating that reflection ability itself can be learned from experience rather than hand-crafted. The MetaGym library is a clear positive contribution for reproducibility and future work. However, the current presentation provides insufficient quantitative detail to evaluate whether the central claim holds.
major comments (2)
- [Abstract] Abstract: the claim that trained reflectors 'outperform an untrained baseline on most held-out task families' is presented without any numerical results, error bars, statistical tests, or description of baseline construction. This information is load-bearing for the central empirical claim and must be supplied with full tables and analysis.
- [Results / Experiments] Results / Experiments: the paper does not report actor success rates, trajectory diversity statistics, or reward-signal analysis. Without these, it is impossible to verify that the reflector extracts reusable cross-task strategies rather than task-specific failure modes or superficial correlations, directly addressing the weakest assumption in the ICT setup.
minor comments (3)
- [Method] Clarify the precise form of the RL reward used to train the reflector and how it is computed from downstream task performance.
- [Experiments] Define 'held-out task families' explicitly and state the criteria used to select them in both ALFWorld and MiniHack.
- [Discussion] Add a limitations section discussing potential failure modes when trajectories lack sufficient success signals.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the empirical presentation. We have revised the manuscript to address the concerns about quantitative detail and supporting analyses while preserving the original claims and experimental design.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that trained reflectors 'outperform an untrained baseline on most held-out task families' is presented without any numerical results, error bars, statistical tests, or description of baseline construction. This information is load-bearing for the central empirical claim and must be supplied with full tables and analysis.
Authors: We agree that the abstract should be more self-contained with respect to the key empirical results. In the revised version we have updated the abstract to report the average success-rate improvement (with standard deviation across seeds) on held-out task families for both ALFWorld and MiniHack, along with a concise description of the untrained baseline construction. The main text now contains the full per-family tables, error bars, and the results of paired statistical tests that were previously only summarized. revision: yes
-
Referee: [Results / Experiments] Results / Experiments: the paper does not report actor success rates, trajectory diversity statistics, or reward-signal analysis. Without these, it is impossible to verify that the reflector extracts reusable cross-task strategies rather than task-specific failure modes or superficial correlations, directly addressing the weakest assumption in the ICT setup.
Authors: We accept that these supporting statistics were insufficiently detailed. The revised manuscript adds a dedicated subsection that reports (i) actor success rates on both training and held-out tasks before and after reflection, (ii) quantitative trajectory diversity measures (unique state-action sequences and entropy of action distributions), and (iii) an analysis of the reward signal, including correlation between reflector prompt quality and subsequent actor episode returns. These additions allow readers to assess whether the observed gains arise from cross-task strategy transfer rather than memorization of task-specific patterns. revision: yes
Circularity Check
No significant circularity; results are empirical evaluations on external benchmarks
full rationale
The paper introduces the ICT task and an RL training pipeline for reflectors that generate system prompts from actor trajectories, then reports performance improvements on held-out task families in ALFWorld and MiniHack. These outcomes are measured via direct comparisons to untrained baselines on independent environments rather than any quantity defined by the paper's own equations or fitted parameters. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation; the central claim rests on experimental generalization rather than reducing to inputs by construction. The evaluation setup is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Observed trajectories contain sufficient signal for a language model to generate effective generalizable system prompts.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We then propose an RL-based training pipeline for learning such reflections directly from experience... reward R(spi) = average actor reward on replayed batch under new prompt
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and orbit embedding unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Performance improves consistently with additional meta-turns... continues to increase beyond turn 4
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym, 2016
work page 2016
-
[3]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[4]
System prompt optimization with meta- learning.arXiv preprint arXiv:2505.09666, 2025
Yumin Choi, Jinheon Baek, and Sung Ju Hwang. System prompt optimization with meta- learning.arXiv preprint arXiv:2505.09666, 2025
-
[5]
Improving retrospective language agents via joint policy gradient optimization
Xueyang Feng, Bo Lan, Quanyu Dai, Lei Wang, Jiakai Tang, Xu Chen, Zhenhua Dong, and Ji-Rong Wen. Improving retrospective language agents via joint policy gradient optimization. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), ...
work page 2025
-
[6]
Samule: Self-learning agents enhanced by multi-level reflection
Yubin Ge, Salvatore Romeo, Jason Cai, Monica Sunkara, and Yi Zhang. Samule: Self-learning agents enhanced by multi-level reflection. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 16602–16621, 2025
work page 2025
-
[7]
Meta-rl induces exploration in language agents
Yulun Jiang, Liangze Jiang, Damien Teney, Michael Moor, and Maria Brbic. Meta-rl induces exploration in language agents. InInternational Conference on Learning Representations, 2026
work page 2026
-
[8]
Lmact: A benchmark for in-context imitation learning with long multimodal demonstrations
Anian Ruoss, Fabio Pardo, Harris Chan, Bonnie Li, V olodymyr Mnih, and Tim Genewein. Lmact: A benchmark for in-context imitation learning with long multimodal demonstrations. arXiv preprint arXiv:2412.01441, 2024
-
[9]
Minihack the planet: A sandbox for open-ended reinforcement learning research
Mikayel Samvelyan, Robert Kirk, Vitaly Kurin, Jack Parker-Holder, Minqi Jiang, Eric Hambro, Fabio Petroni, Heinrich Kuttler, Edward Grefenstette, and Tim Rocktäschel. Minihack the planet: A sandbox for open-ended reinforcement learning research. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), 202...
work page 2021
-
[10]
Vishnu Sarukkai, Zhiqiang Xie, and Kayvon Fatahalian. Self-generated in-context examples improve llm agents for sequential decision-making tasks.arXiv preprint arXiv:2505.00234, 2025
-
[11]
Danny P Sawyer, Nan Rosemary Ke, Hubert Soyer, Martin Engelcke, David P Reichert, Drew A Hudson, John Reid, Alexander Lerchner, Danilo Jimenez Rezende, Timothy P Lillicrap, et al. Can foundation models actively gather information in interactive environments to test hypotheses?arXiv preprint arXiv:2412.06438, 2024
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
work page 2023
-
[15]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning Text and Embodied Environments for Interactive Learning. InProceedings of the International Conference on Learning Representations (ICLR),
-
[16]
URLhttps://arxiv.org/abs/2010.03768. 10
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[17]
Welcome to the era of experience.Google AI, 1, 2025
David Silver and Richard S Sutton. Welcome to the era of experience.Google AI, 1, 2025
work page 2025
-
[18]
Cognitive architec- tures for language agents.Transactions on Machine Learning Research, 2023
Theodore Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas Griffiths. Cognitive architec- tures for language agents.Transactions on Machine Learning Research, 2023
work page 2023
-
[19]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
work page 2024
-
[20]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Large language models as optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[22]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[23]
Weiran Yao, Shelby Heinecke, Juan Carlos Niebles, Zhiwei Liu, Yihao Feng, Le Xue, Rithesh Murthy, Zeyuan Chen, Jianguo Zhang, Devansh Arpit, et al. Retroformer: Retrospective large language agents with policy gradient optimization.arXiv preprint arXiv:2308.02151, 2023
-
[24]
Assessing adaptive world models in machines with novel games.arXiv preprint arXiv:2507.12821, 2025
Lance Ying, Katherine M Collins, Prafull Sharma, Cedric Colas, Kaiya Ivy Zhao, Adrian Weller, Zenna Tavares, Phillip Isola, Samuel J Gershman, Jacob D Andreas, et al. Assessing adaptive world models in machines with novel games.arXiv preprint arXiv:2507.12821, 2025
-
[25]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, 2024. 11 A Reflector Prompt The reflector prompt is shared across both environments. The reflector receives the following system prompt: Reflector system prompt You ...
work page 2024
-
[26]
Identify what went well and what went wrong in the agent’s behaviour
-
[27]
Diagnose how the current system prompt contributed to those outcomes
-
[28]
Write an improved system prompt that addresses the identified weaknesses to improve the agent’s performance in future episodes. Respond in EXACTLY this format –- no additional text outside these two sections: ANALYSIS: [Describe what succeeded, what failed, how the system prompt contributed to those outcomes, and what specific changes the improved prompt ...
work page 2048
-
[31]
Observe the result and repeat Format your responses EXACTLY as follows: Thought: [your reasoning about the current situation and what to do] Action: [exact action from the available actions list] Each turn, the actor receives the following user message, appended to the conversation history of all previous steps in the episode: ALFWorld actor user prompt t...
-
[32]
THINK about what you observe and what you should do next
-
[33]
Take an ACTION from the available actions
-
[34]
<" symbol. I will move east to investigate further. Action 2: step e Observation 2:
Observe the result and repeat Format your responses EXACTLY as follows: Thought: [your reasoning about the current situation and what to do] Action: [exact action from the available actions list] Each turn, the actor receives the following user message, appended to the conversation history of all previous steps in the episode: MiniHack actor user prompt t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.