Spatial Gram Alignment for Ultra-High-Resolution Image Synthesis
Pith reviewed 2026-05-21 05:22 UTC · model grok-4.3
The pith
Aligning self-similarities of generative features with foundation priors preserves pre-trained diffusion models while adding global structure for ultra-high-resolution synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SGA imposes a non-invasive spatial constraint by aligning the internal self-similarities of the generative features with those of the foundation priors. This establishes macroscopic structural coherence while the native generative objectives retain the microscopic pixel-level fidelity inherent to the original LDMs. The approach integrates seamlessly across both intermediate diffusion features and VAE latents within pre-trained LDMs and yields state-of-the-art performance for ultra-high-resolution text-to-image synthesis.
What carries the argument
Spatial Gram Alignment, a non-invasive spatial constraint that aligns internal self-similarities of generative features with foundation priors to enforce structural coherence without perturbing the latent manifold.
If this is right
- SGA reconciles global structural integrity and fine-grained visual details at ultra-high resolutions.
- The method integrates directly with existing pre-trained LDMs at both intermediate diffusion steps and VAE latents.
- Native generative capacity remains intact because the alignment avoids direct patch-wise distillation.
- State-of-the-art results follow for text-to-image synthesis when the spatial constraint is applied.
Where Pith is reading between the lines
- The same self-similarity alignment principle could be tested on other generative backbones that suffer from latent-space drift at scale.
- Extending the constraint to video or 3D diffusion models might address temporal or volumetric coherence without retraining.
- If the relational matching proves robust, it could reduce reliance on task-specific fine-tuning for high-resolution outputs.
Load-bearing premise
Aligning internal self-similarities via a non-invasive spatial constraint on generative features with foundation priors preserves the native generative capacity of pre-trained LDMs without perturbing the latent manifold.
What would settle it
Comparing generation quality and structural metrics at extreme resolutions between an unmodified pre-trained LDM, a version using direct feature distillation, and a version using SGA would show whether the self-similarity constraint avoids degradation.
Figures

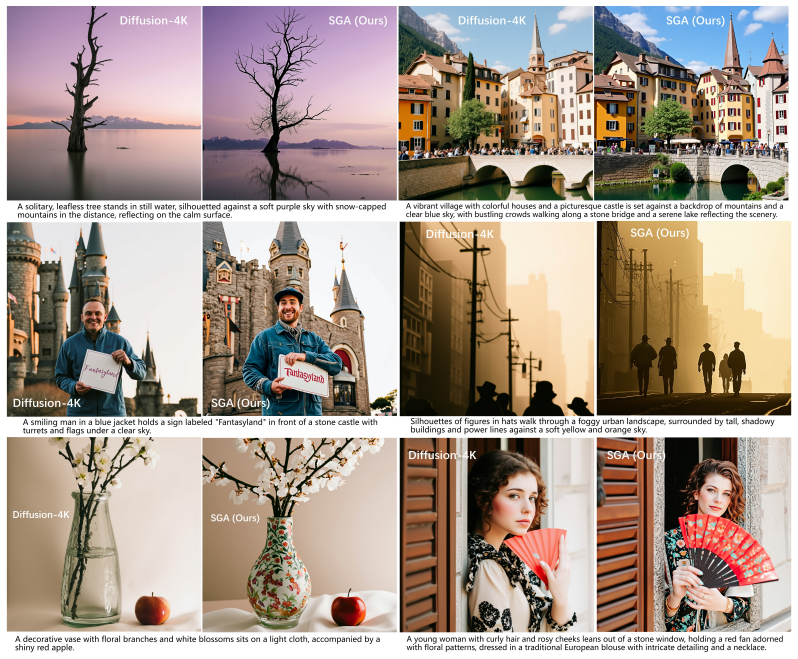

read the original abstract
Modern ultra-high-resolution image synthesis relies heavily on the robust generative capacity of large-scale pre-trained Latent Diffusion Models (LDMs). While recent representation alignment methods have proven effective by distilling visual priors from foundation models (e.g., SAM or DINO) into generative latent features, scaling these approaches to pre-trained LDMs at extreme resolutions exposes a critical learnability-fidelity conflict. Specifically, forcing direct patch-wise feature distillation inherently perturbs the pre-trained latent manifold, ultimately leading to generation degradation. To address this bottleneck, we propose Spatial Gram Alignment (SGA), a novel framework that explicitly leverages the representation priors of vision foundation models while preserving the native generative capacity of LDMs. Moving beyond restrictive direct alignment, SGA imposes a non-invasive spatial constraint by aligning the internal self-similarities of the generative features with those of the foundation priors. This spatial constraint effectively establishes macroscopic structural coherence, while the native generative objectives retain the microscopic pixel-level fidelity inherent to the original LDMs. Notably, this versatile strategy integrates seamlessly across both intermediate diffusion features and VAE latents within pre-trained LDMs. Extensive experiments demonstrate that SGA achieves state-of-the-art performance for ultra-high-resolution text-to-image synthesis, yielding an effective reconciliation between global structural integrity and fine-grained visual details. Code is available at https://github.com/zhang0jhon/SGA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Spatial Gram Alignment (SGA) for ultra-high-resolution text-to-image synthesis in pre-trained Latent Diffusion Models (LDMs). It addresses the learnability-fidelity conflict in representation alignment by imposing a non-invasive spatial constraint that aligns internal self-similarities of generative features (both intermediate diffusion features and VAE latents) with priors from foundation models such as SAM or DINO, rather than using direct patch-wise feature distillation. This is claimed to preserve the original latent manifold and native generative capacity while improving global structural coherence, with extensive experiments demonstrating state-of-the-art performance in reconciling macroscopic structure and microscopic details.
Significance. If the non-invasiveness claim holds and is supported by appropriate validation, SGA could provide a scalable, plug-in improvement for existing LDM pipelines at extreme resolutions without requiring full retraining or manifold perturbation. The approach's emphasis on self-similarity alignment over direct distillation is a potentially useful distinction, and the availability of code supports reproducibility.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method): The central claim that SGA is 'non-invasive' and 'preserves the native generative capacity' of pre-trained LDMs by avoiding perturbation of the latent manifold is load-bearing but lacks direct validation. No quantitative checks (e.g., latent distribution distances, per-layer feature covariance statistics, or manifold-sensitive metrics such as FID on held-out distributions) are referenced to confirm that the spatial Gram constraint does not shift sampling trajectories or feature statistics, especially at extreme resolutions where error accumulation is noted as rapid.
- [§4] §4 (Experiments): The abstract states that SGA achieves SOTA performance with an effective reconciliation between global structural integrity and fine-grained details, yet specific metrics, baselines (e.g., direct alignment variants), ablation results on the self-similarity constraint, or comparisons of generative capacity preservation are not detailed. This weakens support for the claim that the method outperforms direct distillation without degradation.
minor comments (1)
- [Abstract] Abstract: The phrasing 'versatile strategy integrates seamlessly' could be clarified with a brief note on implementation overhead or compatibility constraints with specific LDM architectures.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive feedback on our work. We provide point-by-point responses to the major comments and indicate the revisions we will make to address them.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The central claim that SGA is 'non-invasive' and 'preserves the native generative capacity' of pre-trained LDMs by avoiding perturbation of the latent manifold is load-bearing but lacks direct validation. No quantitative checks (e.g., latent distribution distances, per-layer feature covariance statistics, or manifold-sensitive metrics such as FID on held-out distributions) are referenced to confirm that the spatial Gram constraint does not shift sampling trajectories or feature statistics, especially at extreme resolutions where error accumulation is noted as rapid.
Authors: We thank the referee for highlighting this important point. The non-invasive property is central to our approach, as SGA aligns self-similarities rather than directly distilling features, which we argue avoids manifold perturbation. While we did not report explicit distribution distances in the initial submission, our experiments in §4 show that SGA maintains or improves FID and other metrics compared to baselines without the degradation seen in direct alignment methods. To provide direct validation, we will include additional experiments measuring latent distribution shifts (e.g., using MMD or Wasserstein distance) and feature covariance statistics in the revised version, particularly at high resolutions. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract states that SGA achieves SOTA performance with an effective reconciliation between global structural integrity and fine-grained details, yet specific metrics, baselines (e.g., direct alignment variants), ablation results on the self-similarity constraint, or comparisons of generative capacity preservation are not detailed. This weakens support for the claim that the method outperforms direct distillation without degradation.
Authors: We agree that the abstract could better highlight the specific results. The full details, including metrics, baselines such as direct patch-wise alignment variants, ablations on the self-similarity constraint, and comparisons demonstrating preservation of generative capacity, are provided in §4. We will revise the abstract to include key quantitative findings and explicitly mention the ablation studies to better support our claims. revision: yes
Circularity Check
No significant circularity; derivation introduces independent spatial constraint
full rationale
The paper defines SGA as a new non-invasive alignment of internal self-similarities between LDM generative features and foundation priors (e.g., SAM/DINO), explicitly contrasting it with direct patch-wise distillation to avoid manifold perturbation. No equations reduce a claimed prediction or result back to fitted parameters or prior outputs by construction. No self-citation chains, uniqueness theorems from the same authors, or ansatz smuggling are present in the abstract or described method. The central reconciliation of global coherence and local fidelity is achieved via the proposed constraint itself rather than by re-labeling inputs. This is a standard case of an additive technique on pre-trained models with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained LDMs possess a native generative capacity that direct alignment perturbs but spatial self-similarity constraints can preserve.
Reference graph
Works this paper leans on
-
[1]
Photorealistic text-to- image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to- image diffusion models with deep language understanding. InAdvances in Neural Information Processing Systems, pages 36479–36494, 2022
work page 2022
-
[2]
Imagen 3.arXiv preprint arXiv:2408.07009, 2024
Jason Baldridge, Jakob Bauer, Mukul Bhutani, Nicole Brichtova, Andrew Bunner, Lluis Castrejon, Kelvin Chan, Yichang Chen, Sander Dieleman, Yuqing Du, et al. Imagen 3.arXiv preprint arXiv:2408.07009, 2024
-
[3]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Improving image generation with better captions.Computer Science
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions.Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023
work page 2023
-
[5]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[6]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
work page 2024
- [7]
-
[8]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[9]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
work page 2023
-
[12]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv preprint arXiv:2410.06940, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Jaskirat Singh, Xingjian Leng, Zongze Wu, Liang Zheng, Richard Zhang, Eli Shechtman, and Saining Xie. What matters for representation alignment: Global information or spatial structure?arXiv preprint arXiv:2512.10794, 2025
-
[16]
REPA-E: Unlocking vae for end-to-end tuning of latent diffusion transformers
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. REPA-E: Unlocking vae for end-to-end tuning of latent diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18262–18272, 2025
work page 2025
-
[17]
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15703–15712, 2025. 10
work page 2025
-
[18]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Shilong Zhang, He Zhang, Zhifei Zhang, Chongjian Ge, Shuchen Xue, Shaoteng Liu, Mengwei Ren, Soo Ye Kim, Yuqian Zhou, Qing Liu, et al. Both semantics and reconstruction matter: Making representation encoders ready for text-to-image generation and editing.arXiv preprint arXiv:2512.17909, 2025
-
[20]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. IEEE, 2009
work page 2009
-
[21]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational Bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[22]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
work page 2017
-
[23]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
work page 2021
-
[24]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
work page 2017
-
[25]
Jingjing Ren, Wenbo Li, Haoyu Chen, Renjing Pei, Bin Shao, Yong Guo, Long Peng, Fenglong Song, and Lei Zhu. UltraPixel: Advancing ultra high-resolution image synthesis to new peaks.Advances in Neural Information Processing Systems, 37:111131–111171, 2024
work page 2024
-
[26]
Chen Zhao, En Ci, Yunzhe Xu, Tiehan Fan, Shanyan Guan, Yanhao Ge, Jian Yang, and Ying Tai. UltraHR-100K: Enhancing uhr image synthesis with a large-scale high-quality dataset.arXiv preprint arXiv:2510.20661, 2025
-
[27]
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, et al. SANA: Efficient high-resolution image synthesis with linear diffusion transformers.arXiv preprint arXiv:2410.10629, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Junyu Chen, Han Cai, Junsong Chen, Enze Xie, Shang Yang, Haotian Tang, Muyang Li, Yao Lu, and Song Han. Deep compression autoencoder for efficient high-resolution diffusion models.arXiv preprint arXiv:2410.10733, 2024
-
[29]
Diffusion-4K: Ultra-high-resolution im- age synthesis with latent diffusion models
Jinjin Zhang, Qiuyu Huang, Junjie Liu, Xiefan Guo, and Di Huang. Diffusion-4K: Ultra-high-resolution im- age synthesis with latent diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23464–23473, 2025
work page 2025
-
[30]
Min Zhao, Bokai Yan, Xue Yang, Hongzhou Zhu, Jintao Zhang, Shilong Liu, Chongxuan Li, and Jun Zhu. UltraImage: Rethinking resolution extrapolation in image diffusion transformers.arXiv preprint arXiv:2512.04504, 2025
-
[31]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[32]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In European Conference on Computer Vision, pages 23–40. Springer, 2024
work page 2024
-
[33]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Shengbang Tong, Boyang Zheng, Ziteng Wang, Bingda Tang, Nanye Ma, Ellis Brown, Jihan Yang, Rob Fergus, Yann LeCun, and Saining Xie. Scaling text-to-image diffusion transformers with representation autoencoders.arXiv preprint arXiv:2601.16208, 2026
-
[35]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[36]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International conference on machine learning, pages 8162–8171. PMLR, 2021. 11
work page 2021
-
[37]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Building Normalizing Flows with Stochastic Interpolants
Michael S Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. arXiv preprint arXiv:2209.15571, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Xiangdong Zhang, Jiaqi Liao, Shaofeng Zhang, Fanqing Meng, Xiangpeng Wan, Junchi Yan, and Yu Cheng. VideoREPA: Learning physics for video generation through relational alignment with foundation models. arXiv preprint arXiv:2505.23656, 2025
-
[41]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
work page 2018
-
[42]
Image-to-image translation with conditional adversarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134, 2017
work page 2017
-
[43]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
work page 2019
-
[44]
The Mapillary Vistas dataset for semantic understanding of street scenes
Gerhard Neuhold, Tobias Ollmann, Samuel Rota Bulo, and Peter Kontschieder. The Mapillary Vistas dataset for semantic understanding of street scenes. InProceedings of the IEEE international conference on computer vision, pages 4990–4999, 2017
work page 2017
-
[45]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
ZeRO: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. ZeRO: Memory optimizations toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
work page 2020
-
[47]
ClipScore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. ClipScore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021
work page 2021
-
[48]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. LAION-5B: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
work page 2022
-
[49]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
work page 2004
-
[50]
FLUX.2: Analyzing and enhancing the latent space of FLUX – representation comparison, 2025
Black Forest Labs. FLUX.2: Analyzing and enhancing the latent space of FLUX – representation comparison, 2025
work page 2025
-
[51]
A useful variant of the Davis–Kahan theorem for statisticians.Biometrika, 102(2):315–323, 2015
Yi Yu, Tengyao Wang, and Richard J Samworth. A useful variant of the Davis–Kahan theorem for statisticians.Biometrika, 102(2):315–323, 2015. 12 A Theoretical Analysis This section establishes three properties of Lsga that clarify, respectively, what the constraint leaves free in the projected generative features, what it transfers from the foundation prio...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.