Learning to Think in Physics: Breaking Shortcut Learning in Scientific Diffusion via Representation Alignment
Pith reviewed 2026-05-21 06:20 UTC · model grok-4.3
The pith
REPA-P aligns intermediate features with PDE residuals to break shortcut learning in physics diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By decoding hidden activations from intermediate layers into physical states via simple projection heads and enforcing first-principles PDE residuals on those states, diffusion models avoid learning shortcuts and achieve better adherence to physics across training and out-of-distribution cases.
What carries the argument
Lightweight 1×1 projection heads attached to selected intermediate layers that decode activations into physical quantities for applying PDE residual losses.
If this is right
- Convergence on PDE tasks accelerates by up to a factor of two.
- Physics residuals decrease by as much as 66.4 percent.
- Out-of-distribution robustness improves by up to 49.3 percent.
- Performance gains appear consistently on U-Net and Diffusion Transformer architectures.
- Most benefits come from supervising a small number of intermediate layers in addition to the output.
Where Pith is reading between the lines
- Similar intermediate supervision could apply to other generative models used for scientific simulation.
- Embedding physics constraints earlier in the network might reduce reliance on large training datasets.
- Extending the approach to three-dimensional or time-dependent problems would test its scalability.
- Combining this with other physics-informed techniques could yield further gains in complex settings.
Load-bearing premise
Lightweight 1x1 projection heads can decode hidden activations into accurate physical quantities for residual computation without introducing major approximation errors.
What would settle it
Running the same experiments but measuring whether the decoded quantities from the projection heads match the true physical fields to high accuracy; if they do not, the residual losses would not enforce the intended constraints.
Figures




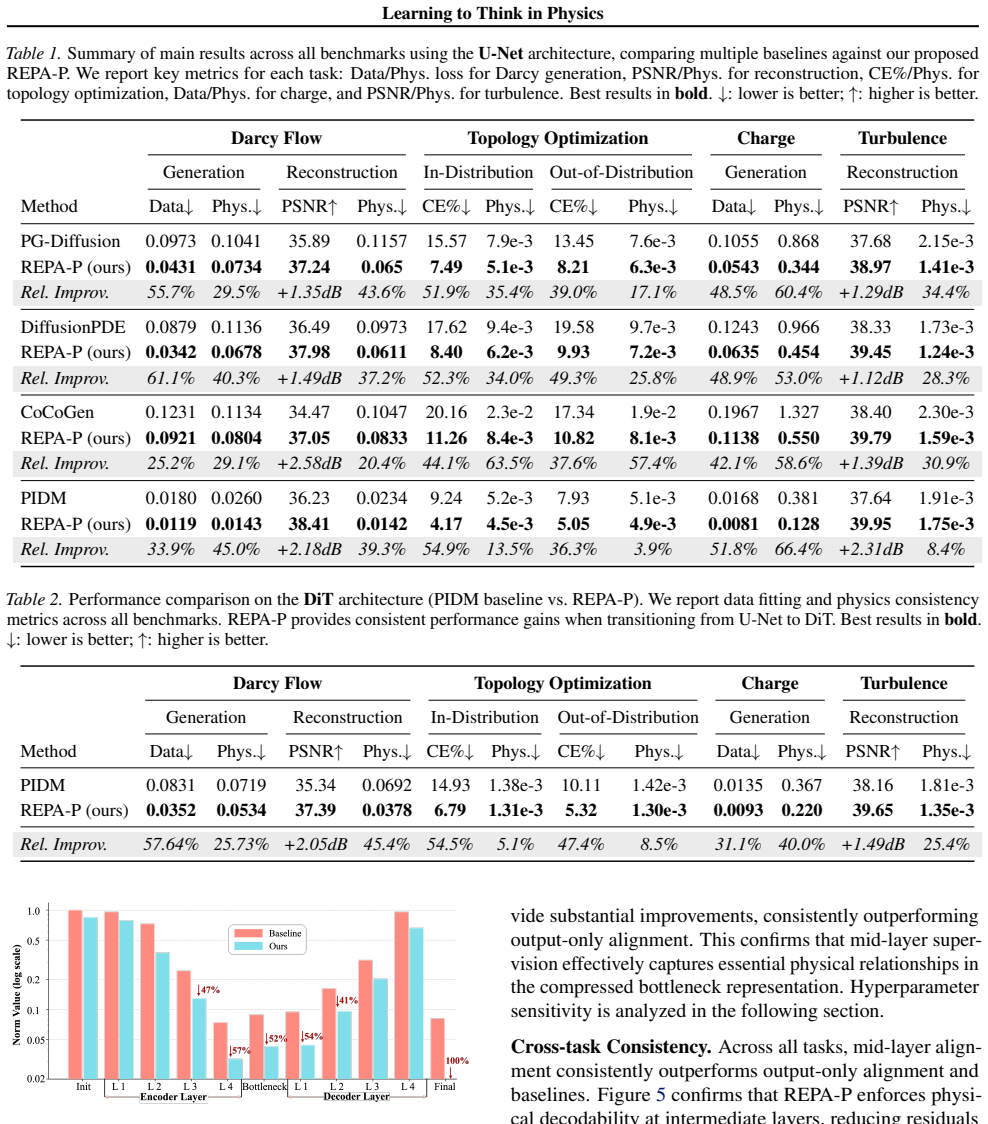
read the original abstract
Physics-informed diffusion models typically enforce PDE constraints only on final outputs, leaving intermediate representations unconstrained and prone to shortcut learning under shifted boundary conditions. We introduce **REPA-P**, a teacher-free, architecture-agnostic framework that aligns intermediate features with physical states using first-principles residuals. REPA-P attaches lightweight $1{\times}1$ projection heads to selected layers, decodes hidden activations into physical quantities, and applies PDE residual losses during training. These heads are discarded at inference, introducing **zero overhead**. Across four PDE tasks, including Darcy flow, topology optimization, electrostatic potential, and turbulent channel flow, REPA-P accelerates convergence by up to $2{\times}$, reduces physics residuals by up to $66.4\%$, and improves out-of-distribution robustness by up to $49.3\%$, with consistent gains on both U-Net and Diffusion Transformer backbones. Ablations show that supervising a small set of intermediate layers captures most benefits and complements output-level physics losses. Code is available at [https://github.com/Hxxxz0/REPA-P](https://github.com/Hxxxz0/REPA-P).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes REPA-P, a teacher-free and architecture-agnostic method for physics-informed diffusion models. It attaches lightweight 1×1 projection heads to selected intermediate layers, decodes hidden activations into physical quantities, and applies PDE residual losses to align representations with first-principles physics. This is claimed to mitigate shortcut learning under shifted boundary conditions. Across four PDE tasks (Darcy flow, topology optimization, electrostatic potential, turbulent channel flow), the approach is reported to accelerate convergence by up to 2×, reduce physics residuals by up to 66.4%, and improve out-of-distribution robustness by up to 49.3%, with consistent gains on U-Net and Diffusion Transformer backbones and zero inference overhead after discarding the heads. Ablations indicate that supervising a small set of layers captures most benefits and complements output-level losses.
Significance. If the decoding mechanism proves accurate, REPA-P could meaningfully advance physics-informed generative modeling by constraining internal representations rather than outputs alone, offering a lightweight alternative to teacher-based or output-only supervision. The open code repository and consistent results across architectures and tasks are notable strengths that support reproducibility and potential adoption in scientific computing applications.
major comments (2)
- [Method and Experiments] The central mechanism depends on the 1×1 projection heads accurately decoding intermediate activations into physical fields without substantial approximation error or layer-specific bias. In the description of REPA-P and the turbulent channel flow experiments, no direct quantification of decoding fidelity (e.g., reconstruction error against ground-truth fields) is provided; without this, the reported residual reductions and robustness gains may reflect auxiliary supervision rather than genuine physics-aligned representations.
- [Ablations] The ablation studies on layer selection demonstrate benefits from intermediate supervision but do not include controls that isolate the contribution of accurate physical decoding versus generic regularization. This leaves open whether the PDE residual losses are enforcing first-principles constraints at the chosen layers or simply adding auxiliary objectives.
minor comments (2)
- [Method] The abstract and method would benefit from explicit equations showing how the decoded quantities enter the PDE residual computation, including any assumptions about boundary conditions or discretization.
- [Experiments] Consider reporting statistical significance or variance across multiple runs for the quantitative improvements (e.g., convergence speed and residual reductions) to strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method and Experiments] The central mechanism depends on the 1×1 projection heads accurately decoding intermediate activations into physical fields without substantial approximation error or layer-specific bias. In the description of REPA-P and the turbulent channel flow experiments, no direct quantification of decoding fidelity (e.g., reconstruction error against ground-truth fields) is provided; without this, the reported residual reductions and robustness gains may reflect auxiliary supervision rather than genuine physics-aligned representations.
Authors: We agree that direct quantification of decoding fidelity would provide stronger evidence that the observed gains arise from physics-aligned representations. The current manuscript emphasizes end-task metrics (convergence speed, residual reduction, and OOD robustness) as the primary validation. In the revised version we will add explicit measurements of reconstruction error (e.g., relative L2 or MSE) between the outputs of the 1×1 projection heads and the corresponding ground-truth physical fields for the turbulent channel flow task, and, where computationally feasible, for the other PDE tasks as well. These new results will be presented in a dedicated subsection under Experiments. revision: yes
-
Referee: [Ablations] The ablation studies on layer selection demonstrate benefits from intermediate supervision but do not include controls that isolate the contribution of accurate physical decoding versus generic regularization. This leaves open whether the PDE residual losses are enforcing first-principles constraints at the chosen layers or simply adding auxiliary objectives.
Authors: We acknowledge the value of controls that separate physics-specific constraints from generic regularization. Our existing ablations already show that intermediate supervision yields gains beyond output-level physics losses alone. To isolate the role of the first-principles PDE residuals, we will add a new control experiment in the revised manuscript: at the same selected layers we will replace the PDE residual loss with a non-physics auxiliary objective (e.g., an L2 penalty on activations or supervision to random targets) while keeping all other training details identical. The performance difference between this control and the original REPA-P will be reported to clarify whether the first-principles nature of the loss is essential. revision: yes
Circularity Check
No circularity: external PDE residuals and empirical baselines keep derivation self-contained
full rationale
The paper introduces REPA-P by attaching 1x1 projection heads to decode intermediate activations and apply first-principles PDE residual losses during training, with heads discarded at inference. These residuals derive from standard physics equations external to the model outputs rather than being fitted or defined in terms of the paper's own predictions. Reported improvements (convergence speed, residual reduction, OOD robustness) are measured against standard output-level baselines on four PDE tasks, not quantities constructed solely from the method's internal choices. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing steps in the provided text. The central mechanism remains independently verifiable against external physics benchmarks and does not reduce to tautology by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- choice of supervised layers
axioms (1)
- domain assumption Hidden activations in diffusion models can be decoded into physical state variables via 1x1 convolutions with sufficient fidelity for residual computation
invented entities (1)
-
REPA-P projection heads
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
REPA-P attaches lightweight 1×1 projection heads to selected layers, decodes hidden activations into physical quantities, and applies PDE residual losses during training.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We hypothesize that the robustness and generalizability of scientific generative models can be significantly enhanced by aligning intermediate representations with physical states.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Chen, W., Jia, H., Lai, S., Wu, K., Xiao, H., Hu, L., and Yue, Y
URL https:// arxiv.org/abs/2403.14404. Chen, W., Jia, H., Lai, S., Wu, K., Xiao, H., Hu, L., and Yue, Y . Free-T2M: Frequency enhanced text-to-motion diffusion model with consistency loss, 2025a. Chen, W., Li, H., Liang, S., Wang, L., Jia, H., Yuan, K., Wu, J., Tian, B., and Yue, Y . POLARIS: Projection-orthogonal least squares for robust and adaptive inv...
-
[2]
Diffusion Posterior Sampling for General Noisy Inverse Problems
URL https://arxiv.org/ abs/2209.14687. Cuomo, S., di Cola, V . S., Giampaolo, F., Rozza, G., Raissi, M., and Piccialli, F. Scientific machine learn- ing through physics-informed neural networks: Where we are and what’s next,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
S., Giampaolo, F., Rozza, G., Raissi, M., et al
URL https://arxiv. org/abs/2201.05624. Esser, P., Kulal, S., Blattmann, A., Entezari, R., M ¨uller, J., Saini, H., Levi, Y ., Lorenz, D., Sauer, A., Boesel, F., Podell, D., Dockhorn, T., English, Z., Lacey, K., Goodwin, A., Marek, Y ., and Rombach, R. Scaling recti- fied flow transformers for high-resolution image synthe- sis,
- [4]
-
[5]
Classifier-Free Diffusion Guidance
URL https://arxiv.org/abs/ 2207.12598. Ho, J., Jain, A., and Abbeel, P. Denoising diffusion prob- abilistic models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Denoising Diffusion Probabilistic Models
URL https://arxiv.org/ abs/2006.11239. Jia, H., Chen, W., Huang, Z., Wang, L., Xiao, H., Jia, N., Wu, K., Lai, S., Tian, B., and Yue, Y . Physics-informed representation alignment for sparse radio-map reconstruc- tion. InProceedings of the 33rd ACM International Con- ference on Multimedia, MM ’25, pp. 12352–12360. As- sociation for Computing Machinery, 20...
work page internal anchor Pith review Pith/arXiv arXiv 2006
- [7]
-
[8]
Fourier Neural Operator for Parametric Partial Differential Equations
URL https://arxiv.org/abs/ 2010.08895. 10 Learning to Think in Physics Li, Z., Zheng, H., Kovachki, N., Jin, D., Chen, H., Liu, B., Azizzadenesheli, K., and Anandkumar, A. Physics- informed neural operator for learning partial differential equations,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
Physics-informed neural operator for learning partial differential equations, 2024
URL https://arxiv.org/abs/ 2111.03794. Lu, C., Zhou, Y ., Bao, F., Chen, J., Li, C., and Zhu, J. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps,
-
[10]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 step s
URL https: //arxiv.org/abs/2206.00927. Maz´e, F. and Ahmed, F. Diffusion models beat gans on topology optimization,
-
[11]
URL https://arxiv. org/abs/2208.09591. Nichol, A. and Dhariwal, P. Improved denoising diffusion probabilistic models,
-
[12]
Improved Denoising Diffusion Probabilistic Models
URL https://arxiv. org/abs/2102.09672. Ning, M., Li, M., Su, J., Jia, H., Liu, L., Benes, M., Chen, W., Salah, A. A., and Onal Ertugrul, I. DCTdiff: Intrigu- ing properties of image generative modeling in the DCT space. InProceedings of the 42nd International Confer- ence on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pp. 4649...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Scalable Diffusion Models with Transformers
URL https://arxiv.org/abs/ 2212.09748. Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
High-Resolution Image Synthesis with Latent Diffusion Models
URL https://arxiv.org/ abs/2112.10752. Ronneberger, O., Fischer, P., and Brox, T. U-net: Convolu- tional networks for biomedical image segmentation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
U-Net: Convolutional Networks for Biomedical Image Segmentation
URLhttps://arxiv.org/abs/1505.04597. Salimans, T. and Ho, J. Progressive distillation for fast sampling of diffusion models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Progressive Distillation for Fast Sampling of Diffusion Models
URL https:// arxiv.org/abs/2202.00512. Sohl-Dickstein, J., Weiss, E. A., Maheswaranathan, N., and Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
URL https: //arxiv.org/abs/1503.03585. Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models.CoRR, abs/2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[18]
Denoising Diffusion Implicit Models
URL https://arxiv.org/abs/2010.02502. Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative model- ing through stochastic differential equations,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[19]
Score-Based Generative Modeling through Stochastic Differential Equations
URL https://arxiv.org/abs/2011.13456. Song, Y ., Dhariwal, P., Chen, M., and Sutskever, I. Con- sistency models,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[20]
URL https://arxiv.org/ abs/2303.01469. Wang, H., Han, J., Fan, W., Zhang, W., and Liu, H. Phyda: Physics-guided diffusion models for data assimilation in atmospheric systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
URL https://arxiv. org/abs/2505.12882. Zhang, L., Rao, A., and Agrawala, M. Adding conditional control to text-to-image diffusion models,
-
[22]
Adding Conditional Control to Text-to-Image Diffusion Models
URL https://arxiv.org/abs/2302.05543. Zheng, H., Nie, W., Vahdat, A., Azizzadenesheli, K., and Anandkumar, A. Fast sampling of diffusion models via operator learning,
work page internal anchor Pith review Pith/arXiv arXiv
- [23]
-
[24]
doi: 10.1016/j.jcp.2018.04.018
ISSN 0021-9991. doi: 10.1016/j.jcp.2018.04.018. URL http://dx. doi.org/10.1016/j.jcp.2018.04.018. 11 Learning to Think in Physics A. Experimental Details This section provides additional details on the experimental setup, residual computation, and evaluation metrics for each benchmark task. A.1. Darcy Flow Problem Formulation.We study steady two-dimension...
-
[25]
For REPA-P, we attach 1×1 convolutional projection heads to the bottleneck and selected decoder blocks. Each head consists of a 1×1 convolution mapping from the hidden dimension to 2 output channels (for K and p), followed by bilinear upsampling to the target resolution 64×64 . The mid-layer alignment weight is set to cmid = 0.1 for the main results, whic...
work page 2025
-
[26]
Best results (excluding baseline) inbold.↓: lower is better;↑: higher is better. Darcy Flow Topology Optimization (ID) Charge Turbulence cmid Data↓Phys.↓Phys.↓CE%↓VFE%↓Phys.↓PSNR↑Phys.↓ Baseline 0.0180 0.0260 5.2e-3 9.24 3.38 0.381 37.64 1.91e-3 0.001 0.0156 0.0177 7.8e-3 11.23 4.13 0.245 38.47 1.86e-3 0.005 0.0142 0.01654.5e-3 4.17 3.020.189 37.91 2.04e-...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.