Deltaynamics: Language-Based Representation for Inferring Rigid-Body Dynamics From Videos
Pith reviewed 2026-05-21 06:10 UTC · model grok-4.3
The pith
Language serves as a unified representation to infer rigid-body dynamics from monocular videos via structured text scene configurations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
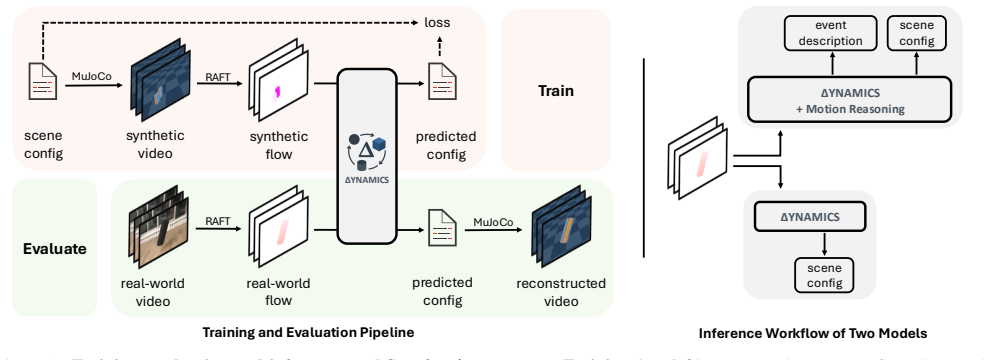
ΔYNAMICS generates scene configurations in a structured text format for physics simulation by leveraging vision-language models enhanced with natural language motion reasoning and optical flow. Instead of predicting parameters directly, the framework produces text outputs that can be simulated, with test-time sampling and evolutionary search providing further gains. This yields a segmentation IoU of 0.30 on CLEVRER, seven times higher than leading VLMs, and demonstrates strong transfer to a new dataset of 235 real-world rigid-body videos.
What carries the argument
structured text scene configurations that act as a language-based interface to physics simulation engines
Load-bearing premise
Generating structured text scene configurations via a vision-language model plus optical flow and evolutionary search will faithfully capture the underlying rigid-body dynamics without requiring explicit physical parameter regression or domain-specific priors.
What would settle it
A collection of videos in which simulations driven by the generated text configurations produce object trajectories that systematically mismatch the motions visible in the input footage would show the representation does not capture the dynamics.
Figures











read the original abstract
Inferring rigid-body physical states and properties from monocular videos is a fundamental step toward physics-based perception and simulation. Existing approaches assume specific underlying physical systems, object types, and camera poses, making them unable to generalize to complex real-world settings. We introduce $\Delta$YNAMICS, a vision-language framework that uses language as a unified representation of rigid-body dynamics. Instead of directly predicting parameters, $\Delta$YNAMICS generates scene configurations in a structured text format for physics simulation. We enhance the model's generalization by integrating natural language motion reasoning and leveraging optical flow as a semantic-agnostic input. On the CLEVRER dataset, $\Delta$YNAMICS achieves a segmentation IoU of 0.30, a 7x improvement over leading VLMs (InternVL3-8B, Qwen2.5-VL-7B and Claude-4-Sonnet). Additionally, test-time sampling and evolutionary search further boost performance by 27% and 120% in segmentation IoU, respectively. Finally, we demonstrate strong transfer to a new dataset of 235 real-world rigid-body videos, highlighting the potential of language-driven physics inference for bridging perception and simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ΔYNAMICS, a vision-language framework that generates structured textual scene configurations from monocular videos by combining VLM-based reasoning, optical flow, and evolutionary search; these configurations are intended as input to a physics simulator for inferring rigid-body dynamics without domain-specific priors. It reports a segmentation IoU of 0.30 on CLEVRER (7× over leading VLMs), additional gains from test-time sampling (+27%) and evolutionary search (+120%), and transfer performance on a new collection of 235 real-world rigid-body videos.
Significance. If the generated text configurations are shown to encode dynamic quantities (velocities, collisions, physical parameters) rather than static layout alone, the language-as-representation strategy could offer a flexible route to generalizable physics inference that bridges perception and simulation. The real-video transfer result is a constructive indicator of robustness, but the overall significance for the dynamics-inference claim remains provisional pending metrics that directly test simulation fidelity.
major comments (2)
- [Abstract] Abstract: the headline result is a segmentation IoU of 0.30, yet this metric quantifies object-mask or bounding-box overlap and does not evaluate whether the structured text encodes time-varying rigid-body quantities (initial velocities, angular velocities, restitution, friction) or produces forward simulations whose trajectories match the input video. The 7× gain and real-world transfer claims are therefore inconclusive for the central thesis without a dynamics-specific metric such as mean trajectory error or collision-event accuracy.
- [Experiments] Experiments section: the description of evolutionary search and test-time sampling does not include an ablation or validation step that confirms the inferred text parameters produce physically consistent simulations; it is possible that search is optimizing the reported IoU rather than recovering ground-truth dynamics, leaving open the possibility that performance gains reflect improved static parsing rather than dynamics inference.
minor comments (2)
- [Abstract] Abstract: the relative improvements of 27% and 120% from test-time sampling and evolutionary search are stated without specifying the exact baseline IoU value or whether the percentages are relative or absolute.
- The manuscript does not report error bars, confidence intervals, or statistical significance for the IoU numbers or transfer results.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below, clarifying how our evaluation relates to dynamics inference while acknowledging the value of additional metrics.
read point-by-point responses
-
Referee: [Abstract] the headline result is a segmentation IoU of 0.30, yet this metric quantifies object-mask or bounding-box overlap and does not evaluate whether the structured text encodes time-varying rigid-body quantities (initial velocities, angular velocities, restitution, friction) or produces forward simulations whose trajectories match the input video.
Authors: We agree that segmentation IoU primarily assesses spatial accuracy of the generated configurations. Our structured text format, however, explicitly encodes dynamic quantities (velocities, angular velocities, and interaction parameters) obtained via VLM motion reasoning and optical flow; the IoU therefore serves as a proxy for the fidelity of these full configurations, including their dynamic components. The reported gains and real-video transfer provide supporting evidence that the language representation captures dynamics beyond static layout. We will add a dedicated discussion of this proxy relationship and its limitations in the revised manuscript. revision: partial
-
Referee: [Experiments] the description of evolutionary search and test-time sampling does not include an ablation or validation step that confirms the inferred text parameters produce physically consistent simulations; it is possible that search is optimizing the reported IoU rather than recovering ground-truth dynamics.
Authors: The evolutionary search and test-time sampling refine the full text configuration (including dynamic parameters initialized from motion reasoning) to maximize agreement with the video. While the objective is IoU-based, the underlying parameters target dynamic content. We will include an additional ablation in the revision that evaluates physical consistency by comparing forward-simulated trajectories against available ground-truth motion in CLEVRER, thereby clarifying the contribution to dynamics recovery versus static parsing. revision: yes
Circularity Check
No load-bearing circularity; evaluation uses held-out splits and independent real-world transfer
full rationale
The paper presents a VLM-based pipeline that outputs structured text scene configurations, augmented by optical flow and evolutionary search, then evaluates via segmentation IoU on CLEVRER held-out data plus transfer to a separate 235-video real-world collection. No equations or steps reduce a claimed prediction to a fitted input by construction, nor does any uniqueness theorem or ansatz rely on self-citation chains. The central representation claim is independent of the reported IoU numbers; the metric choice may be weak for dynamics validation but does not create definitional or statistical circularity within the derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The claude 3 model family: Opus, son- net, haiku.https : / / assets
Anthropic. The claude 3 model family: Opus, son- net, haiku.https : / / assets . anthropic . com / m / 61e7d27f8c8f5919 / original / Claude - 3 - Model-Card.pdf, 2024. 6, 7
work page 2024
-
[2]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425– 2433, 2015. 2
work page 2015
-
[3]
Vivit: A video vi- sion transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lu ˇci´c, and Cordelia Schmid. Vivit: A video vi- sion transformer. InICCV, pages 6836–6846, 2021. 6, 7
work page 2021
-
[4]
Vid2param: Modeling of dynamics parameters from video
Martin Asenov, Michael Burke, Daniel Angelov, Todor Davchev, Kartic Subr, and Subramanian Ramamoorthy. Vid2param: Modeling of dynamics parameters from video. IEEE Robotics and Automation Letters, 5(2):414–421, 2019. 2
work page 2019
-
[5]
Tayfun Ates, M Samil Atesoglu, Cagatay Yigit, Ilker Kesen, Mert Kobas, Erkut Erdem, Aykut Erdem, Tilbe Goksun, and Deniz Yuret. Craft: A benchmark for causal reasoning about forces and interactions.arXiv preprint arXiv:2012.04293,
-
[6]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Cophy: Counterfactual learning of phys- ical dynamics.arXiv preprint arXiv:1909.12000, 2019
Fabien Baradel, Natalia Neverova, Julien Mille, Greg Mori, and Christian Wolf. Cophy: Counterfactual learning of phys- ical dynamics.arXiv preprint arXiv:1909.12000, 2019. 2
-
[8]
Peter Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, et al. Interaction networks for learning about objects, relations and physics.Advances in neural in- formation processing systems, 29, 2016. 1
work page 2016
-
[9]
Jonas Belouadi, Simone Ponzetto, and Steffen Eger. Detikz- ify: Synthesizing graphics programs for scientific figures and sketches with tikz.Advances in Neural Information Process- ing Systems, 37:85074–85108, 2024. 2
work page 2024
-
[10]
Tikzero: Zero-shot text-guided graphics program synthesis.arXiv preprint arXiv:2503.11509, 2025
Jonas Belouadi, Eddy Ilg, Margret Keuper, Hideki Tanaka, Masao Utiyama, Raj Dabre, Steffen Eger, and Simone Paolo Ponzetto. Tikzero: Zero-shot text-guided graphics program synthesis.arXiv preprint arXiv:2503.11509, 2025. 2
-
[11]
Chat- garment: Garment estimation, generation and editing via large language models
Siyuan Bian, Chenghao Xu, Yuliang Xiu, Artur Grigorev, Zhen Liu, Cewu Lu, Michael J Black, and Yao Feng. Chat- garment: Garment estimation, generation and editing via large language models. InCVPR, pages 2924–2934, 2025. 3
work page 2025
-
[12]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired compar- isons.Biometrika, 39(3/4):324–345, 1952. 1
work page 1952
-
[13]
Go-with-the-flow: Motion- controllable video diffusion models using real-time warped noise
Ryan Burgert, Yuancheng Xu, Wenqi Xian, Oliver Pilarski, Pascal Clausen, Mingming He, Li Ma, Yitong Deng, Lingx- iao Li, Mohsen Mousavi, et al. Go-with-the-flow: Motion- controllable video diffusion models using real-time warped noise. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13–23, 2025. 7, 9
work page 2025
-
[14]
Visual physics: Discovering physical laws from videos.arXiv preprint arXiv:1911.11893, 2019
Pradyumna Chari, Chinmay Talegaonkar, Yunhao Ba, and Achuta Kadambi. Visual physics: Discovering physical laws from videos.arXiv preprint arXiv:1911.11893, 2019. 2
-
[15]
Symbolic graphics programming with large language models.arXiv preprint arXiv:2509.05208, 2025
Yamei Chen, Haoquan Zhang, Yangyi Huang, Zeju Qiu, Kaipeng Zhang, Yandong Wen, and Weiyang Liu. Symbolic graphics programming with large language models.arXiv preprint arXiv:2509.05208, 2025. 2
-
[16]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 2
work page 2024
-
[17]
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang. Physbench: Benchmarking and enhancing vision-language models for physical world under- standing.arXiv preprint arXiv:2501.16411, 2025. 2
-
[18]
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tri- pathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art multimodal models.arXiv e-prints, pages arXiv–2409, 2024. 2
work page 2024
-
[19]
Mingyu Ding, Zhenfang Chen, Tao Du, Ping Luo, Josh Tenenbaum, and Chuang Gan. Dynamic visual reasoning by learning differentiable physics models from video and lan- guage.Advances in Neural Information Processing Systems, 34:887–899, 2021. 2
work page 2021
-
[20]
Unsupervised intuitive physics from visual ob- servations
Sebastien Ehrhardt, Aron Monszpart, Niloy Mitra, and An- drea Vedaldi. Unsupervised intuitive physics from visual ob- servations. InAsian Conference on Computer Vision, pages 700–716. Springer, 2018. 1
work page 2018
-
[21]
Brax–a differentiable physics engine for large scale rigid body simulation,
C Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. Brax–a differentiable physics engine for large scale rigid body simulation.arXiv preprint arXiv:2106.13281, 2021. 3
-
[22]
Hiroki Furuta, Kuang-Huei Lee, Shixiang Shane Gu, Yutaka Matsuo, Aleksandra Faust, Heiga Zen, and Izzeddin Gur. Geometric-averaged preference optimization for soft pref- erence labels.Advances in Neural Information Processing Systems, 37:57076–57114, 2024. 2
work page 2024
-
[23]
Alejandro Casta ˜neda Garcia, Jan Warchocki, Jan van Gemert, Daan Brinks, and Nergis Tomen. Learning physics from video: Unsupervised physical parameter estimation for continuous dynamical systems. InCVPR, pages 27924– 27933, 2025. 2
work page 2025
-
[24]
Blendergym: Benchmarking foundational model systems for graphics editing
Yunqi Gu, Ian Huang, Jihyeon Je, Guandao Yang, and Leonidas Guibas. Blendergym: Benchmarking foundational model systems for graphics editing. InCVPR, pages 18574– 18583, 2025. 3
work page 2025
-
[25]
Nikolaus Hansen and Andreas Ostermeier. Adapting arbi- trary normal mutation distributions in evolution strategies: The covariance matrix adaptation. InProceedings of IEEE international conference on evolutionary computation, pages 312–317. IEEE, 1996. 5
work page 1996
-
[26]
Learning articulated rigid body dynamics simulations from video
Eric Heiden, Ziang Liu, Vibhav Vineet, Erwin Coumans, and Gaurav Sukhatme. Learning articulated rigid body dynamics simulations from video. InICLR Workshop on the Elements of Reasoning: Objects, Structure and Causality, 2022. 2 9
work page 2022
-
[27]
Difftaichi: Differentiable programming for physical simulation.arXiv preprint arXiv:1910.00935, 2019
Yuanming Hu, Luke Anderson, Tzu-Mao Li, Qi Sun, Nathan Carr, Jonathan Ragan-Kelley, and Fr´edo Durand. Difftaichi: Differentiable programming for physical simulation.arXiv preprint arXiv:1910.00935, 2019. 3
-
[28]
Zhiao Huang, Yuanming Hu, Tao Du, Siyuan Zhou, Hao Su, Joshua B Tenenbaum, and Chuang Gan. Plasticinelab: A soft-body manipulation benchmark with differentiable physics.arXiv preprint arXiv:2104.03311, 2021. 3
-
[29]
Krishna Murthy Jatavallabhula, Miles Macklin, Florian Golemo, Vikram V oleti, Linda Petrini, Martin Weiss, Brean- dan Considine, J ´erˆome Parent-L´evesque, Kevin Xie, Kenny Erleben, et al. gradsim: Differentiable simulation for sys- tem identification and visuomotor control.arXiv preprint arXiv:2104.02646, 2021. 3
-
[30]
James R Kubricht, Keith J Holyoak, and Hongjing Lu. Intu- itive physics: Current research and controversies.Trends in cognitive sciences, 21(10):749–759, 2017. 1
work page 2017
-
[31]
Re-thinking inverse graphics with large language models.arXiv preprint arXiv:2404.15228, 2024
Peter Kulits, Haiwen Feng, Weiyang Liu, Victoria Abrevaya, and Michael J Black. Re-thinking inverse graphics with large language models.arXiv preprint arXiv:2404.15228, 2024. 3
-
[32]
Reconstruct- ing animals and the wild
Peter Kulits, Michael J Black, and Silvia Zuffi. Reconstruct- ing animals and the wild. InCVPR, pages 16565–16577,
-
[33]
Long Le, Jason Xie, William Liang, Hung-Ju Wang, Yue Yang, Yecheng Jason Ma, Kyle Vedder, Arjun Krishna, Di- nesh Jayaraman, and Eric Eaton. Articulate-anything: Auto- matic modeling of articulated objects via a vision-language foundation model.arXiv preprint arXiv:2410.13882, 2024. 5
-
[34]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 2
work page 2023
-
[35]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 2
work page 2024
-
[36]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceed- ings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021. 2
work page 2021
-
[37]
Uniphy: Learning a unified constitutive model for inverse physics simulation
Himangi Mittal, Peiye Zhuang, Hsin-Ying Lee, and Shub- ham Tulsiani. Uniphy: Learning a unified constitutive model for inverse physics simulation. InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 16208–16218, 2025. 3
work page 2025
-
[38]
Yi-Ling Qiao, Alexander Gao, and Ming Lin. Neu- physics: Editable neural geometry and physics from monoc- ular videos.Advances in Neural Information Processing Sys- tems, 35:12841–12854, 2022. 3
work page 2022
-
[39]
Nazneen Fatema Rajani, Rui Zhang, Yi Chern Tan, Stephan Zheng, Jeremy Weiss, Aadit Vyas, Abhijit Gupta, Caiming Xiong, Richard Socher, and Dragomir Radev. Esprit: Ex- plaining solutions to physical reasoning tasks.arXiv preprint arXiv:2005.00730, 2020. 2
-
[40]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Ronan Riochet, Mario Ynocente Castro, Mathieu Bernard, Adam Lerer, Rob Fergus, V ´eronique Izard, and Emmanuel Dupoux. Intphys 2019: A benchmark for visual intuitive physics understanding.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 44(9):5016–5025, 2021. 2
work page 2019
-
[42]
Starvector: Gener- ating scalable vector graphics code from images and text
Juan A Rodriguez, Abhay Puri, Shubham Agarwal, Issam H Laradji, Pau Rodriguez, Sai Rajeswar, David Vazquez, Christopher Pal, and Marco Pedersoli. Starvector: Gener- ating scalable vector graphics code from images and text. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 16175–16186, 2025. 2
work page 2025
-
[43]
Aligning text, images, and 3d structure token-by-token
Aadarsh Sahoo, Vansh Tibrewal, and Georgia Gkioxari. Aligning text, images, and 3d structure token-by-token. arXiv preprint arXiv:2506.08002, 2025. 5
-
[44]
Soft preference opti- mization: Aligning language models to expert distributions
Arsalan Sharifnassab, Saber Salehkaleybar, Sina Ghiassian, Surya Kanoria, and Dale Schuurmans. Soft preference opti- mization: Aligning language models to expert distributions. arXiv preprint arXiv:2405.00747, 2024. 2
-
[45]
Preference rank- ing optimization for human alignment
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. Preference rank- ing optimization for human alignment. InProceedings of the AAAI Conference on Artificial Intelligence, pages 18990– 18998, 2024. 5, 1
work page 2024
-
[46]
Yiren Song, Danze Chen, and Mike Zheng Shou. Layer- tracer: Cognitive-aligned layered svg synthesis via diffusion transformer.arXiv preprint arXiv:2502.01105, 2025. 2
-
[47]
Priya Sundaresan, Rika Antonova, and Jeannette Bohgl. Dif- fcloud: Real-to-sim from point clouds with differentiable simulation and rendering of deformable objects. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10828–10835. IEEE, 2022. 3
work page 2022
-
[48]
Cheng Tan, Qi Chen, Jingxuan Wei, Gaowei Wu, Zhangyang Gao, Siyuan Li, Bihui Yu, Ruifeng Guo, and Stan Z Li. Sketchagent: Generating structured diagrams from hand- drawn sketches.arXiv preprint arXiv:2508.01237, 2025. 2
-
[49]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InECCV, pages 402–419. Springer, 2020. 3, 4, 5, 7
work page 2020
-
[50]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012. 2, 4
work page 2012
-
[51]
Nicholas Watters, Daniel Zoran, Theophane Weber, Peter Battaglia, Razvan Pascanu, and Andrea Tacchetti. Visual interaction networks: Learning a physics simulator from video.Advances in neural information processing systems, 30, 2017. 1
work page 2017
-
[52]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Galileo: Perceiving physical object prop- erties by integrating a physics engine with deep learning
Jiajun Wu, Ilker Yildirim, Joseph J Lim, Bill Freeman, and Josh Tenenbaum. Galileo: Perceiving physical object prop- erties by integrating a physics engine with deep learning. NeurIPS, 28, 2015. 2 10
work page 2015
-
[54]
Learning to see physics via visual de- animation.NeurIPS, 30, 2017
Jiajun Wu, Erika Lu, Pushmeet Kohli, Bill Freeman, and Josh Tenenbaum. Learning to see physics via visual de- animation.NeurIPS, 30, 2017. 2
work page 2017
-
[55]
Chat2svg: Vec- tor graphics generation with large language models and im- age diffusion models
Ronghuan Wu, Wanchao Su, and Jing Liao. Chat2svg: Vec- tor graphics generation with large language models and im- age diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23690–23700,
-
[56]
Svgdreamer: Text guided svg gener- ation with diffusion model
Ximing Xing, Haitao Zhou, Chuang Wang, Jing Zhang, Dong Xu, and Qian Yu. Svgdreamer: Text guided svg gener- ation with diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4546–4555, 2024
work page 2024
-
[57]
Ximing Xing, Qian Yu, Chuang Wang, Haitao Zhou, Jing Zhang, and Dong Xu. Svgdreamer++: Advancing editability and diversity in text-guided svg generation.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2025. 2
work page 2025
-
[58]
Ppr: Physically plausible re- construction from monocular videos
Gengshan Yang, Shuo Yang, John Z Zhang, Zachary Manch- ester, and Deva Ramanan. Ppr: Physically plausible re- construction from monocular videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3914–3924, 2023. 3
work page 2023
-
[59]
CLEVRER: CoLlision Events for Video REpresentation and Reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning. arXiv preprint arXiv:1910.01442, 2019. 1, 2, 6, 7, 5
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[60]
The scene language: Representing scenes with programs, words, and embeddings
Yunzhi Zhang, Zizhang Li, Matt Zhou, Shangzhe Wu, and Jiajun Wu. The scene language: Representing scenes with programs, words, and embeddings. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24625–24634, 2025. 3
work page 2025
-
[61]
Wang Zhao, Yan-Pei Cao, Jiale Xu, Yuejiang Dong, and Ying Shan. Di-pcg: Diffusion-based efficient inverse pro- cedural content generation for high-quality 3d asset creation. InCVPR, pages 11061–11072, 2025. 3
work page 2025
-
[62]
Xian Zhou, Yiling Qiao, Zhenjia Xu, TH Wang, Z Chen, J Zheng, Z Xiong, Y Wang, M Zhang, P Ma, et al. Genesis: A generative and universal physics engine for robotics and beyond.arXiv preprint arXiv:2401.01454, 2024. 5
-
[63]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 5, 7 11 ∆YNAMICS: Language-Based Representation for Inferring Rigid-Body Dynamics From Videos Sup...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.