Dynamic TMoE: A Drift-Aware Dynamic Mixture of Experts Framework for Non-Stationary Time Series Forecasting
Pith reviewed 2026-05-21 05:57 UTC · model grok-4.3
The pith
Dynamic TMoE evolves Mixture of Experts by detecting shifts and adding or pruning experts while using memory for stable routing in non-stationary time series forecasting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
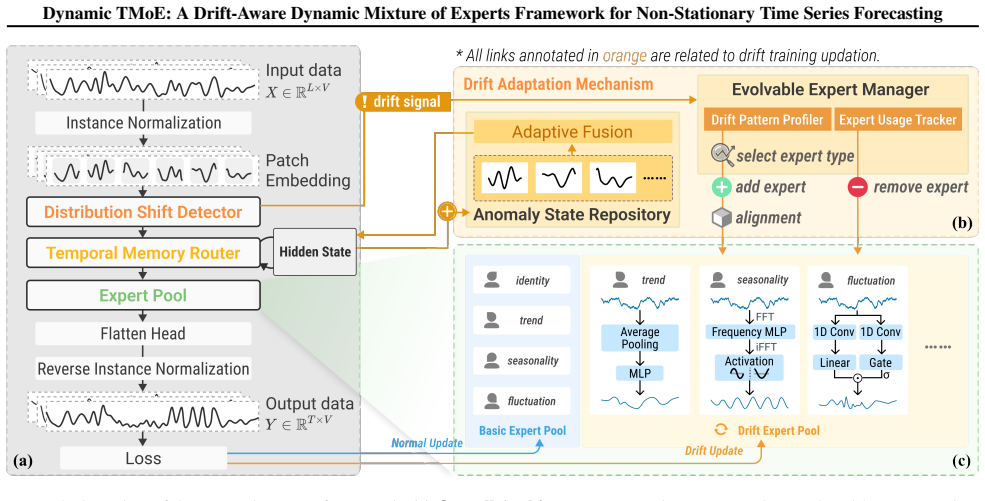
Dynamic TMoE unifies architectural evolution with temporal continuity during the learning phase. By detecting distribution shifts via Maximum Mean Discrepancy, the framework dynamically instantiates heterogeneous experts and prunes redundant ones to optimize capacity. A temporal memory router leverages recurrent states and an anomaly repository to ensure stable, context-aware expert selection without requiring test-time updates.
What carries the argument
Dynamic expert pool evolution guided by MMD shift detection together with a temporal memory router that maintains recurrent states and an anomaly repository for context-aware selection.
If this is right
- Forecasting models can adjust their effective capacity on the fly as new regimes appear without restarting training from scratch.
- Routing decisions remain consistent across time steps because the router draws on stored history rather than current input alone.
- Redundant experts can be removed during training, keeping computational cost from growing unbounded as the series evolves.
- The same learned experts continue to be used at inference without any further architectural changes or retraining.
Where Pith is reading between the lines
- The same shift-detection and dynamic-pool logic could transfer to other online learning settings where data distributions drift, such as adaptive control or continual classification.
- Replacing MMD with alternative drift detectors might improve sensitivity on particular data types like high-frequency financial series.
- The anomaly repository could be extended to support explicit rare-event handling in addition to gradual or abrupt shifts.
Load-bearing premise
The approach assumes that Maximum Mean Discrepancy will correctly identify meaningful regime shifts in the time series without excessive false detections or misses, and that the resulting additions and removals of experts during training will remain stable enough to produce the reported accuracy gains.
What would settle it
Train the model on a synthetic time series whose exact change points are known in advance; if the detected shifts and expert additions do not align with those points or if prediction error fails to drop below that of a static expert pool of equal total size, the central claim would be falsified.
Figures



read the original abstract
Non-stationary time series forecasting is challenged by evolving distribution shifts that static models struggle to capture. While Mixture-of-Experts (MoE) architectures offer a promising paradigm for decoupling complex drift patterns, existing approaches are limited by fixed expert pools and memoryless routing, hampering their ability to adapt to abrupt regime shifts. To address this, we propose Dynamic TMoE, a framework that unifies architectural evolution with temporal continuity during learning phase. By detecting distribution shifts via Maximum Mean Discrepancy (MMD), we dynamically instantiate heterogeneous experts and prune redundant ones to optimize capacity. Additionally, a temporal memory router leverages recurrent states and an anomaly repository to ensure stable, context-aware expert selection without requiring test-time updates. Experiments on nine benchmarks demonstrate state-of-the-art performance, reducing MSE by 10.4% and MAE by 7.8%. Code is available at https://github.com/andone-07/Dynamic-TMoE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dynamic TMoE, a drift-aware dynamic Mixture-of-Experts framework for non-stationary time series forecasting. It detects distribution shifts using Maximum Mean Discrepancy (MMD) to dynamically instantiate heterogeneous experts and prune redundant ones during training, while employing a temporal memory router that leverages recurrent states and an anomaly repository for stable, context-aware expert selection without test-time updates. The central empirical claim is that this unification yields state-of-the-art results on nine benchmarks, with average reductions of 10.4% in MSE and 7.8% in MAE relative to baselines.
Significance. If the reported gains can be robustly attributed to the MMD-driven architectural evolution rather than the temporal router or capacity changes alone, the work would advance adaptive MoE designs for handling regime shifts in time series. The public code release is a positive factor for reproducibility. The significance is currently limited by the absence of component-isolating experiments needed to support the attribution in the central claim.
major comments (2)
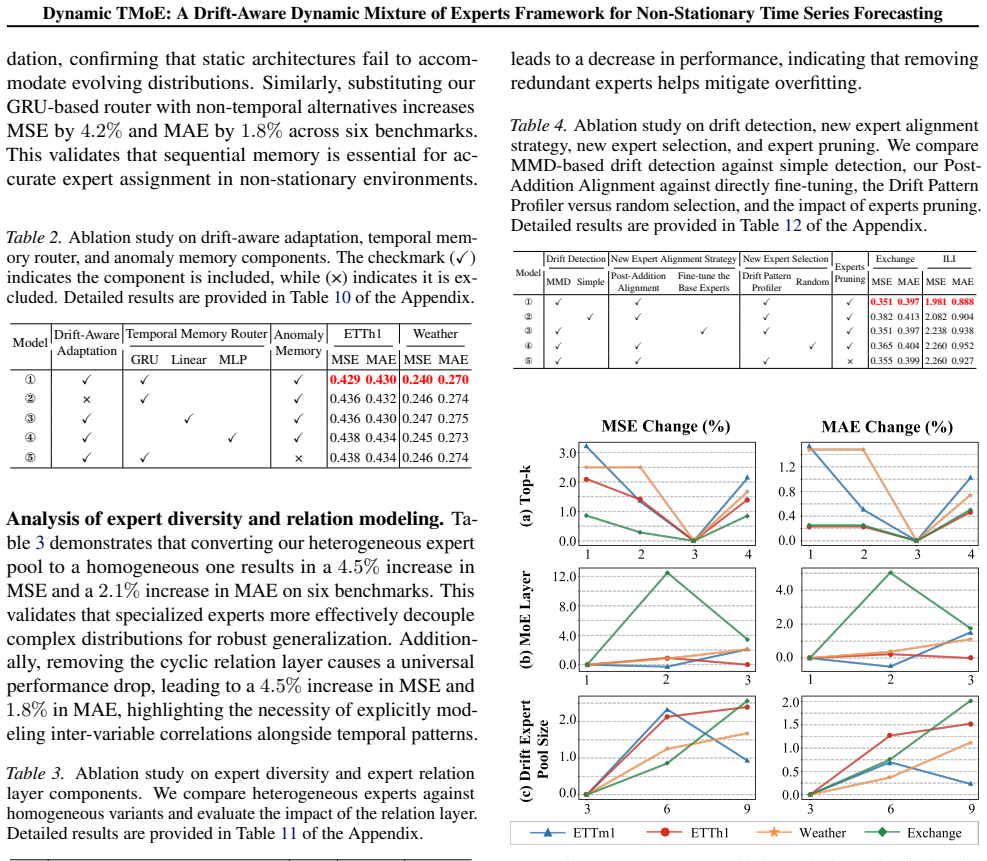
- [Experimental results] Experimental results section: The manuscript reports 10.4% MSE and 7.8% MAE reductions but provides no ablation that disables only the MMD-triggered expert addition and pruning steps while retaining the temporal memory router and anomaly repository. This ablation is load-bearing for the central claim that the unification of architectural evolution with the router produces the observed gains; without it, the performance delta could arise from the router alone or from incidental increases in model capacity.
- [Method] Method section on shift detection: The MMD shift detection threshold is listed as a free hyperparameter. The paper should quantify how sensitive the dynamic expert pool changes and final performance are to this threshold, including the frequency of expert additions/prunings and any resulting training instability, because unreliable or overly frequent architectural changes would undermine the claimed stability of the temporal memory router.
minor comments (2)
- [Abstract] The abstract and experimental section should explicitly list the nine benchmark datasets and the exact baselines used for the reported percentage reductions to allow direct comparison.
- [Method] Notation for the recurrent state in the temporal memory router and the anomaly repository should be defined more clearly with equations or pseudocode to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and describe the revisions we will incorporate to strengthen the work.
read point-by-point responses
-
Referee: [Experimental results] Experimental results section: The manuscript reports 10.4% MSE and 7.8% MAE reductions but provides no ablation that disables only the MMD-triggered expert addition and pruning steps while retaining the temporal memory router and anomaly repository. This ablation is load-bearing for the central claim that the unification of architectural evolution with the router produces the observed gains; without it, the performance delta could arise from the router alone or from incidental increases in model capacity.
Authors: We agree that this ablation is necessary to robustly attribute the reported gains to the MMD-driven architectural evolution rather than the router or capacity changes alone. We will conduct the suggested ablation by training a variant that retains the temporal memory router and anomaly repository but disables the MMD-triggered expert addition and pruning. The results will be added to the Experimental Results section of the revised manuscript. revision: yes
-
Referee: [Method] Method section on shift detection: The MMD shift detection threshold is listed as a free hyperparameter. The paper should quantify how sensitive the dynamic expert pool changes and final performance are to this threshold, including the frequency of expert additions/prunings and any resulting training instability, because unreliable or overly frequent architectural changes would undermine the claimed stability of the temporal memory router.
Authors: We acknowledge the value of a sensitivity analysis for the MMD threshold. We will add experiments that vary the threshold, reporting its effects on the frequency of expert additions and prunings, changes to the expert pool, final performance, and any observed training instability. These results will be included in the revised Method and Experimental Results sections. revision: yes
Circularity Check
No significant circularity; empirical results independent of inputs
full rationale
The paper introduces Dynamic TMoE as a new framework combining MMD-based drift detection with dynamic expert instantiation/pruning and a temporal memory router. Reported MSE/MAE gains are presented as outcomes of experiments on nine benchmarks rather than quantities obtained by fitting parameters to the target metrics or by self-referential definitions in equations. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes that reduce the central claims to their own inputs appear in the abstract or described method. The derivation chain consists of architectural choices and empirical validation that remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- MMD shift detection threshold
axioms (1)
- domain assumption MMD can be computed reliably on sliding windows of time series to detect distribution shifts
invented entities (1)
-
Temporal memory router
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By detecting distribution shifts via Maximum Mean Discrepancy (MMD), we dynamically instantiate heterogeneous experts and prune redundant ones... temporal memory router leverages recurrent states and an anomaly repository
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Heterogeneous Expert Designs. Trend Expert extracts global trends via average pooling. Seasonality Expert captures periodic signals in the frequency domain. Fluctuation Expert models local volatility using causal convolutions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[3]
0 Gr oundT rut h Pr ediction (a) Dynamic TMoE (b) TFPS (c) RAFT (d) ST -MTM (e) T imeMixer (f) FITS (g) PatchTST (h) T imesNet (i) Dlinear 0 25 50 7 5 100 125 150 17 5 200 1 . 0 0 . 5 0 . 0 0 . 5 1 . 0 1 . 5
-
[8]
0 Gr oundT rut h Pr ediction 0 25 50 7 5 100 125 150 17 5 200 1 . 0 0 . 5 0 . 0 0 . 5 1 . 0 1 . 5
-
[9]
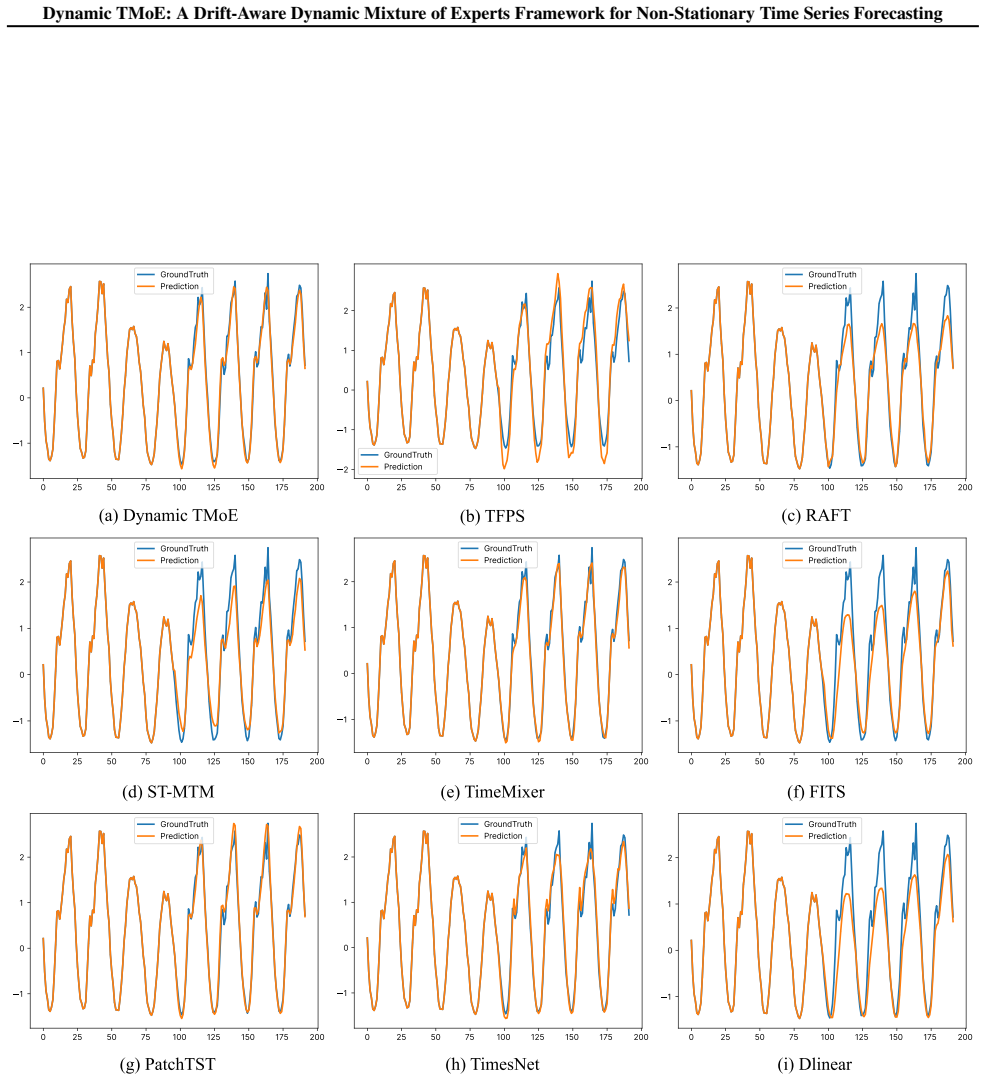
The blue lines represent the ground truth, while the orange lines indicate the model predictions
0 Gr oundT rut h Pr ediction Figure 5.Visualization of forecasting results on the Electricity dataset with an input-96-predict-96 setting. The blue lines represent the ground truth, while the orange lines indicate the model predictions. 20 Dynamic TMoE: A Drift-Aware Dynamic Mixture of Experts Framework for Non-Stationary Time Series Forecasting (a) Dynam...
-
[12]
5 Gr oundT rut h Pr ediction 0 10 20 30 40 50 60 0 . 0 0 . 5 1 . 0 1 . 5
-
[17]
5 Gr oundT rut h Pr ediction 0 10 20 30 40 50 60 0 . 5 1 . 0 1 . 5
-
[18]
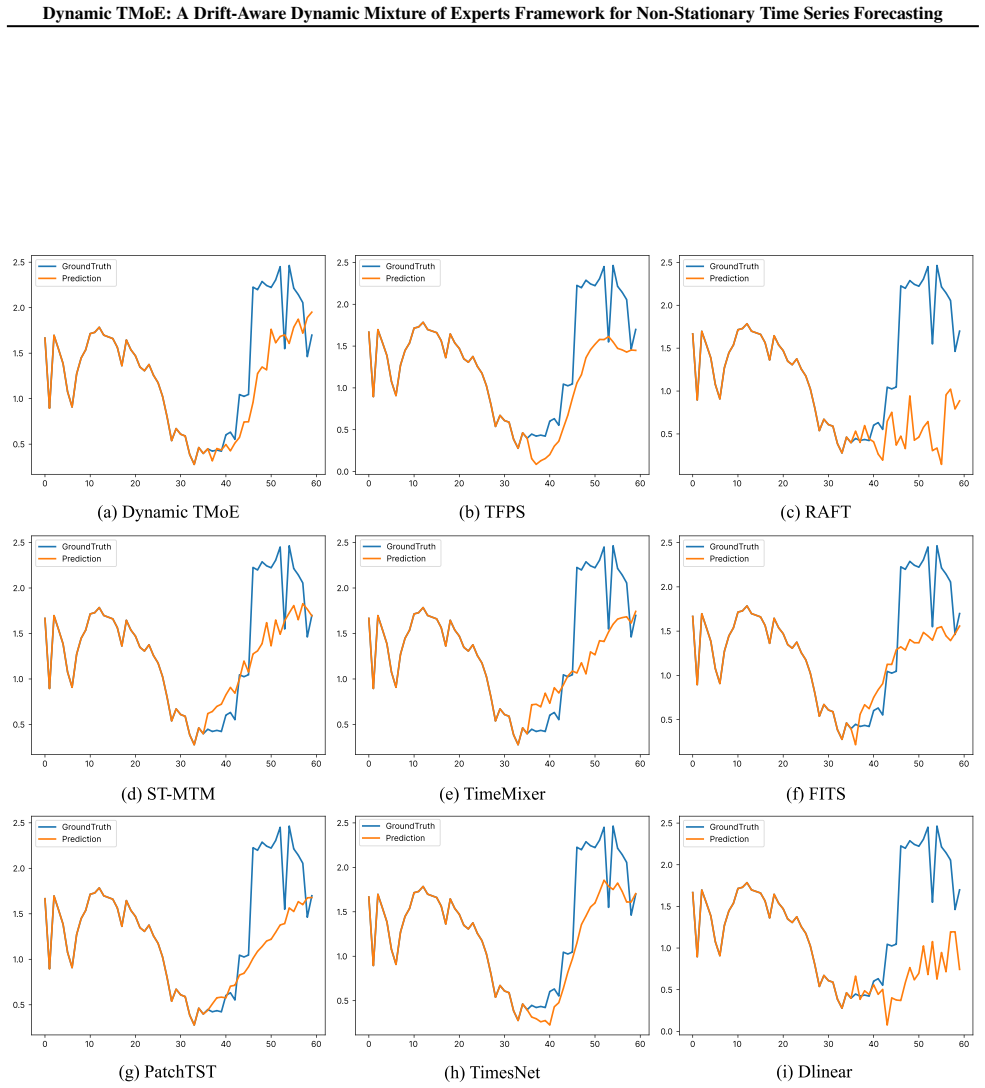
The blue lines represent the ground truth, while the orange lines indicate the model predictions
5 Gr oundT rut h Pr ediction Figure 7.Visualization of forecasting results on the ILI dataset with an input-36-predict-24 setting. The blue lines represent the ground truth, while the orange lines indicate the model predictions. 22 Dynamic TMoE: A Drift-Aware Dynamic Mixture of Experts Framework for Non-Stationary Time Series Forecasting Table 7.Detailed ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.