HyperVision: A Channel-Adaptive Ground-Based Hyperspectral Vision Pre-trained Backbone
Pith reviewed 2026-05-20 14:47 UTC · model grok-4.3
The pith
HyperVision is the first ground-based hyperspectral pre-trained backbone that adapts to varying sensor channels and reaches state-of-the-art results on segmentation, tracking, and detection using only head adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
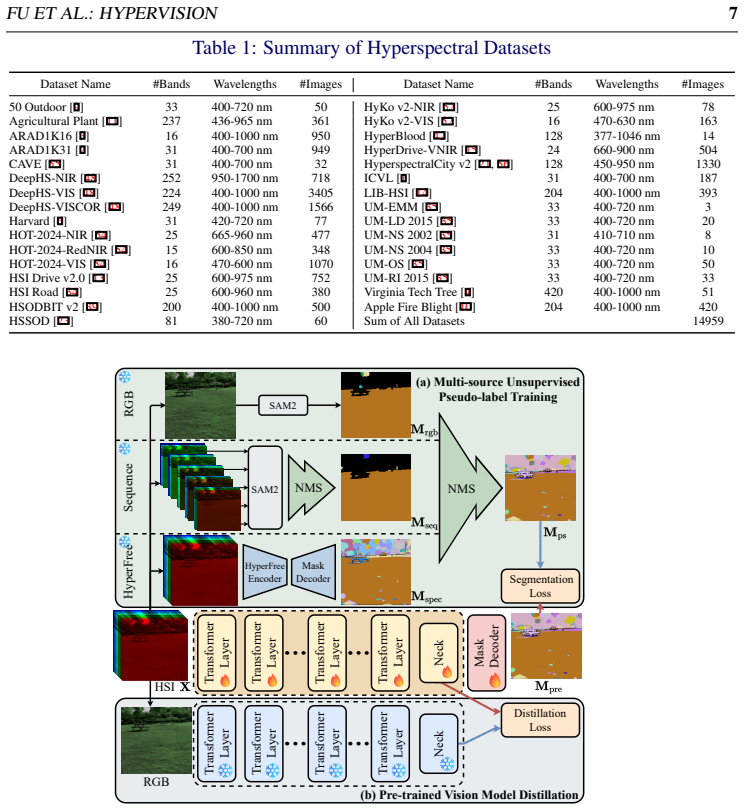
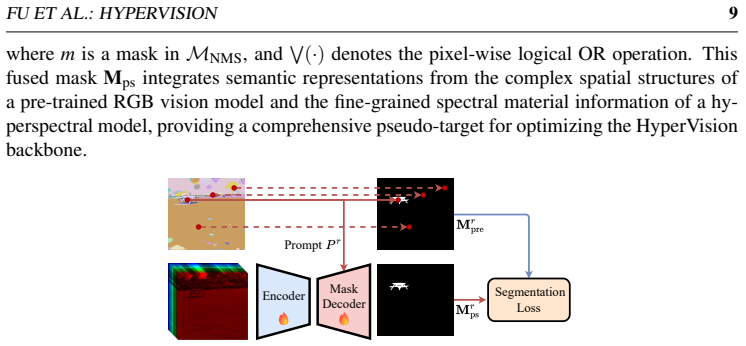
HyperVision supplies the first ground-based hyperspectral backbone by (1) a channel-adaptive dynamic embedding that projects inputs of arbitrary spectral length into one unified token space, (2) multi-source pseudo-labeling that merges SAM2 spatial structures with HyperFree spectral material information, and (3) cross-modal distillation that transfers rich semantics from a pre-trained RGB vision model. After training on 15 k images from 26 diverse ground-based datasets, the model yields state-of-the-art accuracy on semantic segmentation, object tracking, and salient-object detection when only a task-specific head is trained.
What carries the argument
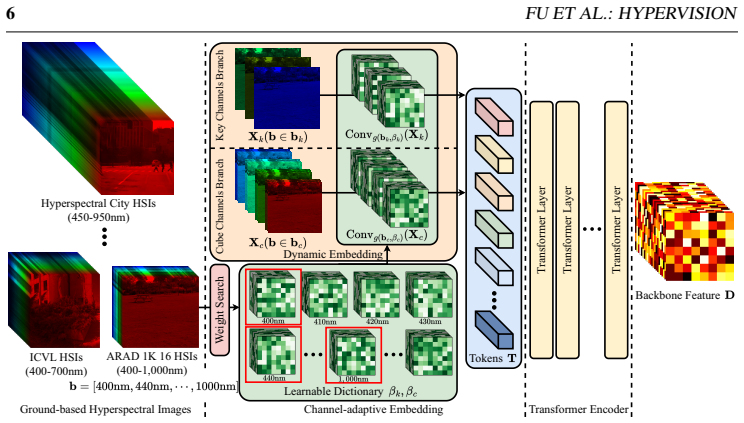
Channel-adaptive dynamic embedding mechanism that maps heterogeneous spectral inputs into a unified token space while preserving spectral resolution.
If this is right
- Any new ground-based hyperspectral sensor can be used immediately by feeding its raw band stack through the same backbone without retraining the feature extractor.
- Labeling effort for future hyperspectral tasks drops sharply because the pre-trained model already carries both spatial layout and material identity cues.
- Cross-modal distillation from RGB models becomes a standard route for enriching small hyperspectral collections.
- Real-time hyperspectral applications such as material sorting or vegetation monitoring can adopt the same backbone across different camera hardware.
Where Pith is reading between the lines
- The same channel-adaptive design could be tested on airborne or satellite hyperspectral data to check whether the backbone transfers beyond ground-based scenes.
- If the pseudo-labeling step is replaced by a small amount of human-verified labels, the performance gap between head-only and full fine-tuning might shrink further.
- The reported gains on three disparate tasks suggest the backbone has learned a representation that is largely task-agnostic, which could support zero-shot or few-shot hyperspectral recognition.
Load-bearing premise
The pseudo-labels created by fusing SAM2 spatial structures with HyperFree spectral cues are accurate and consistent enough to train a backbone that generalizes across unseen sensors and tasks.
What would settle it
Train the backbone once, then evaluate it on a new ground-based hyperspectral dataset recorded by a sensor whose channel count and wavelength centers lie outside the 26 training datasets; if head-only adaptation fails to match or exceed task-specific baselines, the generalization claim is falsified.
Figures







read the original abstract
While hyperspectral imaging provides rich spatial-spectral information across hundreds of narrow wavelength bands for precise material identification, ground-based hyperspectral pre-trained backbones remain absent, constrained by varying spectral configurations across sensors, the scarcity and inconsistency of labels, and the limited scale and scene diversity of existing datasets. To address these challenges and enable universal perception, we propose HyperVision, the first ground-based hyperspectral pre-trained backbone. First, to handle varying spectral configurations, HyperVision adopts a channel-adaptive dynamic embedding mechanism to map heterogeneous inputs into a unified token space. Second, we develop an unsupervised representation learning framework. Specifically, to address label scarcity and inconsistency, a multi-source pseudo-labeling method is introduced to fuse spatial structures from SAM2 and fine-grained spectral material information from HyperFree. Furthermore, to enrich scene diversity and compensate for limited dataset scale, a cross-modal knowledge distillation mechanism is utilized to transfer rich semantic representations from a pre-trained RGB vision model to our backbone. Pre-trained on a collection of 15k images from 26 diverse ground-based datasets, HyperVision demonstrates exceptional generalization. Requiring only efficient head-only adaptation without adjusting backbone parameters, it achieves state-of-the-art performance compared to task-specific methods across three downstream tasks under varying sensor configurations, yielding up to a 16.3% relative improvement in hyperspectral semantic segmentation $\mathrm{Acc}_{\mathrm{M}}$, a 2.1% relative gain in object tracking AUC, and a 35.5% reduction in salient object detection MAE. The source code and pre-trained model will be publicly available on https://github.com/lronkitty/HyperVision .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HyperVision as the first ground-based hyperspectral pre-trained backbone. It employs a channel-adaptive dynamic embedding to unify heterogeneous spectral inputs, a multi-source pseudo-labeling strategy that fuses SAM2-derived spatial structures with HyperFree spectral material cues to overcome label scarcity and inconsistency, and cross-modal distillation from RGB models to increase scene diversity. Pre-trained on 15k images drawn from 26 ground-based datasets, the backbone achieves reported state-of-the-art results on three downstream tasks using only head-only adaptation: up to 16.3% relative improvement in hyperspectral semantic segmentation Acc_M, 2.1% relative gain in object tracking AUC, and 35.5% reduction in salient object detection MAE across varying sensor configurations.
Significance. If the performance claims are substantiated by rigorous validation of the pseudo-label quality and experimental controls, the work would constitute a meaningful contribution by establishing the first general-purpose pre-trained model for ground-based hyperspectral perception. The channel-adaptive design and head-only adaptation protocol address practical deployment constraints across heterogeneous sensors, while the public release of code and weights would support reproducibility and follow-on research in material-aware vision tasks.
major comments (2)
- [Abstract (multi-source pseudo-labeling paragraph)] The multi-source pseudo-labeling method (described in the abstract paragraph on multi-source pseudo-labeling) is load-bearing for the central claim that a generalizable backbone can be trained despite label scarcity. The manuscript provides no quantitative validation of the fused pseudo-labels themselves, such as pixel-wise agreement with held-out human annotations, cross-sensor consistency scores, or error rates on a real-label validation subset. Without these metrics, downstream SOTA gains with head-only adaptation could plausibly arise from dataset curation or the distillation component rather than reliable spectral-spatial supervision.
- [Experimental evaluation (implied by abstract performance claims)] The abstract reports concrete relative gains (16.3% Acc_M, 2.1% AUC, 35.5% MAE reduction) on three tasks, yet the provided text contains no details on baseline implementations, statistical significance tests, error bars, dataset splits, or ablation studies isolating the contribution of each component. These omissions make it impossible to confirm that the reported improvements are robust and attributable to the proposed pre-training pipeline rather than implementation specifics.
minor comments (1)
- [Abstract] The symbols Acc_M and MAE are used without explicit definition in the abstract; a brief parenthetical clarification or reference to standard definitions would improve readability for readers outside the immediate hyperspectral community.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects for strengthening the presentation of our multi-source pseudo-labeling approach and the experimental evaluation. We address each major comment below and will incorporate revisions to provide the requested validations and details, thereby improving the rigor and reproducibility of the work.
read point-by-point responses
-
Referee: [Abstract (multi-source pseudo-labeling paragraph)] The multi-source pseudo-labeling method (described in the abstract paragraph on multi-source pseudo-labeling) is load-bearing for the central claim that a generalizable backbone can be trained despite label scarcity. The manuscript provides no quantitative validation of the fused pseudo-labels themselves, such as pixel-wise agreement with held-out human annotations, cross-sensor consistency scores, or error rates on a real-label validation subset. Without these metrics, downstream SOTA gains with head-only adaptation could plausibly arise from dataset curation or the distillation component rather than reliable spectral-spatial supervision.
Authors: We acknowledge that direct quantitative validation of the pseudo-label quality would further substantiate the reliability of the multi-source fusion strategy. While the manuscript demonstrates effectiveness through downstream task performance, we agree this leaves room for alternative explanations. In the revised manuscript, we will add a new subsection on pseudo-label validation. This will report: pixel-wise agreement (e.g., IoU and accuracy) against held-out human annotations from multiple sensors; cross-sensor consistency scores for scenes captured under varying spectral configurations; and error rates on a real-label validation subset. We will also include component-wise ablations of the SAM2 spatial and HyperFree spectral contributions to the fused labels, along with qualitative visualizations. These additions will help confirm the supervision quality and isolate its role from dataset curation or distillation. revision: yes
-
Referee: [Experimental evaluation (implied by abstract performance claims)] The abstract reports concrete relative gains (16.3% Acc_M, 2.1% AUC, 35.5% MAE reduction) on three tasks, yet the provided text contains no details on baseline implementations, statistical significance tests, error bars, dataset splits, or ablation studies isolating the contribution of each component. These omissions make it impossible to confirm that the reported improvements are robust and attributable to the proposed pre-training pipeline rather than implementation specifics.
Authors: We agree that expanded experimental details are essential to demonstrate robustness and attribute the gains specifically to our pre-training pipeline. In the revised manuscript, we will substantially expand the experimental section to include: full specifications of baseline implementations and adaptations for hyperspectral inputs; results of statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values); error bars from multiple runs with different random seeds; explicit descriptions of dataset splits for pre-training and each downstream task; and comprehensive ablation studies isolating the channel-adaptive dynamic embedding, multi-source pseudo-labeling, and cross-modal distillation components. We will also detail the head-only adaptation protocol and ensure all comparisons use consistent settings. These changes will make the evaluation transparent and confirm the improvements are attributable to the proposed methods. revision: yes
Circularity Check
No circularity in claimed derivation or predictions
full rationale
The paper presents an empirical engineering contribution: a channel-adaptive embedding, multi-source pseudo-labeling via SAM2+HyperFree fusion, and cross-modal distillation, all trained on a collected 15k-image corpus. These are described as practical responses to sensor variation, label scarcity, and dataset scale rather than as outputs of any first-principles derivation or equation set. No mathematical predictions, fitted parameters renamed as forecasts, or self-citation chains that render the central claims tautological appear in the abstract or described methodology. Downstream metrics (Acc_M, AUC, MAE) are independent of the pre-training procedure itself. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SAM2 spatial structures and HyperFree spectral representations can be fused into reliable pseudo-labels despite label scarcity
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.