General-Purpose Co-Evolutionary Construction of Parallel Algorithm Portfolios for Multi-Objective Binary Optimization
Pith reviewed 2026-05-19 19:37 UTC · model grok-4.3
The pith
A co-evolutionary method builds parallel algorithm portfolios that apply directly to multiple multi-objective binary optimization problems without custom generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
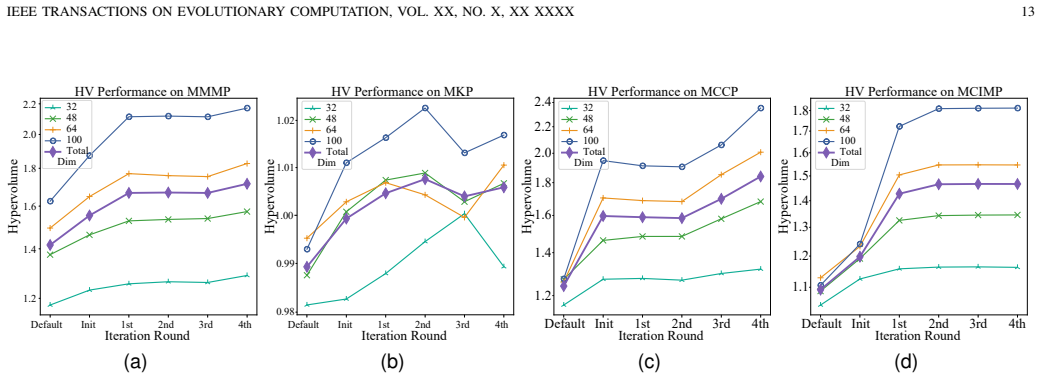
DACMO performs co-evolutionary construction by evolving both problem instances and algorithm operators together. The neural instance representation decouples invariant and specific features so that instances remain consistent within each problem class even as dimensions change. LLM-based generation expands the design space to include new operators. Applied without modification to the multi-objective match max problem, multi-objective knapsack problem, multi-objective contamination control problem, and multi-objective complementary influence maximization problem, the portfolios match or exceed the performance of a privileged baseline that uses hand-crafted instance generators on two of the四个
What carries the argument
The neural instance representation architecture that decouples domain-invariant and instance-specific features to support class-consistent instance generation across varying dimensions.
If this is right
- DACMO applies directly to all four tested problem classes without any modification.
- The constructed portfolios outperform those built from classic multi-objective evolutionary algorithm templates.
- Performance reaches levels comparable to a state-of-the-art baseline that depends on manually designed problem-specific instance generators.
- DACMO exceeds the privileged baseline on two of the four evaluated problem classes.
Where Pith is reading between the lines
- The same decoupling of invariant and specific features could support automated portfolio construction for continuous or combinatorial problems beyond binary cases.
- LLM-driven operator generation might shorten the time needed to adapt portfolios when entirely new objective functions appear in practice.
- Wider adoption could lower the barrier for non-experts to obtain competitive optimization setups for real-world multi-objective tasks.
Load-bearing premise
The neural instance representation successfully decouples domain-invariant features from instance-specific ones so that generated instances stay consistent within each problem class across different dimensions.
What would settle it
Apply DACMO unchanged to a fifth multi-objective binary optimization problem class and measure whether the portfolios still outperform classic MOEA-based portfolios and remain competitive with specialized baselines.
Figures






read the original abstract
Despite recent progress in constructing generalizable parallel algorithm portfolios (PAPs), no general-purpose approach is yet available for multi-objective binary optimization problems (MOBOPs). To fill this gap, this paper proposes domain-agnostic co-evolution of parameterized search for multi-objective binary optimization~(DACMO), which features two technical innovations. First, we propose a neural instance representation architecture that decouples domain-invariant and instance-specific features, enabling class-consistent instance generation across varying dimensions without problem-specific instance generators. Second, we introduce LLM-based automatic search operator generation into PAP construction, extending the search space from parameter tuning of predefined templates to operator-level algorithm design. We evaluate DACMO on four representative MOBOP classes to demonstrate its effectiveness as a general-purpose PAP construction method: the multi-objective match max problem~(MMMP), the multi-objective knapsack problem~(MKP), the multi-objective contamination control problem (MCCP), and the multi-objective complementary influence maximization problem~(MCIMP). Experimental results show that DACMO can be directly applied to all four problem classes without modification, outperforms PAPs built from classic MOEA templates, and achieves performance comparable to a privileged state-of-the-art baseline that relies on manually designed problem-specific instance generators, while outperforming it on two of the four evaluated problem classes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DACMO, a domain-agnostic co-evolutionary method for constructing parallel algorithm portfolios (PAPs) for multi-objective binary optimization problems (MOBOPs). It introduces two innovations: a neural instance representation architecture claimed to decouple domain-invariant and instance-specific features, enabling class-consistent instance generation across varying dimensions without problem-specific generators; and LLM-based automatic search operator generation to extend beyond parameter tuning of predefined templates. The method is evaluated on four MOBOP classes (MMMP, MKP, MCCP, MCIMP), with claims that it applies directly without modification, outperforms classic MOEA-based PAPs, and matches or exceeds a privileged SOTA baseline relying on manual instance generators on two of the four classes.
Significance. If the neural decoupling holds and enables truly modification-free application across MOBOP classes while the LLM operator generation produces effective search operators, the work would advance automated algorithm portfolio construction in evolutionary computation by reducing manual, problem-specific engineering. The co-evolutionary framework combined with LLM-driven design could provide a template for generalizable methods in multi-objective binary optimization, with potential impact on reducing reliance on privileged baselines.
major comments (2)
- [Abstract and method description of neural instance representation] The central claim of direct applicability to all four classes (MMMP, MKP, MCCP, MCIMP) without modification rests on the neural instance representation successfully decoupling domain-invariant from instance-specific features. The manuscript provides no architectural details on input encoding, training regime, or confirmation of a single shared model across classes, leaving open the possibility of hidden class-specific components. This is load-bearing for the 'general-purpose' contribution and the attribution of performance gains.
- [Experimental evaluation and results] The experimental results section reports comparative outcomes on the four problem classes but supplies no details on statistical tests, data splits, ablation studies, or controls for post-hoc selection. Without these, it is not possible to confirm that the reported outperformance over classic MOEA PAPs and the privileged baseline is free of fitting artifacts, undermining the soundness of the performance claims.
minor comments (2)
- [Method overview] Notation for the co-evolutionary components and the LLM operator generation process could be clarified with explicit pseudocode or a diagram to improve reproducibility.
- [Introduction] The abstract and introduction would benefit from a brief statement on the specific MOBOP classes' characteristics to contextualize why they test generality.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our manuscript. These have helped us identify areas where additional clarity and rigor will strengthen the presentation of our contributions. We address each major comment point by point below, with revisions planned where they improve the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and method description of neural instance representation] The central claim of direct applicability to all four classes (MMMP, MKP, MCCP, MCIMP) without modification rests on the neural instance representation successfully decoupling domain-invariant from instance-specific features. The manuscript provides no architectural details on input encoding, training regime, or confirmation of a single shared model across classes, leaving open the possibility of hidden class-specific components. This is load-bearing for the 'general-purpose' contribution and the attribution of performance gains.
Authors: We agree that explicit architectural details are essential to support the decoupling claim and the general-purpose applicability. Section 3.2 of the manuscript describes the neural instance representation as a shared encoder-decoder architecture with a bottleneck that separates domain-invariant features (learned jointly) from instance-specific adapters. Input encoding uses fixed-length binary vectors with padding for varying dimensions, and training employs a joint multi-class objective combining reconstruction and contrastive losses to enforce decoupling. A single model is applied across all four classes, as stated in the experimental protocol. To eliminate any remaining ambiguity and directly address the possibility of hidden class-specific components, we will expand this section in the revision with a detailed diagram, pseudocode for the forward pass and training loop, explicit confirmation of the single shared model, and additional ablation results on the decoupling mechanism. This will provide stronger substantiation for the load-bearing claim. revision: yes
-
Referee: [Experimental evaluation and results] The experimental results section reports comparative outcomes on the four problem classes but supplies no details on statistical tests, data splits, ablation studies, or controls for post-hoc selection. Without these, it is not possible to confirm that the reported outperformance over classic MOEA PAPs and the privileged baseline is free of fitting artifacts, undermining the soundness of the performance claims.
Authors: We acknowledge that the current experimental section would benefit from greater statistical rigor and transparency to rule out fitting artifacts. The original results are based on 30 independent runs with mean and standard deviation reported, but formal tests, splits, and ablations were not included. In the revised manuscript, we will add Wilcoxon signed-rank tests (with Bonferroni correction) for all key comparisons, specify the data splits used for neural representation training (70/30 random split per class on held-out instances), include ablation studies that isolate the neural decoupling component and the LLM operator generation, and document the full configuration search process (including all variants explored) to control for post-hoc selection. These additions will directly support the soundness of the outperformance claims over both classic MOEA PAPs and the privileged baseline. revision: yes
Circularity Check
No significant circularity; claims rest on external empirical benchmarks
full rationale
The paper's central claims concern the empirical effectiveness of DACMO as a general-purpose method, demonstrated via direct application without modification to four distinct MOBOP classes (MMMP, MKP, MCCP, MCIMP) and performance comparisons against classic MOEA templates and a privileged state-of-the-art baseline. These are independent external references, not quantities defined solely in terms of the method's own fitted parameters or internal definitions. The neural instance representation is introduced as an architectural innovation enabling class-consistent generation, but its role is verified through experimental outcomes rather than by self-referential construction or reduction to prior self-citations. No load-bearing derivation step reduces to its inputs by construction, and the paper is self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network hyperparameters
axioms (1)
- domain assumption Domain-invariant and instance-specific features can be reliably separated by the proposed neural architecture
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
neural instance representation architecture that decouples domain-invariant and instance-specific features, enabling class-consistent instance generation across varying dimensions without problem-specific instance generators
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DACMO can be directly applied to all four problem classes without modification
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
C. A. C. Coello, G. B. Lamont, and D. A. van Veldhuizen,Evolutionary algorithms for solving multi-objective problems, Second Edition, ser. Genetic and evolutionary computation series. Springer, 2007
work page 2007
-
[2]
Multi- objective optimization for resource allocation in vehicular cloud com- puting networks,
W. Wei, R. Yang, H. Gu, W. Zhao, C. Chen, and S. Wan, “Multi- objective optimization for resource allocation in vehicular cloud com- puting networks,”IEEE Trans. Intell. Transp. Syst., vol. 23, no. 12, pp. 25 536–25 545, 2022
work page 2022
-
[3]
X. He, Q. Pan, L. Gao, L. Wang, and P. N. Suganthan, “A greedy cooperative co-evolutionary algorithm with problem-specific knowledge for multiobjective flowshop group scheduling problems,”IEEE Trans. Evol. Comput., vol. 27, no. 3, pp. 430–444, 2023. IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION, VOL. XX, NO. X, XX XXXX 14
work page 2023
-
[4]
An improved NSGAII for integrated container scheduling problems with two transshipment routes,
L. Zhong, W. Li, K. Gao, L. He, and Y . Zhou, “An improved NSGAII for integrated container scheduling problems with two transshipment routes,”IEEE Trans. Intell. Transp. Syst., vol. 25, no. 10, pp. 14 586– 14 599, 2024
work page 2024
-
[5]
W. Hong, C. Qian, and K. Tang, “Efficient minimum cost seed selection with theoretical guarantees for competitive influence maximization,” IEEE Trans. Cybern., vol. 51, no. 12, pp. 6091–6104, 2021
work page 2021
-
[6]
A survey of automatic parameter tuning methods for metaheuristics,
C. Huang, Y . Li, and X. Yao, “A survey of automatic parameter tuning methods for metaheuristics,”IEEE Trans. Evol. Comput., vol. 24, no. 2, pp. 201–216, 2020
work page 2020
-
[7]
Model-based genetic algorithms for algorithm configuration,
C. Ans ´otegui, Y . Malitsky, H. Samulowitz, M. Sellmann, and K. Tier- ney, “Model-based genetic algorithms for algorithm configuration,” in Proceedings of IJCAI 2015, Buenos Aires, Argentina, pp. 733–739
work page 2015
-
[8]
The irace package: Iterated racing for automatic algorithm configura- tion,
L.-I. Manuel, D.-L. J ´er´emie, P. C. Leslie, B. Mauro, and S. Thomas, “The irace package: Iterated racing for automatic algorithm configura- tion,”Oper. Res. Perspect., vol. 3, pp. 43–58, 2016
work page 2016
-
[9]
Sequential model-based optimization for general algorithm configuration,
F. Hutter, H. H. Hoos, and K. Leyton-Brown, “Sequential model-based optimization for general algorithm configuration,” inProceedings of LION 2011, Rome, Italy, vol. 6683, pp. 507–523
work page 2011
-
[10]
On performance estimation in automatic algorithm configuration,
S. Liu, K. Tang, Y . Lei, and X. Yao, “On performance estimation in automatic algorithm configuration,” inProceedings of AAAI 2020, NY, USA, pp. 2384–2391
work page 2020
-
[11]
Automatic construction of parallel portfolios via algorithm configuration,
M. Lindauer, H. H. Hoos, K. Leyton-Brown, and T. Schaub, “Automatic construction of parallel portfolios via algorithm configuration,”Artif. Intell., vol. 244, pp. 272–290, 2017
work page 2017
-
[12]
ISAC - instance-specific algorithm configuration,
S. Kadioglu, Y . Malitsky, M. Sellmann, and K. Tierney, “ISAC - instance-specific algorithm configuration,” inProceedings of ECAI 2010, Lisbon, Portugal, vol. 215, pp. 751–756
work page 2010
-
[13]
Hydra: Automatically configuring algorithms for portfolio-based selection,
L. Xu, H. H. Hoos, and K. Leyton-Brown, “Hydra: Automatically configuring algorithms for portfolio-based selection,” inProceedings of AAAI 2010, GA, USA, pp. 210–216
work page 2010
-
[14]
Automatic construction of parallel portfolios via explicit instance grouping,
S. Liu, K. Tang, and X. Yao, “Automatic construction of parallel portfolios via explicit instance grouping,” inProceedings of AAAI 2019, HI, USA, pp. 1560–1567
work page 2019
-
[15]
An economics approach to hard computational problems,
B. A. Huberman, R. M. Lukose, and T. Hogg, “An economics approach to hard computational problems,”Science, vol. 275, no. 5296, pp. 51–54, 1997
work page 1997
-
[16]
C. P. Gomes and B. Selman, “Algorithm portfolios,”Artif. Intell., vol. 126, no. 1-2, pp. 43–62, 2001
work page 2001
-
[17]
R. W. Hockney and C. R. Jesshope,Parallel Computers 2: architecture, programming and algorithms. CRC Press, 2019
work page 2019
-
[18]
Learn to optimize-a brief overview,
K. Tang and X. Yao, “Learn to optimize-a brief overview,”Natl. Sci. Rev., vol. 11, no. 8, p. nwae132, 2024
work page 2024
-
[19]
Generating new test instances by evolving in instance space,
K. Smith-Miles and S. Bowly, “Generating new test instances by evolving in instance space,”Comput. Oper. Res., vol. 63, pp. 102–113, 2015
work page 2015
-
[20]
Few-shots parallel algorithm portfolio construction via co-evolution,
K. Tang, S. Liu, P. Yang, and X. Yao, “Few-shots parallel algorithm portfolio construction via co-evolution,”IEEE Trans. Evol. Comput., vol. 25, no. 3, pp. 595–607, 2021
work page 2021
-
[21]
Generative adversarial construction of parallel portfolios,
S. Liu, K. Tang, and X. Yao, “Generative adversarial construction of parallel portfolios,”IEEE Trans. Cybern., vol. 52, no. 2, pp. 784–795, 2022
work page 2022
-
[22]
ASP: learn a universal neural solver!
C. Wang, Z. Yu, S. McAleer, T. Yu, and Y . Yang, “ASP: learn a universal neural solver!”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 6, pp. 4102–4114, 2024
work page 2024
-
[23]
Z. Wang, S. Liu, P. Yang, and K. Tang, “Evolving generalizable parallel algorithm portfolios for binary optimization problems via domain- agnostic instance generation,”IEEE Trans. Evol. Comput., vol. Early Access, no. 1, pp. 1–1, 2025
work page 2025
-
[24]
T. Guo, Y . Mei, M. Zhang, K. Tang, K. Cai, and W. Du, “Enhanced evolution of parallel algorithm portfolio for vehicle routing problem via transfer optimization,”IEEE Trans. Evol. Comput., vol. Early Access, no. 1, pp. 1–1, 2025
work page 2025
-
[25]
Benchmarking moeas for multi- and many- objective optimization using an unbounded external archive,
R. Tanabe and A. Oyama, “Benchmarking moeas for multi- and many- objective optimization using an unbounded external archive,” inProceed- ings of GECCO 2017, NY, USA, P. A. N. Bosman, Ed., pp. 633–640
work page 2017
-
[26]
H. Li, K. Deb, Q. Zhang, P. N. Suganthan, and L. Chen, “Comparison between MOEA/D and NSGA-III on a set of novel many and multi- objective benchmark problems with challenging difficulties,”Swarm Evol. Comput., vol. 46, pp. 104–117, 2019
work page 2019
-
[27]
Performance comparison of NSGA-II and NSGA-III on various many-objective test problems,
H. Ishibuchi, R. Imada, Y . Setoguchi, and Y . Nojima, “Performance comparison of NSGA-II and NSGA-III on various many-objective test problems,” inProceedings of CEC 2016, BC, Canada, pp. 3045–3052
work page 2016
-
[28]
Mathematical discoveries from program search with large language models,
B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P. Kumar, E. Dupont, F. J. R. Ruiz, J. S. Ellenberg, P. Wang, O. Fawzi, P. Kohli, and A. Fawzi, “Mathematical discoveries from program search with large language models,”Nat., vol. 625, no. 7995, pp. 468–475, 2024
work page 2024
-
[29]
Evolution of heuristics: Towards efficient automatic algorithm design using large language model,
F. Liu, X. Tong, M. Yuan, X. Lin, F. Luo, Z. Wang, Z. Lu, and Q. Zhang, “Evolution of heuristics: Towards efficient automatic algorithm design using large language model,” inProceedings of ICML 2024, Vienna, Austria, pp. 32 201–32 223
work page 2024
-
[30]
Reevo: Large language models as hyper-heuristics with reflective evolution,
H. Ye, J. Wang, Z. Cao, F. Berto, C. Hua, H. Kim, J. Park, and G. Song, “Reevo: Large language models as hyper-heuristics with reflective evolution,” inProceedings of NeurIPS 2024, BC, Canada
work page 2024
-
[31]
LLM- driven instance-specific heuristic generation and selection,
S. Zhang, S. Liu, N. Lu, J. Wu, J. Liu, Y .-S. Ong, and K. Tang, “LLM- driven instance-specific heuristic generation and selection,”CoRR, vol. abs/2506.00490, 2025
-
[32]
Monte carlo tree search for comprehensive exploration in LLM-based automatic heuristic design,
Z. Zheng, Z. Xie, Z. Wang, and B. Hooi, “Monte carlo tree search for comprehensive exploration in LLM-based automatic heuristic design,” inProceedings of ICML 2025, BC, Canada
work page 2025
-
[33]
In-the-loop hyper-parameter optimization for LLM-based automated design of heuristics,
N. van Stein, D. Vermetten, and T. B ¨ack, “In-the-loop hyper-parameter optimization for LLM-based automated design of heuristics,”ACM Trans. Evol. Learn. Optim., 2025
work page 2025
-
[34]
LLMOPT: learning to define and solve general optimization problems from scratch,
C. Jiang, X. Shu, H. Qian, X. Lu, J. Zhou, A. Zhou, and Y . Yu, “LLMOPT: learning to define and solve general optimization problems from scratch,” inProceedings of ICLR 2025, Singapore
work page 2025
-
[35]
Multi-objective evolution of heuristic using large language model,
S. Yao, F. Liu, X. Lin, Z. Lu, Z. Wang, and Q. Zhang, “Multi-objective evolution of heuristic using large language model,” inProceedings of AAAI 2025, PA, USA, pp. 27 144–27 152
work page 2025
-
[36]
H. M. Hieu, H. Phan, T. D. Doan, T. Dao, C. D. Tran, and H. T. T. Binh, “Pareto-grid-guided large language models for fast and high- quality heuristics design in multi-objective combinatorial optimization,” inProceedings of AAAI 2026, Singapore, pp. 36 964–36 972
work page 2026
-
[37]
Large language model for multiobjective evolutionary optimization,
F. Liu, X. Lin, S. Yao, Z. Wang, X. Tong, M. Yuan, and Q. Zhang, “Large language model for multiobjective evolutionary optimization,” inProceedings of EMO 2025, ACT, Australia, pp. 178–191
work page 2025
-
[38]
Au- tonomous multi-objective optimization using large language model,
Y . Huang, S. Wu, W. Zhang, J. Wu, L. Feng, and K. C. Tan, “Au- tonomous multi-objective optimization using large language model,” IEEE Trans. Evol. Comput., vol. Early Access, pp. 1–1, 2025
work page 2025
-
[39]
A fast and elitist multiobjective genetic algorithm: NSGA-II,
K. Deb, S. Agrawal, A. Pratap, and T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: NSGA-II,”IEEE Trans. Evol. Comput., vol. 6, no. 2, pp. 182–197, 2002
work page 2002
-
[40]
K. Deb and H. Jain, “An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: solving problems with box constraints,”IEEE Trans. Evol. Comput., vol. 18, no. 4, pp. 577–601, 2014
work page 2014
-
[41]
MOEA/D: A multiobjective evolutionary algorithm based on decomposition,
Q. Zhang and H. Li, “MOEA/D: A multiobjective evolutionary algorithm based on decomposition,”IEEE Trans. Evol. Comput., vol. 11, no. 6, pp. 712–731, 2007
work page 2007
-
[42]
SPEA2: Improving the strength pareto evolutionary algorithm,
E. Zitzler, M. Laumanns, and L. Thiele, “SPEA2: Improving the strength pareto evolutionary algorithm,”TIK report, vol. 103, 2001
work page 2001
-
[43]
M. Cui, L. Li, M. Zhou, and A. Abusorrah, “Surrogate-assisted autoencoder-embedded evolutionary optimization algorithm to solve high-dimensional expensive problems,”IEEE Trans. Evol. Comput., vol. 26, no. 4, pp. 676–689, 2022
work page 2022
-
[44]
Q. Yang, Z. Zhan, X. Liu, J. Li, and J. Zhang, “Grid classification-based surrogate-assisted particle swarm optimization for expensive multiob- jective optimization,”IEEE Trans. Evol. Comput., vol. 28, no. 6, pp. 1867–1881, 2024
work page 2024
-
[45]
Parameter-exploring policy gradients,
F. Sehnke, C. Osendorfer, T. R ¨uckstieß, A. Graves, J. Peters, and J. Schmidhuber, “Parameter-exploring policy gradients,”Neural Netw., vol. 23, no. 4, pp. 551–559, 2010
work page 2010
-
[46]
Runtime analysis of evolutionary diversity maximization for oneminmax,
B. Doerr, W. Gao, and F. Neumann, “Runtime analysis of evolutionary diversity maximization for oneminmax,” inProceedings of GECCO 2016, CO, USA, pp. 557–564
work page 2016
-
[47]
A. Jaszkiewicz, “On the performance of multiple-objective genetic local search on the 0/1 knapsack problem - a comparative experiment,”IEEE Trans. Evol. Comput., vol. 6, no. 4, pp. 402–412, 2002
work page 2002
-
[48]
Contamination control in food supply chain,
Y . Hu, J. Hu, Y . Xu, F. Wang, and R. Cao, “Contamination control in food supply chain,” inProceedings of WSC 2010, MD, USA, pp. 2678– 2681
work page 2010
-
[49]
Combinatorial bayesian optimization using the graph cartesian product,
C. Oh, J. M. Tomczak, E. Gavves, and M. Welling, “Combinatorial bayesian optimization using the graph cartesian product,” inProceedings of NeurIPS 2019, BC, Canada, pp. 2910–2920
work page 2019
-
[50]
From competition to complementarity: Comparative influence diffusion and maximization,
W. Lu, W. Chen, and L. V . S. Lakshmanan, “From competition to complementarity: Comparative influence diffusion and maximization,” Proc. VLDB Endow., vol. 9, no. 2, pp. 60–71, 2015. IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION, VOL. XX, NO. X, XX XXXX 15 Supplementary for “General-Purpose Co-Evolutionary Construction of Parallel Algorithm Portfolios for ...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.