LT2: Linear-Time Looped Transformers
Pith reviewed 2026-05-21 06:07 UTC · model grok-4.3
The pith
Looped transformers can use linear and sparse attention to run in linear time while matching or exceeding the performance of standard looped transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LT2 introduces looped architectures with linear-time attention that synergize looping with subquadratic mechanisms for iterative refinement and receptive field growth. The LT2-hybrid (Full+GDN) variant surpasses the standard looped transformer in both performance and efficiency. Converting a pre-trained LT yields the Ouro-hybrid-1.4B model, which outperforms industry 1B models and competes with 4B models while preserving linear-time speed advantages.
What carries the argument
The looped structure combined with linear-time attention variants such as GDN and DSA, where iteration enables memory refinement and progressive context expansion.
If this is right
- Looping with linear attention allows iterative memory updates at constant cost per step.
- Hybrid interleaving of full and linear attention maximizes quality gains while keeping overall linear complexity.
- Pre-trained looped transformers can be efficiently converted to LT2-hybrid form with about 1B tokens of additional training.
- The resulting models retain speed benefits of linear-time attention while achieving competitive performance on language modeling tasks.
Where Pith is reading between the lines
- These designs could extend to other sequence models to reduce quadratic bottlenecks in long contexts.
- Testing the conversion on different base models might reveal how broadly the efficiency gains apply.
- The synergy observed suggests that iteration can compensate for reduced attention expressivity in efficient variants.
Load-bearing premise
That the synergy between looping and linear or sparse attention observed in specific recall, state-tracking, and language modeling tasks will generalize to other domains and larger scales.
What would settle it
Observing that on a held-out task the LT2-hybrid requires more compute to reach the same accuracy as the standard looped transformer, or that the converted model underperforms the claimed comparisons to industry models.
Figures



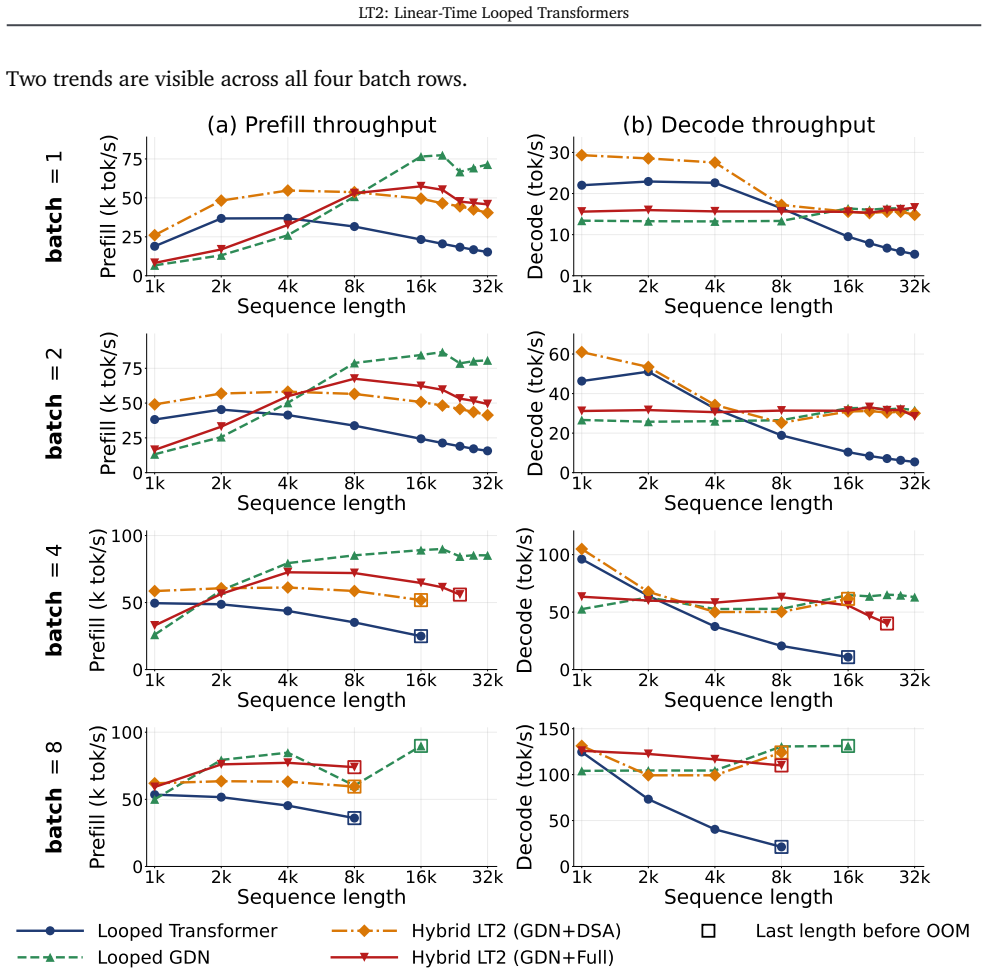
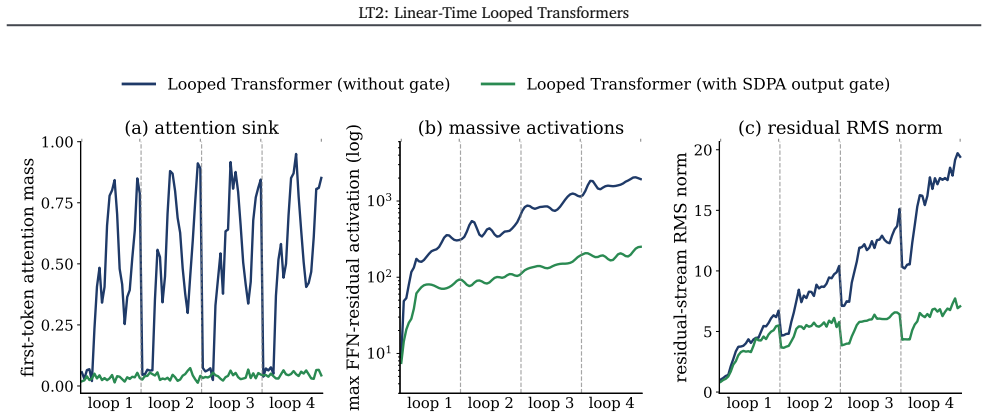






read the original abstract
Looped Transformers (LT) have emerged as a powerful architecture by iterating their layers multiple times before decoding the final token. However, pairing them with full attention retains quadratic complexity, making them computationally expensive and slow. We introduce LT2 (Linear-Time Looped Transformers), a family of looped architectures that replace quadratic softmax attention with subquadratic, linear-time attention. We study two variants: LT2-linear with linear attention and LT2-sparse with sparse attention. We find that looping uniquely synergizes with these variants: it enables iterative memory refinement in linear attention and progressively expands the effective receptive field in sparse attention. We formalize these benefits theoretically and demonstrate consistent empirical gains across controlled recall, state-tracking, and language modeling tasks. We then explore LT2-hybrid, which combines different attention variants in a looped setting. Two variants are especially promising: LT2-hybrid (GDN+DSA), which interleaves linear and sparse attention to maximize efficiency and matches the standard looped transformer's quality at fully linear-time cost; and LT2-hybrid (Full+GDN), which interleaves GDN with a small fraction of full attention layers to maximize quality, surpassing the standard looped transformer in both performance and efficiency. We also show how to convert a pre-trained LT into an LT2-hybrid model. With about 1B tokens of training, our converted model, Ouro-hybrid-1.4B, outperforms industry-level 1B models and is competitive with industry-level 4B models while retaining the speed benefits of linear-time attention. Together, these results show a clear path toward making looped transformers more scalable and advancing efficient, capable small language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LT2, a family of looped transformer architectures that replace quadratic full attention with subquadratic linear-time mechanisms (linear attention and sparse attention). It claims that looping uniquely synergizes with these mechanisms—enabling iterative memory refinement for linear attention and progressive receptive-field expansion for sparse attention—formalizes these benefits theoretically, and reports consistent empirical gains on controlled recall, state-tracking, and language modeling tasks. The work further explores LT2-hybrid variants, highlighting LT2-hybrid (Full+GDN) as surpassing standard looped transformers in both performance and efficiency, and presents a conversion procedure from pre-trained looped transformers to an Ouro-hybrid-1.4B model that outperforms industry 1B-scale models and competes with 4B-scale models while retaining linear-time benefits.
Significance. If the central claims hold under rigorous controls, this work offers a practical route to scaling looped transformers beyond quadratic costs, with direct relevance to efficient small language models. The conversion procedure from pre-trained LTs is a notable strength for real-world applicability, and the hybrid interleaving approach could influence future efficient architecture design. The theoretical formalization, if it provides non-circular derivations of the synergy effects, would strengthen the contribution beyond pure empirics.
major comments (2)
- [§4] §4 (Experimental Results) and associated tables: The claim that looping 'uniquely synergizes' with linear/sparse attention to produce gains beyond the attention mechanisms themselves is load-bearing for the hybrid superiority and conversion justification, yet the manuscript does not report non-looped LT2-linear and LT2-sparse baselines under matched total FLOPs or effective depth. Without these controls, the reported improvements on recall and state-tracking tasks cannot be confidently attributed to the iterative looping rather than the choice of GDN/DSA attention, directly affecting the central synergy argument.
- [§3] §3 (Theoretical Formalization): The formalization of iterative memory refinement and receptive-field expansion is presented as a key contribution, but the manuscript does not include explicit derivations or equations demonstrating that these effects require multiple loop iterations rather than arising from a single pass of the same subquadratic attention; this leaves the 'unique' synergy claim at risk of being an interpretation rather than a derived necessity.
minor comments (3)
- [Abstract] Abstract and §4: Dataset sizes, number of runs, and error bars are not reported for the empirical results on recall, state-tracking, and language modeling tasks; including these would allow readers to assess the reliability of the consistent gains.
- [§4.3] §4.3 (Hybrid Exploration): The selection of the two 'especially promising' hybrids after exploration is noted without reporting results for all explored combinations or pre-specifying the candidates; this introduces potential post-hoc emphasis that should be addressed by either reporting the full search or justifying the selection criteria a priori.
- Conversion procedure description: More precise details on the 1B tokens of training (e.g., data distribution, learning rate schedule, and whether the base LT weights are frozen) would clarify the efficiency claims for the Ouro-hybrid-1.4B model.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The two major comments raise valid points about strengthening the evidence for the claimed synergy between looping and subquadratic attention mechanisms. We address each comment below and have revised the manuscript accordingly to incorporate additional controls and derivations.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Results) and associated tables: The claim that looping 'uniquely synergizes' with linear/sparse attention to produce gains beyond the attention mechanisms themselves is load-bearing for the hybrid superiority and conversion justification, yet the manuscript does not report non-looped LT2-linear and LT2-sparse baselines under matched total FLOPs or effective depth. Without these controls, the reported improvements on recall and state-tracking tasks cannot be confidently attributed to the iterative looping rather than the choice of GDN/DSA attention, directly affecting the central synergy argument.
Authors: We agree that explicit non-looped LT2 baselines under matched compute are necessary to isolate the contribution of looping. The original experiments included comparisons against standard looped full-attention models and single-pass full-attention baselines, but did not tabulate non-looped LT2-linear and LT2-sparse variants with FLOPs or effective depth matched to the multi-iteration versions. In the revised manuscript we have added these controls in §4 and the associated tables: for each task we report single-pass LT2-linear and LT2-sparse models whose width or depth was increased to equalize total FLOPs with the looped counterparts. The new results show that the looped versions still outperform the matched non-looped variants, providing direct support for the synergy claim. We have also clarified the compute-matching procedure in the experimental setup. revision: yes
-
Referee: [§3] §3 (Theoretical Formalization): The formalization of iterative memory refinement and receptive-field expansion is presented as a key contribution, but the manuscript does not include explicit derivations or equations demonstrating that these effects require multiple loop iterations rather than arising from a single pass of the same subquadratic attention; this leaves the 'unique' synergy claim at risk of being an interpretation rather than a derived necessity.
Authors: We appreciate the referee’s observation. While §3 presents formal arguments for memory refinement under linear attention and receptive-field growth under sparse attention, the necessity of multiple iterations versus a single pass was not derived in full detail. In the revised version we have expanded §3 with explicit step-by-step derivations: for the linear-attention case we now include a recurrence showing that the fixed-point residual decreases only after repeated applications; for the sparse-attention case we derive the growth of the effective receptive field as a function of iteration count, proving that a single pass cannot achieve the same coverage. These additions make the requirement for looping a derived property rather than an interpretation. revision: yes
Circularity Check
No circularity: claims rest on new architectural variants and empirical results
full rationale
The paper introduces LT2 variants by replacing quadratic attention with linear/sparse mechanisms in a looped setting, then reports empirical gains on recall, state-tracking, and language modeling tasks plus a conversion procedure from pre-trained LT models. No equations or derivations in the abstract or described content reduce a claimed prediction or theoretical benefit to a fitted parameter or self-referential definition by construction. Theoretical formalization of synergy is presented as analysis of the new architecture rather than tautological renaming or imported uniqueness from self-citations. The central results depend on reported experiments and practical conversion with additional training tokens, which are independent of the input definitions.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of loop iterations
- hybrid mixing ratio
axioms (1)
- domain assumption Linear and sparse attention mechanisms can be iterated without destabilizing training dynamics when combined with standard layer normalization.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
looping uniquely synergizes with these variants: it enables iterative memory refinement in linear attention and progressively expands the effective receptive field in sparse attention
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3 forcing) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
T loops of a window-w block reach as far back as T stacked layers of window-w attention but with T× fewer parameters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
J. Ba, G. Hinton, V. Mnih, J. Z. Leibo, and C. Ionescu. Using fast weights to attend to the recent past, 2016
work page 2016
-
[3]
S. Bae, A. Fisch, H. Harutyunyan, Z. Ji, S. Kim, and T. Schuster. Relaxed recursive transformers: Effective parameter sharing with layer-wise lora, 2025
work page 2025
-
[4]
S. Bae, Y. Kim, R. Bayat, S. Kim, J. Ha, T. Schuster, A. Fisch, H. Harutyunyan, Z. Ji, A. Courville, et al. Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation. In The Thirty-Ninth Annual Conference on Neural Information Processing Systems. NeurIPS, 2025
work page 2025
-
[5]
S. Bai, J. Z. Kolter, and V. Koltun. Deep equilibrium models, 2019
work page 2019
-
[6]
H. Blayney, Álvaro Arroyo, J. Obando-Ceron, P. S. Castro, A. Courville, M. M. Bronstein, and X. Dong. A mechanistic analysis of looped reasoning language models, 2026
work page 2026
-
[7]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amod...
work page 2020
-
[8]
G. Chen, D. Liu, and J. Shao. Loop as a bridge: Can looped transformers truly link representation space and natural language outputs?, 2026
work page 2026
-
[9]
L. Chen, D. Xu, C. An, X. Wang, Y. Zhang, J. Chen, Z. Liang, F. Wei, J. Liang, Y. Xiao, and W. Wang. Powerattention: Exponentially scaling of receptive fields for effective sparse attention, 2025
work page 2025
-
[10]
Y. Chen, N. Gu, J. Shang, Z. Zhang, Y. Feng, J. Sheng, T. Liu, S. Wang, Y. Sun, H. Wu, and H. Wang. Mixture of universal experts: Scaling virtual width via depth-width transformation, 2026
work page 2026
-
[11]
R. Csordás, K. Irie, and J. Schmidhuber. The devil is in the detail: Simple tricks improve systematic generalization of transformers. In M.-F. Moens, X. Huang, L. Specia, and S. W.-t. Yih, editors, 16 LT2: Linear-Time Looped Transformers Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 619–634, Online and Punta...
work page 2021
-
[12]
R. Csordás, K. Irie, J. Schmidhuber, C. Potts, and C. D. Manning. Moeut: Mixture-of-experts universal transformers.Advances in Neural Information Processing Systems, 37:28589–28614, 2024
work page 2024
-
[13]
T. Dao. Flashattention-2: Faster attention with better parallelism and work partitioning, 2023
work page 2023
- [14]
-
[15]
DeepSeek-AI, A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong, C. Lu, C. Zhao, C. Deng, C. Xu, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, E. Li, F. Zhou, F. Lin, F. Dai, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Li, H. Liang, H. Wei, H. Zhang, H. Luo, H. Ji, H. Ding, H. Tang, H. Cao, H. Gao, H. Qu, H. Zeng, and et al. Dee...
work page 2025
-
[16]
M. Dehghani, S. Gouws, O. Vinyals, J. Uszkoreit, and Łukasz Kaiser. Universal transformers, 2019
work page 2019
-
[17]
D. Dua, Y. Wang, P. Dasigi, G. Stanovsky, S. Singh, and M. Gardner. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs, 2019
work page 2019
-
[18]
Y. Fan, Y. Du, K. Ramchandran, and K. Lee. Looped transformers for length generalization. InThe Thirteenth International Conference on Learning Representations
-
[19]
Z. Gao, L. Chen, Y. Xiao, H. Xing, R. Tao, H. Luo, J. Zhou, and B. Dai. Universal reasoning model, 2025
work page 2025
-
[20]
K. Gatmiry, N. Saunshi, S. J. Reddi, S. Jegelka, and S. Kumar. On the role of depth and looping for in-context learning with task diversity
-
[21]
K. Gatmiry, N. Saunshi, S. J. Reddi, S. Jegelka, and S. Kumar. Can looped transformers learn to implement multi-step gradient descent for in-context learning? InInternational Conference on Machine Learning, pages 15130–15152. PMLR, 2024
work page 2024
-
[22]
J. Geiping, X. Yang, and G. Su. Efficient parallel samplers for recurrent-depth models and their connection to diffusion language models, 2025
work page 2025
-
[23]
A. Giannou, S. Rajput, J.-y. Sohn, K. Lee, J. D. Lee, and D. Papailiopoulos. Looped transformers as programmable computers. InInternational Conference on Machine Learning, pages 11398–11442. PMLR, 2023
work page 2023
-
[24]
D. Goldstein, E. Alcaide, J. Lu, and E. Cheah. Radlads: Rapid attention distillation to linear attention decoders at scale, 2026
work page 2026
-
[25]
Z. Gong, Y. Liu, and J. Teng. What makes looped transformers perform better than non-recursive ones, 2026
work page 2026
- [26]
- [27]
-
[28]
E. Guha, R. Marten, S. Keh, N. Raoof, G. Smyrnis, H. Bansal, M. Nezhurina, J. Mercat, T. Vu, Z. Sprague, A. Suvarna, B. Feuer, L. Chen, Z. Khan, E. Frankel, S. Grover, C. Choi, N. Muennighoff, S. Su, W. Zhao, J. Yang, S. Pimpalgaonkar, K. Sharma, C. C.-J. Ji, Y. Deng, S. Pratt, V. Ramanujan, J. Saad-Falcon, J. Li, A. Dave, A. Albalak, K. Arora, B. Wulfe, ...
work page 2025
-
[29]
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L. Sifre. Training compute-optimal large language models, 2022
work page 2022
- [30]
-
[31]
K. Irie, I. Schlag, R. Csordás, and J. Schmidhuber. Going beyond linear transformers with recurrent fast weight programmers, 2021
work page 2021
-
[32]
A. Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks, 2025
work page 2025
- [33]
- [34]
-
[35]
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret. Transformers are rnns: Fast autoregressive transformerswithlinearattention. InInternationalconferenceonmachinelearning,pages5156–5165. PMLR, 2020
work page 2020
- [36]
-
[37]
T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Lee, K. Toutanova, L. Jones, M. Kelcey, M.-W. Chang, A. M. Dai, J. Uszkoreit, Q. Le, and S. Petrov. Natural questions: A benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:452–466, 2019
work page 2019
- [38]
-
[39]
J. Li, A. Fang, G. Smyrnis, M. Ivgi, M. Jordan, S. Gadre, H. Bansal, E. Guha, S. Keh, K. Arora, S. Garg, R. Xin, N. Muennighoff, R. Heckel, J. Mercat, M. Chen, S. Gururangan, M. Wortsman, A. Albalak, Y. Bitton, M. Nezhurina, A. Abbas, C.-Y. Hsieh, D. Ghosh, J. Gardner, M. Kilian, H. Zhang, R. Shao, S. Pratt, S. Sanyal, G. Ilharco, G. Daras, K. Marathe, A....
work page 2025
-
[40]
Y. Li, S. Yang, S. Tan, M. Mishra, R. Panda, J. Zhou, and Y. Kim. Distilling to hybrid attention models via kl-guided layer selection, 2025. 18 LT2: Linear-Time Looped Transformers
work page 2025
-
[41]
O. Lieber, B. Lenz, H. Bata, G. Cohen, J. Osin, I. Dalmedigos, E. Safahi, S. Meirom, Y. Belinkov, S. Shalev-Shwartz, O. Abend, R. Alon, T. Asida, A. Bergman, R. Glozman, M. Gokhman, A. Manevich, N. Ratner, N. Rozen, E. Shwartz, M. Zusman, and Y. Shoham. Jamba: A hybrid transformer-mamba language model, 2024
work page 2024
-
[42]
W. Luo, Y. Li, R. Urtasun, and R. Zemel. Understanding the effective receptive field in deep convolutional neural networks, 2017
work page 2017
-
[43]
W. Merrill, Y. Li, T. Romero, A. Svete, C. Costello, P. Dasigi, D. Groeneveld, D. Heineman, B. Kuehl, N. Lambert, C. Li, K. Lo, S. Malik, D. Matusz, B. Minixhofer, J. Morrison, L. Soldaini, F. Timbers, P. Walsh, N. A. Smith, H. Hajishirzi, and A. Sabharwal. Olmo hybrid: From theory to practice and back, 2026
work page 2026
-
[44]
Y. Nie, K. Han, H. Li, H. Zhou, T. Guo, E. Wu, X. Chen, and Y. Wang. Versatileffn: Achieving parameter efficiency in llms via adaptive wide-and-deep reuse, 2026
work page 2026
-
[45]
NVIDIA, :, A. Blakeman, A. Grattafiori, A. Basant, A. Gupta, A. Khattar, A. Renduchintala, A. Vavre, A. Shukla, A. Bercovich, A. Ficek, A. Shaposhnikov, A. Kondratenko, A. Bukharin, A. Milesi, A. Taghibakhshi, A. Liu, A. Barton, and et al. Nvidia nemotron 3: Efficient and open intelligence, 2025
work page 2025
- [46]
-
[47]
B. Peng, R. Zhang, D. Goldstein, E. Alcaide, X. Du, H. Hou, J. Lin, J. Liu, J. Lu, W. Merrill, G. Song, K. Tan, S. Utpala, N. Wilce, J. S. Wind, T. Wu, D. Wuttke, and C. Zhou-Zheng. Rwkv-7 "goose" with expressive dynamic state evolution, 2025
work page 2025
-
[48]
H. Prairie, Z. Novack, T. Berg-Kirkpatrick, and D. Y. Fu. Parcae: Scaling laws for stable looped language models, 2026
work page 2026
- [49]
- [50]
-
[51]
Z. Qiu, Z. Wang, B. Zheng, Z. Huang, K. Wen, S. Yang, R. Men, L. Yu, F. Huang, S. Huang, D. Liu, J. Zhou, and J. Lin. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free, 2025
work page 2025
-
[52]
P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang. Squad: 100,000+ questions for machine compre- hension of text, 2016
work page 2016
-
[53]
N. Saunshi, N. Dikkala, Z. Li, S. Kumar, and S. J. Reddi. Reasoning with latent thoughts: On the power of looped transformers, 2025
work page 2025
- [54]
- [55]
-
[56]
W.-J. Shu, X. Qiu, R.-J. Zhu, H. H. Chen, Y. Liu, and H. Yang. Loopvit: Scaling visual arc with looped transformers, 2026. 19 LT2: Linear-Time Looped Transformers
work page 2026
- [57]
-
[58]
M. Sun, X. Chen, J. Z. Kolter, and Z. Liu. Massive activations in large language models, 2024
work page 2024
-
[59]
Y. Sun, L. Dong, S. Huang, S. Ma, Y. Xia, J. Xue, J. Wang, and F. Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
S. Takase and S. Kiyono. Lessons on parameter sharing across layers in transformers. In N. Sa- dat Moosavi, I. Gurevych, Y. Hou, G. Kim, Y. J. Kim, T. Schuster, and A. Agrawal, editors,Proceedings of the Fourth Workshop on Simple and Efficient Natural Language Processing (SustaiNLP), pages 78–90, Toronto, Canada (Hybrid), July 2023. Association for Comput...
work page 2023
-
[61]
S. Tan, Y. Shen, Z. Chen, A. Courville, and C. Gan. Sparse universal transformer. In H. Bouamor, J. Pino, and K. Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natu- ral Language Processing, pages 169–179, Singapore, Dec. 2023. Association for Computational Linguistics
work page 2023
-
[62]
Y. Tay, M. Dehghani, S. Abnar, H. Chung, W. Fedus, J. Rao, S. Narang, V. Tran, D. Yogatama, and D. Metzler. Scaling laws vs model architectures: How does inductive bias influence scaling? In H. Bouamor, J. Pino, and K. Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 12342–12364, Singapore, Dec. 2023. Association ...
work page 2023
-
[63]
K. Team, Y. Zhang, Z. Lin, X. Yao, J. Hu, F. Meng, C. Liu, X. Men, S. Yang, Z. Li, W. Li, E. Lu, W. Liu, Y. Chen, W. Xu, L. Yu, Y. Wang, Y. Fan, L. Zhong, E. Yuan, D. Zhang, Y. Zhang, T. Y. Liu, H. Wang, S. Fang, W. He, S. Liu, Y. Li, J. Su, J. Qiu, B. Pang, J. Yan, Z. Jiang, W. Huang, B. Yin, J. You, C. Wei, Z. Wang, C. Hong, Y. Chen, G. Chen, Y. Wang, H...
work page 2025
-
[64]
Q. Team. Qwen3.5-omni technical report, 2026
work page 2026
- [65]
-
[66]
G. Wang, J. Li, Y. Sun, X. Chen, C. Liu, Y. Wu, M. Lu, S. Song, and Y. A. Yadkori. Hierarchical reasoning model, 2025
work page 2025
-
[67]
G. Xiao. Why stacking sliding windows can’t see very far.https://guangxuanx.com/blog/ stacking-swa.html, 2025
work page 2025
-
[68]
G. Xiao, Y. Tian, B. Chen, S. Han, and M. Lewis. Efficient streaming language models with attention sinks, 2024
work page 2024
-
[69]
L. Yang, K. Lee, R. D. Nowak, and D. Papailiopoulos. Looped transformers are better at learning learning algorithms. InThe Twelfth International Conference on Learning Representations
-
[70]
S. Yang, J. Kautz, and A. Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. arXiv preprint arXiv:2412.06464, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
S. Yang, B. Wang, Y. Shen, R. Panda, and Y. Kim. Gated linear attention transformers with hardware- efficient training. InForty-first International Conference on Machine Learning
-
[72]
S. Yang, B. Wang, Y. Zhang, Y. Shen, and Y. Kim. Parallelizing linear transformers with the delta 20 LT2: Linear-Time Looped Transformers rule over sequence length.Advances in neural information processing systems, 37:115491–115522, 2024
work page 2024
-
[73]
S. Yang and Y. Zhang. Fla: A triton-based library for hardware-efficient implementations of linear attention mechanism, Jan. 2024
work page 2024
-
[74]
C. Yu, X. Shu, Y. Wang, Y. Zhang, H. Wu, Y. Wu, R. Long, Z. Chen, Y. Xu, W. Su, and B. Zheng. Spi- ralformer: Looped transformers can learn hierarchical dependencies via multi-resolution recursion, 2026
work page 2026
-
[75]
J. Yuan, H. Gao, D. Dai, J. Luo, L. Zhao, Z. Zhang, Z. Xie, Y. X. Wei, L. Wang, Z. Xiao, Y. Wang, C. Ruan, M. Zhang, W. Liang, and W. Zeng. Native sparse attention: Hardware-aligned and natively trainable sparse attention, 2025
work page 2025
-
[76]
R.-J. Zhu, Z. Wang, K. Hua, T. Zhang, Z. Li, H. Que, B. Wei, Z. Wen, F. Yin, H. Xing, L. Li, J. Shi, K. Ma, S. Li, T. Kergan, A. Smith, X. Qu, M. Hui, B. Wu, Q. Min, H. Huang, X. Zhou, W. Ye, J. Liu, J. Yang, Y. Shi, C. Lin, E. Zhao, T. Cai, G. Zhang, W. Huang, Y. Bengio, and J. Eshraghian. Scaling latent reasoning via looped language models, 2025. 21 LT2...
work page 2025
-
[77]
We tokenize with the Llama tiktoken tokenizer (vocabulary size128,256) and prepend a BOS and append an EOS token to every document. The data loader runs asynchronously with a prefetch buffer of 1024shards and produces two views per example for downstream consumption. Token budget.Every model is trained for255,000 optimizer steps at sequence length4096. Wi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.