TASTE: A Designer-Annotated Multi-Dimensional Preference Dataset for AI-Generated Graphic Design
Pith reviewed 2026-05-21 05:05 UTC · model grok-4.3
The pith
A small pairwise-difference head trained on designer ratings for graphic design reaches 0.611 macro agreement with the five-designer majority.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
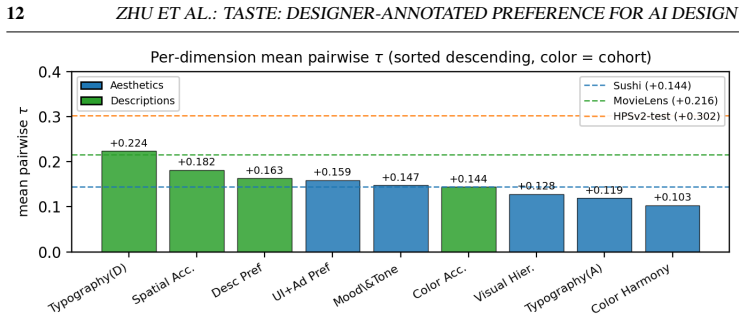
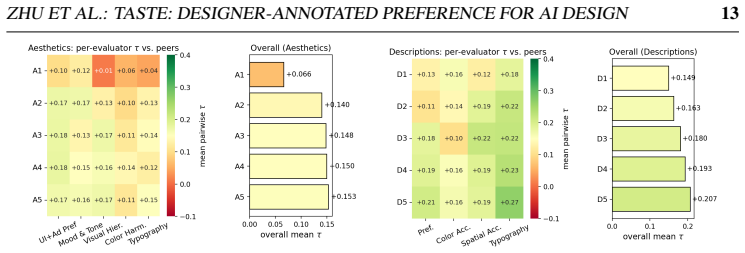
Ten designers supplied 1,600 ratings per criterion plus hallucination flags on two cohorts of images. A criterion-agnostic signal test using Kendall's tau, majority probability, and Condorcet cycles shows designer agreement sits between food preferences and photo-style image quality. No benchmarked pre-trained system exceeds 0.55 macro agreement with the five-designer majority, while a small head trained directly on TASTE reaches 0.611 and thereby closes half the gap to the single-rater ceiling of 0.741.
What carries the argument
The TASTE dataset of multi-criterion designer rankings paired with a small pairwise-difference head that predicts relative preference between image pairs.
If this is right
- Text-to-image systems can be fine-tuned or guided using separate scores for typography, visual hierarchy, and brief fidelity rather than a single overall preference label.
- The same signal-test framework can quantify agreement levels when the same method is applied to other creative domains such as UI design or product photography.
- Future model releases can be ranked by how closely their outputs match the nine separate axes instead of by aggregate human preference.
- The per-image hallucination flags collected on the holistic cohorts provide a direct way to measure and penalize factual or semantic errors in generated layouts.
Where Pith is reading between the lines
- If the multi-axis scores prove additive, an AI design tool could let users dial typography quality independently of color harmony without retraining the generator.
- The dataset's scale of 1,600 ratings per criterion suggests it could serve as a seed for active-learning loops that keep improving the head as more designer labels arrive.
- Extending the same annotation protocol to video or 3-D outputs would test whether the current agreement levels and head performance generalize beyond static graphic design.
Load-bearing premise
The five-designer majority vote on the holistic-preference cohorts serves as a stable and representative target for both measuring and training automated scorers.
What would settle it
Retraining the pairwise-difference head on TASTE and evaluating it on a fresh set of designs from the same four models yields macro agreement no higher than 0.55 with the held-out five-designer majority.
Figures


read the original abstract
Text-to-image models produce graphic design at production scale, but their supervision comes from photo-style preference data with a single overall verdict per comparison. Designers evaluate along several distinct axes, including typography, visual hierarchy, color harmony, layout, and brief fidelity, and a single label collapses them. We release TASTE (Typography, Aesthetics, Spatial, Tone, Etc.): ten professional designers ranked outputs from four current text-to-image models on nine criteria across two disjoint cohorts, yielding 1,600 ratings per criterion plus per-image hallucination flags on the holistic-preference cohorts. We pair the dataset with three contributions. First, a criterion-agnostic signal test framework, using Kendall's tau, majority probability, and Condorcet cycles against exact iid-uniform nulls at p = 4 and R = 5, places designer agreement on graphic design between food and movie preferences and photo-style image quality, with every TASTE criterion rejecting the random-rater null. Second, no pre-trained system in our benchmark, including six open-weight VLM judges from 3B to 33B parameters and three dedicated T2I scorers, HPSv2.1, PickScore-v1, and LAION-Aesthetic-V2, exceeds 0.55 macro agreement with the 5-designer majority; VLM judges trade off position bias against content sensitivity, so scaling moves along this frontier without improving accuracy. Third, a small pairwise-difference head trained on TASTE reaches 0.611, closing roughly half the gap to the 0.741 single-rater ceiling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the TASTE dataset, consisting of rankings by ten professional designers on outputs from four text-to-image models across nine criteria (typography, aesthetics, spatial, tone, etc.) in two cohorts, yielding 1,600 ratings per criterion plus hallucination flags. It presents a criterion-agnostic statistical framework using Kendall's tau, majority probability, and Condorcet cycles against iid-uniform nulls, benchmarks existing VLMs and T2I scorers (none exceeding 0.55 macro agreement with the 5-designer majority), and reports a small pairwise-difference head trained on TASTE achieving 0.611 macro agreement, closing roughly half the gap to the 0.741 single-rater ceiling.
Significance. If the empirical measurements hold, TASTE supplies a much-needed multi-axis preference resource for graphic design that goes beyond single-verdict photo-style data, while the benchmark and new head establish concrete baselines showing current systems fall short and that modest task-specific training can improve alignment with designer judgments on axes such as layout and brief fidelity.
major comments (2)
- [Abstract] Abstract: the headline claim that the pairwise-difference head at 0.611 'closes roughly half the gap' to the 0.741 single-rater ceiling treats the 5-designer majority as a fixed, stable target. The single-rater ceiling already encodes substantial disagreement; without leave-one-out, bootstrap, or per-cohort variance statistics on majority stability, it remains unclear whether the reported improvement is robust or partly an artifact of label noise in the aggregate.
- [Abstract] Abstract and statistical framework section: the signal-test results (every criterion rejects the random-rater null at p=4, R=5) are presented as placing graphic-design agreement between food/movie preferences and photo-style quality, yet the exact data-exclusion rules, inter-rater reliability formula, and handling of ties or missing ratings are not stated, preventing independent verification of the reported agreement numbers.
minor comments (2)
- [Abstract] Abstract: the phrase '1,600 ratings per criterion' should be clarified as total across designers or per cohort to avoid ambiguity.
- [Benchmark] Benchmark section: the architecture, training hyperparameters, and exact loss for the 0.611 head should be reported in more detail to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the robustness and reproducibility of our claims regarding the TASTE dataset and its associated benchmarks. We address each point below and have incorporated revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the pairwise-difference head at 0.611 'closes roughly half the gap' to the 0.741 single-rater ceiling treats the 5-designer majority as a fixed, stable target. The single-rater ceiling already encodes substantial disagreement; without leave-one-out, bootstrap, or per-cohort variance statistics on majority stability, it remains unclear whether the reported improvement is robust or partly an artifact of label noise in the aggregate.
Authors: We agree that quantifying the stability of the 5-designer majority is necessary to substantiate the gap-closure claim. In the revised manuscript we add leave-one-out analyses across the ten designers and bootstrap resampling (1,000 iterations) of the majority labels, both per criterion and per cohort. These show that the macro agreement of 0.611 remains within the reported range relative to the single-rater ceiling of 0.741, with the improvement holding after accounting for label variance. The abstract has been updated to reference these additional statistics. revision: yes
-
Referee: [Abstract] Abstract and statistical framework section: the signal-test results (every criterion rejects the random-rater null at p=4, R=5) are presented as placing graphic-design agreement between food/movie preferences and photo-style quality, yet the exact data-exclusion rules, inter-rater reliability formula, and handling of ties or missing ratings are not stated, preventing independent verification of the reported agreement numbers.
Authors: We acknowledge the omission of these implementation details. The statistical framework section has been expanded to specify: (i) exclusion criteria (images with fewer than three complete rankings or unresolved ties after the tie-breaking protocol are removed), (ii) the inter-rater reliability computation as the average pairwise Kendall's tau with the standard tie correction, and (iii) confirmation that the collected data contain no missing ratings. We also include pseudocode for the exact null-model simulation in the appendix to enable direct replication of the p=4, R=5 rejection results. revision: yes
Circularity Check
No circularity: empirical dataset release and direct measurements on new annotations
full rationale
The paper collects fresh multi-criteria rankings from ten designers on outputs from four T2I models, yielding 1,600 ratings per criterion plus hallucination flags. It computes agreement statistics (Kendall's tau, majority probability, Condorcet cycles) against exact iid-uniform nulls, benchmarks six VLMs and three dedicated scorers against the 5-designer majority on the holistic cohorts, and trains a small pairwise-difference head on TASTE to reach 0.611 macro agreement. No equations, self-definitional loops, or fitted-parameter renamings appear; the reported figures are direct comparisons to the collected labels and standard supervised training on those labels. The derivation chain consists of data collection followed by independent empirical evaluation and model fitting, with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Kendall's tau, majority probability, and Condorcet cycle detection against exact iid-uniform nulls at p=4 and R=5 constitute a valid criterion-agnostic test for signal in preference data.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a small pairwise-difference head trained on TASTE reaches 0.611 macro agreement with the 5-designer majority
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
every TASTE criterion rejecting the random-rater null
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anonymous et al. E-comIQ-ZH: A human-aligned dataset and benchmark for fine- grained evaluation of E-commerce posters with chain-of-thought. arXiv preprint arXiv:2602.21698, 2026
-
[2]
FLUX: Open-source text-to-image generation models
Black Forest Labs. FLUX: Open-source text-to-image generation models. Technical report,https://blackforestlabs.ai, 2024
work page 2024
-
[3]
Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
work page 1952
-
[4]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
work page 1952
-
[5]
Learning vi- sual importance for graphic designs and data visualizations
Zoya Bylinskii, Nam Wook Kim, Peter O’Donovan, Sami Alsheikh, Spandan Madan, Hanspeter Pfister, Fredo Durand, Bryan Russell, and Aaron Hertzmann. Learning vi- sual importance for graphic designs and data visualizations. InProceedings of the 30th Annual ACM Symposium on User Interface Software and Technology (UIST), 2017
work page 2017
-
[6]
Seedream: Native high-resolution bilingual image generation foundation model
ByteDance. Seedream: Native high-resolution bilingual image generation foundation model. Technical report, ByteDance, 2024. 20ZHU ET AL.: TASTE: DESIGNER-ANNOTA TED PREFERENCE FOR AI DESIGN
work page 2024
-
[7]
Zijian Chen, Wei Sun, Yuan Tian, Jun Jia, Zicheng Zhang, Jiarui Wang, Ru Huang, Xiongkuo Min, Guangtao Zhai, and Wenjun Zhang. Exploring the naturalness of AI- generated images.IEEE Transactions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[8]
Graphic-Design-Bench: A Comprehensive Benchmark for Evaluating AI on Graphic Design Tasks
Adrienne Deganutti, Elad Hirsch, Haonan Zhu, Jaejung Seol, and Purvanshi Mehta. Graphic-Design-Bench: A comprehensive benchmark for evaluating AI on graphic de- sign tasks. arXiv preprint arXiv:2604.04192, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Predicting visual importance across graphic design types
Camilo Fosco, Vincent Casser, Amish Kumar Bedi, Peter O’Donovan, Aaron Hertz- mann, and Zoya Bylinskii. Predicting visual importance across graphic design types. arXiv preprint arXiv:2008.02912, 2020
-
[10]
I-HallA: Evaluating image hallucination in text-to-image generation with question answering
Sang gil Lim, Heesoo Jung, Choonghan Kim, Hyunwoo Park, Hwanhee Lee, and Pil- sung Kang. I-HallA: Evaluating image hallucination in text-to-image generation with question answering. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
work page 2025
-
[11]
Imagen and the Nano-Banana image generator
Google DeepMind. Imagen and the Nano-Banana image generator. Technical report, Google DeepMind, 2024
work page 2024
-
[12]
DistortBench: Benchmarking Vision Language Models on Image Distortion Identification
Divyanshu Goyal, Akhil Eppa, and Vanya Bannihatti Kumar. DistortBench: Bench- marking vision language models on image distortion identification.arXiv preprint arXiv:2604.19966, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
F. Maxwell Harper and Joseph A. Konstan. The MovieLens datasets: History and context.ACM Transactions on Interactive Intelligent Systems (TiiS), 5(4):19:1–19:19, 2015
work page 2015
-
[14]
LICA: Lay- ered image composition annotations for graphic design research
Elad Hirsch, Shubham Yadav, Mohit Garg, and Purvanshi Mehta. LICA: Lay- ered image composition annotations for graphic design research. arXiv preprint arXiv:2603.16098, 2026
-
[15]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogniti...
work page 2024
-
[16]
Nantonac collaborative filtering: Recommendation based on order responses
Toshihiro Kamishima. Nantonac collaborative filtering: Recommendation based on order responses. Technical report, ACM SIGKDD, 2003. Sushi preference dataset
work page 2003
-
[17]
Maurice G. Kendall. A new measure of rank correlation.Biometrika, 30(1/2):81–93, 1938
work page 1938
-
[18]
Pick-a-Pic: An open dataset of user preferences for text-to-image generation
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-Pic: An open dataset of user preferences for text-to-image generation. In Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[19]
Klaus Krippendorff. Reliability in content analysis: Some common misconceptions and recommendations.Human Communication Research, 30(3):411–433, 2004. ZHU ET AL.: TASTE: DESIGNER-ANNOTA TED PREFERENCE FOR AI DESIGN21
work page 2004
-
[20]
Klaus Krippendorff.Content Analysis: An Introduction to Its Methodology. SAGE, 4th edition, 2018
work page 2018
-
[21]
GenAI-Bench: Evaluating and improving compositional text-to-visual generation
Baiqi Li, Zhiqiu Lin, Deepak Pathak, Jiayao Li, Yixin Fei, Kewen Wu, Tiffany Ling, Xide Xia, Pengchuan Zhang, Graham Neubig, and Deva Ramanan. GenAI-Bench: Evaluating and improving compositional text-to-visual generation. InAdvances in Neu- ral Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2024
work page 2024
-
[22]
Chunyi Li, Zicheng Zhang, Haoning Wu, Wei Sun, Xiongkuo Min, Xiaohong Liu, Guangtao Zhai, and Weisi Lin. AGIQA-3K: An open database for AI-generated image quality assessment.IEEE Transactions on Circuits and Systems for Video Technology, 2023
work page 2023
-
[23]
AIGIQA-20K: A large database for AI-generated image quality assessment
Chunyi Li, Tengchuan Kou, Yixuan Gao, Yuqin Cao, Wei Sun, Zicheng Zhang, Yingjie Zhou, Zhichao Zhang, Weixia Zhang, Haoning Wu, Xiaohong Liu, Xiongkuo Min, and Guangtao Zhai. AIGIQA-20K: A large database for AI-generated image quality assessment. InCVPR Workshops (NTIRE), 2024
work page 2024
-
[24]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Qwen3- vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multi- modal retrieval and ranking.arXiv, 2026
work page 2026
-
[25]
Rich human feedback for text-to-image generation
Youwei Liang, Junfeng He, Gang Li, Peizhao Li, Arseniy Klimovskiy, Nicholas Car- olan, Jiao Sun, Jordi Pont-Tuset, Sarah Young, Feng Yang, et al. Rich human feedback for text-to-image generation. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[26]
A survey of multimodal hallucination evaluation and detection
Hao Liu et al. A survey of multimodal hallucination evaluation and detection. arXiv preprint arXiv:2507.19024, 2025
-
[27]
Duncan Luce.Individual Choice Behavior: A Theoretical Analysis
R. Duncan Luce.Individual Choice Behavior: A Theoretical Analysis. John Wiley & Sons, 1959
work page 1959
-
[28]
HPSv3: Towards wide- spectrum human preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, Hongsheng Li, et al. HPSv3: Towards wide- spectrum human preference score. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), 2025
work page 2025
-
[29]
C. L. Mallows. Non-null ranking models.Biometrika, 44(1/2):114–130, 1957
work page 1957
-
[30]
GPT-Image and DALL·E 3: Text-to-image generation
OpenAI. GPT-Image and DALL·E 3: Text-to-image generation. Technical report, OpenAI, 2024
work page 2024
-
[31]
Yi-Hao Peng, Jeffrey P. Bigham, and Jason Wu. DesignPref: Capturing personal pref- erences in visual design generation. arXiv preprint arXiv:2511.20513, 2025
- [32]
-
[33]
Manning, Stefano Er- mon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Er- mon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 22ZHU ET AL.: TASTE: DESIGNER-ANNOTA TED PREFERENCE FOR AI DESIGN
work page 2023
-
[34]
Tao Sun et al. ImagenWorld: Stress-testing image generation models with explainable human evaluation on open-ended real-world tasks. arXiv preprint arXiv:2603.27862, 2026
-
[35]
Identifying and mitigating position bias of multi-image vision-language models
Yu Tian, Tianqi Liu, Zhiyuan Liu, Jie Yang, and Cordelia Schmid. Identifying and mitigating position bias of multi-image vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. arXiv:2503.13792
-
[36]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hong- sheng Li. Human Preference Score v2: A solid benchmark for evaluating human pref- erences of text-to-image synthesis. arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
ImageReward: Learning and evaluating human preferences for text-to- image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. ImageReward: Learning and evaluating human preferences for text-to- image generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[38]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qinkai Li, Mingyi Zhang, et al. VisionReward: Fine-grained multi- dimensional human preference learning for image and video generation. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2026
work page 2026
-
[39]
Learning multi-dimensional human preference for text-to-image generation
Sixian Zhang, Bohan Wang, Junqiang Wu, Yan Li, Tingting Gao, Di Zhang, and Zhongyuan Wang. Learning multi-dimensional human preference for text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2024
work page 2024
-
[40]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Wang, Jingwen He, Fan Zhang, Yuanhan Zhang, Jingkang Yang, Yu Qiao, and Ziwei Liu. VBench-2.0: Advancing video gen- eration benchmark suite for intrinsic faithfulness. arXiv preprint arXiv:2503.21755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonza- lez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. In Advances in Neural Information Processing Systems (NeurIPS) Datasets and Bench- marks Track, 2023
work page 2023
-
[42]
From fragment to one piece: A survey on AI-driven graphic design
Xingxing Zou, Wen Zhang, and Nanxuan Zhao. From fragment to one piece: A survey on AI-driven graphic design. arXiv preprint arXiv:2503.18641, 2025. A Statistical definitions This appendix collects the formal definitions, support sets, and null PMFs of the three signal- test statistics introduced in §4. Notation: a sample is one prompt rated byR=5 evaluato...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.