Attention Dispersion in Dynamic Graph Transformers: Diagnosis and a Transferable Fix
Pith reviewed 2026-05-20 19:59 UTC · model grok-4.3
The pith
Differential attention corrects attention dispersion in dynamic graph Transformers by focusing on critical nodes under temporal shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Existing dynamic graph Transformers suffer from attention dispersion under temporal distribution shift, as the reduced contrast causes attention to spread evenly instead of concentrating on critical historical neighbors that carry stronger predictive signals than arbitrary nodes; differential attention addresses this by subtracting common-mode components to highlight token-specific differences, which reduces entropy and directs more attention mass to those critical nodes, improving accuracy in a transferable way.
What carries the argument
differential attention, which suppresses common-mode attention and amplifies distinctive token-level signals
If this is right
- Adding differential attention to existing CTDG Transformer baselines yields consistent performance gains.
- The gains concentrate on datasets with high temporal distribution shift.
- Attention entropy decreases and attention mass on critical nodes increases.
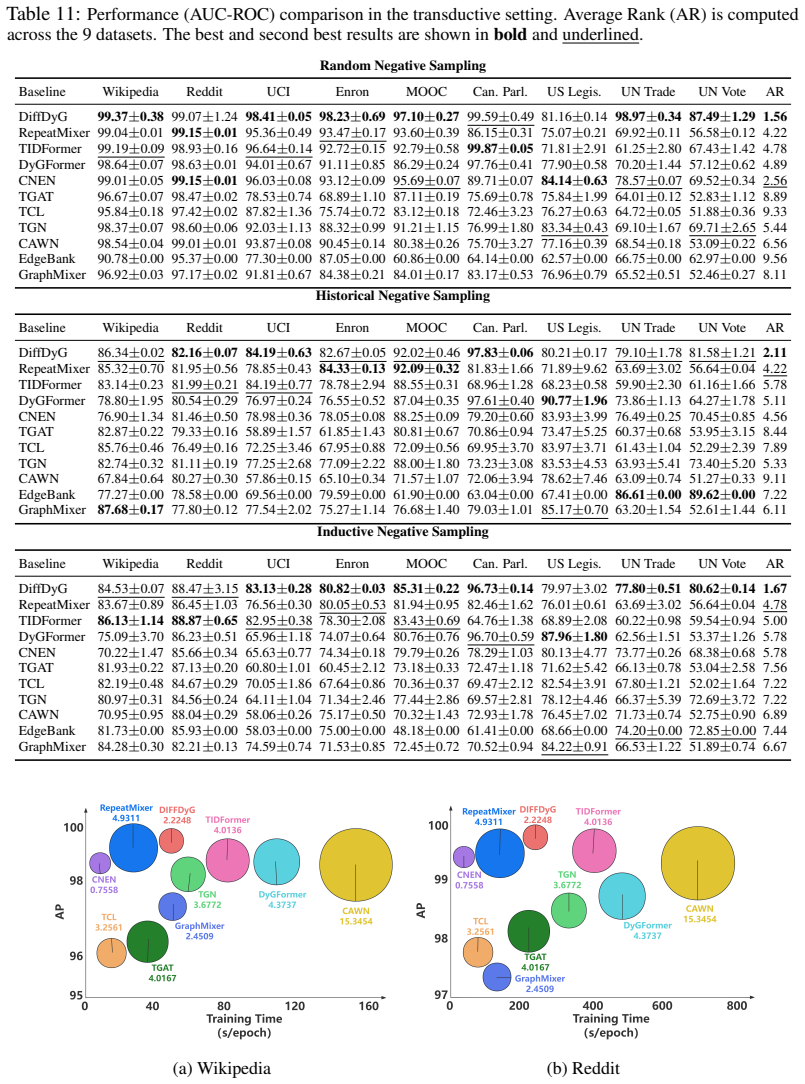
- The combined DiffDyG model achieves state-of-the-art results on nine benchmarks under multiple negative sampling protocols.
Where Pith is reading between the lines
- The attention dispersion diagnosis may apply to other transformer models that process sequences with temporal or distributional changes.
- Differential attention could be tested as a lightweight addition in non-graph sequence tasks facing similar focus problems.
Load-bearing premise
The controlled ablation correctly isolates that prediction depends on a distinct class of critical nodes with more predictive signal than random historical neighbors.
What would settle it
If applying differential attention on high-shift datasets produces no measurable drop in attention entropy and no rise in attention mass allocated to the identified critical nodes, the diagnosis and mechanism would be falsified.
Figures




read the original abstract
Transformer-based architectures have become the dominant paradigm for Continuous-Time Dynamic Graph (CTDG) learning, yet their performance remains limited on temporally shifted datasets. In this work, we identify attention dispersion as a shared failure mode of dynamic graph Transformers under temporal distribution shift. Through controlled ablation contrasting structurally and temporally distinguished historical neighbors against random ones, we show that prediction depends on a class of critical nodes that carry consistently more predictive signal than arbitrary neighbors. However, existing Transformers fail to focus on these nodes even when they are present in the input, as temporal shift weakens attention contrast and produces overly dispersed attention distributions. This diagnosis suggests a simple and transferable fix: replace standard attention with differential attention, which suppresses common-mode attention and amplifies distinctive token-level signals. When added to three representative CTDG Transformer baselines, differential attention consistently improves performance, with gains concentrated on high-shift datasets. Attention-level measurements further confirm the mechanism, showing reduced attention entropy and increased attention mass on critical nodes. Building on these findings, we introduce DiffDyG, a reference implementation combining differential attention with standard input encodings. Across 9 benchmarks and three negative sampling protocols, DiffDyG achieves SOTA performance, with especially large gains on the most shifted datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper diagnoses attention dispersion as a failure mode in Transformer-based models for Continuous-Time Dynamic Graphs (CTDG) under temporal distribution shift. Through ablations, it claims that prediction relies on a class of critical nodes carrying more predictive signal than arbitrary neighbors, but existing models produce overly dispersed attention distributions that fail to focus on these nodes even when present. It proposes differential attention to suppress common-mode signals and amplify distinctive token-level information, reports consistent gains when added to three baselines (especially on high-shift data), provides attention measurements confirming reduced entropy and increased mass on critical nodes, and introduces DiffDyG which achieves SOTA across 9 benchmarks and three negative sampling protocols.
Significance. If the central diagnosis and mechanism hold after addressing controls, the work would offer a practical, transferable architectural adjustment for improving robustness of dynamic graph Transformers to temporal shifts, with potential value in domains such as link prediction on evolving networks. The combination of ablation-based diagnosis, attention-level diagnostics, and empirical gains on shifted datasets provides a coherent empirical narrative; the reference implementation DiffDyG further aids reproducibility.
major comments (1)
- Ablation study (described in the abstract and §4): the contrast between structurally/temporally distinguished historical neighbors and random ones does not report matching the random baseline on node degree, recency, or embedding similarity. Without such controls, observed performance gaps could be explained by these established confounders rather than the existence of a privileged critical-node class, weakening the empirical support for the claim that existing Transformers fail to focus on critical nodes even when present.
minor comments (2)
- Experimental results would benefit from reporting error bars, exact statistical tests, and a more complete experimental protocol to allow readers to assess the reliability of the reported consistent gains.
- Notation for differential attention could be clarified with an explicit equation or pseudocode block early in the methods section to make the mechanism easier to implement from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our diagnosis of attention dispersion in CTDG Transformers. We address the single major comment below and will revise the manuscript to incorporate additional controls in the ablation study.
read point-by-point responses
-
Referee: Ablation study (described in the abstract and §4): the contrast between structurally/temporally distinguished historical neighbors and random ones does not report matching the random baseline on node degree, recency, or embedding similarity. Without such controls, observed performance gaps could be explained by these established confounders rather than the existence of a privileged critical-node class, weakening the empirical support for the claim that existing Transformers fail to focus on critical nodes even when present.
Authors: We agree that matching the random baseline on node degree, recency, and embedding similarity would provide a stronger control and help rule out these potential confounders. In the revised manuscript we will add new ablation experiments in §4 that sample random neighbors to match the empirical distributions of these three properties within each critical-node set. This will isolate the contribution of structural and temporal distinction more cleanly. We expect the performance gap to persist under these matched conditions, but we will report the results transparently regardless of outcome. revision: yes
Circularity Check
No significant circularity: empirical diagnosis and architectural modification remain independent of inputs
full rationale
The paper's chain consists of an empirical observation of attention dispersion under temporal shift, a controlled ablation showing predictive value of distinguished historical neighbors, and the introduction of differential attention as a fix. No equations or derivations reduce a claimed prediction to a fitted parameter or self-citation by construction. The ablation and benchmark results are presented as falsifiable measurements rather than tautological outputs. Self-citations, if present, are not load-bearing for the central diagnosis. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Critical nodes carry consistently more predictive signal than arbitrary neighbors
invented entities (1)
-
differential attention
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
replace standard attention with differential attention, which subtracts two softmax attention maps... suppresses common-mode attention and amplifies distinctive token-level signals
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
critical nodes... structural centrality... temporal stability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Ainslie, J. Lee-Thorp, M. de Jong, Y . Zemlyanskiy, F. Lebrón, and S. Sanghai. GQA: training generalized multi-query transformer models from multi-head checkpoints. InProc. EMNLP, pages 4895–4901. Association for Computational Linguistics, 2023
work page 2023
- [2]
- [3]
-
[4]
W. Cong, S. Zhang, J. Kang, B. Yuan, H. Wu, X. Zhou, H. Tong, and M. Mahdavi. Do we really need complicated model architectures for temporal networks? InProc. ICLR. OpenReview.net, 2023
work page 2023
-
[5]
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. InProc. NeurIPS, 2022
work page 2022
-
[6]
A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Schölkopf, and A. Smola. A kernel two-sample test.The journal of machine learning research, 13(1):723–773, 2012
work page 2012
-
[7]
Z. Han, J. Jiang, Y . Wang, Y . Ma, and V . Tresp. The graph hawkes network for reasoning on temporal knowledge graphs. InLearning with Temporal Point Processes Workshop at the 33rd Conference on Neural Information Processing Systems (TPP@ NeurIPS 2019)), 2019
work page 2019
-
[8]
W. Hu, Y . Yang, Z. Cheng, C. Yang, and X. Ren. Time-series event prediction with evolutionary state graph. InProc. WSDM, pages 580–588. ACM, 2021
work page 2021
- [9]
- [10]
- [11]
-
[12]
Y . Li, Y . Shen, L. Chen, and M. Yuan. Zebra: When temporal graph neural networks meet temporal personalized pagerank.Proc. VLDB Endow., 16(6):1332–1345, 2023. 10
work page 2023
-
[13]
X. Lu, L. Sun, T. Zhu, and W. Lv. Improving temporal link prediction via temporal walk matrix projection. InAdvanced in NeurIPS, 2024
work page 2024
- [14]
-
[15]
J. Peng, Z. Wei, and Y . Ye. Tidformer: Exploiting temporal and interactive dynamics makes A great dynamic graph transformer. InProc. KDD, pages 2245–2256. ACM, 2025
work page 2025
-
[16]
F. Poursafaei, S. Huang, K. Pelrine, and R. Rabbany. Towards better evaluation for dynamic link prediction. InAdvanced in NeurIPS, 2022
work page 2022
-
[17]
Temporal Graph Networks for Deep Learning on Dynamic Graphs
E. Rossi, B. Chamberlain, F. Frasca, D. Eynard, F. Monti, and M. M. Bronstein. Temporal graph networks for deep learning on dynamic graphs.CoRR, abs/2006.10637, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
- [18]
-
[19]
A. H. Souza, D. Mesquita, S. Kaski, and V . Garg. Provably expressive temporal graph networks. InAdvanced in NeurIPS, 2022
work page 2022
-
[20]
J. Su, M. H. M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[21]
J. Su, D. Zou, and C. Wu. PRES: toward scalable memory-based dynamic graph neural networks. InICLR. OpenReview.net, 2024
work page 2024
-
[22]
R. Trivedi, H. Dai, Y . Wang, and L. Song. Know-evolve: Deep temporal reasoning for dynamic knowledge graphs. InProc. ICML, volume 70, pages 3462–3471. PMLR, 2017
work page 2017
-
[23]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. InAdvanced in NIPS, pages 5998–6008, 2017
work page 2017
- [24]
-
[25]
X. Wang, D. Lyu, M. Li, Y . Xia, Q. Yang, X. Wang, X. Wang, P. Cui, Y . Yang, B. Sun, and Z. Guo. APAN: asynchronous propagation attention network for real-time temporal graph embedding. InProc. SIGMOD, pages 2628–2638. ACM, 2021
work page 2021
-
[26]
Y . Wang, Y . Chang, Y . Liu, J. Leskovec, and P. Li. Inductive representation learning in temporal networks via causal anonymous walks. InICLR. OpenReview.net, 2021
work page 2021
-
[27]
Y . Wu, Y . Fang, and L. Liao. On the feasibility of simple transformer for dynamic graph modeling. InProc. Web Conference, pages 870–880. ACM, 2024
work page 2024
-
[28]
D. Xu, C. Ruan, E. Körpeoglu, S. Kumar, and K. Achan. Inductive representation learning on temporal graphs. InICLR. OpenReview.net, 2020
work page 2020
-
[29]
T. Ye, L. Dong, Y . Xia, Y . Sun, Y . Zhu, G. Huang, and F. Wei. Differential transformer. InProc. ICLR. OpenReview.net, 2025
work page 2025
-
[30]
J. You, T. Du, and J. Leskovec. ROLAND: graph learning framework for dynamic graphs. In Proc. KDD, pages 2358–2366. ACM, 2022
work page 2022
-
[31]
L. Yu, L. Sun, B. Du, and W. Lv. Towards better dynamic graph learning: New architecture and unified library. InAdvanced in NeurIPS, 2023
work page 2023
-
[32]
Z. Zhao, X. Zhu, T. Xu, A. Lizhiyu, Y . Yu, X. Li, Z. Yin, and E. Chen. Time-interval aware share recommendation via bi-directional continuous time dynamic graphs. InProc. SIGIR, pages 822–831. ACM, 2023
work page 2023
-
[33]
yes” on the same bill. The edge weight equals the number of such shared “yes
T. Zou, Y . Mao, J. Ye, and B. Du. Repeat-aware neighbor sampling for dynamic graph learning. InProc. KDD, pages 4722–4733. ACM, 2024. 11 A Additional experimental details A.1 Details of datasets Table 8:Summary of dynamic graph datasets Datasets Domains #Nodes #Links #Node & Link Feat. Bipartite Duration Time Granularity # Steps Wikipedia Social 9,227 15...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.