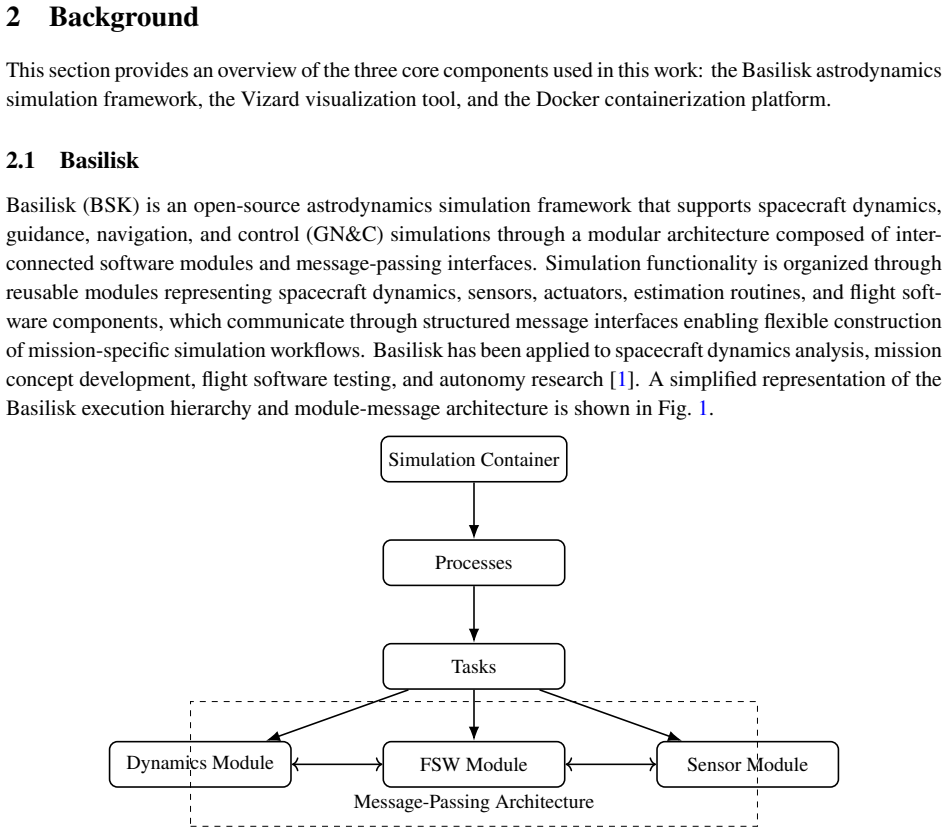
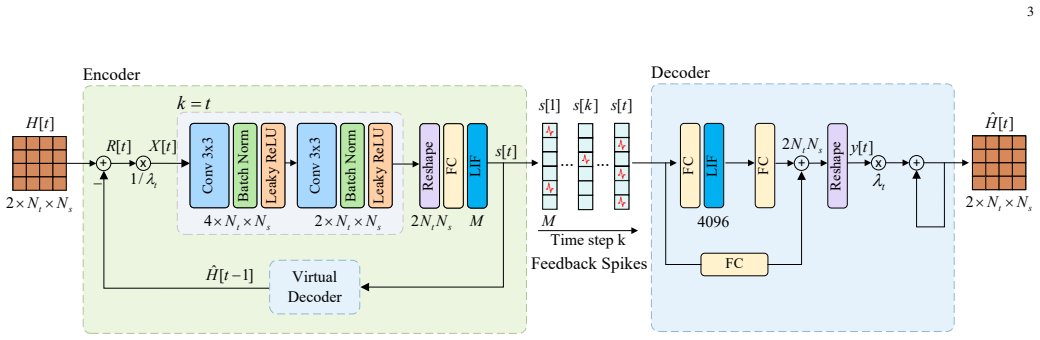
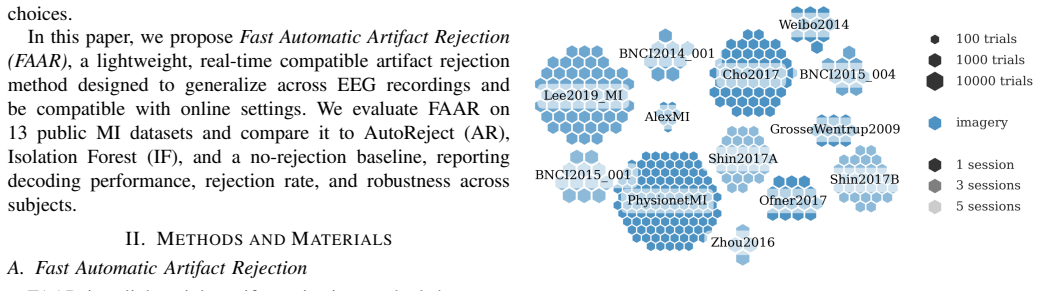
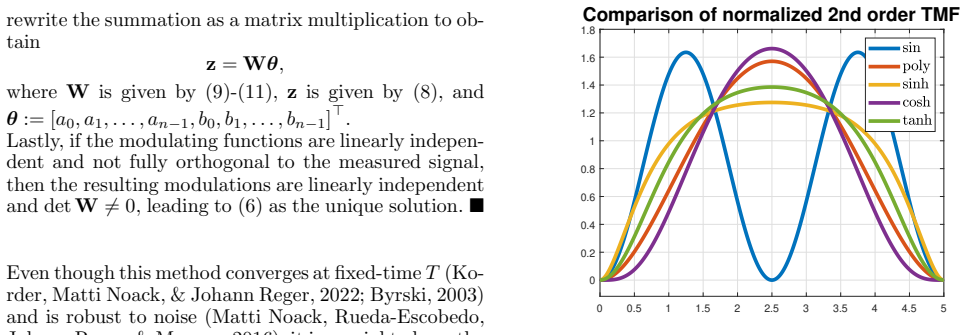
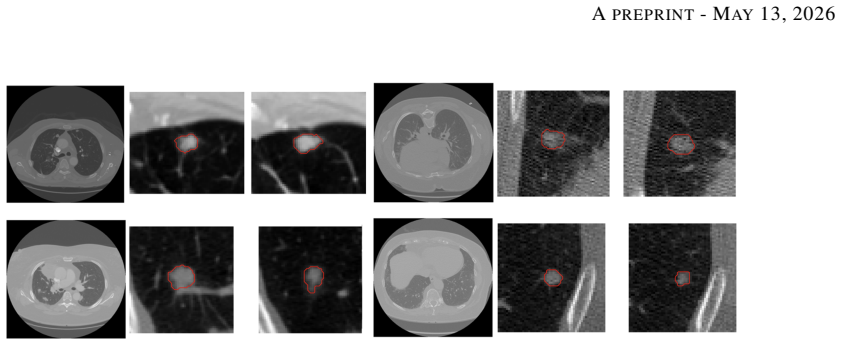
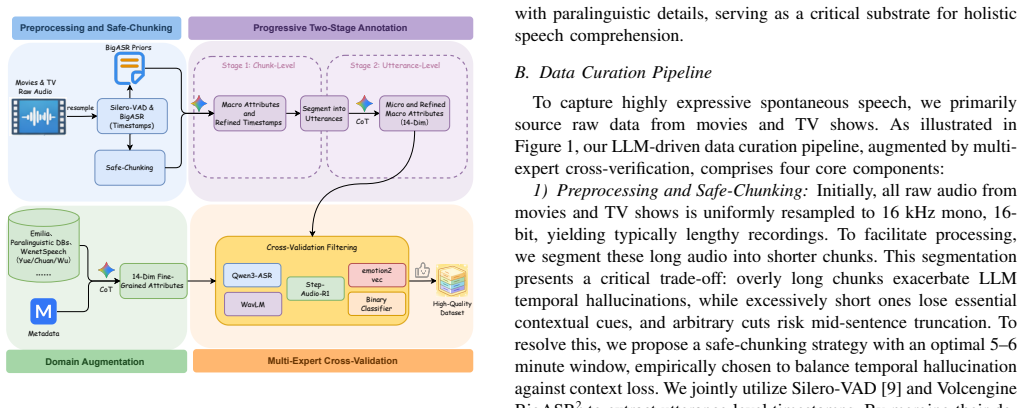
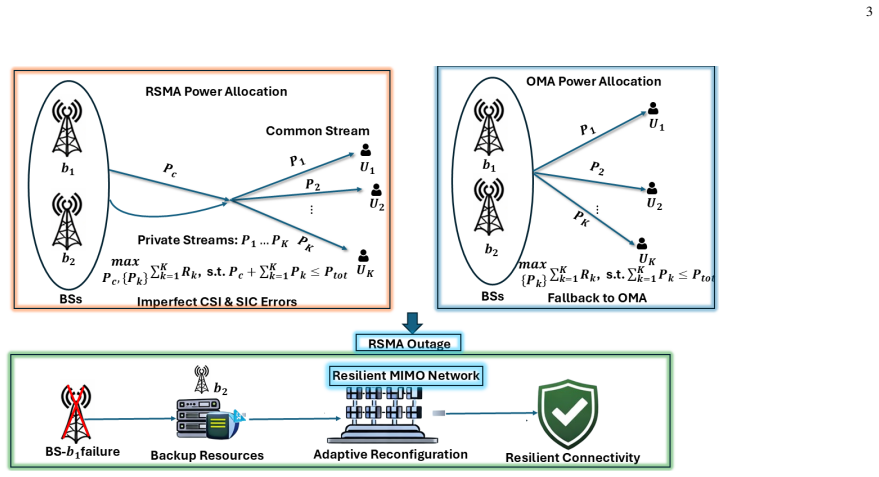
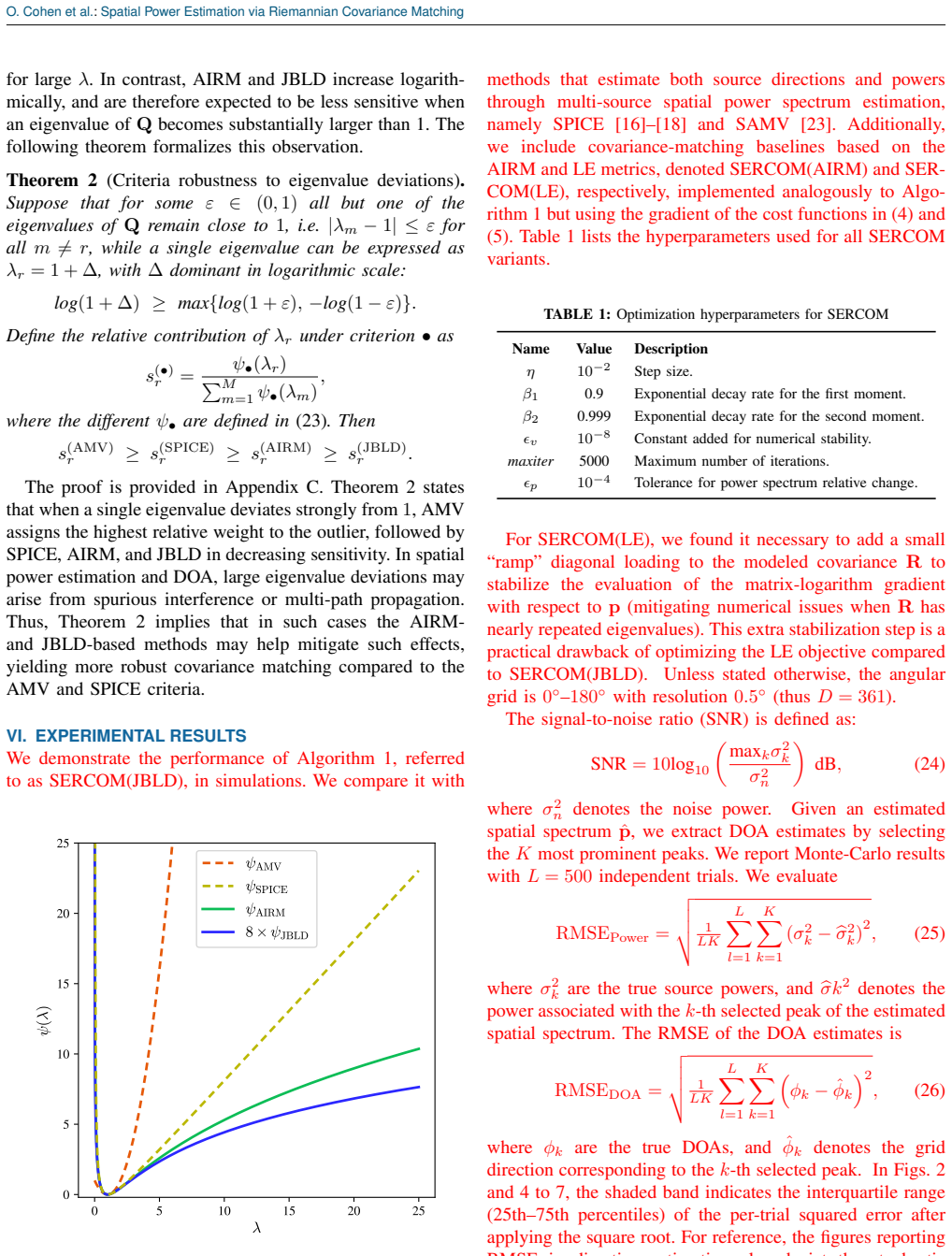
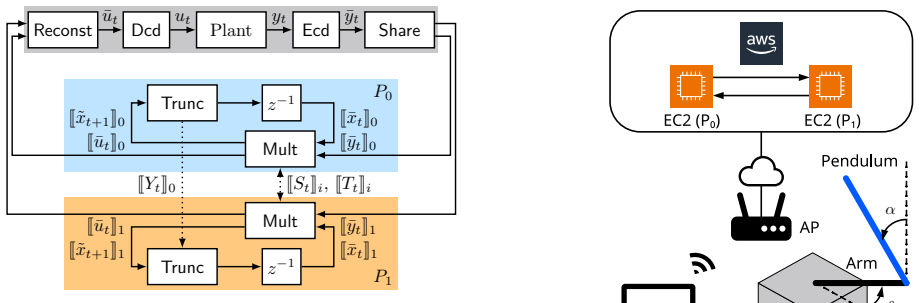
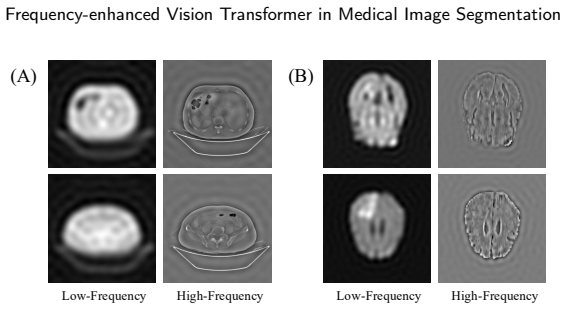
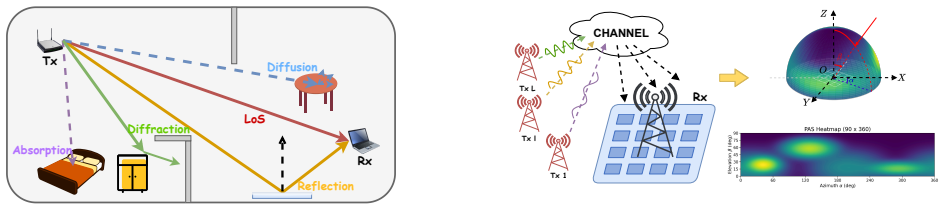
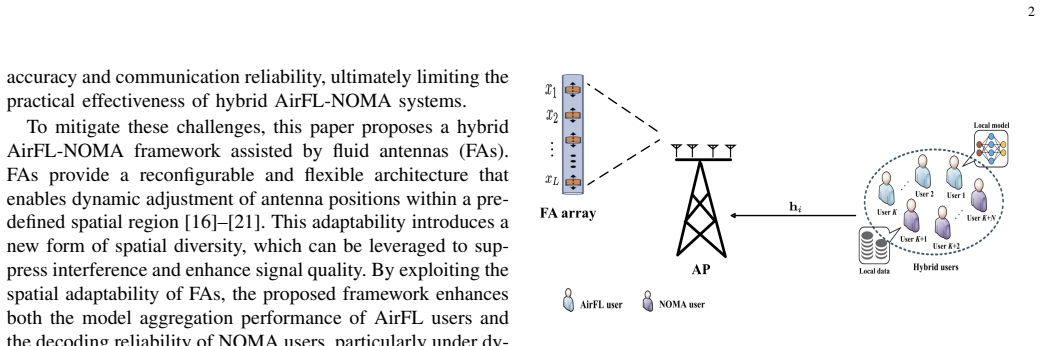
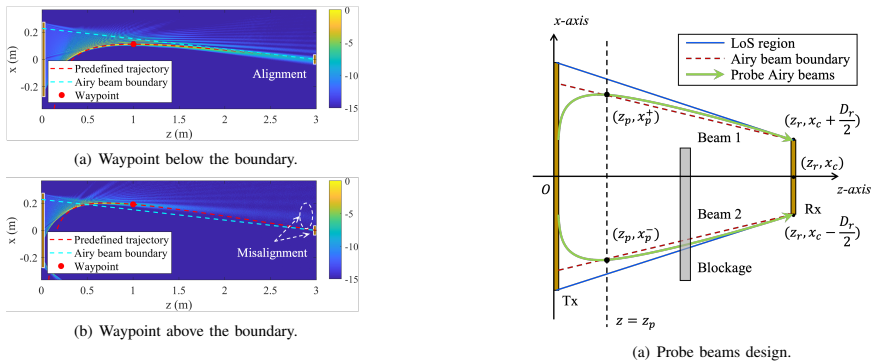
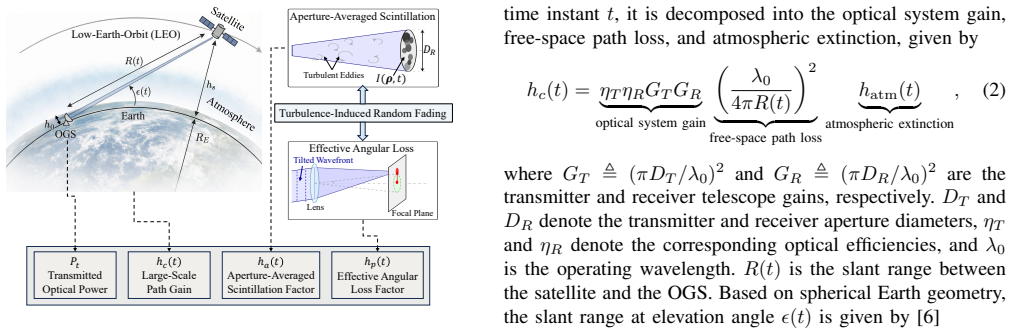
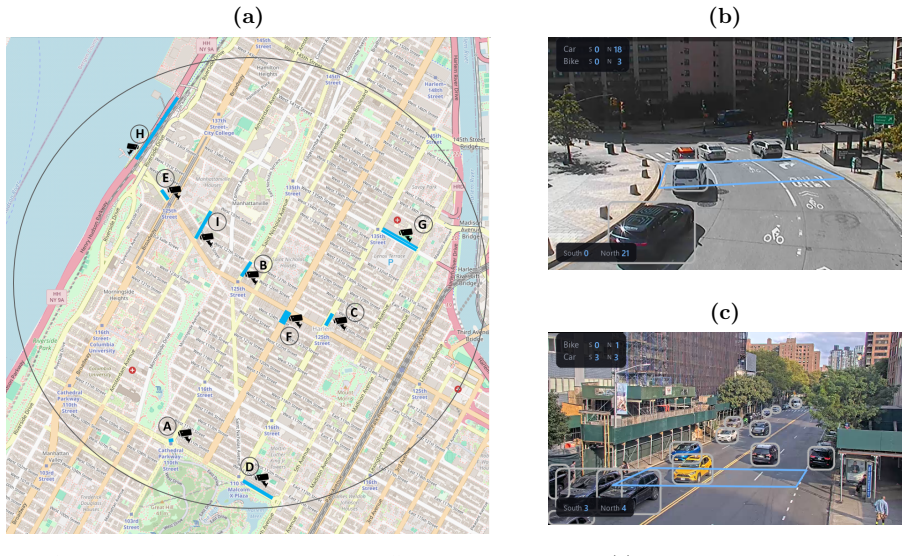
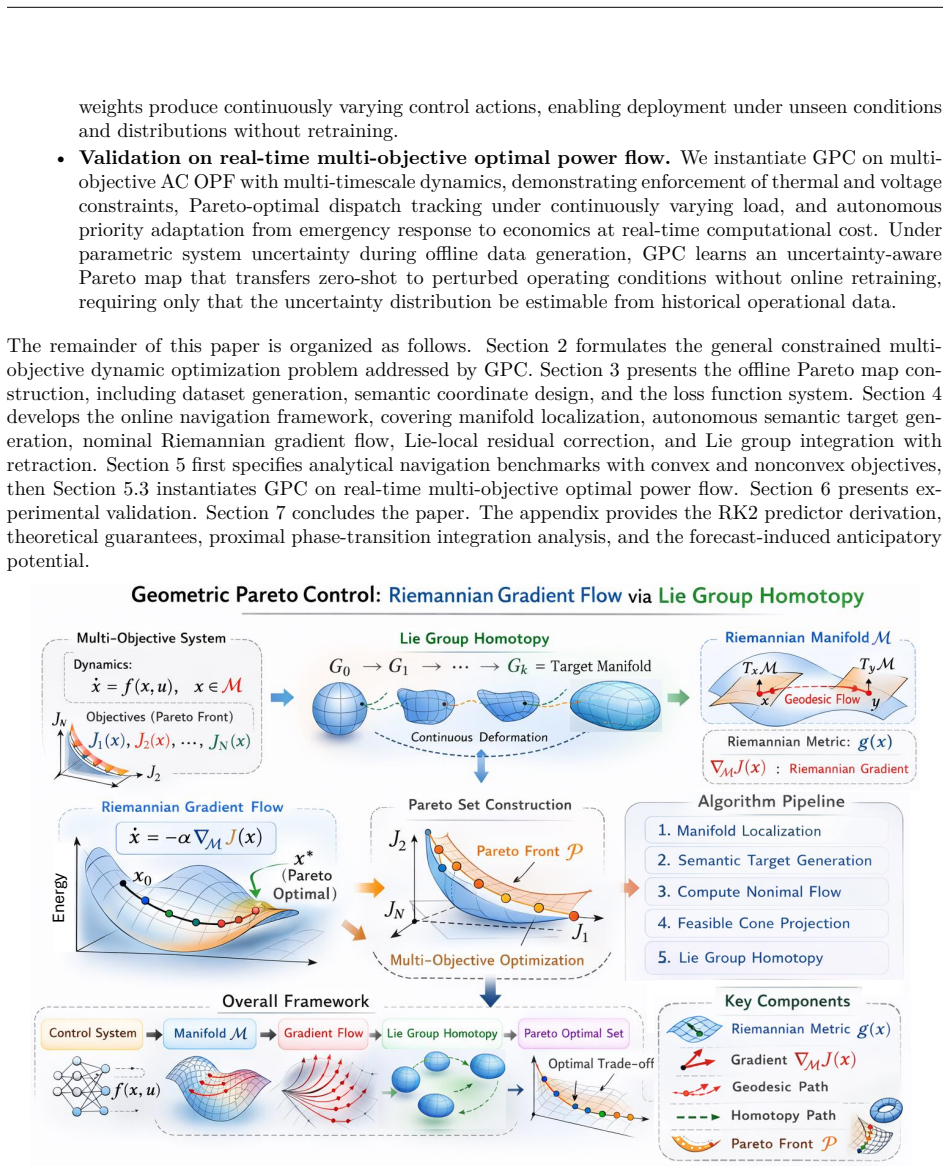
0
Turnpike property stabilizes receding horizon games without terminals
Towards Closed-loop Stability of Nonlinear Receding Horizon Games
Recursive feasibility and practical convergence to equilibrium follow from mild assumptions on dynamics and costs, with attraction regions,
 full image
full image
abstract click to expand
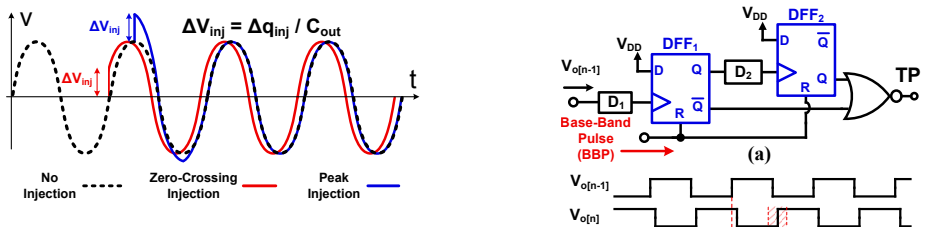
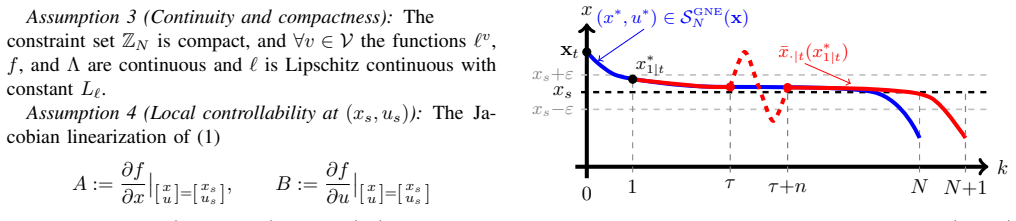
We analyze Receding Horizon Games without any MPC-like terminal ingredients. We show that recursive feasibility can be inferred from the turnpike phenomenon under mild assumptions. Moreover, we prove sufficient conditions for practical asymptotic convergence of the closed-loop trajectories, and we discuss how the gap towards practical asymptotic stability may be closed. We use numerical examples to show that the closed-loop region of attraction around the steady-state GNE shrinks exponentially with the horizon length, a behavior previously known only for model predictive control. Further, we apply a linear end penalty and demonstrate in numerical simulations that it suppresses the leaving arc and ensures asymptotic convergence to the steady-state GNE.