One Model to Translate Them All: Universal Any-to-Any Translation for Heterogeneous Collaborative Perception
Pith reviewed 2026-05-20 11:40 UTC · model grok-4.3
The pith
A single pretrained model can translate intermediate features between any pair of sensor modalities without retraining or fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
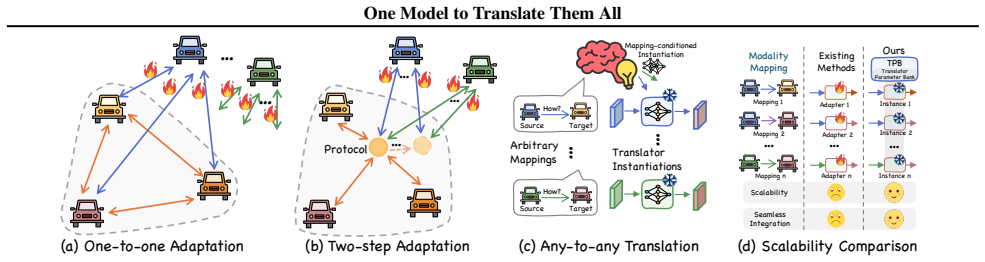
UniTrans pretrains a bank of translator expert parameters and learns their combination coefficients as a function of source-to-target modality mapping measured in a modality-intrinsic latent space, where an intrinsic encoder extracts modality-specific yet scene-invariant codes from single-frame intermediate features, enabling the model to instantiate translators for arbitrary modalities in a zero-shot manner.
What carries the argument
Bank of pretrained translator expert parameters whose combination coefficients are predicted from a modality mapping in a latent space produced by an intrinsic encoder on single-frame features.
If this is right
- Any-to-any feature translation becomes possible through one universal model instead of training separate adapters for each new modality.
- Translation works in zero-shot fashion for previously unseen modality pairs measured in the latent space.
- The approach respects model and data privacy by eliminating the need for additional retraining across different manufacturers.
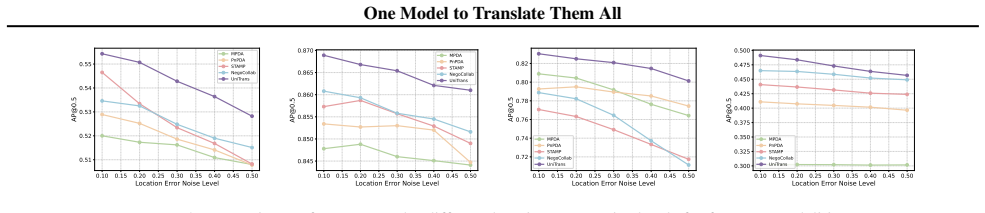
- Performance improves over existing direct-adaptation and protocol-based methods on both simulated and real-world collaborative perception benchmarks.
Where Pith is reading between the lines
- The method could support dynamic addition of new sensors in deployed fleets without requiring system-wide updates or data sharing.
- Similar expert-bank techniques might apply to other heterogeneous multi-agent tasks such as joint mapping or coordinated planning.
- Extending the latent-space mapping to handle temporal sequences rather than single frames could improve robustness in fast-moving scenes.
Load-bearing premise
An intrinsic encoder can reliably extract modality-specific yet scene-invariant codes from single-frame intermediate features that suffice to determine accurate combination coefficients for any unseen modality pair.
What would settle it
A clear drop in translation quality or end-to-end perception performance when the model is tested on a new sensor modality whose intrinsic code was never seen during coefficient learning.
Figures



read the original abstract
By sharing intermediate features, collaborative perception extends each agent's sensing beyond standalone limits, but real-world feature modality heterogeneity remains a key barrier to effective fusion. Most existing methods, including direct adaption and protocol-based transformation, typically rely on training adapters for newly emerging feature modalities and often require additional retraining or fine-tuning. Such repeated training is costly and is often infeasible across manufacturers due to model and data privacy constraints, limiting real-world scalability. To address this issue, we propose UniTrans, a universal any-to-any feature modality translation model that instantiates translators on the fly for arbitrary modalities. UniTrans pretrains a bank of translator expert parameters and learns their combination coefficients as a function of source-to-target modality mapping. The mapping is measured in a modality-intrinsic latent space, where an intrinsic encoder extracts modality-specific yet scene-invariant codes from single-frame intermediate features, enabling UniTrans to instantiate translators in a zero-shot manner. Experiments on OPV2V-H and DAIR-V2X demonstrate that UniTrans consistently outperforms state-of-the-art methods in both simulated and real-world settings, enabling efficient any-to-any translation through a universal model. The code is available at https://github.com/CheeryLeeyy/UniTrans.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniTrans, a universal any-to-any feature modality translation model for heterogeneous collaborative perception. It pretrains a bank of translator expert parameters and learns their combination coefficients as a function of source-to-target modality mapping measured in a modality-intrinsic latent space. An intrinsic encoder extracts modality-specific yet scene-invariant codes from single-frame intermediate features, enabling zero-shot instantiation of translators for arbitrary modalities without retraining. Experiments on OPV2V-H and DAIR-V2X demonstrate consistent outperformance over state-of-the-art methods in simulated and real-world settings.
Significance. If the central claims hold, this work would have substantial significance for collaborative perception and multi-modal fusion. It directly tackles the practical barrier of feature modality heterogeneity by enabling a single model to handle any-to-any translation scalably, avoiding costly per-modality retraining or fine-tuning that conflicts with privacy constraints across manufacturers. The dynamic expert combination via intrinsic latent codes represents a novel direction that could extend to other heterogeneous multi-agent systems. The public code release at the provided GitHub link supports reproducibility.
major comments (2)
- [Section 4] Section 4 (Experiments): All reported results use modalities from the OPV2V-H and DAIR-V2X training distributions; no evaluation is provided for translation involving a truly novel sensor type or representation outside this support. This is load-bearing for the zero-shot any-to-any claim, as the intrinsic encoder and expert bank are fitted exclusively to seen modalities.
- [Section 3.2] Section 3.2 (Intrinsic Encoder): The claim that single-frame intermediate features yield modality-specific yet scene-invariant codes sufficient to compute accurate combination coefficients for unseen pairs lacks supporting analysis or ablation; nothing in the architecture enforces invariance under distribution shift to new resolutions or noise statistics.
minor comments (2)
- [Section 4] Abstract and Section 4: Outperformance statements lack error bars, ablation details on the expert bank size or latent space, and statistical tests, which would strengthen verification of the results.
- [Figures] Figure captions: Some visualizations of the latent space or translator instantiation could include more explicit annotations for modality clusters to aid clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help clarify the scope of our zero-shot claims. We address each major comment in detail below, providing clarifications on the experimental support and architectural design while noting where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Experiments): All reported results use modalities from the OPV2V-H and DAIR-V2X training distributions; no evaluation is provided for translation involving a truly novel sensor type or representation outside this support. This is load-bearing for the zero-shot any-to-any claim, as the intrinsic encoder and expert bank are fitted exclusively to seen modalities.
Authors: We appreciate the referee pointing out the distinction between modalities within the training support and truly novel sensors. The reported experiments evaluate any-to-any translation across the heterogeneous modalities present in OPV2V-H (simulated) and DAIR-V2X (real-world), which include distinct sensor representations such as different LiDAR point-cloud features and camera-based features. The core mechanism—pretraining an expert bank and deriving combination coefficients from mappings in the modality-intrinsic latent space extracted by the intrinsic encoder—is explicitly designed to support zero-shot instantiation for arbitrary modalities by relying on single-frame feature characteristics rather than dataset-specific training. We acknowledge that direct empirical results on sensor types completely absent from the training distributions would provide stronger validation of the generalization claim. In the revised manuscript we will add a dedicated limitations and future-work paragraph discussing this point, along with preliminary results using synthetically altered feature representations to simulate novel modalities. revision: partial
-
Referee: [Section 3.2] Section 3.2 (Intrinsic Encoder): The claim that single-frame intermediate features yield modality-specific yet scene-invariant codes sufficient to compute accurate combination coefficients for unseen pairs lacks supporting analysis or ablation; nothing in the architecture enforces invariance under distribution shift to new resolutions or noise statistics.
Authors: The intrinsic encoder is trained to produce codes that isolate modality-specific properties (e.g., feature dimensionality, noise characteristics, and representation style) while remaining invariant to scene content by operating exclusively on single-frame intermediate features and employing a combination of reconstruction and contrastive objectives that penalize scene-dependent variations. This design choice is motivated by the observation that modality intrinsics are largely preserved across frames, whereas scene semantics vary. We provide supporting ablations in the supplementary material that isolate the contribution of the single-frame input and the latent-space mapping for coefficient prediction accuracy on held-out modality pairs. Nevertheless, we agree that explicit robustness tests under controlled distribution shifts (resolution changes, added sensor noise) are not currently reported in the main text. We will incorporate these ablations into the revised Section 3.2 and add corresponding quantitative results. revision: partial
Circularity Check
No significant circularity; derivation is self-contained via standard pretraining and held-out evaluation.
full rationale
The paper's core mechanism pretrains a bank of translator expert parameters and learns combination coefficients as a function of source-to-target mappings in a latent space produced by a trained intrinsic encoder. These components are optimized on training data from OPV2V-H and DAIR-V2X and evaluated on held-out test sets for both simulated and real-world scenarios. No equation or claim reduces the claimed any-to-any translation performance to quantities defined by the same fitted parameters or to a self-citation chain. The architecture follows conventional supervised training of neural modules without self-definitional loops or fitted-input predictions.
Axiom & Free-Parameter Ledger
free parameters (1)
- combination coefficients
axioms (1)
- domain assumption A modality-intrinsic latent space exists in which codes are scene-invariant across modalities
invented entities (2)
-
intrinsic encoder
no independent evidence
-
bank of translator expert parameters
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
UniTrans pretrains a bank of translator expert parameters and learns their combination coefficients as a function of source-to-target modality mapping measured in a modality-intrinsic latent space, where an intrinsic encoder extracts modality-specific yet scene-invariant codes from single-frame intermediate features
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ϕj→i = Θ(0) + Σ α(k)j→i Θ(k) (linear parameter combination to instantiate mapping-specific translator)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Soup-of-Experts: Pretraining Specialist Models via Parameters Averaging , shorttitle =
Ablin, Pierre and Katharopoulos, Angelos and Seto, Skyler and Grangier, David , year = 2025, langid =. Soup-of-Experts: Pretraining Specialist Models via Parameters Averaging , shorttitle =. Forty-Second
work page 2025
-
[2]
Bai, Zhengwei and Wu, Guoyuan and Barth, Matthew J. and Liu, Yongkang and Akin Sisbot, Emrah and Oguchi, Kentaro and Huang, Zhitong , year = 2024, month = nov, journal =. A Survey and Framework of Cooperative Perception: From Heterogeneous Singleton to Hierarchical Cooperation , shorttitle =. doi:10.1109/TITS.2024.3436012 , langid =
-
[3]
IEEE Transactions on Knowledge and Data Engineering , volume =
A Survey on Mixture of Experts in Large Language Models , author =. IEEE Transactions on Knowledge and Data Engineering , volume =. doi:10.1109/TKDE.2025.3554028 , langid =
-
[4]
End-to-End Autonomous Driving: Challenges and Frontiers , shorttitle =
Chen, Li and Wu, Penghao and Chitta, Kashyap and Jaeger, Bernhard and Geiger, Andreas and Li, Hongyang , year = 2024, journal =. End-to-End Autonomous Driving: Challenges and Frontiers , shorttitle =. doi:10.1109/TPAMI.2024.3435937 , langid =
-
[5]
Cheng, Kun and He, Xiao and Yu, Lei and Tu, Zhijun and Zhu, Mingrui and Wang, Nannan and Gao, Xinbo and Hu, Jie , year = 2025, langid =. Diff-. Forty-Second
work page 2025
-
[6]
Chen, Ting and Kornblith, Simon and Norouzi, Mohammad and Hinton, Geoffrey E. , year = 2020, series =. A Simple Framework for Contrastive Learning of Visual Representations , booktitle =
work page 2020
-
[7]
Chen, Weinan and Chi, Wenzheng and Ji, Sehua and Ye, Hanjing and Liu, Jie and Jia, Yunjie and Yu, Jiajie and Cheng, Jiyu , year = 2025, month = jun, journal =. A Survey of Autonomous Robots and Multi-Robot Navigation: Perception, Planning and Collaboration , shorttitle =. doi:10.1016/j.birob.2024.100203 , langid =
-
[8]
Shao, Congzhang and Yuan, Quan and Luo, Guiyang and Hu, Yue and Wang, Danni and Yilin, Liu and Pan, Rui and Chen, Bo and Li, Jinglin , year = 2025, month = oct, langid =. The
work page 2025
-
[9]
Dosovitskiy, Alexey and Ros, German and Codevilla, Felipe and Lopez, Antonio and Koltun, Vladlen , year = 2017, month = oct, series =. Proceedings of the 1st
work page 2017
-
[10]
Learning Factored Representations in a Deep Mixture of Experts , booktitle =
Eigen, David and Ranzato, Marc'Aurelio and Sutskever, Ilya , year = 2014, langid =. Learning Factored Representations in a Deep Mixture of Experts , booktitle =
work page 2014
-
[11]
Fedus, William and Zoph, Barret and Shazeer, Noam , year = 2022, month = jan, journal =. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , shorttitle =
work page 2022
-
[12]
Gao, Xiangbo and Xu, Runsheng and Li, Jiachen and Wang, Ziran and Fan, Zhiwen and Tu, Zhengzhong , year = 2025, langid =. The
work page 2025
-
[13]
IEEE Transactions on Intelligent Vehicles , pages =
A Survey of Collaborative Perception in Intelligent Vehicles at Intersections , author =. IEEE Transactions on Intelligent Vehicles , pages =. doi:10.1109/TIV.2024.3395783 , langid =
-
[14]
A Neural Algorithm of Artistic Style
A Neural Algorithm of Artistic Style , author =. doi:10.48550/arXiv.1508.06576 , archiveprefix =. 1508.06576 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1508.06576
-
[15]
Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models , shorttitle =
Guo, Yongxin and Cheng, Zhenglin and Tang, Xiaoying and Tu, Zhaopeng and Lin, Tao , year = 2024, month = oct, langid =. Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models , shorttitle =. The
work page 2024
-
[16]
Hu, Senkang and Fang, Zhengru and Deng, Yiqin and Chen, Xianhao and Fang, Yuguang , year = 2025, month = oct, journal =. Collaborative Perception for Connected and Autonomous Driving: Challenges, Possible Solutions and Opportunities , shorttitle =. doi:10.1109/MWC.002.2400348 , langid =
-
[17]
Hu, Yue and Fang, Shaoheng and Lei, Zixing and Zhong, Yiqi and Chen, Siheng , year = 2022, month = dec, journal =. Where2comm:
work page 2022
-
[18]
and Ba, Jimmy , year = 2015, langid =
Kingma, Diederik P. and Ba, Jimmy , year = 2015, langid =. Adam: A Method for Stochastic Optimization , shorttitle =. 3rd
work page 2015
-
[19]
Lang, Alex H. and Vora, Sourabh and Caesar, Holger and Zhou, Lubing and Yang, Jiong and Beijbom, Oscar , year = 2019, month = jun, pages =. 2019. doi:10.1109/CVPR.2019.01298 , copyright =
- [20]
-
[21]
doi:10.1109/TMM.2026.3654458 , langid =
Lin, Bin and Tang, Zhenyu and Ye, Yang and Huang, Jinfa and Zhang, Junwu and Pang, Yatian and Jin, Peng and Ning, Munan and Luo, Jiebo and Yuan, Li , year = 2026, journal =. doi:10.1109/TMM.2026.3654458 , langid =
-
[22]
Towards Accurate and Efficient
Liu, Linshen and Su, Boyan and Jiang, Junyue and Wu, Guanlin and Guo, Cong and Xu, Ceyu and Yang, Hao Frank , year = 2025, pages =. Towards Accurate and Efficient. Proceedings of the
work page 2025
-
[23]
Liu, Zhuang and Mao, Hanzi and Wu, Chao-Yuan and Feichtenhofer, Christoph and Darrell, Trevor and Xie, Saining , year = 2022, pages =. A. doi:10.1109/CVPR52688.2022.01167 , langid =
-
[24]
Liu, Xu and Liu, Juncheng and Woo, Gerald and Aksu, Taha and Liang, Yuxuan and Zimmermann, Roger and Liu, Chenghao and Li, Junnan and Savarese, Silvio and Xiong, Caiming and Sahoo, Doyen , year = 2025, langid =. Moirai-. Forty-Second
work page 2025
-
[25]
Li, Yunxin and Jiang, Shenyuan and Hu, Baotian and Wang, Longyue and Zhong, Wanqi and Luo, Wenhan and Ma, Lin and Zhang, Min , year = 2025, month = may, journal =. Uni-. doi:10.1109/TPAMI.2025.3532688 , langid =
-
[26]
Lu, Yifan and Li, Quanhao and Liu, Baoan and Dianati, Mehrdad and Feng, Chen and Chen, Siheng and Wang, Yanfeng , year = 2023, month = may, pages =. 2023. doi:10.1109/ICRA48891.2023.10160546 , copyright =
-
[27]
An Extensible Framework for Open Heterogeneous Collaborative Perception , booktitle =
Lu, Yifan and Hu, Yue and Zhong, Yiqi and Wang, Dequan and Wang, Yanfeng and Chen, Siheng , year = 2024, langid =. An Extensible Framework for Open Heterogeneous Collaborative Perception , booktitle =
work page 2024
-
[28]
Plug and Play: A Representation Enhanced Domain Adapter for Collaborative Perception , shorttitle =
Luo, Tianyou and Yuan, Quan and Luo, Guiyang and Xia, Yuchen and Yang, Yujia and Li, Jinglin , year = 2025, pages =. Plug and Play: A Representation Enhanced Domain Adapter for Collaborative Perception , shorttitle =. Computer. doi:10.1007/978-3-031-73004-7_17 , langid =
-
[29]
McKinzie, Brandon and Gan, Zhe and Fauconnier, Jean-Philippe and Dodge, Sam and Zhang, Bowen and Dufter, Philipp and Shah, Dhruti and Du, Xianzhi and Peng, Futang and Belyi, Anton and Zhang, Haotian and Singh, Karanjeet and Kang, Doug and H. Computer. doi:10.1007/978-3-031-73397-0_18 , langid =
-
[30]
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to
Philion, Jonah and Fidler, Sanja , year = 2020, month = aug, pages =. Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to. Computer. doi:10.1007/978-3-030-58568-6_12 , langid =
-
[31]
On Variational Bounds of Mutual Information , booktitle =
Poole, Ben and Ozair, Sherjil and van den Oord, A. On Variational Bounds of Mutual Information , booktitle =
-
[32]
Shazeer, Noam and Mirhoseini, Azalia and Maziarz, Krzysztof and Davis, Andy and Le, Quoc V. and Hinton, Geoffrey E. and Dean, Jeff , year = 2017, langid =. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , shorttitle =. 5th
work page 2017
-
[33]
Wang, Tsun-Hsuan and Manivasagam, Sivabalan and Liang, Ming and Yang, Bin and Zeng, Wenyuan and Urtasun, Raquel , year = 2020, volume =. European. doi:10.1007/978-3-030-58536-5_36 , langid =
-
[34]
Xia, Yuchen and Yuan, Quan and Luo, Guiyang and Fu, Xiaoyuan and Li, Yang and Zhu, Xuanhan and Luo, Tianyou and Chen, Siheng and Li, Jinglin , year = 2025, pages =. One Is Plenty: A Polymorphic Feature Interpreter for Immutable Heterogeneous Collaborative Perception , shorttitle =. doi:10.1109/CVPR52734.2025.00156 , langid =
-
[35]
ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions
Xu, Runsheng and Li, Jinlong and Dong, Xiaoyu and Yu, Hongkai and Ma, Jiaqi , year = 2023, month = may, pages =. Bridging the. 2023. doi:10.1109/ICRA48891.2023.10160871 , langid =
-
[36]
Xu, Runsheng and Tu, Zhengzhong and Xiang, Hao and Shao, Wei and Zhou, Bolei and Ma, Jiaqi , year = 2022, series =. Conference on
work page 2022
-
[37]
Xu, Runsheng and Tu, Zhengzhong and Xiang, Hao and Shao, Wei and Zhou, Bolei and Ma, Jiaqi , year = 2022, month = aug, langid =. 6th
work page 2022
-
[38]
Xu, Xiang and Kong, Lingdong and Shuai, Hui and Pan, Liang and Liu, Ziwei and Liu, Qingshan , year = 2025, pages =. doi:10.1109/CVPR52734.2025.02549 , langid =
-
[39]
Xu, Runsheng and Guo, Yi and Han, Xu and Xia, Xin and Xiang, Hao and Ma, Jiaqi , year = 2021, month = sep, pages =. 2021. doi:10.1109/ITSC48978.2021.9564825 , keywords =
-
[40]
Xu, Runsheng and Xiang, Hao and Xia, Xin and Han, Xu and Li, Jinlong and Ma, Jiaqi , year = 2022, month = may, pages =. 2022. doi:10.1109/ICRA46639.2022.9812038 , copyright =
-
[41]
Xu, Runsheng and Xiang, Hao and Tu, Zhengzhong and Xia, Xin and Yang, Ming-Hsuan and Ma, Jiaqi , year = 2022, series =. European. doi:10.1007/978-3-031-19842-7_7 , langid =
-
[42]
DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
Yang, Zhenjie and Chai, Yilin and Jia, Xiaosong and Li, Qifeng and Shao, Yuqian and Zhu, Xuekai and Su, Haisheng and Yan, Junchi , year = 2025, month = may, number =. doi:10.48550/arXiv.2505.16278 , archiveprefix =. 2505.16278 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.16278 2025
-
[43]
Yang, Zuhao and Yu, Yingchen and Zhao, Yunqing and Lu, Shijian and Bai, Song , year = 2025, pages =. Proceedings of the
work page 2025
-
[44]
doi:10.3390/s18103337 , copyright =
Yan, Yan and Mao, Yuxing and Li, Bo , year = 2018, month = oct, journal =. doi:10.3390/s18103337 , copyright =
-
[45]
Yazgan, Melih and Graf, Thomas and Liu, Min and Fleck, Tobias and Z. A Survey on Intermediate Fusion Methods for Collaborative Perception Categorized by Real World Challenges , booktitle =. doi:10.1109/IV55156.2024.10588382 , langid =
-
[46]
Yu, Haibao and Luo, Yizhen and Shu, Mao and Huo, Yiyi and Yang, Zebang and Shi, Yifeng and Guo, Zhenglong and Li, Hanyu and Hu, Xing and Yuan, Jirui and Nie, Zaiqing , year = 2022, month = jun, pages =. 2022. doi:10.1109/CVPR52688.2022.02067 , copyright =
-
[47]
Zhou, Yin and Tuzel, Oncel , year = 2018, month = jun, pages =. 2018. doi:10.1109/CVPR.2018.00472 , langid =
-
[48]
Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis , author =. 1987 , journal =. doi:10.1016/0377-0427(87)90125-7 , langid =
-
[49]
Kapse, Saarthak and Pati, Pushpak and Das, Srijan and Zhang, Jingwei and Chen, Chao and Vakalopoulou, Maria and Saltz, Joel and Samaras, Dimitris and Gupta, Rajarsi R. and Prasanna, Prateek , year =. Proceedings of the. doi:10.1109/CVPR52733.2024.01067 , langid =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.