1
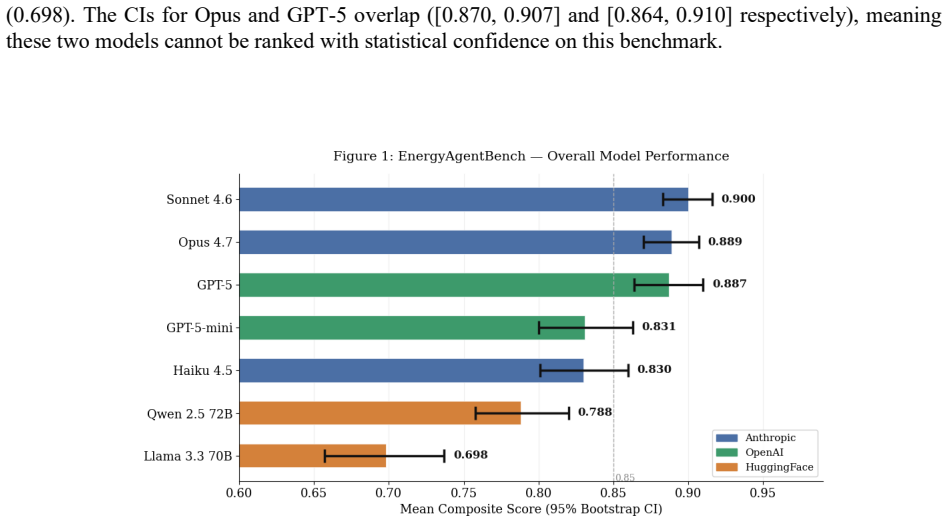
Claude Sonnet leads on live energy data benchmark
EnergyAgentBench: Benchmarking LLM Agents on Live Energy Infrastructure Data
New tasks require agents to query real electricity prices, grid carbon, and cost trajectories, exposing wide gaps on causal reasoning.
 full image
full image
abstract click to expand
Selecting the right electricity market region for a hyperscale AI datacenter requires reasoning across live electricity prices, grid carbon intensity, technology cost trajectories, and causal grid dynamics -- a multi-step, multi-source analytical task that static knowledge benchmarks cannot evaluate. We introduce EnergyAgentBench, the first agentic benchmark grounded in live electricity market data for this problem class. The benchmark comprises 70 task variants across five families: datacenter siting under cost-carbon trade-offs (F1), long-horizon portfolio siting (F1-LH), lifetime LCOE ranking over multi-decade cost trajectories (F2), 30-year portfolio optimization (F2-LH), and causal grid diagnosis (F3). Tasks require 3 to 48 sequential tool calls against live endpoints from the QuarluxAI infrastructure platform, the U.S. Energy Information Administration (EIA), and the National Renewable Energy Laboratory (NREL) with ground truth derived from trained XGBoost cost-surface models (R^2 0.967--0.995) and the NREL Annual Technology Baseline 2024. We evaluate nine models across Anthropic, OpenAI, and HuggingFace over 1,414 runs at three random seeds. Claude Sonnet 4.6 achieves the highest overall score (0.900) at one-quarter the cost of Claude Opus 4.7 (0.889). Claude Haiku 4.5 leads on long-horizon procedural siting (0.986), outperforming all frontier models including those costing 16x more per run. F3 Causal is the most discriminating family, with a 30.7-point spread between Sonnet (0.793) and Llama 3.3 70B (0.486), versus a 6.6-point spread on F1 Siting. A failure taxonomy of 135 coded failures identifies null-value integration in NREL ATB trajectories as the dominant failure mode (70%), followed by premature commitment on causal tasks (20%) and adversarial injection blindness (6%). Benchmark code, run trajectories, and the failure taxonomy dataset are publicly released.