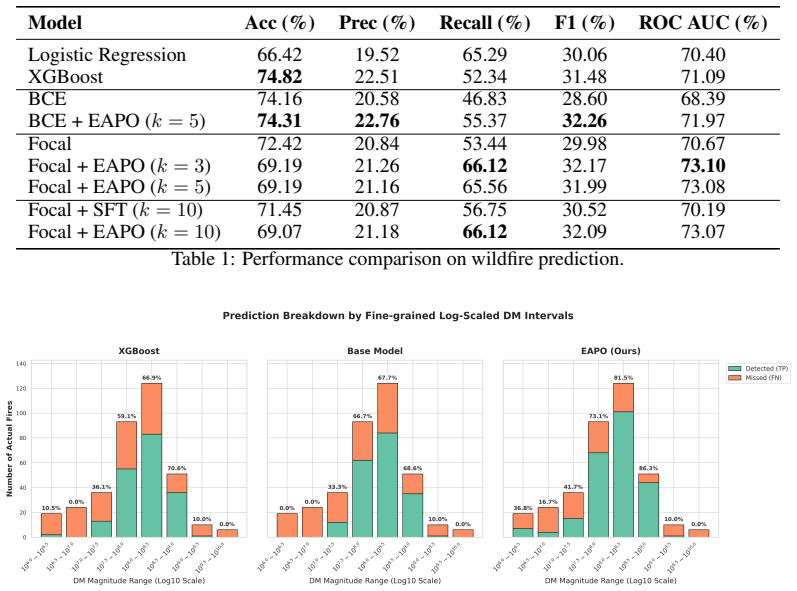
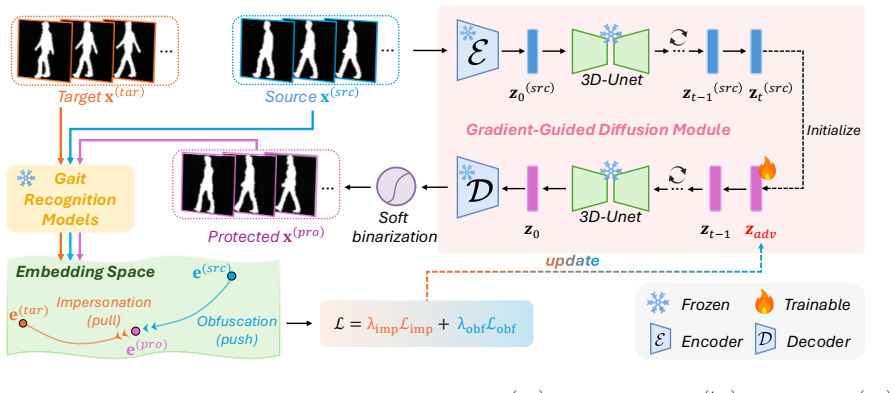
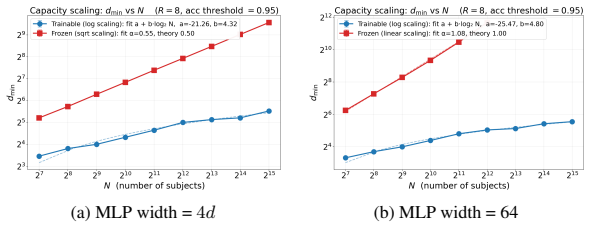
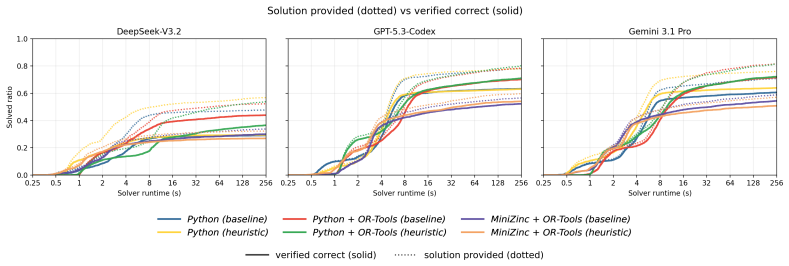
0
BlitzGS is a distributed 3D Gaussian Splatting system that shards Gaussians by index…
BlitzGS: City-Scale Gaussian Splatting at Lightning Speed
BlitzGS delivers order-of-magnitude faster city-scale 3D Gaussian Splatting training via index-parity GPU sharding, scheduled importance…
abstract click to expand
We present BlitzGS, a distributed 3DGS framework that reduces active Gaussian workload for fast city-scale reconstruction. BlitzGS manages this workload at three coupled levels. At the system level, the framework shards Gaussians across GPUs by index parity rather than spatial blocks. This approach mitigates the cross-block visibility redundancy inherent in spatial partitioning. Furthermore, it distributes each rendering step through a single cross-GPU exchange that routes projected Gaussians to their tile owners. At the model level, scheduled importance-scoring passes shrink the global Gaussian population. During these passes, the framework generates a per-Gaussian visibility weight to bias density-control updates toward contributing primitives and a per-view importance mask for the view-level renderer. At the view level, BlitzGS trims each camera's active set with a distance-based LOD gate to exclude excessively fine primitives for the current frustum and the importance-based culling mask to skip Gaussians with negligible cross-view contribution.
On large-scale benchmarks, BlitzGS matches the rendering quality of recent large-scale baselines while delivering an order-of-magnitude speedup, training city-scale scenes in tens of minutes. Our code is available at https: //github.com/AkierRaee/BlitzGS.