Demo-JEPA: Joint-Embedding Predictive Architecture for One-shot Cross-Embodiment Imitation
Pith reviewed 2026-05-21 04:41 UTC · model grok-4.3
The pith
A JEPA world model turns visual demonstrations into latent subgoals that any robot body can plan toward.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
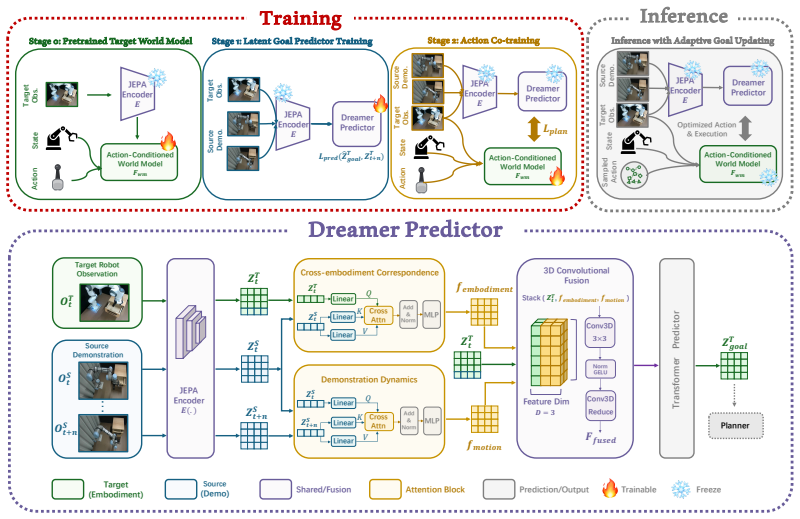
Demo-JEPA translates source visual demonstrations into target-compatible future latent trajectories in a shared predictive representation space. The target agent then uses these latent trajectories as subgoals and realizes them through planning under its own learned forward dynamics. Because Demo-JEPA avoids action-level correspondence and requires only visual demonstrations plus the target agent's own interaction experience, it supports flexible imitation across heterogeneous embodiments.
What carries the argument
The JEPA-based world model that builds a shared predictive representation space to convert visual demonstrations into future latent trajectories usable as subgoals by the target agent.
If this is right
- Imitation succeeds without shared action spaces, retargeting, or multi-embodiment co-training.
- The method generalizes to unseen tasks and new embodiment configurations.
- Performance matches specialized in-domain planners on RLBench and real-world manipulation tasks.
- Only visual demonstrations and the target agent's own experience are required.
Where Pith is reading between the lines
- The same latent space might let a single world model translate goals between agents that differ even more, such as from human hands to robotic grippers.
- Predictive models could become standard translators for goal inference in multi-robot teams with mismatched sensors.
- Further tests with extreme morphology gaps would show where the shared representation starts to lose intent information.
Load-bearing premise
A world model trained primarily on the target agent's interactions can still produce a latent space that correctly captures the intent behind demonstrations from other embodiments.
What would settle it
Run a controlled test where the visual demonstration shows one clear goal but the translated latent trajectory leads the target robot to a different outcome; consistent failure to match the demonstrator's intent would falsify the shared-space claim.
Figures



read the original abstract
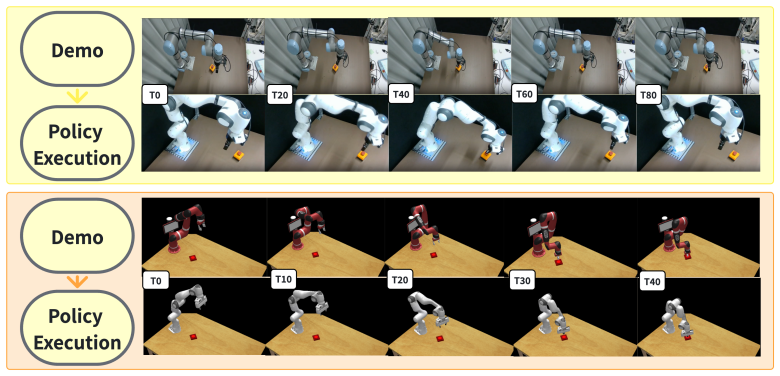
Robotic imitation learning is often treated as reproducing demonstrated actions, but actions are inherently embodiment-specific. When demonstrations come from humans or robots with different morphology, kinematics, or action spaces, this action-centric view requires shared action spaces, heuristic retargeting, or large-scale multi-embodiment co-training. We instead view demonstrations as implicit specifications of future goals: the target agent should infer what state the demonstrator is trying to realize, rather than how the demonstrator executes it. We propose Demo-JEPA, a cross-embodiment imitation framework that decouples demonstration intent from embodiment-specific execution. Built on a JEPA-based world model, Demo-JEPA translates source visual demonstrations into target-compatible future latent trajectories in a shared predictive representation space. The target agent then uses these latent trajectories as subgoals and realizes them through planning under its own learned forward dynamics. Because Demo-JEPA avoids action-level correspondence and requires only visual demonstrations plus the target agent's own interaction experience, it supports flexible imitation across heterogeneous embodiments. Experiments on RLBench and real-world manipulation tasks show that Demo-JEPA matches specialized in-domain planners and generalizes to unseen tasks and embodiment configurations where prior methods fail.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Demo-JEPA, a cross-embodiment imitation framework built on a JEPA world model. Source visual demonstrations are encoded into a shared predictive latent space to produce future trajectories that serve as subgoals; the target agent then plans to realize these trajectories using its own learned forward dynamics. The approach requires only visual demonstrations and the target agent's interaction data, avoiding action retargeting or multi-embodiment co-training. Experiments on RLBench and real-world manipulation are reported to match in-domain planners while generalizing to unseen tasks and embodiment variations.
Significance. If the central mechanism holds, the work offers a principled way to separate intent inference from embodiment-specific execution in imitation learning. The reliance on a predictive JEPA representation rather than direct action matching is a conceptual strength, and the one-shot setting with only target self-interaction data could reduce data requirements compared with prior cross-embodiment methods. Reproducible code or explicit falsifiable predictions are not mentioned in the provided text.
major comments (2)
- [Method] Method section (description of JEPA training and inference): the claim that a JEPA encoder and predictor trained exclusively on target-agent interaction data produces a latent space in which source demonstration frames yield realizable target trajectories rests on an untested invariance assumption. No contrastive loss, domain-adaptation term, or explicit cross-embodiment alignment is described; therefore the translation step may map visually dissimilar source frames to latents whose predicted futures are unreachable under the target dynamics. This assumption is load-bearing for the central cross-embodiment claim.
- [Experiments] Experiments section (quantitative results and ablations): the abstract asserts that Demo-JEPA matches specialized in-domain planners and generalizes where prior methods fail, yet no success rates, baseline comparisons, ablation studies on the predictive component, or metrics for latent-space alignment across embodiments are supplied in the available text. Without these, the empirical support for generalization cannot be evaluated.
minor comments (2)
- [Method] Notation for the latent trajectory and subgoal extraction should be defined explicitly with equations rather than prose only.
- [Experiments] Figure captions for any qualitative rollout visualizations should include embodiment labels and camera viewpoints to clarify cross-embodiment differences.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for identifying key areas where the manuscript could be strengthened. We address each major comment below with clarifications on the method and plans to improve the experimental presentation.
read point-by-point responses
-
Referee: [Method] Method section (description of JEPA training and inference): the claim that a JEPA encoder and predictor trained exclusively on target-agent interaction data produces a latent space in which source demonstration frames yield realizable target trajectories rests on an untested invariance assumption. No contrastive loss, domain-adaptation term, or explicit cross-embodiment alignment is described; therefore the translation step may map visually dissimilar source frames to latents whose predicted futures are unreachable under the target dynamics. This assumption is load-bearing for the central cross-embodiment claim.
Authors: We thank the referee for this observation. The JEPA world model is trained exclusively on the target agent's self-supervised interaction data using a predictive objective that learns to forecast future latent states. This training encourages the encoder to produce representations focused on task-relevant dynamics rather than embodiment-specific visual features, as the loss penalizes inaccurate future predictions under the target's own actions. Consequently, when source demonstration frames are encoded into this space, the resulting latent trajectories correspond to future states that the target can realize by planning with its learned dynamics model. No explicit alignment term is included by design, since the approach avoids requiring paired cross-embodiment data. We will revise the method section to expand on this rationale, including why the predictive (rather than reconstructive) objective supports the observed cross-embodiment generalization. revision: partial
-
Referee: [Experiments] Experiments section (quantitative results and ablations): the abstract asserts that Demo-JEPA matches specialized in-domain planners and generalizes where prior methods fail, yet no success rates, baseline comparisons, ablation studies on the predictive component, or metrics for latent-space alignment across embodiments are supplied in the available text. Without these, the empirical support for generalization cannot be evaluated.
Authors: We agree that the quantitative support should be presented more explicitly. While the manuscript reports results on RLBench and real-world tasks showing performance comparable to in-domain methods and superior generalization, we will revise the experiments section to include a dedicated table of success rates, direct numerical comparisons to baselines (such as behavior cloning and other cross-embodiment approaches), an ablation isolating the contribution of the predictive JEPA component, and metrics evaluating latent trajectory consistency across embodiments. These additions will make the empirical claims fully evaluable. revision: yes
Circularity Check
No significant circularity in Demo-JEPA derivation chain
full rationale
The paper introduces Demo-JEPA as a framework that trains a JEPA world model on target-agent interaction data, encodes source visual demonstrations into the resulting latent space, and uses predicted trajectories as subgoals for planning under the target's dynamics. No equations, fitting procedures, or self-citations are described that would reduce the central translation claim to a quantity defined by the same inputs or prior author work. The approach rests on an empirical assumption about representation invariance rather than any definitional or constructional equivalence between prediction and training data. The derivation from world-model training to cross-embodiment subgoal realization remains self-contained and independent of the target result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A JEPA-style world model can learn a shared predictive representation space that captures future states independently of embodiment-specific details.
Reference graph
Works this paper leans on
-
[1]
Behavioral Cloning from Observation
Faraz Torabi, Garrett Warnell, and Peter Stone. Behavioral cloning from observation.arXiv preprint arXiv:1805.01954, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Imitation learning: A survey of learning methods.ACM Computing Surveys (CSUR), 50(2):1–35, 2017
Ahmed Hussein, Mohamed Medhat Gaber, Eyad Elyan, and Chrisina Jayne. Imitation learning: A survey of learning methods.ACM Computing Surveys (CSUR), 50(2):1–35, 2017
work page 2017
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision- language-action models transfer web knowledge to robotic control, 2023.URL https://arxiv. org/abs/2307.15818, 1:2, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
π0: A vision-language-action flow model for general robot control, 2026
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
work page 2026
-
[6]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page 2025
-
[7]
Xirl: Cross-embodiment inverse reinforcement learning, 2021
Kevin Zakka, Andy Zeng, Pete Florence, Jonathan Tompson, Jeannette Bohg, and Debidatta Dwibedi. Xirl: Cross-embodiment inverse reinforcement learning, 2021
work page 2021
-
[8]
Ria Doshi, Homer Walke, Oier Mees, Sudeep Dasari, and Sergey Levine. Scaling cross- embodied learning: One policy for manipulation, navigation, locomotion and aviation.arXiv preprint arXiv:2408.11812, 2024. 10
-
[9]
Shichao Fan, Kun Wu, Zhengping Che, Xinhua Wang, Di Wu, Fei Liao, Ning Liu, Yixue Zhang, Zhen Zhao, Zhiyuan Xu, et al. Xr-1: Towards versatile vision-language-action models via learning unified vision-motion representations.arXiv preprint arXiv:2511.02776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
La- tent action diffusion for cross-embodiment manipulation
Erik Bauer, Elvis Nava, and Robert K Katzschmann. Latent action diffusion for cross- embodiment manipulation.arXiv preprint arXiv:2506.14608, 2025
-
[11]
arXiv preprint arXiv:2509.22199 (2025)
Haoyun Li, Ivan Zhang, Runqi Ouyang, Xiaofeng Wang, Zheng Zhu, Zhiqin Yang, Zhentao Zhang, Boyuan Wang, Chaojun Ni, Wenkang Qin, et al. Mimicdreamer: Aligning human and robot demonstrations for scalable vla training.arXiv preprint arXiv:2509.22199, 2025
-
[12]
Deep visual foresight for planning robot motion, 2017
Chelsea Finn and Sergey Levine. Deep visual foresight for planning robot motion, 2017
work page 2017
-
[13]
Goal-conditioned reinforcement learning: Problems and solutions, 2022
Minghuan Liu, Menghui Zhu, and Weinan Zhang. Goal-conditioned reinforcement learning: Problems and solutions, 2022
work page 2022
-
[14]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62(1):1–62, 2022
work page 2022
-
[15]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
work page 2023
-
[16]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual repre- sentations from video.arXiv preprint arXiv:2404.08471, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
V-jepa 2.1: Unlocking dense features in video self-supervised learning, 2026
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-jepa 2.1: Unlocking dense features in video self-supervised learning, 2026
work page 2026
-
[19]
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks, 2014
work page 2014
-
[20]
Taming transformers for high-resolution image synthesis, 2021
Patrick Esser, Robin Rombach, and Björn Ommer. Taming transformers for high-resolution image synthesis, 2021
work page 2021
-
[21]
Denoising diffusion probabilistic models, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models, 2020
work page 2020
-
[22]
Denoising diffusion implicit models, 2022
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2022
work page 2022
-
[23]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023
work page 2023
-
[24]
Auto-encoding variational bayes, 2022
Diederik P Kingma and Max Welling. Auto-encoding variational bayes, 2022
work page 2022
-
[25]
Extracting and composing robust features with denoising autoencoders
Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. Extracting and composing robust features with denoising autoencoders. InProceedings of the 25th International Conference on Machine Learning, ICML ’08, page 1096–1103, New York, NY , USA, 2008. Association for Computing Machinery
work page 2008
-
[26]
Masked autoencoders are scalable vision learners, 2021
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners, 2021
work page 2021
-
[27]
Reuven Y Rubinstein. Optimization of computer simulation models with rare events.European Journal of Operational Research, 99(1):89–112, 1997. 11
work page 1997
-
[28]
Kurtland Chua, Roberto Calandra, Rowan McAllister, and Sergey Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models.Advances in neural information processing systems, 31, 2018
work page 2018
-
[29]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
work page 2020
-
[30]
A survey of robot learning from demonstration.Robotics and autonomous systems, 57(5):469–483, 2009
Brenna D Argall, Sonia Chernova, Manuela Veloso, and Brett Browning. A survey of robot learning from demonstration.Robotics and autonomous systems, 57(5):469–483, 2009
work page 2009
-
[31]
Matthew E Taylor and Peter Stone. Transfer learning for reinforcement learning domains: A survey.Journal of Machine Learning Research, 10(7), 2009
work page 2009
-
[32]
Learning Invariant Feature Spaces to Transfer Skills with Reinforcement Learning
Abhishek Gupta, Coline Devin, YuXuan Liu, Pieter Abbeel, and Sergey Levine. Learn- ing invariant feature spaces to transfer skills with reinforcement learning.arXiv preprint arXiv:1703.02949, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Learn- ing modular neural network policies for multi-task and multi-robot transfer
Coline Devin, Abhishek Gupta, Trevor Darrell, Pieter Abbeel, and Sergey Levine. Learn- ing modular neural network policies for multi-task and multi-robot transfer. In2017 IEEE international conference on robotics and automation (ICRA), pages 2169–2176. IEEE, 2017
work page 2017
-
[34]
Universal actions for enhanced embodied foundation models, 2025
Jinliang Zheng, Jianxiong Li, Dongxiu Liu, Yinan Zheng, Zhihao Wang, Zhonghong Ou, Yu Liu, Jingjing Liu, Ya-Qin Zhang, and Xianyuan Zhan. Universal actions for enhanced embodied foundation models, 2025
work page 2025
-
[35]
Boyu Chen, Yi Chen, Lu Qiu, Jerry Bai, Yuying Ge, and Yixiao Ge. Unit: Toward a unified physical language for human-to-humanoid policy learning and world modeling, 2026
work page 2026
-
[36]
Embodiment Collaboration, Abby O’Neill, Abdul Rehman, Abhinav Gupta, Abhiram Mad- dukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, Albert Tung, Alex Bewley, Alex Herzog, Alex Irpan, Alexander Khaz- atsky, Anant Rai, Anchit Gupta, Andrew Wang, Andrey Kolobov, Anikait Singh, Animesh Garg, Aniru...
work page 2025
-
[37]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Xskill: Cross embodiment skill discovery, 2023
Mengda Xu, Zhenjia Xu, Cheng Chi, Manuela Veloso, and Shuran Song. Xskill: Cross embodiment skill discovery, 2023
work page 2023
-
[39]
Learning from observation: A survey of recent advances, 2025
Returaj Burnwal, Hriday Mehta, Nirav Pravinbhai Bhatt, and Balaraman Ravindran. Learning from observation: A survey of recent advances, 2025
work page 2025
-
[40]
Mirage: Cross-embodiment zero-shot policy transfer with cross-painting, 2024
Lawrence Yunliang Chen, Kush Hari, Karthik Dharmarajan, Chenfeng Xu, Quan Vuong, and Ken Goldberg. Mirage: Cross-embodiment zero-shot policy transfer with cross-painting, 2024
work page 2024
-
[41]
Latent diffusion planning for imitation learning, 2025
Amber Xie, Oleh Rybkin, Dorsa Sadigh, and Chelsea Finn. Latent diffusion planning for imitation learning, 2025
work page 2025
-
[42]
One-shot imitation under mismatched execution, 2025
Kushal Kedia, Prithwish Dan, Angela Chao, Maximus Adrian Pace, and Sanjiban Choudhury. One-shot imitation under mismatched execution, 2025
work page 2025
-
[43]
Video prediction policy: A generalist robot policy with predictive visual representations, 2025
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations, 2025
work page 2025
-
[44]
Dream to control: Learning behaviors by latent imagination, 2020
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination, 2020
work page 2020
-
[45]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
World action models are zero-shot policies, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, Jimmy Wu, Qi ...
work page 2026
-
[47]
Learning to predict activity progress by self-supervised video alignment
Gerard Donahue and Ehsan Elhamifar. Learning to predict activity progress by self-supervised video alignment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18667–18677, 2024
work page 2024
-
[48]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025. 13 A Preliminary We briefly review the key building blocks of our approach: action-conditioned world m...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.