Unifying Value Alignment and Assignment in Cross-Domain Offline Reinforcement Learning with Heterogeneous Datasets
Pith reviewed 2026-06-30 12:33 UTC · model grok-4.3
The pith
Value misassignment in heterogeneous source datasets undermines value alignment and data filtering in cross-domain offline RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
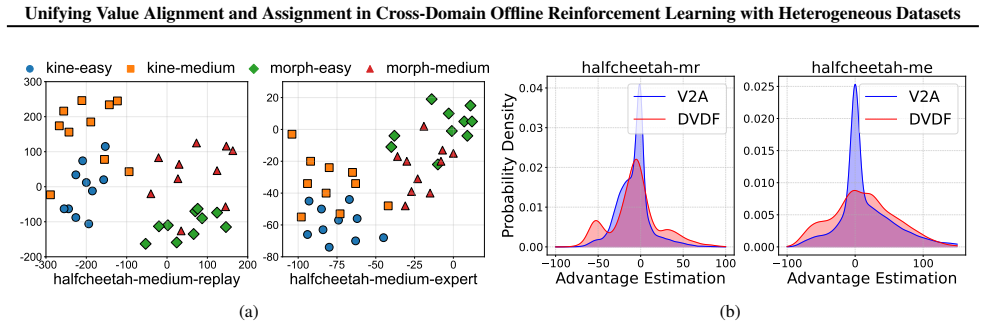
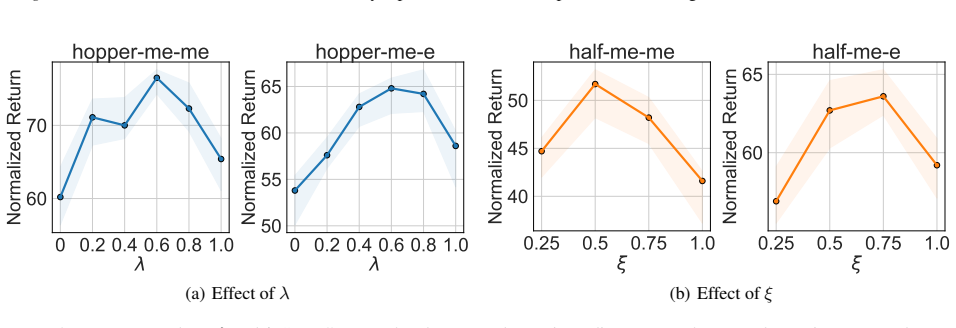
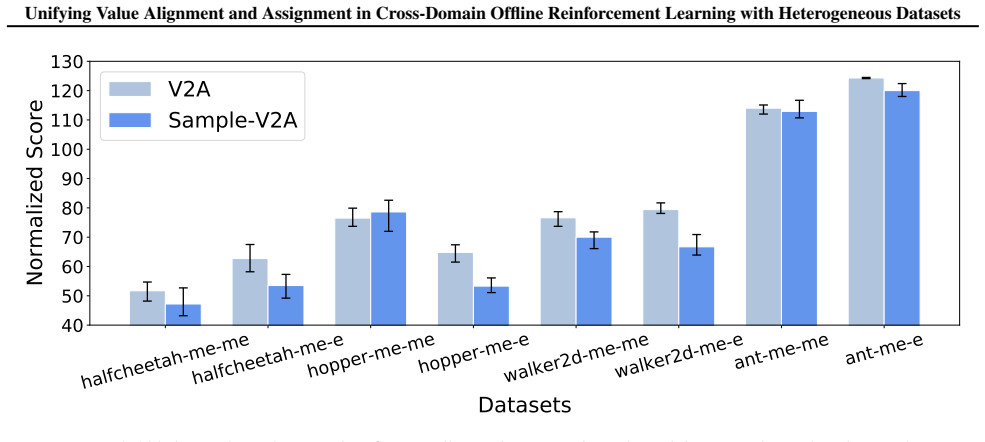
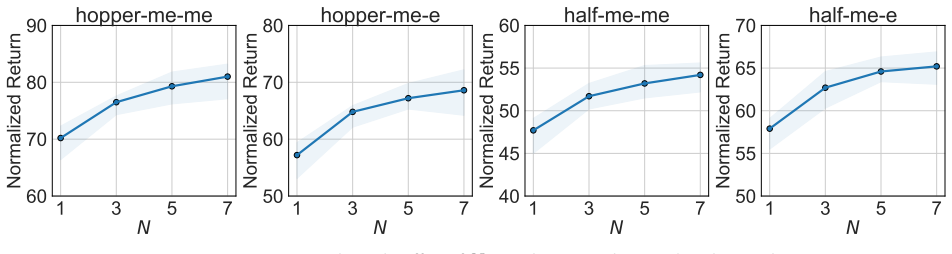
In heterogeneous cross-domain offline RL, value misassignment occurs when source trajectories from differing dynamics receive incorrect value estimates, which then distorts value alignment and causes data filtering to retain low-quality samples. V2A corrects the problem by learning modality representations that remain consistent over time, performing modality-aware advantage estimation to realign values, and using the corrected values to filter source data before policy optimization.
What carries the argument
V2A, which unifies dynamics alignment, value alignment, and value assignment via temporally-consistent modality representation learning followed by modality-aware advantage learning and filtered policy training.
If this is right
- Value misassignment loosens the suboptimality gap between filtered source data and the target optimum.
- Modality-aware advantage learning rectifies value estimates across distinct dynamics without requiring domain labels.
- Data filtering that incorporates corrected values selects higher-quality source samples for target policy learning.
- The integrated V2A pipeline produces policies that transfer more reliably under multiple source domains and behavior policies.
Where Pith is reading between the lines
- The same misassignment mechanism could appear in multi-task offline RL where tasks induce distinct dynamics.
- Applying modality representation learning before value estimation may be testable as a general preprocessing step in any multi-source RL pipeline.
- If the modality representations prove robust, the method could extend to settings where dynamics shift gradually rather than across fixed domains.
Load-bearing premise
Value misassignment is the main driver of performance loss when source datasets are heterogeneous, and correcting it through modality-aware advantage learning will not create fresh misalignment or filtering mistakes.
What would settle it
A controlled experiment in which heterogeneous source data is constructed so that value misassignment is prevented from occurring, yet V2A still shows no performance gain over alignment-only baselines.
Figures

read the original abstract
Cross-domain offline reinforcement learning (RL) aims to learn a policy in the target domain with a limited target domain dataset and a source domain dataset that exhibits a dynamics shift. Training directly on the original source dataset typically leads to performance collapse. Recent studies perform data filtering from the perspective of dynamics alignment or value alignment to enable efficient policy transfer. However, these studies are typically validated on single-domain or single-behavior-policy source datasets. In this work, we explore a more general heterogeneous cross-domain offline RL setting, where the source datasets may be collected from multiple source domains by diverse behavior policies. We first uncover a critical yet overlooked issue in this setting: value misassignment. Empirically and theoretically, we demonstrate that value misassignment can undermine value alignment, mislead data filtering toward selecting suboptimal samples, and loosen the suboptimality gap, thereby degrading the agent's performance. To address this issue, we propose V2A, which integrates dynamics alignment, value alignment, and value assignment. V2A first employs temporally-consistent modality representation learning to extract dynamics modalities from the source dataset, followed by modality-aware advantage learning to rectify value alignment. Finally, it adopts a data filtering paradigm to selectively share source data for policy learning. Empirical results show that V2A significantly outperforms strong baseline methods under general heterogeneous cross-domain offline RL settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies cross-domain offline RL under heterogeneous source datasets collected from multiple domains by diverse behavior policies. It identifies value misassignment as an overlooked failure mode that can undermine value alignment, bias data filtering toward suboptimal samples, and loosen the suboptimality gap. The proposed V2A method first performs temporally-consistent modality representation learning to extract dynamics modalities, then applies modality-aware advantage learning to rectify values, and finally uses a data-filtering step for policy learning. The authors claim both theoretical demonstration of the misassignment effects and empirical outperformance over baselines in the general heterogeneous setting.
Significance. If the theoretical analysis and empirical claims hold under the stated conditions, the work would provide a concrete unification of dynamics alignment, value alignment, and value assignment for a more realistic class of offline RL transfer problems. The emphasis on modality extraction as a prerequisite for correct advantage estimation addresses a practical gap in prior single-domain or single-policy filtering methods. Reproducible code or explicit dataset construction details would strengthen the contribution.
major comments (3)
- [§3.1–3.2] §3.1–3.2: The temporally-consistent modality representation learning step is load-bearing for the entire pipeline, yet the manuscript provides no analysis or experiments demonstrating that the learned representations remain separable when source-domain dynamics exhibit partial overlap or continuous variation rather than clean clusters. If overlap occurs, the subsequent modality-aware advantage estimates remain misassigned, reproducing the exact failure mode the paper attributes to prior methods.
- [§4] §4 (theoretical demonstration): The claim that value misassignment loosens the suboptimality gap is asserted without an explicit derivation or bound that isolates the effect of misassignment from other sources of error (e.g., dynamics mismatch or behavior-policy diversity). A concrete inequality or proof sketch linking the modality extraction error to the final performance gap is required to support the theoretical contribution.
- [Table 2 / §5.2] Table 2 / §5.2: The reported gains of V2A over dynamics-alignment and value-alignment baselines are presented without controls that ablate the modality extraction component while keeping the rest of the pipeline fixed. Without such an ablation, it is unclear whether the performance improvement stems from corrected value assignment or from incidental regularization introduced by the representation learner.
minor comments (2)
- [§3] Notation for the modality indicator and advantage estimator should be introduced once and used consistently; current usage mixes M and ilde{M} without an explicit mapping.
- [Abstract / §4] The abstract states both empirical outperformance and theoretical demonstration, yet the main text should include a short proof sketch or key inequality in the theory section to match the abstract claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the contributions and limitations of our work on unifying value alignment and assignment in heterogeneous cross-domain offline RL. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§3.1–3.2] The temporally-consistent modality representation learning step is load-bearing for the entire pipeline, yet the manuscript provides no analysis or experiments demonstrating that the learned representations remain separable when source-domain dynamics exhibit partial overlap or continuous variation rather than clean clusters. If overlap occurs, the subsequent modality-aware advantage estimates remain misassigned, reproducing the exact failure mode the paper attributes to prior methods.
Authors: We agree that robustness to partial overlap or continuous dynamics variation is an important consideration not explicitly tested in the current manuscript. Our formulation in Sections 3.1–3.2 targets the heterogeneous setting with distinct modalities arising from multiple source domains and behavior policies, where the temporally-consistent representation learning is intended to recover separable clusters. We will add a new subsection with experiments on synthetic overlapping dynamics (e.g., interpolated transition functions) and a discussion of failure cases under severe overlap in the revision. revision: yes
-
Referee: [§4] The claim that value misassignment loosens the suboptimality gap is asserted without an explicit derivation or bound that isolates the effect of misassignment from other sources of error (e.g., dynamics mismatch or behavior-policy diversity). A concrete inequality or proof sketch linking the modality extraction error to the final performance gap is required to support the theoretical contribution.
Authors: The theoretical section demonstrates that value misassignment biases advantage estimates and loosens the suboptimality gap relative to correctly assigned values, but we acknowledge it does not fully isolate the modality extraction error term from other sources. We will include an expanded proof sketch in the appendix that derives a bound separating the contribution of modality misassignment error from dynamics mismatch and policy diversity effects, using the existing decomposition in Section 4 as the starting point. revision: yes
-
Referee: [Table 2 / §5.2] The reported gains of V2A over dynamics-alignment and value-alignment baselines are presented without controls that ablate the modality extraction component while keeping the rest of the pipeline fixed. Without such an ablation, it is unclear whether the performance improvement stems from corrected value assignment or from incidental regularization introduced by the representation learner.
Authors: This is a fair criticism of the experimental controls. The current comparisons in Table 2 and Section 5.2 evaluate the full V2A pipeline against baselines lacking modality extraction, but do not isolate the extraction module itself. We will add an ablation variant that disables modality extraction (replacing it with a shared representation) while retaining modality-aware advantage learning and filtering, and report the results in a revised Table 2. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe an empirical/theoretical identification of value misassignment in heterogeneous cross-domain offline RL, followed by the proposal of V2A that combines dynamics alignment, value alignment, and value assignment via temporally-consistent modality representation learning and modality-aware advantage learning. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the given text that would reduce any claimed result to its inputs by construction. The central claims rest on external experimental validation rather than definitional equivalence or load-bearing self-references, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lyu, J., Ma, X., Li, X., and Lu, Z
IEEE, 2018. Lyu, J., Ma, X., Li, X., and Lu, Z. Mildly conservative q- learning for offline reinforcement learning.Advances in 10 Unifying Value Alignment and Assignment in Cross-Domain Offline Reinforcement Learning with Heterogeneous Datasets Neural Information Processing Systems, 35:1711–1724, 2022. Lyu, J., Bai, C., Yang, J., Lu, Z., and Li, X. Cross-...
-
[2]
T−1X t=0 Ez∼qψ(·|τ) [logp θ(st+1|st, at, z)]−D KL(qψ(·|τ), p(·)) # =E τ∼D src,z∼qψ(·|τ)
that narrows action coverage by exploiting the mode-seeking property of reverse KL-divergence, and LOM (Wang et al., 2024a) that performs weighted imitation learning on a single promising mode, and so on. Our work is orthogonal to these studies, as we focus on the cross-domain offline RL setting. Moreover, we investigate a novel setting where both the beh...
2006
-
[3]
0 1 0" damping=
Then we have |JM1(π⋆ 1)−J M2(π⋆ 2)| ≤C 2 ·sup s,a [DTV(P1(·|s, a), P2(·|s, a))], whereC 2 = 2rmax (1−γ)2 is a positive constant. 17 Unifying Value Alignment and Assignment in Cross-Domain Offline Reinforcement Learning with Heterogeneous Datasets Proof. The proof mainly follows that of Proposition 4.1 in Qiao et al. (2025b). Since JM(π) =E s∼ρ[V π M(s)], ...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.