Empowering VLMs for Few-Shot Multimodal Time Series Classification via Tailored Agentic Reasoning
Pith reviewed 2026-05-20 22:43 UTC · model grok-4.3
The pith
MarsTSC uses three agent roles to refine a knowledge bank and boost few-shot time series classification in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
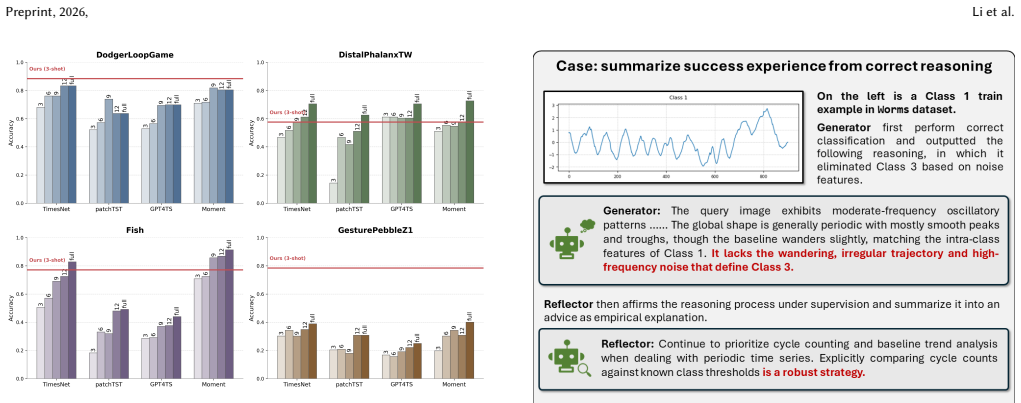
MarsTSC delivers substantial and consistent performance gains across 6 VLM backbones, outperforming both classical and foundation model-based time series baselines under few-shot conditions, while producing interpretable rationales that ground each classification decision in human-readable feature evidence.
What carries the argument
The self-evolving knowledge bank iteratively refined via reflective agentic reasoning with generator, reflector, and modifier agents.
If this is right
- Outperforms baselines on 12 mainstream time series benchmarks in few-shot settings
- Works across 6 different VLM backbones with consistent improvements
- Generates human-readable rationales explaining classifications based on temporal features
- Uses test-time updates to reduce few-shot bias and distribution shift effects
Where Pith is reading between the lines
- The approach might generalize to other data modalities or tasks requiring few-shot adaptation.
- Interpretable rationales could support applications where decision transparency is required.
- Continuous knowledge bank updates may enable better handling of evolving data streams in practice.
Load-bearing premise
The reflector agent can reliably diagnose reasoning errors and produce insights that target specific temporal features the generator missed, so the modifier can make useful updates.
What would settle it
Running the system without the reflector and modifier agents and observing whether performance and interpretability still improve would test if the full agentic loop is necessary.
Figures









read the original abstract
In this paper, we propose the first VL$\underline{\textbf{M}}$ $\underline{\textbf{a}}$gentic $\underline{\textbf{r}}$easoning framework for few-$\underline{\textbf{s}}$hot multimodal $\underline{\textbf{T}}$ime $\underline{\textbf{S}}$eries $\underline{\textbf{C}}$lassification ($\textbf{MarsTSC}$), which introduces a self-evolving knowledge bank as a dynamic context iteratively refined via reflective agentic reasoning. The framework comprises three collaborative roles: i) Generator conducts reliable classification via reasoning; ii) Reflector diagnoses the root causes of reasoning errors to yield discriminative insights targeting the temporal features overlooked by Generator; iii) Modifier applies verified updates to the knowledge bank to prevent context collapse. We further introduce a test-time update strategy to enable cautious, continuous knowledge bank refinement to mitigate few-shot bias and distribution shift. Extensive experiments across 12 mainstream time series benchmarks demonstrate that $\textbf{MarsTSC}$ delivers substantial and consistent performance gains across 6 VLM backbones, outperforming both classical and foundation model-based time series baselines under few-shot conditions, while producing interpretable rationales that ground each classification decision in human-readable feature evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MarsTSC, the first VLM agentic reasoning framework for few-shot multimodal time series classification. It introduces a self-evolving knowledge bank refined iteratively through reflective agentic reasoning involving three roles: Generator for classification, Reflector for diagnosing reasoning errors and providing insights on overlooked temporal features, and Modifier for updating the knowledge bank. A test-time update strategy is also presented to handle few-shot bias and distribution shift. The authors report substantial and consistent performance gains across 12 time series benchmarks and 6 VLM backbones, outperforming classical and foundation model baselines, along with interpretable rationales.
Significance. If the empirical results hold and the agentic components are shown to be responsible for the gains, this could represent a meaningful advance in applying VLMs to time series tasks by improving few-shot performance and providing human-readable explanations. The tailored agent roles and self-evolving knowledge bank address important limitations in standard prompting approaches for temporal data.
major comments (2)
- The central claim attributes substantial gains to the three-role agentic loop in which the Reflector diagnoses root causes of generator errors and yields insights specifically targeting overlooked temporal features (trends, periodicity, phase). For this to explain the reported outperformance over classical and foundation-model baselines under few-shot conditions, the Reflector must produce actionable, time-series-specific corrections. The framework description provides no quantitative metric (e.g., reflector diagnostic accuracy against human labels on misclassified samples) or ablation that isolates the reflector-modifier pair from generic chain-of-thought or self-refinement prompting.
- Experiments section: While performance gains are asserted on 12 benchmarks across 6 VLM backbones, the manuscript lacks targeted ablations for the Reflector and Modifier components. Without these, it is impossible to confirm that gains exceed what would be obtained from standard VLM prompting or self-refinement alone, weakening the attribution to the proposed agentic reasoning.
minor comments (2)
- Abstract: Consider adding one or two concrete accuracy numbers or relative improvements to give readers an immediate sense of effect size.
- Notation: Ensure consistent expansion of acronyms such as VLM on first use in each major section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the empirical validation of the agentic components. We address each major comment below and will revise the manuscript accordingly to better isolate the contributions of the proposed framework.
read point-by-point responses
-
Referee: The central claim attributes substantial gains to the three-role agentic loop in which the Reflector diagnoses root causes of generator errors and yields insights specifically targeting overlooked temporal features (trends, periodicity, phase). For this to explain the reported outperformance over classical and foundation-model baselines under few-shot conditions, the Reflector must produce actionable, time-series-specific corrections. The framework description provides no quantitative metric (e.g., reflector diagnostic accuracy against human labels on misclassified samples) or ablation that isolates the reflector-modifier pair from generic chain-of-thought or self-refinement prompting.
Authors: We agree that a dedicated quantitative evaluation of the Reflector's diagnostic quality would strengthen the central claim. The current manuscript provides qualitative case studies in the appendix illustrating how the Reflector identifies overlooked temporal features such as phase shifts and periodicity that the Generator misses, leading to knowledge bank updates. However, we did not include a human-labeled accuracy metric for these diagnoses. We will add an ablation in the revised version that replaces the Reflector-Modifier pair with generic chain-of-thought self-refinement (without the tailored temporal-feature focus) and report the resulting performance drop on the same 12 benchmarks. This will help attribute gains specifically to the proposed roles rather than generic refinement. revision: yes
-
Referee: Experiments section: While performance gains are asserted on 12 benchmarks across 6 VLM backbones, the manuscript lacks targeted ablations for the Reflector and Modifier components. Without these, it is impossible to confirm that gains exceed what would be obtained from standard VLM prompting or self-refinement alone, weakening the attribution to the proposed agentic reasoning.
Authors: We acknowledge the absence of component-specific ablations in the submitted manuscript. The reported results compare MarsTSC against classical time-series methods and foundation-model baselines under identical few-shot settings, but do not directly ablate the Reflector or Modifier in isolation. In the revision we will insert a new subsection with targeted ablations: (1) MarsTSC without Reflector (using only Generator + standard prompting), (2) MarsTSC without Modifier (updates applied without verification), and (3) a generic self-refinement baseline. These will be run across the same 6 VLM backbones and 12 datasets to quantify the incremental benefit of the tailored agentic loop. revision: yes
Circularity Check
No significant circularity; framework is independently specified
full rationale
The paper defines MarsTSC as a novel three-role agentic framework (Generator for classification, Reflector for diagnosing temporal oversights, Modifier for knowledge-bank updates) plus a test-time refinement strategy. These components are introduced via explicit role descriptions and update rules rather than any equations, fitted parameters, or self-referential definitions. Performance claims rest on external benchmark experiments across 12 datasets and 6 VLMs, not on reductions to the framework's own inputs. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the derivation chain that would collapse the central claims back to prior author work or internal fits. The overall structure remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models possess sufficient reasoning ability to perform reliable classification on multimodal time series when guided by structured agent roles.
invented entities (2)
-
self-evolving knowledge bank
no independent evidence
-
Reflector agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Harika Abburi, Tanya Chaudhary, Haider Ilyas, Lakshmi Manne, Deepak Mit- tal, Don Williams, Derek Snaidauf, Edward Bowen, and Balaji Veeramani
-
[2]
arXiv preprint arXiv:2309.17001 (2023)
A closer look at bearing fault classification approaches. arXiv preprint arXiv:2309.17001 (2023)
- [3]
-
[4]
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebas- tian Pineda Arango, Shubham Kapoor, et al. 2024. Chronos: Learning the language of time series. arXiv preprint arXiv:2403.07815 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Anthony Bagnall, Hoang Anh Dau, Jason Lines, Michael Flynn, James Large, Aaron Bostrom, Paul Southam, and Eamonn Keogh. 2018. The UEA multivariate time series classification archive, 2018. arXiv preprint arXiv:1811.00075 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [6]
-
[7]
Leo Breiman. 2001. Random forests. Machine learning 45, 1 (2001), 5–32
work page 2001
- [8]
-
[9]
Ngai Hang Chan. 2004. Time series: applications to finance. John Wiley & Sons
work page 2004
-
[10]
Ching Chang, Wei-Yao Wang, Wen-Chih Peng, and Tien-Fu Chen. 2025. Llm4ts: Aligning pre-trained llms as data-efficient time-series forecasters. ACM Transactions on Intelligent Systems and Technology 16, 3 (2025), 1–20
work page 2025
-
[11]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al . 2024. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 24185–24198
work page 2024
-
[12]
Corinna Cortes and Vladimir Vapnik. 1995. Support-vector networks. Machine learning 20, 3 (1995), 273–297
work page 1995
-
[13]
Thomas Cover and Peter Hart. 1967. Nearest neighbor pattern classification. IEEE transactions on information theory 13, 1 (1967), 21–27
work page 1967
- [14]
-
[15]
Hoang Anh Dau, Anthony Bagnall, Kaveh Kamgar, Chin-Chia Michael Yeh, Yan Zhu, Shaghayegh Gharghabi, Chotirat Ann Ratanamahatana, and Eamonn Keogh
-
[16]
IEEE/CAA Journal of Automatica Sinica 6, 6 (2019), 1293–1305
The UCR time series archive. IEEE/CAA Journal of Automatica Sinica 6, 6 (2019), 1293–1305
work page 2019
-
[17]
Shengdong Du, Tianrui Li, Yan Yang, and Shi-Jinn Horng. 2019. Deep air qual- ity forecasting using hybrid deep learning framework. IEEE Transactions on Knowledge and Data Engineering 33, 6 (2019), 2412–2424
work page 2019
-
[18]
Mojtaba A Farahani, MR McCormick, Ramy Harik, and Thorsten Wuest. 2025. Time-series classification in smart manufacturing systems: An experimen- tal evaluation of state-of-the-art machine learning algorithms. Robotics and Computer-Integrated Manufacturing 91 (2025), 102839
work page 2025
-
[19]
Google DeepMind. 2026. Gemini 3.1 Pro Model Card. https://deepmind.google/ models/model-cards/gemini-3-1-pro/
work page 2026
-
[20]
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. 2024. MOMENT: A Family of Open Time-series Foundation Models. In International Conference on Machine Learning. PMLR, 16115–16152
work page 2024
-
[21]
Xinyu Huang, Jun Tang, and Yongming Shen. 2024. Long time series of ocean wave prediction based on PatchTST model. Ocean Engineering 301 (2024), 117572
work page 2024
-
[22]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM computing surveys 55, 12 (2023), 1–38
work page 2023
-
[23]
Yushan Jiang, Kanghui Ning, Zijie Pan, Xuyang Shen, Jingchao Ni, Wenchao Yu, Anderson Schneider, Haifeng Chen, Yuriy Nevmyvaka, and Dongjin Song. 2025. Multi-modal time series analysis: A tutorial and survey. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 6043–6053
work page 2025
- [24]
- [25]
-
[26]
Peiwen Li, Xin Wang, Zeyang Zhang, Yuan Meng, Fang Shen, Yue Li, Jialong Wang, Yang Li, and Wenwu Zhu. 2024. Realtcd: Temporal causal discovery from interventional data with large language model. In Proceedings of the 33rd ACM international conference on information and knowledge management. 4669– 4677
work page 2024
-
[27]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning. Advances in neural information processing systems 36 (2023), 34892–34916
work page 2023
- [28]
-
[29]
Matthew Middlehurst, James Large, Michael Flynn, Jason Lines, Aaron Bostrom, and Anthony Bagnall. 2021. HIVE-COTE 2.0: a new meta ensemble for time series classification. Machine Learning 110, 11 (2021), 3211–3243
work page 2021
-
[30]
Mukaffi Bin Moin, Fatema Tuj Johora Faria, Swarnajit Saha, Busra Kamal Rafa, and Mohammad Shafiul Alam. 2024. Exploring explainable ai techniques for improved interpretability in lung and colon cancer classification. InInternational Conference on Computing and Communication Networks. Springer, 1–11
work page 2024
-
[31]
Moonshot AI. 2026. Kimi K2.5 Quickstart. https://platform.kimi.ai/docs/guide/ kimi-k2-5-quickstart
work page 2026
-
[32]
Mohammad Amin Morid, Olivia R Liu Sheng, and Joseph Dunbar. 2023. Time series prediction using deep learning methods in healthcare. ACM Transactions on Management Information Systems 14, 1 (2023), 1–29
work page 2023
- [33]
- [34]
-
[35]
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. 2022. A time series is worth 64 words: Long-term forecasting with transformers. arXiv preprint arXiv:2211.14730 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
OpenAI. 2026. GPT-5 Model. https://developers.openai.com/api/docs/models/ gpt-5
work page 2026
-
[37]
OpenAI. 2026. GPT-5.4 mini Model. https://developers.openai.com/api/docs/ models/gpt-5.4-mini
work page 2026
- [38]
-
[39]
J. Ross Quinlan. 1986. Induction of decision trees. Machine learning 1, 1 (1986), 81–106
work page 1986
-
[40]
Qwen Team. 2026.Qwen3.5-397B-A17B. https://huggingface.co/Qwen/Qwen3.5- 397B-A17B
work page 2026
-
[41]
Lisa Schmors, Dominic Gonschorek, Jan Niklas Böhm, Yongrong Qiu, Na Zhou, Dmitry Kobak, Andreas Tolias, Fabian Sinz, Jacob Reimer, Katrin Franke, et al
-
[42]
arXiv preprint arXiv:2506.04906 (2025)
TRACE: Contrastive learning for multi-trial time-series data in neuroscience. arXiv preprint arXiv:2506.04906 (2025)
work page internal anchor Pith review arXiv 2025
- [43]
-
[44]
Chang Wei Tan, Angus Dempster, Christoph Bergmeir, and Geoffrey I Webb
-
[45]
Data Mining and Knowledge Discovery 36, 5 (2022), 1623–1646
MultiRocket: multiple pooling operators and transformations for fast and effective time series classification: CW Tan. Data Mining and Knowledge Discovery 36, 5 (2022), 1623–1646
work page 2022
-
[46]
Mingtian Tan, Mike Merrill, Vinayak Gupta, Tim Althoff, and Tom Hartvigsen
-
[47]
Are language models actually useful for time series forecasting? Advances in Neural Information Processing Systems 37 (2024), 60162–60191
work page 2024
-
[48]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017)
work page 2017
-
[49]
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al . 2016. Matching networks for one shot learning. Advances in neural information processing systems 29 (2016)
work page 2016
-
[50]
Jiahao Wang, Mingyue Cheng, Qingyang Mao, Yitong Zhou, Daoyu Wang, Qi Liu, Feiyang Xu, and Xin Li. 2025. Tabletime: Reformulating time series classification as training-free table understanding with large language models. In Proceedings of the 34th ACM International Conference on Information and Knowledge Management. 3009–3019
work page 2025
-
[51]
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. [n. d.]. TimesNet: Temporal 2D-Variation Modeling for General Time Series Anal- ysis. In The Eleventh International Conference on Learning Representations
-
[52]
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. 2021. Autoformer: De- composition transformers with auto-correlation for long-term series forecasting. Advances in neural information processing systems 34 (2021), 22419–22430
work page 2021
-
[53]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
-
[54]
A-MEM: Agentic Memory for LLM Agents
A-mem: Agentic memory for llm agents. arXiv preprint arXiv:2502.12110 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical 10 Empowering VLMs for Few-Shot Multimodal Time Series Classification via Tailored Agentic Reasoning Preprint, 2026, report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [56]
-
[57]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations
work page 2022
-
[58]
Wojciech Zaremba, Ilya Sutskever, and Oriol Vinyals. 2014. Recurrent neural network regularization. arXiv preprint arXiv:1409.2329 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[59]
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, et al
-
[60]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Agentic context engineering: Evolving contexts for self-improving language models. arXiv preprint arXiv:2510.04618 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [61]
- [62]
-
[63]
Siru Zhong, Weilin Ruan, Ming Jin, Huan Li, Qingsong Wen, and Yuxuan Liang
-
[64]
arXiv preprint arXiv:2502.04395 (2025)
Time-vlm: Exploring multimodal vision-language models for augmented time series forecasting. arXiv preprint arXiv:2502.04395 (2025)
-
[65]
Shu Zhou, Yunyang Xuan, Yuxuan Ao, Xin Wang, Tao Fan, and Hao Wang. 2025. MERIT: Multi-Agent Collaboration for Unsupervised Time Series Representation Learning. In Findings of the Association for Computational Linguistics: ACL
work page 2025
-
[66]
Tian Zhou, Peisong Niu, Liang Sun, Rong Jin, et al . 2023. One fits all: Power general time series analysis by pretrained lm. Advances in neural information processing systems 36 (2023), 43322–43355
work page 2023
- [67]
-
[68]
Yufan Zhuang, Chandan Singh, Liyuan Liu, Yelong Shen, Dinghuai Zhang, Jingbo Shang, Jianfeng Gao, and Weizhu Chen. 2026. Test-time Recursive Thinking: Self-Improvement without External Feedback. arXiv preprint arXiv:2602.03094 (2026). 11 Preprint, 2026, Li et al. A Appendix Overview This appendix is organized as follows. We first describe additional imple...
-
[69]
- section: the section to add the new bullet to
ADD: Create new bullet points with fresh IDs. - section: the section to add the new bullet to. - content: the new content of the bullet
-
[70]
- target_id: the exact ID of the bullet to modify
MODIFY: Update an existing bullet point. - target_id: the exact ID of the bullet to modify. - content: the fully updated content of the bullet
-
[71]
- target_id: index of the bullet point you want to remove
DELETE: Remove an existing bullet point. - target_id: index of the bullet point you want to remove. ### Query Sample: Below is the Query Image to be classified by the predictor.: { visualized time series } C Extended Experiments C.1 Analysis of Few-shot Train Samples To further evaluate the robustness ofMarsTSCunder few-shot sampling randomness and varyin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.