SkillMAS: Skill Co-Evolution with LLM-based Multi-Agent System
Pith reviewed 2026-05-20 23:16 UTC · model grok-4.3
The pith
SkillMAS couples skill evolution with multi-agent restructuring in LLM systems using utility signals from traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
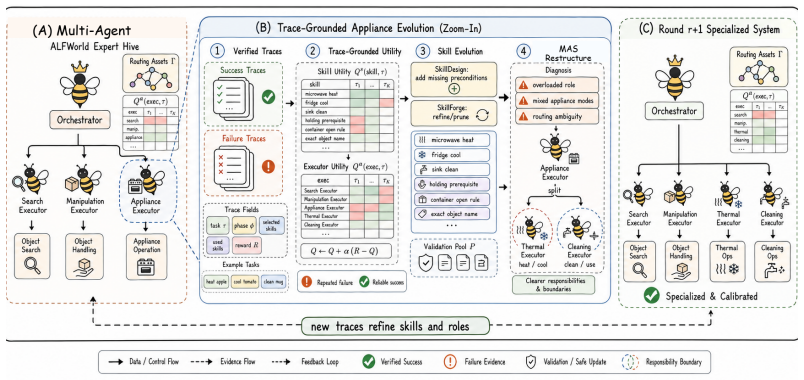
SkillMAS is a non-parametric framework for adaptive specialization in multi-agent systems that couples skill evolution with MAS restructuring using Utility Learning to assign credit from verified execution traces, bounded skill evolution to refine reusable procedures without unfiltered library growth, and evidence-gated MAS restructuring when retained failures and Executor Utility indicate a structural mismatch. Across embodied manipulation, command-line execution, and retail workflows, SkillMAS is competitive under the reported harnesses while clarifying how post-deployment specialization is attributed, updated, and applied.
What carries the argument
Utility Learning combined with bounded skill evolution and evidence-gated MAS restructuring, which uses execution traces to credit skills and trigger organizational changes when needed.
If this is right
- Systems can maintain bounded skill libraries while still improving task performance over time.
- Agent organizations adapt specifically when failures indicate structural issues rather than individual skill deficiencies.
- Credit assignment becomes traceable to specific skills and structures from verified traces.
- Post-deployment adaptation reduces context pressure and mis-specialization in multi-agent setups.
Where Pith is reading between the lines
- Similar coupling could apply to single-agent systems where internal modules evolve with task demands.
- Long-term deployments might show reduced need for initial system design as adaptation handles specialization.
- Testing on sequential tasks over many episodes could reveal patterns in how often restructuring occurs.
- Integration with other adaptation methods like fine-tuning might enhance the utility signals.
Load-bearing premise
Verified execution traces reliably indicate which skills deserve credit and when failures signal a need for restructuring the agent system rather than other issues like noise or missing skills.
What would settle it
Observing that performance does not improve after restructuring events triggered by the framework, or that skill utilities from traces do not predict future success rates accurately.
Figures

read the original abstract
Large language model (LLM) agent systems are increasingly expected to improve after deployment, but existing work often decouples two adaptation targets: skill evolution and multi-agent system (MAS) restructuring. This separation can create organization bottlenecks, context pressure, and mis-specialization. We present SkillMAS, a non-parametric framework for adaptive specialization in multi-agent systems that couples skill evolution with MAS restructuring. SkillMAS uses Utility Learning to assign credit from verified execution traces, bounded skill evolution to refine reusable procedures without unfiltered library growth, and evidence-gated MAS restructuring when retained failures and Executor Utility indicate a structural mismatch. Across embodied manipulation, command-line execution, and retail workflows, SkillMAS is competitive under the reported harnesses while clarifying how post-deployment specialization is attributed, updated, and applied.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SkillMAS, a non-parametric framework for adaptive specialization in LLM-based multi-agent systems. It couples skill evolution with MAS restructuring via Utility Learning (credit assignment from verified execution traces), bounded skill evolution (to refine reusable procedures without unfiltered library growth), and evidence-gated MAS restructuring (triggered when retained failures and Executor Utility indicate structural mismatch). The framework is evaluated across embodied manipulation, command-line execution, and retail workflows, with the abstract asserting competitive performance under the reported harnesses.
Significance. If the empirical support and signal reliability hold, SkillMAS could meaningfully address the decoupling of skill adaptation and organizational restructuring in post-deployment LLM agent systems, reducing bottlenecks and mis-specialization. The non-parametric design and explicit use of verified traces for credit assignment represent potential strengths for reproducible specialization mechanisms.
major comments (2)
- [Abstract] Abstract: The assertion that SkillMAS 'is competitive under the reported harnesses' is unsupported by any metrics, baselines, statistical details, ablation results, or quantitative comparisons. This directly undermines evaluation of the central performance claim across the three domains.
- [§3] §3 (Mechanism description): The evidence-gated restructuring relies on the assumption that retained failures plus Executor Utility reliably diagnose structural mismatch rather than skill gaps, transient noise, or LLM variance. No disambiguation procedure, failure-mode analysis, or ablation isolating these factors is provided, which is load-bearing for the restructuring trigger.
minor comments (2)
- [§3.1] Notation for 'Executor Utility' and 'Utility Learning' is introduced conceptually but without a formal definition or pseudocode, making the credit-assignment step difficult to replicate precisely.
- [§3.2] The manuscript would benefit from explicit discussion of how bounded skill evolution prevents library growth in practice, including any size or retention thresholds used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that SkillMAS 'is competitive under the reported harnesses' is unsupported by any metrics, baselines, statistical details, ablation results, or quantitative comparisons. This directly undermines evaluation of the central performance claim across the three domains.
Authors: We agree that the abstract presents the performance claim at a high level without quantitative detail. The full manuscript reports success rates, baseline comparisons, and ablation results across the three domains in Section 5. To address this, we will revise the abstract to include key metrics, a brief description of the evaluation harnesses, and explicit reference to the comparative results. revision: yes
-
Referee: [§3] §3 (Mechanism description): The evidence-gated restructuring relies on the assumption that retained failures plus Executor Utility reliably diagnose structural mismatch rather than skill gaps, transient noise, or LLM variance. No disambiguation procedure, failure-mode analysis, or ablation isolating these factors is provided, which is load-bearing for the restructuring trigger.
Authors: The evidence-gated trigger is intended to activate only after bounded skill updates have been applied and failures persist, using Executor Utility as an additional signal of organizational fit. Section 3 details the utility learning from verified traces and the gating logic. We acknowledge that the current version lacks an explicit disambiguation procedure or dedicated ablation isolating structural mismatch from skill gaps or variance. We will add a failure-mode analysis subsection and an ablation on the restructuring trigger in the revised manuscript. revision: yes
Circularity Check
No circularity: conceptual framework with no equations or self-referential reductions
full rationale
The paper describes SkillMAS as a non-parametric framework coupling skill evolution and MAS restructuring via Utility Learning from verified traces, bounded evolution, and evidence-gated restructuring. No equations, derivations, fitted parameters, or self-citations appear as load-bearing steps in the provided abstract or described mechanisms. The claims rest on descriptive attribution of post-deployment specialization rather than any reduction of outputs to inputs by construction, making the derivation chain self-contained at a conceptual level without circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Verified execution traces yield usable credit signals for skill attribution
invented entities (1)
-
Utility Learning
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Utility Learning assigns credit only to execution-supported skills... evidence-gated MAS restructuring changes executor boundaries only when retained failures and Executor Utility indicate a structural mismatch.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
bounded skill evolution... evidence-gated MAS restructuring
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Skills on the Fly: Test-Time Adaptive Skill Synthesis for LLM Agents
SkillTTA synthesizes temporary task-specific skills from retrieved training trajectories to boost LLM agent Pass@1 scores on SpreadsheetBench and BigCodeBench without parameter updates.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2505.15182. Weiwen Liu, Jiarui Qin, Xu Huang, Xingshan Zeng, Yunjia Xi, Jianghao Lin, Chuhan Wu, Yasheng Wang, Lifeng Shang, Ruiming Tang, Defu Lian, Yong Yu, and Weinan Zhang. Position: The real barrier to LLM agent usability is agentic ROI.arXiv preprint arXiv:2505.17767, 2025. URL https://arxiv.org/abs/2505.17767. Yujian Liu, J...
-
[2]
URLhttps://arxiv.org/abs/2506.09046. Jingwei Ni, Yihao Liu, Xinpeng Liu, Yutao Sun, Mengyu Zhou, Pengyu Cheng, Dexin Wang, Erchao Zhao, Xiaoxi Jiang, and Guanjun Jiang. Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158, 2026. URL https://arxiv.org/ abs/2603.25158. 10 Xiaohang Nie, Zihan Guo, Zicai...
-
[3]
URLhttps://arxiv.org/abs/2603.09716. Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Chi Wang, Shaokun Zhang, et al. Autogen: Enabling next-gen llm applications via multi- agent conversation.arXiv preprint arXiv:2308.08155, 2023. URL https://arxiv.org/abs/ 2308.08155. Peng Xia, Jianwen Chen, Hanyang Wang, J...
-
[4]
Identify task family: place, clean, heat, cool, or examine
-
[5]
Route search before manipulation when the exact object or receptacle is unknown
-
[6]
Route appliance use only after the exact object and exact appliance are grounded. Why kept / why rejected.Kept because a worker split without manager-side decomposition would not form a coherent MAS story. Rejected neighbors are early placeholder files that still treat the task as one undifferentiated workflow. alfworld/object_search_strategy(search skill...
-
[7]
Classify the target category to choose high-probability locations
-
[8]
Use exact environment names such ascabinet 5orcountertop 1
-
[9]
Why kept / why rejected.Kept because it turns noisy search traces into a reusable executor rule
Open only the confirmed closed receptacle that is currently under inspection. Why kept / why rejected.Kept because it turns noisy search traces into a reusable executor rule. Rejected neighbors mixed object search, take actions, and lamp operations inside one prompt-like patch. 16 alfworld/object_handling(manipulation skill) When to use.Exact take or put ...
-
[10]
Go to the exact source or destination
-
[11]
Open the exact container only if it is confirmed closed
-
[12]
Why kept / why rejected.Kept because the same manipulation invariants recur across task families
Take or put using the exact object and receptacle names, then verify holding state if needed. Why kept / why rejected.Kept because the same manipulation invariants recur across task families. Rejected neighbors remained broad placement summaries without stronger exact-reference safeguards. alfworld/appliance_operation(appliance skill) When to use.Heat, co...
-
[13]
Go to the exact appliance or lamp
-
[14]
Open it only if the operation requires that state
-
[15]
Perform the requested operation and report concrete evidence of success or failure. Why kept / why rejected.Kept because it absorbs brittle transformation rules into one reusable executor role. Rejected neighbors never became appliance-specific enough to retain. pick_heat_then_place_learned_r5(accepted late trajectory skill) When to use.Stabilized heat-tr...
-
[16]
Locate and pick up the target item
-
[17]
Navigate to the exact heating appliance and perform the heat operation
-
[18]
Carry the heated item to the exact destination. Why kept / why rejected.Kept because it complements the appliance executor with a concrete multi-step heating routine. Earlier heating summaries were rejected when they stayed generic or lacked verification. pick_two_obj_and_place_learned_r5(accepted late trajectory skill) When to use.Multi-instance placemen...
-
[19]
Locate both target instances with exact names
-
[20]
Open containers before retrieval and keep exact references during transport
-
[21]
Place both objects into the exact destination while verifying completion after each placement. Why kept / why rejected.Kept because it adds exact-reference discipline that the seed single-object routines did not encode. Earlier two-object patches were rejected when they lacked collection-state tracking. A.6 Lifelong Agent Bench OS Task Executor Prompt and...
-
[22]
Ground the user and plausible orders before asking for more identifiers
-
[23]
Solve directly when the next write is clear, confirmed, and status-compatible
-
[24]
Treat helper output as evidence and reconcile exact ids before any mutation or final reply. Why kept / why rejected.Kept because τ-Bench rewards continuous single-agent case handling; splitting responsibility too early increased routing and closure risk in later rounds. 19 identity_order_grounding(grounding skill) When to use.Authentication, order scans, ...
-
[25]
Prefer concrete credentials already present in the task
-
[26]
Build an order map with order id, status, current item ids, product ids, address, and payment methods
-
[27]
Separate pending, delivered, processed, canceled, and unknown-status orders before choosing a tool lane. Why kept / why rejected.Kept because most downstream failures start from wrong order or status grounding. Rejected alternatives asked for identifiers prematurely or restarted authentication after the user was already grounded. catalog_variant_selection...
-
[28]
Resolve the current product id from order details before variant lookup
-
[29]
Filter variants by confirmed attributes andavailable=true
-
[30]
Preserve unchanged attributes for “same but” or “similar” requests and return one exact candidate only when evidence supports it. Why kept / why rejected.Kept because wrong item-id and near-miss replacement choices dominated hard exchange-return failures. Rejected behavior used product ids as item ids or selected unavailable near matches. payload_prefligh...
-
[31]
Check pending-only and delivered-only tool lanes before execution
-
[32]
Verify array alignment and item-id provenance for current and replacement items
-
[33]
Block same-order incompatible mutation mixes unless the user has given an explicit priority choice. Why kept / why rejected.Kept because it converts many benchmark-specific mistakes into general status, id, payment, and confirmation checks. Rejected variants became prompt patches for individual stories rather than reusable mutation guards. transaction_exe...
-
[34]
Verify the planned write names exactly one tool and exact arguments
-
[35]
Re-check status or item provenance when the case graph is incomplete
-
[36]
Execute the write and use the tool result, not an old plan, for the customer summary. Why kept / why rejected.Kept as a manager-run procedure because delegated transaction execution did not produce stable promoted-helper evidence in the selected trajectory. 20 closure_audit(closure skill) When to use.Before final reply, transfer, ordone. Accepted reasonin...
-
[37]
Verify each confirmed write has a matching completed write or blocker
-
[38]
Check multi-order and multi-item scopes for skipped rows
-
[39]
Use latest tool results for status, payment, refund, balance, and price-difference statements. Why kept / why rejected.Kept because many failures were completed writes with incomplete or looping closure. Rejected neighbors kept reopening already-completed work or promised unsupported follow-up. 21
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.