MBABench: Evaluating LLM Agents on End-to-End Spreadsheet Tasks in Finance
Pith reviewed 2026-05-22 05:25 UTC · model grok-4.3
The pith
Current LLM agents fall short of professional standards when creating complete financial spreadsheets from high-level instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM agents are not yet able to reliably produce professional-quality spreadsheets at the level of complexity real-world financial workflows demand, as shown by their sharp performance degradation on harder tasks despite leading models producing the most professional-looking outputs.
What carries the argument
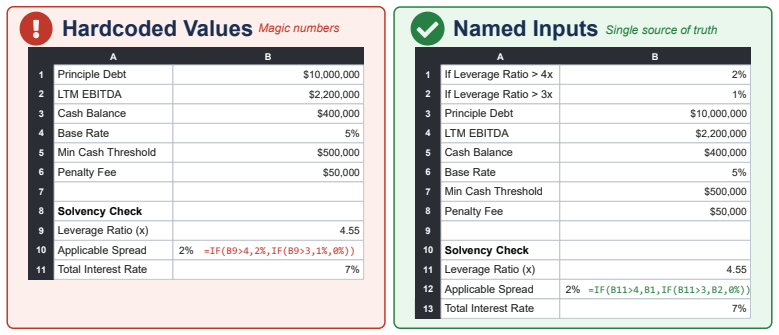
A three-dimensional evaluation taxonomy with Accuracy, Formula, and Format dimensions, each containing fine-grained criteria that reflect professional finance standards for reviewed deliverables.
If this is right
- If agents can close this gap, they could automate substantial portions of financial modeling and analysis in enterprise settings.
- Performance degrades with increasing difficulty, implying that current models lack robust capabilities for long sequences of dependent calculations.
- Qualitative review shows Claude family outputs look most professional, suggesting differences in how models handle structure and presentation.
- The benchmark focuses on end-to-end tasks, which could guide development toward more practical AI tools for finance.
Where Pith is reading between the lines
- Such a benchmark might be extended to other domains like accounting or data analysis where spreadsheets are central.
- Improvements here could lead to AI assistants that not only compute but also create maintainable documents for teams.
- Tracking progress on this benchmark over time could measure advancement in agentic AI for professional tasks.
Load-bearing premise
The assumption that the Accuracy, Formula, and Format dimensions together capture the key criteria that finance stakeholders apply when they review and revise spreadsheet work.
What would settle it
A controlled study in which finance professionals rate the quality of agent-generated spreadsheets on real tasks and check whether high benchmark scores align with their professional approval or rejection.
Figures

















read the original abstract
LLM agents are increasingly expected to carry out end-to-end workflows, producing complete artifacts from high-level user instructions. To meet enterprise needs, frontier AI labs have developed agents that can construct entire spreadsheets from scratch. This is especially relevant in finance, where core workflows such as financial modeling, forecasting, and scenario analysis are commonly conducted through spreadsheets. Yet, existing spreadsheet benchmarks do not measure this advanced capability, focusing instead on question-answering or single-formula edits. To address this gap, we provide one of the first evaluations of agents on end-to-end spreadsheet tasks, focusing on economically critical financial workflows such as modeling and scenario analysis. Since deliverables therein are routinely reviewed and revised by multiple stakeholders, judging their quality necessarily involves high-level criteria such as readability or ease of modification. To reflect the multidimensional nature of solution quality, we develop an evaluation taxonomy comprising three dimensions: Accuracy, Formula, and Format, each comprising fine-grained criteria that reflect professional standards. The Claude family leads the benchmark and produces the most professional-looking outputs in our qualitative review, but even the strongest agents frequently fall short of professional finance standards and degrade sharply as the difficulty increases beyond a few chained calculations. This suggests that current agents are not yet able to reliably produce professional-quality spreadsheets at the level of complexity real-world workflows demand.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WorkstreamBench, one of the first benchmarks for evaluating LLM agents on end-to-end spreadsheet construction tasks in finance, such as financial modeling, forecasting, and scenario analysis. It defines a three-dimensional evaluation taxonomy (Accuracy, Formula, Format) with fine-grained criteria intended to reflect professional standards, evaluates frontier agents on these tasks, and reports that the Claude family produces the most professional-looking outputs while all agents frequently fall short of professional finance standards and degrade sharply with increasing difficulty beyond a few chained calculations.
Significance. If the taxonomy is shown to align with actual finance-professional review practices, the benchmark fills a clear gap left by prior spreadsheet evaluations focused on question-answering or single-formula edits. The work supplies concrete evidence of current agent limitations on complex, multi-stakeholder deliverables and offers a reusable evaluation framework that could steer development toward more reliable enterprise agents. The qualitative observation that Claude outputs appear most professional is a useful secondary finding.
major comments (1)
- Abstract: The central claim that agents 'frequently fall short of professional finance standards' rests on the assertion that the Accuracy/Formula/Format taxonomy 'reflect professional standards.' No evidence is provided of external validation—such as expert inter-rater agreement, correlation with real revision rates, or blind comparison against existing finance review rubrics—which is load-bearing for interpreting the measured performance gaps and difficulty scaling as evidence of professional inadequacy.
minor comments (1)
- Abstract: The headline results would be easier to contextualize if the number of tasks, difficulty levels, and agents evaluated were stated explicitly rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify the scope and limitations of our evaluation framework. We address the major comment point by point below.
read point-by-point responses
-
Referee: Abstract: The central claim that agents 'frequently fall short of professional finance standards' rests on the assertion that the Accuracy/Formula/Format taxonomy 'reflect professional standards.' No evidence is provided of external validation—such as expert inter-rater agreement, correlation with real revision rates, or blind comparison against existing finance review rubrics—which is load-bearing for interpreting the measured performance gaps and difficulty scaling as evidence of professional inadequacy.
Authors: We agree that the manuscript would benefit from clearer justification of how the taxonomy aligns with professional practice. The three dimensions and their criteria were derived from widely cited guidelines in financial modeling (e.g., best-practice recommendations from the CFA Institute, Wall Street training materials on model auditability, and common review criteria used in investment banking for model hand-off). However, we did not perform formal external validation such as inter-rater reliability studies with practicing finance professionals or correlation analyses against real-world revision rates. In the revised version we will (1) expand the Methods section with explicit references to the professional sources used to construct each criterion, (2) add a dedicated Limitations subsection that acknowledges the absence of direct expert validation and the interpretive caution this implies, and (3) revise the abstract and conclusion to state that agents fall short of the standards encoded in the taxonomy rather than asserting professional inadequacy without qualification. These changes will make the evidential basis for our claims more transparent. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
This is an empirical benchmark paper with no mathematical derivations, equations, or fitted parameters. The evaluation taxonomy is introduced as a methodological framework whose criteria are stated to reflect professional standards; this is a definitional choice for measurement rather than a prediction or result derived from prior inputs by construction. Central claims consist of direct performance measurements and qualitative observations against the stated criteria. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The work is self-contained as an empirical study, consistent with the default expectation of no circularity for such evaluations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The selected tasks (financial modeling, forecasting, scenario analysis) are representative of real-world finance workflows that require multi-stakeholder review.
- domain assumption The Accuracy-Formula-Format taxonomy reflects the criteria actually used by finance professionals when judging spreadsheet deliverables.
invented entities (1)
-
WorkstreamBench benchmark
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
develop an evaluation taxonomy comprising three dimensions: Accuracy, Formula, and Format, each comprising fine-grained criteria that reflect professional standards
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.