OSGNet with MLLM Reranking @ Ego4D Episodic Memory Challenge 2026
Pith reviewed 2026-05-21 05:17 UTC · model grok-4.3
The pith
A reranking framework using OSGNet for candidates and MLLM for selection wins first place in two Ego4D episodic memory tracks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
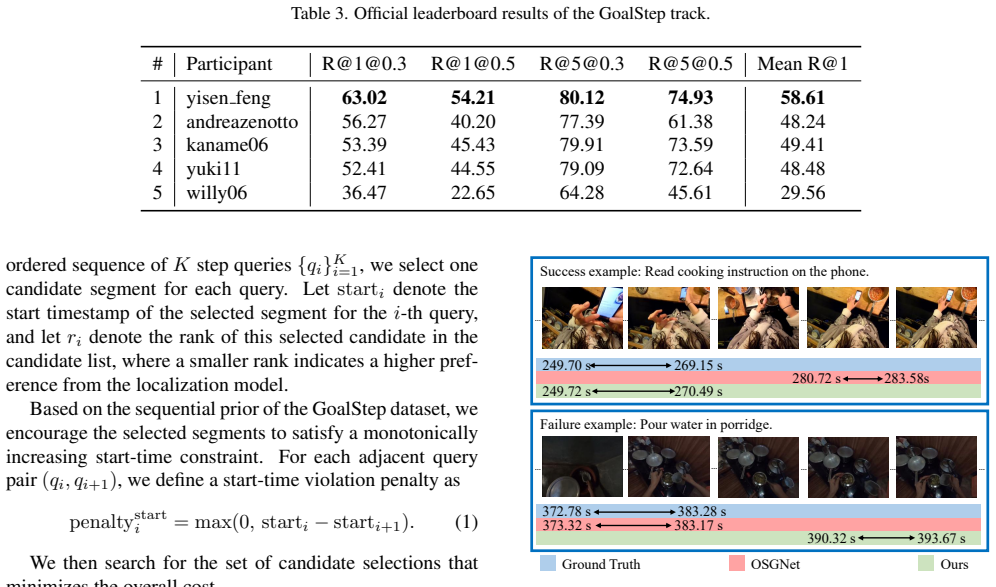
The authors establish that obtaining candidate segments from OSGNet and refining the prediction by having an MLLM select the best match for the query produces superior localization results in untrimmed egocentric videos, as demonstrated by winning the top spots in the relevant challenge tracks.
What carries the argument
The reranking-based framework that generates candidates with OSGNet and refines them with MLLM selection to identify the query-matching segment.
Load-bearing premise
The multimodal large language model can reliably identify the single correct segment among the candidates produced by OSGNet when given the query.
What would settle it
Running the MLLM reranker on a validation set and checking if it consistently selects the ground-truth segment more often than the highest-scoring OSGNet candidate would test the claim.
Figures


read the original abstract
In this report, we present our champion solutions for the Natural Language Queries and GoalStep tracks of the Ego4D Episodic Memory Challenge at CVPR 2026. Both tracks require accurately localizing temporal segments from long untrimmed egocentric videos. To address these tasks, we propose a reranking-based framework that effectively leverages the strong video-language reasoning capability of multimodal large language model (MLLM) while preserving the efficiency and candidate recall of conventional localization pipelines. Specifically, we first obtain a set of candidate segments from existing localization model OSGNet, and then employ MLLM to select the segment that best matches the given query, thereby refining the final prediction. Ultimately, our method achieved first place in both the Natural Language Queries and GoalStep tracks. Our code can be found at https://github.com/iLearn-Lab/CVPR25-OSGNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports on a champion solution for the Ego4D Episodic Memory Challenge 2026 in the Natural Language Queries and GoalStep tracks. The approach uses OSGNet to generate candidate temporal segments from egocentric videos and then applies a multimodal large language model (MLLM) for reranking to select the segment that best matches the query. The method achieved first place in both tracks, with code made available at a GitHub repository.
Significance. Should the reported first-place ranking be confirmed by the challenge organizers, this work illustrates an effective hybrid strategy that combines the efficiency of traditional localization models with the reasoning capabilities of MLLMs. This has potential significance for advancing episodic memory and video understanding in egocentric settings. The provision of reproducible code is a notable strength that facilitates further research and verification in the community.
minor comments (3)
- The abstract could benefit from a brief mention of the specific MLLM architecture or prompting strategy used for reranking to provide more context on the method's implementation.
- The manuscript is quite concise; expanding on the experimental setup, such as the number of candidates generated by OSGNet or the criteria for MLLM selection, would improve clarity without altering the central contribution.
- Ensure consistency in terminology, for example, clarifying whether 'GoalStep' refers to a specific track name as used in the challenge.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the hybrid strategy's potential significance, and recommendation for minor revision. We are pleased that the reproducibility via released code is noted as a strength. No specific major comments appear in the report, so we have no individual points requiring detailed rebuttal or clarification at this stage.
Circularity Check
No significant circularity; pipeline is sequential and result is externally verified
full rationale
The paper is a concise technical report on a challenge-winning pipeline that first runs an existing model (OSGNet) to produce candidate segments and then applies an MLLM reranker to select the best match for the query. The reported first-place outcome is an external empirical result confirmed by challenge organizers rather than any internal derivation or prediction. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear in the text. The approach is presented as a straightforward sequential composition of independent components with released code, making the derivation self-contained against the external benchmark.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we first obtain a set of candidate segments from existing localization model OSGNet, and then employ MLLM to select the segment that best matches the given query
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reranking-based framework that effectively leverages the strong video-language reasoning capability of multimodal large language model
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ObjectNLQ@ Ego4D episodic mem- ory challenge 2024.arXiv preprint arXiv:2406.15778, 2024
Yisen Feng, Haoyu Zhang, Yuquan Xie, Zaijing Li, Meng Liu, and Liqiang Nie. ObjectNLQ@ Ego4D episodic mem- ory challenge 2024.arXiv preprint arXiv:2406.15778, 2024. 1
-
[2]
OSGNet @ Ego4D episodic memory challenge 2025.arXiv preprint arXiv:2506.03710, 2025
Yisen Feng, Haoyu Zhang, Qiaohui Chu, Meng Liu, Weili Guan, Yaowei Wang, and Liqiang Nie. OSGNet@ Ego4D episodic memory challenge 2025.arXiv preprint arXiv:2506.03710, 2025. 1
-
[3]
Object-shot enhanced grounding network for egocentric video.arXiv preprint arXiv:2505.04270, 2025
Yisen Feng, Haoyu Zhang, Meng Liu, Weili Guan, and Liqiang Nie. Object-shot enhanced grounding network for egocentric video.arXiv preprint arXiv:2505.04270, 2025. 1, 2
-
[4]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18995–19012, 2022. 1
work page 2022
-
[5]
Zhijian Hou, Lei Ji, Difei Gao, Wanjun Zhong, Kun Yan, Chao Li, Wing-Kwong Chan, Chong-Wah Ngo, Nan Duan, and Mike Zheng Shou. Groundnlq@ ego4d natural language queries challenge 2023.arXiv preprint arXiv:2306.15255, pages 1–5, 2023. 1
-
[6]
Zeqian Li, Shangzhe Di, Zhonghua Zhai, Weilin Huang, Yanfeng Wang, and Weidi Xie. Universal video temporal grounding with generative multi-modal large language mod- els.Advances in Neural Information Processing Systems, 38: 64426–64455, 2026. 1
work page 2026
-
[7]
Attentive moment retrieval in videos
Meng Liu, Xiang Wang, Liqiang Nie, Xiangnan He, Bao- quan Chen, and Tat-Seng Chua. Attentive moment retrieval in videos. InThe 41st international ACM SIGIR conference on research & development in information retrieval, pages 15–24, 2018. 1
work page 2018
-
[8]
Cross-modal moment localiza- tion in videos
Meng Liu, Xiang Wang, Liqiang Nie, Qi Tian, Baoquan Chen, and Tat-Seng Chua. Cross-modal moment localiza- tion in videos. InProceedings of the 26th ACM international conference on Multimedia, pages 843–851, 2018. 1
work page 2018
-
[9]
Yale Song, Eugene Byrne, Tushar Nagarajan, Huiyu Wang, Miguel Martin, and Lorenzo Torresani. Ego4d goal-step: To- ward hierarchical understanding of procedural activities.Ad- vances in Neural Information Processing Systems, 36, 2024. 1
work page 2024
-
[10]
Ye Wang, Ziheng Wang, Boshen Xu, Yang Du, Kejun Lin, Zihan Xiao, Zihao Yue, Jianzhong Ju, Liang Zhang, Dingyi Yang, et al. Time-r1: Post-training large vision language model for temporal video grounding.Advances in Neural Information Processing Systems, 38:83330–83364, 2026. 1
work page 2026
-
[11]
Multimodal dialog system: Rela- tional graph-based context-aware question understanding
Haoyu Zhang, Meng Liu, Zan Gao, Xiaoqiang Lei, Yinglong Wang, and Liqiang Nie. Multimodal dialog system: Rela- tional graph-based context-aware question understanding. In Proceedings of the 29th ACM international conference on multimedia, pages 695–703, 2021. 1
work page 2021
-
[12]
Haoyu Zhang, Meng Liu, Yuhong Li, Ming Yan, Zan Gao, Xiaojun Chang, and Liqiang Nie. Attribute-guided collab- orative learning for partial person re-identification.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(12):14144–14160, 2023. 1
work page 2023
-
[13]
Multi-factor adaptive vision selec- tion for egocentric video question answering
Haoyu Zhang, Meng Liu, Zixin Liu, Xuemeng Song, Yaowei Wang, and Liqiang Nie. Multi-factor adaptive vision selec- tion for egocentric video question answering. InProceedings of the 41st International Conference on Machine Learning, pages 59310–59328. PMLR, 2024. 1
work page 2024
-
[14]
Exo2ego: Exocentric knowledge guided mllm for egocentric video understanding
Haoyu Zhang, Qiaohui Chu, Meng Liu, Haoxiang Shi, Yaowei Wang, and Liqiang Nie. Exo2ego: Exocentric knowledge guided mllm for egocentric video understanding. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 12502–12510, 2026. 1
work page 2026
-
[15]
Spatial understand- ing from videos: Structured prompts meet simulation data
Haoyu Zhang, Meng Liu, Zaijing Li, Haokun Wen, Weili Guan, Yaowei Wang, and Liqiang Nie. Spatial understand- ing from videos: Structured prompts meet simulation data. Advances in Neural Information Processing Systems, 38: 103202–103229, 2026. 1
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.