Reinforcement Learning with Action Chunking
Pith reviewed 2026-05-19 05:14 UTC · model grok-4.3
The pith
Running reinforcement learning in a chunked action space lets agents use consistent sequences from offline data for better exploration and more stable learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Q-chunking adopts action chunking by directly running RL in a 'chunked' action space, enabling the agent to leverage temporally consistent behaviors from offline data for more effective online exploration and to use unbiased n-step backups for more stable and efficient TD learning.
What carries the argument
The chunked action space, in which the policy selects sequences of future actions rather than one action at each timestep.
If this is right
- Q-chunking achieves strong performance on the offline dataset and high sample efficiency during the online phase.
- The method outperforms prior best offline-to-online RL algorithms on long-horizon sparse-reward manipulation tasks.
- Temporal difference learning becomes more stable and efficient through the use of unbiased n-step backups.
- Online exploration improves because the agent can commit to temporally consistent action sequences drawn from the prior data.
Where Pith is reading between the lines
- Chunking might still help when offline data is somewhat noisy if paired with simple filtering of inconsistent sequences.
- The same idea could link imitation-learning techniques more directly to value-based online optimization without extra machinery.
- Applying the approach to navigation or locomotion tasks would test whether the benefits extend past the manipulation domains evaluated here.
Load-bearing premise
The offline dataset contains temporally consistent action sequences that remain useful when the policy is optimized online inside the chunked action space.
What would settle it
Experiments on long-horizon sparse-reward tasks that use an offline dataset lacking consistent action chunks at the sequence level, showing no gains in online exploration or sample efficiency compared to standard non-chunked RL.
Figures

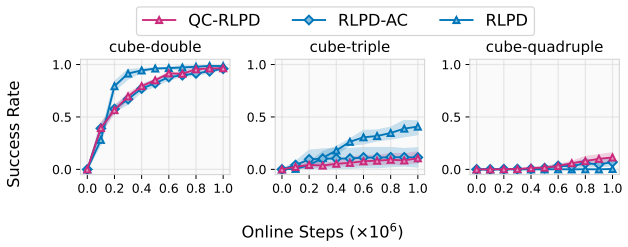




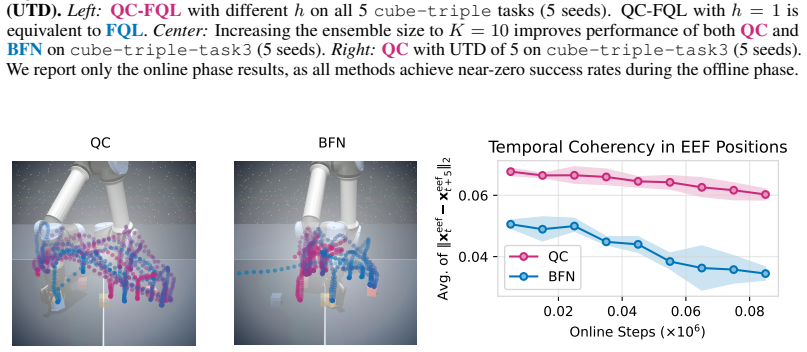





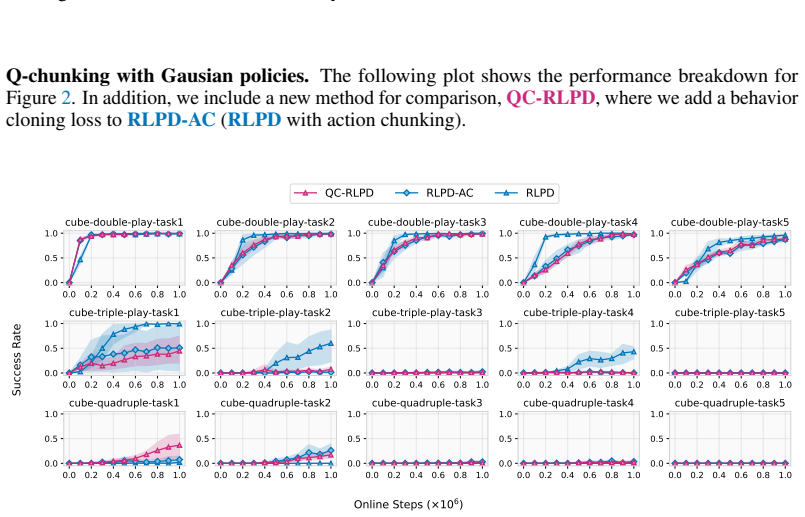


read the original abstract
We present Q-chunking, a simple yet effective recipe for improving reinforcement learning (RL) algorithms for long-horizon, sparse-reward tasks. Our recipe is designed for the offline-to-online RL setting, where the goal is to leverage an offline prior dataset to maximize the sample-efficiency of online learning. Effective exploration and sample-efficient learning remain central challenges in this setting, as it is not obvious how the offline data should be utilized to acquire a good exploratory policy. Our key insight is that action chunking, a technique popularized in imitation learning where sequences of future actions are predicted rather than a single action at each timestep, can be applied to temporal difference (TD)-based RL methods to mitigate the exploration challenge. Q-chunking adopts action chunking by directly running RL in a 'chunked' action space, enabling the agent to (1) leverage temporally consistent behaviors from offline data for more effective online exploration and (2) use unbiased $n$-step backups for more stable and efficient TD learning. Our experimental results demonstrate that Q-chunking exhibits strong offline performance and online sample efficiency, outperforming prior best offline-to-online methods on a range of long-horizon, sparse-reward manipulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Q-chunking, a recipe for offline-to-online RL on long-horizon sparse-reward tasks. It runs TD-based RL directly inside a chunked action space so that the agent can (1) exploit temporally consistent action sequences present in the offline dataset for more effective online exploration and (2) perform unbiased n-step backups. Experiments are reported to show improved offline performance and online sample efficiency relative to prior offline-to-online baselines on manipulation tasks.
Significance. If the central claims hold, the work supplies a lightweight, algorithm-agnostic way to convert existing TD methods into more sample-efficient offline-to-online learners by borrowing the action-chunking idea from imitation learning. The absence of new hyperparameters and the direct applicability to standard TD updates are practical strengths that could affect how practitioners initialize exploration from offline data.
major comments (2)
- The load-bearing assumption that offline trajectories contain reusable, temporally consistent chunks whose internal structure survives online policy optimization inside the coarser chunked action space is stated but not empirically tested. No chunk-level consistency metric, filtering step, or regularization term is introduced to enforce or recover this property when the original data policy varies within what becomes a single chunk.
- The claim of unbiased n-step backups (Abstract and method description) requires a formal argument showing that the chunked transition and reward definitions preserve the unbiasedness of the multi-step estimator; without this derivation or an explicit equation relating the chunked Bellman operator to the original one, it is unclear whether the reported stability gain is a consequence of chunking or of other implementation choices.
minor comments (2)
- Add error bars, number of seeds, and a clear statement of the full experimental protocol (including how chunks are formed from the offline dataset) so that the outperformance numbers can be reproduced and statistically evaluated.
- Clarify the precise definition of the chunked action space and the corresponding state-transition and reward functions; a short pseudocode block or equation would remove ambiguity about how standard TD updates are applied inside the new space.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: The load-bearing assumption that offline trajectories contain reusable, temporally consistent chunks whose internal structure survives online policy optimization inside the coarser chunked action space is stated but not empirically tested. No chunk-level consistency metric, filtering step, or regularization term is introduced to enforce or recover this property when the original data policy varies within what becomes a single chunk.
Authors: We agree that a direct empirical test of the chunk-consistency assumption would strengthen the presentation. Although the reported performance gains on long-horizon manipulation tasks are consistent with the assumption that temporally coherent sequences in the offline data remain useful under chunked online optimization, the manuscript does not contain an explicit consistency metric or analysis. In the revised version we will add a short empirical subsection that quantifies intra-chunk action variance both in the offline dataset and throughout online training, thereby providing concrete evidence that the low-variance structure is present and largely preserved. revision: yes
-
Referee: The claim of unbiased n-step backups (Abstract and method description) requires a formal argument showing that the chunked transition and reward definitions preserve the unbiasedness of the multi-step estimator; without this derivation or an explicit equation relating the chunked Bellman operator to the original one, it is unclear whether the reported stability gain is a consequence of chunking or of other implementation choices.
Authors: We appreciate the request for a formal justification. In the chunked formulation the agent executes a fixed sequence of actions over the chunk horizon; the accumulated reward is the sum of the per-step rewards and the successor state is the state reached after the entire chunk. This construction yields an n-step return that is unbiased for the value of the policy that repeats the chosen chunk, and the corresponding Bellman operator remains a contraction with the same fixed point as the original MDP. We will insert a concise derivation (including the explicit relation between the chunked and standard n-step targets) into the methods section of the revision to clarify this point. revision: yes
Circularity Check
No circularity: method is a direct recipe on existing TD algorithms
full rationale
The paper presents Q-chunking as applying the existing concept of action chunking directly to the action space of standard TD-based RL algorithms in the offline-to-online setting. The two claimed benefits (leveraging consistent behaviors from offline data and unbiased n-step backups) follow immediately from the definition of operating in a chunked action space; they are not derived via any fitted parameter, self-referential equation, or load-bearing self-citation that reduces the result to its own inputs. No equations or steps in the provided abstract or description collapse the claimed improvements back onto data used for evaluation. The derivation remains self-contained against external RL benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Offline dataset contains temporally consistent action sequences usable for exploration
- domain assumption n-step backups remain unbiased when performed over action chunks
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Q-chunking adopts action chunking by directly running RL in a 'chunked' action space, enabling the agent to (1) leverage temporally consistent behaviors from offline data for more effective online exploration and (2) use unbiased n-step backups for more stable and efficient TD learning.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 12 Pith papers
-
Aligning Flow Map Policies with Optimal Q-Guidance
Flow map policies enable fast one-step inference for flow-based RL policies, and FMQ provides an optimal closed-form Q-guided target for offline-to-online adaptation under trust-region constraints, achieving SOTA performance.
-
Revisiting Policy Gradients for Restricted Policy Classes: Escaping Myopic Local Optima with $k$-step Policy Gradients
The k-step policy gradient converges exponentially close to the optimal deterministic policy in restricted classes, achieving O(1/T) rates under smoothness assumptions without distribution mismatch factors.
-
Long-Horizon Q-Learning: Accurate Value Learning via n-Step Inequalities
LQL stabilizes Q-learning by penalizing violations of n-step action-sequence lower bounds with a hinge loss computed from standard network outputs.
-
Long-Horizon Q-Learning: Accurate Value Learning via n-Step Inequalities
LQL turns n-step action-sequence lower bounds into a practical hinge-loss stabilizer for off-policy Q-learning without extra networks or forward passes.
-
OGPO: Sample Efficient Full-Finetuning of Generative Control Policies
OGPO is a sample-efficient off-policy method for full finetuning of generative control policies that reaches SOTA on robotic manipulation tasks and can recover from poor behavior-cloning initializations without expert data.
-
GSDrive: Reinforcing Driving Policies by Multi-mode Future Trajectory Probing with 3D Gaussian Splatting Environment
GSDrive combines IL priors with RL feedback by probing multi-mode futures inside a 3D Gaussian Splatting simulator to supply dense rewards for closed-loop driving policy improvement on nuScenes.
-
GSDrive: Reinforcing Driving Policies by Multi-mode Future Trajectory Probing with 3D Gaussian Splatting Environment
GSDrive improves end-to-end driving policies through 3D Gaussian Splatting simulation and multi-mode trajectory probing that supplies dense, differentiable rewards for reinforcement learning.
-
Empowering Multi-Robot Cooperation via Sequential World Models
SeqWM introduces sequential autoregressive agent-wise world models for multi-robot MBRL, outperforming baselines in performance and sample efficiency on Bi-DexHands and Multi-Quadruped tasks with physical robot deployment.
-
COOPO: Cyclic Offline-Online Policy Optimization Algorithm
COOPO is a cyclic offline-online RL algorithm that repeatedly anchors the policy to a dataset via KL-regularized updates then fine-tunes online, claiming better sample efficiency and monotonic improvement under covera...
-
DyGRO-VLA: Cross-Task Scaling of Vision-Language-Action Models via Dynamic Grouped Residual Optimization
DyGRO-VLA is a two-stage optimization framework for cross-task scaling of Vision-Language-Action models via dynamic grouped residual optimization in RL.
-
ProcVLM: Learning Procedure-Grounded Progress Rewards for Robotic Manipulation
ProcVLM learns procedure-grounded dense progress rewards for robotic manipulation via a reasoning-before-estimation VLM trained on a 60M-frame synthesized corpus from 30 embodied datasets.
-
RAD-2: Scaling Reinforcement Learning in a Generator-Discriminator Framework
RAD-2 uses a diffusion generator and RL discriminator to cut collision rates by 56% in closed-loop autonomous driving planning.
Reference graph
Works this paper leans on
-
[1]
Reincarnating reinforcement learning: Reusing prior computation to accelerate progress
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron C Courville, and Marc Belle- mare. Reincarnating reinforcement learning: Reusing prior computation to accelerate progress. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 28955–28971. Curran Associat...
work page 2022
-
[2]
Reincarnating reinforcement learning: Reusing prior computation to accelerate progress
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron C Courville, and Marc Belle- mare. Reincarnating reinforcement learning: Reusing prior computation to accelerate progress. Advances in neural information processing systems, 35:28955–28971, 2022
work page 2022
-
[3]
OPAL: Offline primitive discovery for accelerating offline reinforcement learning
Anurag Ajay, Aviral Kumar, Pulkit Agrawal, Sergey Levine, and Ofir Nachum. OPAL: Offline primitive discovery for accelerating offline reinforcement learning. In International Confer- ence on Learning Representations, 2021. URL https://openreview.net/forum?id= V69LGwJ0lIN
work page 2021
-
[4]
The option-critic architecture
Pierre-Luc Bacon, Jean Harb, and Doina Precup. The option-critic architecture. In Proceedings of the AAAI conference on artificial intelligence, volume 31, 2017
work page 2017
-
[5]
Option discovery using deep skill chaining
Akhil Bagaria and George Konidaris. Option discovery using deep skill chaining. In Interna- tional Conference on Learning Representations, 2019. 11
work page 2019
-
[6]
Effectively learning initiation sets in hierarchical reinforcement learning
Akhil Bagaria, Ben Abbatematteo, Omer Gottesman, Matt Corsaro, Sreehari Rammohan, and George Konidaris. Effectively learning initiation sets in hierarchical reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[7]
Efficient online reinforcement learning with offline data
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. In International Conference on Machine Learning, pages 1577–1594. PMLR, 2023
work page 2023
-
[8]
Homanga Bharadhwaj, Jay Vakil, Mohit Sharma, Abhinav Gupta, Shubham Tulsiani, and Vikash Kumar. Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 4788–4795. IEEE, 2024
work page 2024
-
[9]
Self- supervised reinforcement learning that transfers using random features
Boyuan Chen, Chuning Zhu, Pulkit Agrawal, Kaiqing Zhang, and Abhishek Gupta. Self- supervised reinforcement learning that transfers using random features. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[10]
Intrinsically motivated reinforcement learning
Nuttapong Chentanez, Andrew Barto, and Satinder Singh. Intrinsically motivated reinforcement learning. Advances in neural information processing systems, 17, 2004
work page 2004
-
[11]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, page 02783649241273668, 2023
work page 2023
-
[12]
Accelerating robotic reinforcement learning via parameterized action primitives
Murtaza Dalal, Deepak Pathak, and Russ R Salakhutdinov. Accelerating robotic reinforcement learning via parameterized action primitives. Advances in Neural Information Processing Systems, 34:21847–21859, 2021
work page 2021
-
[13]
Hierarchical relative entropy policy search
Christian Daniel, Gerhard Neumann, Oliver Kroemer, and Jan Peters. Hierarchical relative entropy policy search. Journal of Machine Learning Research, 17(93):1–50, 2016
work page 2016
-
[14]
Peter Dayan and Geoffrey E Hinton. Feudal reinforcement learning. Advances in neural information processing systems, 5, 1992
work page 1992
-
[15]
Learning transferable sub-goals by hypothesizing generalizing features
Anita de Mello Koch, Akhil Bagaria, Bingnan Huo, Zhiyuan Zhou, Cameron Allen, and George Konidaris. Learning transferable sub-goals by hypothesizing generalizing features. 2025
work page 2025
-
[16]
Hierarchical reinforcement learning with the maxq value function decomposition
Thomas G Dietterich. Hierarchical reinforcement learning with the maxq value function decomposition. Journal of artificial intelligence research, 13:227–303, 2000
work page 2000
-
[17]
Revisiting fundamentals of experience replay
William Fedus, Prajit Ramachandran, Rishabh Agarwal, Yoshua Bengio, Hugo Larochelle, Mark Rowland, and Will Dabney. Revisiting fundamentals of experience replay. InInternational conference on machine learning, pages 3061–3071. PMLR, 2020
work page 2020
-
[18]
Multi-Level Discovery of Deep Options
Roy Fox, Sanjay Krishnan, Ion Stoica, and Ken Goldberg. Multi-level discovery of deep options. arXiv preprint arXiv:1703.08294, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Unsupervised zero-shot rein- forcement learning via functional reward encodings
Kevin Frans, Seohong Park, Pieter Abbeel, and Sergey Levine. Unsupervised zero-shot rein- forcement learning via functional reward encodings. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, edi- tors, Proceedings of the 41st International Conference on Machine Learning, volume 2...
work page 2024
-
[20]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4RL: Datasets for deep data-driven reinforcement learning. arXiv preprint arXiv:2004.07219, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[21]
Hierarchical skills for efficient exploration
Jonas Gehring, Gabriel Synnaeve, Andreas Krause, and Nicolas Usunier. Hierarchical skills for efficient exploration. Advances in Neural Information Processing Systems, 34:11553–11564, 2021
work page 2021
-
[22]
One act play: Single demonstration behavior cloning with action chunking transformers
Abraham George and Amir Barati Farimani. One act play: Single demonstration behavior cloning with action chunking transformers. arXiv preprint arXiv:2309.10175, 2023. 12
-
[23]
Emaq: Expected-max q-learning operator for simple yet effective offline and online rl
Seyed Kamyar Seyed Ghasemipour, Dale Schuurmans, and Shixiang Shane Gu. Emaq: Expected-max q-learning operator for simple yet effective offline and online rl. In International Conference on Machine Learning, pages 3682–3691. PMLR, 2021
work page 2021
-
[24]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pages 1861–1870. PMLR, 2018
work page 2018
-
[25]
Rainbow: Combining improve- ments in deep reinforcement learning
Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. Rainbow: Combining improve- ments in deep reinforcement learning. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[26]
Kl divergence of max-of-n, 2023
Jacob Hilton. Kl divergence of max-of-n, 2023. URL https://www.jacobh.co.uk/ bon_kl.pdf
work page 2023
-
[27]
Unsupervised behavior extraction via random intent priors
Hao Hu, Yiqin Yang, Jianing Ye, Ziqing Mai, and Chongjie Zhang. Unsupervised behavior extraction via random intent priors. In Thirty-seventh Conference on Neural Information Pro- cessing Systems, 2023. URL https://openreview.net/forum?id=4vGVQVz5KG
work page 2023
-
[28]
Recurrent experience replay in distributed reinforcement learning
Steven Kapturowski, Georg Ostrovski, John Quan, Remi Munos, and Will Dabney. Recurrent experience replay in distributed reinforcement learning. In International conference on learning representations, 2018
work page 2018
-
[29]
Variational temporal abstraction
Taesup Kim, Sungjin Ahn, and Yoshua Bengio. Variational temporal abstraction. Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[30]
Policy search for motor primitives in robotics
Jens Kober and Jan Peters. Policy search for motor primitives in robotics. Advances in neural information processing systems, 21, 2008
work page 2008
-
[31]
Autonomous robot skill acquisition
George Dimitri Konidaris. Autonomous robot skill acquisition. University of Massachusetts Amherst, 2011
work page 2011
-
[32]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit Q-learning. arXiv preprint arXiv:2110.06169, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Revisiting peng’s q (λ) for modern reinforcement learning
Tadashi Kozuno, Yunhao Tang, Mark Rowland, Rémi Munos, Steven Kapturowski, Will Dabney, Michal Valko, and David Abel. Revisiting peng’s q (λ) for modern reinforcement learning. In International Conference on Machine Learning, pages 5794–5804. PMLR, 2021
work page 2021
-
[34]
Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation
Tejas D Kulkarni, Karthik Narasimhan, Ardavan Saeedi, and Josh Tenenbaum. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. Advances in neural information processing systems, 29, 2016
work page 2016
-
[35]
Conservative Q-learning for offline reinforcement learning
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative Q-learning for offline reinforcement learning. Advances in Neural Information Processing Systems, 33: 1179–1191, 2020
work page 2020
-
[36]
Offline-to-online reinforcement learning via balanced replay and pessimistic Q-ensemble
Seunghyun Lee, Younggyo Seo, Kimin Lee, Pieter Abbeel, and Jinwoo Shin. Offline-to-online reinforcement learning via balanced replay and pessimistic Q-ensemble. In Conference on Robot Learning, pages 1702–1712. PMLR, 2022
work page 2022
-
[37]
TOP-ERL: Transformer-based off-policy episodic reinforcement learning
Ge Li, Dong Tian, Hongyi Zhou, Xinkai Jiang, Rudolf Lioutikov, and Gerhard Neumann. TOP-ERL: Transformer-based off-policy episodic reinforcement learning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=N4NhVN30ph
work page 2025
-
[38]
Accelerating ex- ploration with unlabeled prior data
Qiyang Li, Jason Zhang, Dibya Ghosh, Amy Zhang, and Sergey Levine. Accelerating ex- ploration with unlabeled prior data. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[39]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971, 2015. 13
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[40]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Finetuning from offline reinforcement learning: Challenges, trade-offs and practical solutions
Yicheng Luo, Jackie Kay, Edward Grefenstette, and Marc Peter Deisenroth. Finetuning from offline reinforcement learning: Challenges, trade-offs and practical solutions. arXiv preprint arXiv:2303.17396, 2023
-
[42]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. In arXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[43]
Dynamic abstraction in reinforcement learning via clustering
Shie Mannor, Ishai Menache, Amit Hoze, and Uri Klein. Dynamic abstraction in reinforcement learning via clustering. In Proceedings of the twenty-first international conference on Machine learning, page 71, 2004
work page 2004
-
[44]
Q-cut—dynamic discovery of sub-goals in reinforcement learning
Ishai Menache, Shie Mannor, and Nahum Shimkin. Q-cut—dynamic discovery of sub-goals in reinforcement learning. In Machine Learning: ECML 2002: 13th European Conference on Machine Learning Helsinki, Finland, August 19–23, 2002 Proceedings 13, pages 295–306. Springer, 2002
work page 2002
-
[45]
Neural probabilistic motor primitives for humanoid control
Josh Merel, Leonard Hasenclever, Alexandre Galashov, Arun Ahuja, Vu Pham, Greg Wayne, Yee Whye Teh, and Nicolas Heess. Neural probabilistic motor primitives for humanoid control. arXiv preprint arXiv:1811.11711, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
Asynchronous methods for deep reinforce- ment learning
V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforce- ment learning. In International conference on machine learning, pages 1928–1937. PmLR, 2016
work page 1928
-
[47]
Data-efficient hierarchical reinforcement learning
Ofir Nachum, Shixiang Shane Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical reinforcement learning. Advances in neural information processing systems, 31, 2018
work page 2018
-
[48]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online reinforcement learning with offline datasets. arXiv preprint arXiv:2006.09359, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[49]
Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning
Mitsuhiko Nakamoto, Simon Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[50]
Learning and retrieval from prior data for skill-based imitation learning
Soroush Nasiriany, Tian Gao, Ajay Mandlekar, and Yuke Zhu. Learning and retrieval from prior data for skill-based imitation learning. In Conference on Robot Learning, 2022
work page 2022
-
[51]
Junhyuk Oh, Satinder Singh, and Honglak Lee. Value prediction network. Advances in neural information processing systems, 30, 2017
work page 2017
-
[52]
Probabilistic movement primitives
Alexandros Paraschos, Christian Daniel, Jan R Peters, and Gerhard Neumann. Probabilistic movement primitives. Advances in neural information processing systems, 26, 2013
work page 2013
-
[53]
Ogbench: Benchmarking offline goal-conditioned rl
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmarking offline goal-conditioned rl. ArXiv, 2024
work page 2024
-
[54]
OGBench: Bench- marking Offline Goal-Conditioned RL, February 2025
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmarking offline goal-conditioned rl. arXiv preprint arXiv:2410.20092, 2024
-
[55]
Foundation policies with hilbert rep- resentations
Seohong Park, Tobias Kreiman, and Sergey Levine. Foundation policies with hilbert rep- resentations. In Forty-first International Conference on Machine Learning , 2024. URL https://openreview.net/forum?id=LhNsSaAKub
work page 2024
-
[56]
Seohong Park, Qiyang Li, and Sergey Levine. Flow Q-learning. arXiv preprint arXiv:2502.02538, 2025
-
[57]
Deeploco: Dynamic locomotion skills using hierarchical deep reinforcement learning
Xue Bin Peng, Glen Berseth, KangKang Yin, and Michiel Van De Panne. Deeploco: Dynamic locomotion skills using hierarchical deep reinforcement learning. Acm transactions on graphics (tog), 36(4):1–13, 2017. 14
work page 2017
-
[58]
Accelerating reinforcement learning with learned skill priors
Karl Pertsch, Youngwoon Lee, and Joseph Lim. Accelerating reinforcement learning with learned skill priors. In Conference on robot learning, pages 188–204. PMLR, 2021
work page 2021
-
[59]
Diffusion Policy Policy Optimization
Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization. arXiv preprint arXiv:2409.00588, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Learning by playing solving sparse reward tasks from scratch
Martin Riedmiller, Roland Hafner, Thomas Lampe, Michael Neunert, Jonas Degrave, Tom Wiele, Vlad Mnih, Nicolas Heess, and Jost Tobias Springenberg. Learning by playing solving sparse reward tasks from scratch. In International conference on machine learning , pages 4344–4353. PMLR, 2018
work page 2018
-
[61]
Dynamic movement primitives-a framework for motor control in humans and humanoid robotics
Stefan Schaal. Dynamic movement primitives-a framework for motor control in humans and humanoid robotics. In Adaptive motion of animals and machines, pages 261–280. Springer, 2006
work page 2006
-
[62]
Mastering atari, go, chess and shogi by planning with a learned model
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Si- mon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature, 588(7839):604–609, 2020
work page 2020
-
[63]
Reinforcement learning with action sequence for data-efficient robot learning
Younggyo Seo and Pieter Abbeel. Reinforcement learning with action sequence for data-efficient robot learning. arXiv preprint arXiv:2411.12155, 2024
-
[64]
Continuous control with coarse-to-fine re- inforcement learning
Younggyo Seo, Jafar Uruç, and Stephen James. Continuous control with coarse-to-fine re- inforcement learning. In 8th Annual Conference on Robot Learning , 2024. URL https: //openreview.net/forum?id=WjDR48cL3O
work page 2024
-
[65]
Learning robot skills with temporal variational inference
Tanmay Shankar and Abhinav Gupta. Learning robot skills with temporal variational inference. In International Conference on Machine Learning, pages 8624–8633. PMLR, 2020
work page 2020
-
[66]
Using relative novelty to identify useful temporal abstrac- tions in reinforcement learning
Özgür ¸ Sim¸ sek and Andrew G Barto. Using relative novelty to identify useful temporal abstrac- tions in reinforcement learning. In Proceedings of the twenty-first international conference on Machine learning, page 95, 2004
work page 2004
-
[67]
Özgür ¸ Sim¸ sek and Andrew G. Barto. Betweenness centrality as a basis for forming skills. Workingpaper, University of Massachusetts Amherst, April 2007
work page 2007
-
[68]
Parrot: Data-driven behavioral priors for reinforcement learning
Avi Singh, Huihan Liu, Gaoyue Zhou, Albert Yu, Nicholas Rhinehart, and Sergey Levine. Parrot: Data-driven behavioral priors for reinforcement learning. In International Confer- ence on Learning Representations , 2021. URL https://openreview.net/forum? id=Ysuv-WOFeKR
work page 2021
-
[69]
Hybrid RL: Using both offline and online data can make RL efficient
Yuda Song, Yifei Zhou, Ayush Sekhari, Drew Bagnell, Akshay Krishnamurthy, and Wen Sun. Hybrid RL: Using both offline and online data can make RL efficient. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview. net/forum?id=yyBis80iUuU
work page 2023
-
[70]
Option discovery in hierarchical reinforcement learning using spatio-temporal clustering
Aravind Srinivas, Ramnandan Krishnamurthy, Peeyush Kumar, and Balaraman Ravindran. Option discovery in hierarchical reinforcement learning using spatio-temporal clustering. arXiv preprint arXiv:1605.05359, 2016
-
[71]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020
work page 2020
-
[72]
Reinforcement learning: An introduction, volume 1
Richard S Sutton, Andrew G Barto, et al. Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
work page 1998
-
[73]
Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning
Richard S Sutton, Doina Precup, and Satinder Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artificial intelligence, 112(1-2): 181–211, 1999
work page 1999
-
[74]
Revisiting the minimalist approach to offline reinforcement learning
Denis Tarasov, Vladislav Kurenkov, Alexander Nikulin, and Sergey Kolesnikov. Revisiting the minimalist approach to offline reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024. 15
work page 2024
-
[75]
Chunking the critic: A transformer-based soft actor-critic with n-step returns
Dong Tian, Ge Li, Hongyi Zhou, Onur Celik, and Gerhard Neumann. Chunking the critic: A transformer-based soft actor-critic with n-step returns. arXiv preprint arXiv:2503.03660, 2025
-
[76]
Ahmed Touati, Jérémy Rapin, and Yann Ollivier. Does zero-shot reinforcement learning exist? In The Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[77]
Strategic attentive writer for learning macro-actions
Alexander Vezhnevets, V olodymyr Mnih, Simon Osindero, Alex Graves, Oriol Vinyals, John Agapiou, et al. Strategic attentive writer for learning macro-actions. Advances in neural information processing systems, 29, 2016
work page 2016
-
[78]
Feudal networks for hierarchical reinforcement learning
Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. Feudal networks for hierarchical reinforcement learning. In International conference on machine learning, pages 3540–3549. PMLR, 2017
work page 2017
-
[79]
Train once, get a family: State-adaptive balances for offline-to-online reinforcement learning
Shenzhi Wang, Qisen Yang, Jiawei Gao, Matthieu Lin, Hao Chen, Liwei Wu, Ning Jia, Shiji Song, and Gao Huang. Train once, get a family: State-adaptive balances for offline-to-online reinforcement learning. Advances in Neural Information Processing Systems, 36:47081–47104, 2023
work page 2023
-
[80]
Christopher John Cornish Hellaby Watkins et al. Learning from delayed rewards. 1989
work page 1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.