Semi-Supervised Model-Free Bayesian State Estimation from Compressed Measurements
Pith reviewed 2026-05-23 23:08 UTC · model grok-4.3
The pith
SemiDANSE adds limited labeled pairs to regularize unsupervised learning and solves under-determined state estimation from compressed measurements in model-free processes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
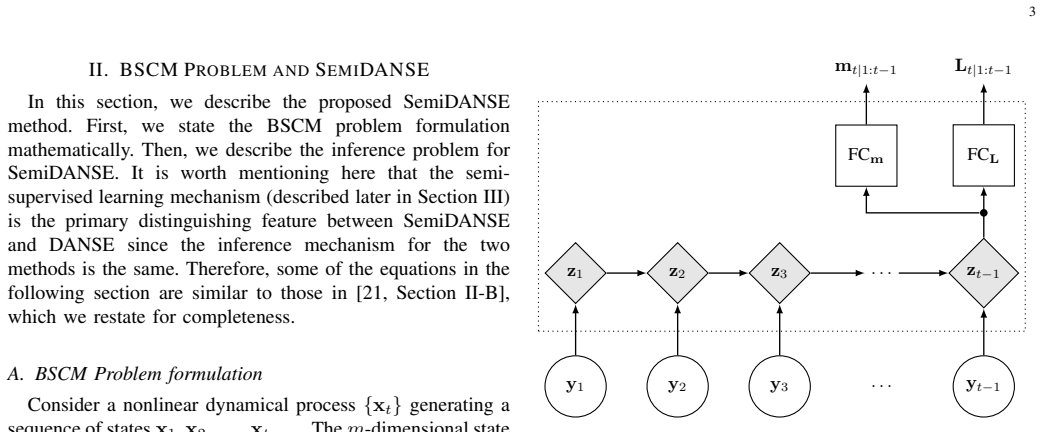
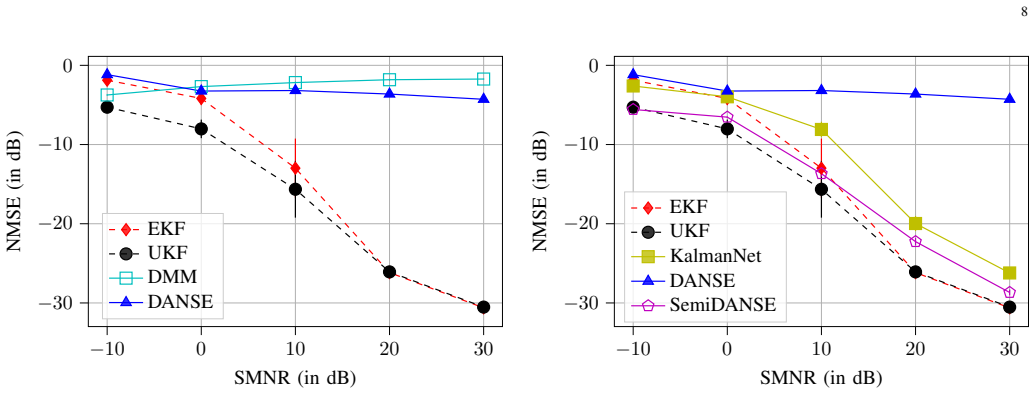
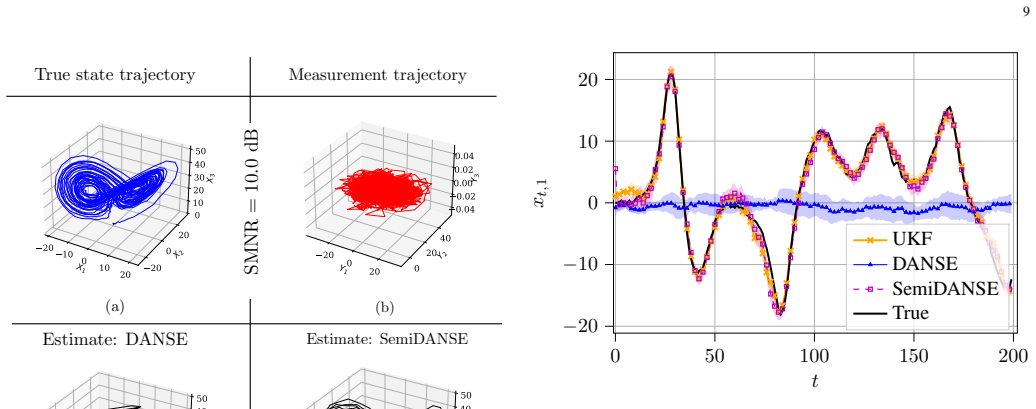
The central claim is that SemiDANSE, a semi-supervised extension of DANSE, uses a large volume of unlabeled measurement time series together with limited pairwise labeled measurement-and-state data to regularize the learning process, thereby solving the under-determined BSCM inverse problem for model-free processes and delivering state estimation performance competitive with both the hybrid KalmanNet and the model-driven extended and unscented Kalman filters that know the dynamics exactly, as shown empirically on benchmark chaotic dynamical systems across several measurement systems.
What carries the argument
SemiDANSE, the semi-supervised DANSE variant that injects limited labeled measurement-state pairs to regularize the unsupervised component for compressed measurement inversion.
If this is right
- SemiDANSE solves BSCM tasks in which the temporal measurement dimension is lower than the state dimension.
- The method operates without any knowledge of the underlying dynamical model.
- It remains competitive when the measurement system changes among a handful of different linear or nonlinear mappings.
- It succeeds on chaotic benchmark systems where purely unsupervised DANSE and deep Markov models fail to produce usable state estimates.
Where Pith is reading between the lines
- The same limited-label regularization pattern could be tested on other under-determined inverse problems that involve temporal data.
- Varying the fraction of labeled pairs while holding total data fixed would reveal how little supervision is actually required for stable performance.
- The approach suggests that hybrid semi-supervised wrappers might improve additional unsupervised time-series estimators beyond the DANSE family.
Load-bearing premise
The limited amount of labelled pairwise measurement-and-state data supplies sufficient regularization to make the unsupervised component solve the under-determined BSCM inverse problem for model-free processes.
What would settle it
If SemiDANSE state estimation errors remain substantially larger than those of the unscented Kalman filter on the same benchmark chaotic systems and measurement setups, the claim of competitive performance from the added regularization would be falsified.
Figures


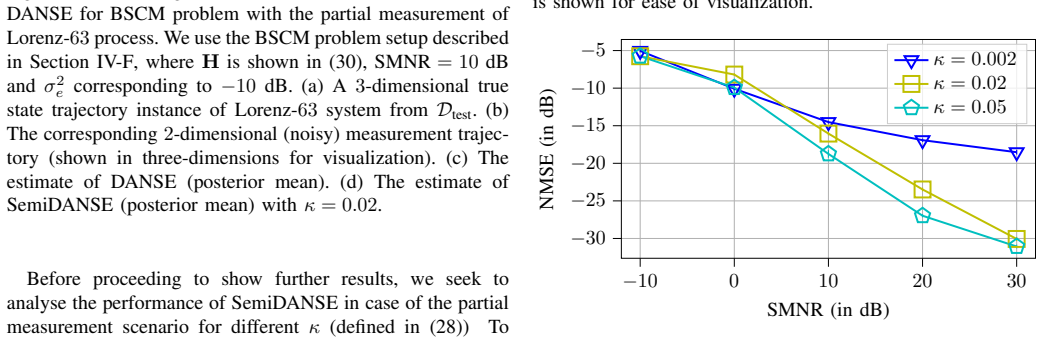
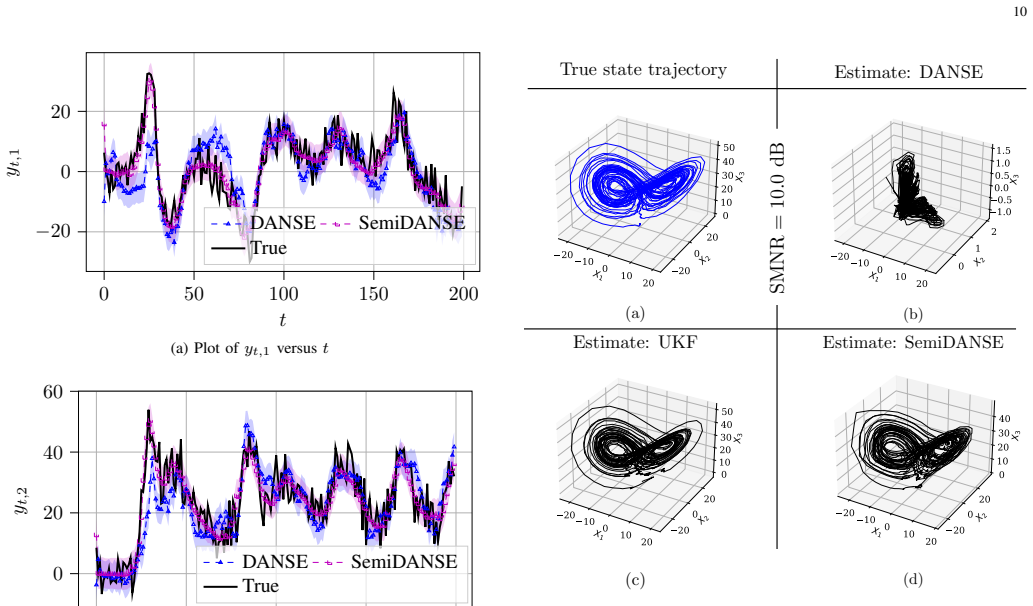

read the original abstract
We consider data-driven Bayesian state estimation from compressed measurements (BSCM) of a model-free process. The dimension of the temporal measurement vector is lower than that of the temporal state vector to be estimated, leading to an under-determined inverse problem. The underlying dynamical model of the state's evolution is unknown for a `model-free process.' Hence, it is difficult to use traditional model-driven methods, for example, Kalman and particle filters. Instead, we consider data-driven methods. We experimentally show that two existing unsupervised learning-based data-driven methods fail to address the BSCM problem in a model-free process. The methods are -- data-driven nonlinear state estimation (DANSE) and deep Markov model (DMM). While DANSE provides good predictive/forecasting performance to model the temporal measurement data as a time series, its unsupervised learning lacks suitable regularization for tackling the BSCM task. We then propose a semi-supervised learning approach and develop a semi-supervised learning-based DANSE method, referred to as SemiDANSE. In SemiDANSE, we use a large amount of unlabelled data along with a limited amount of labelled data, i.e., pairwise measurement-and-state data, which provides the desired regularization. Using {benchmark chaotic dynamical systems}, we {empirically} show that the data-driven SemiDANSE provides competitive state estimation performance for BSCM {using a handful of different measurement systems}, against a hybrid method called KalmanNet and two model-driven methods (extended Kalman filter and unscented Kalman filter) that know the dynamical models exactly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses Bayesian state estimation from compressed measurements (BSCM) for model-free dynamical processes where the state dimension exceeds the measurement dimension. It argues that existing unsupervised data-driven methods (DANSE and DMM) fail due to insufficient regularization, proposes SemiDANSE which augments unsupervised training with limited labelled (measurement, state) pairs, and empirically demonstrates that SemiDANSE achieves competitive estimation performance against the hybrid KalmanNet and the model-aware EKF/UKF on benchmark chaotic systems across multiple measurement operators.
Significance. If the empirical claims are substantiated with proper statistical controls, the work would offer a practical semi-supervised route to model-free state estimation under compression, a setting where purely unsupervised methods are known to be under-regularized and model-based filters are inapplicable. The use of multiple measurement systems and direct comparison to exact-model baselines is a positive feature.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the central claim that 'unsupervised learning lacks suitable regularization' for BSCM rests on the assertion that DANSE and DMM 'fail' while SemiDANSE succeeds, yet no quantitative characterization is given of the labelled-data fraction or compression ratio at which the transition occurs. This quantification is load-bearing for the regularization premise.
- [Experiments] Experiments section: the reported comparisons to EKF, UKF and KalmanNet omit error bars, exact train/validation/test splits, hyperparameter-search protocol, and any statistical significance testing. Without these, it is impossible to determine whether SemiDANSE is statistically competitive or whether the results reflect post-hoc measurement-system choices.
- [SemiDANSE formulation / Experiments] § on SemiDANSE formulation: the paper does not provide an ablation or sensitivity analysis showing how performance scales with the number of labelled pairs; the weakest assumption—that a small labelled set suffices to regularize the under-determined inverse problem—therefore remains untested at the level required to support the competitiveness claim.
minor comments (1)
- [Notation / Experiments] Notation for the measurement operator and compression ratio should be introduced once and used consistently; currently the abstract refers to 'a handful of different measurement systems' without a table summarizing the operators and their dimensions.
Simulated Author's Rebuttal
Thank you for the thorough review. We address the major comments below and will revise the manuscript accordingly to strengthen the experimental validation.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim that 'unsupervised learning lacks suitable regularization' for BSCM rests on the assertion that DANSE and DMM 'fail' while SemiDANSE succeeds, yet no quantitative characterization is given of the labelled-data fraction or compression ratio at which the transition occurs. This quantification is load-bearing for the regularization premise.
Authors: We agree that quantifying the transition would provide stronger support for the regularization premise. In the revised version, we will include additional experiments that vary the fraction of labeled data and report the performance of DANSE, DMM, and SemiDANSE across a range of labeled fractions and compression ratios to characterize the point at which unsupervised methods begin to fail. revision: yes
-
Referee: [Experiments] Experiments section: the reported comparisons to EKF, UKF and KalmanNet omit error bars, exact train/validation/test splits, hyperparameter-search protocol, and any statistical significance testing. Without these, it is impossible to determine whether SemiDANSE is statistically competitive or whether the results reflect post-hoc measurement-system choices.
Authors: We acknowledge the omission of these details. In the revision, we will report error bars from multiple runs, specify the exact train/validation/test splits used, describe the hyperparameter search protocol, and include statistical significance testing (e.g., paired t-tests) to substantiate the competitiveness claims. We will also clarify that the measurement systems were chosen based on standard benchmarks rather than post-hoc selection. revision: yes
-
Referee: [SemiDANSE formulation / Experiments] § on SemiDANSE formulation: the paper does not provide an ablation or sensitivity analysis showing how performance scales with the number of labelled pairs; the weakest assumption—that a small labelled set suffices to regularize the under-determined inverse problem—therefore remains untested at the level required to support the competitiveness claim.
Authors: We agree that an ablation study on the number of labeled pairs is important to validate the assumption that a small labeled set suffices. We will add a sensitivity analysis in the revised manuscript showing how the estimation performance of SemiDANSE scales with the number of labeled pairs (e.g., from 10 to 1000 pairs) for the benchmark systems. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper advances a semi-supervised extension (SemiDANSE) of an existing unsupervised method and validates it solely through numerical experiments on standard chaotic dynamical systems, comparing against EKF, UKF (model-aware) and KalmanNet. No derivation, uniqueness theorem, or fitted-parameter prediction is offered; the central claim is that limited labelled pairs suffice for regularization, which is tested rather than assumed by construction. All load-bearing steps are external comparisons, so the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network architecture and training hyperparameters
axioms (1)
- domain assumption Limited labeled pairs provide the desired regularization for the BSCM task
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop a semi-supervised learning-based method called semi-supervised DANSE (SemiDANSE) to tackle the BSCM problem for a model-free process... using a limited amount of labelled data along with a large amount of unlabeled data for offline training
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the unsupervised learning problem in DANSE... fails to tackle the BSCM problem... owing to a lack of suitable regularization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
pDANSE: Particle-based Data-driven Nonlinear State Estimation from Nonlinear Measurements
pDANSE enables nonlinear state estimation for model-free processes by using RNN-parameterized Gaussian priors and reparameterization-based particle sampling to compute posterior second-order statistics from nonlinear ...
Reference graph
Works this paper leans on
-
[1]
S. S ¨arkk¨a and L. Svensson, Bayesian filtering and smoothing , vol. 17, Cambridge university press, 2023
work page 2023
-
[2]
Simon, Optimal state estimation: Kalman, H∞, and nonlinear approaches, John Wiley & Sons, 2006
D. Simon, Optimal state estimation: Kalman, H∞, and nonlinear approaches, John Wiley & Sons, 2006
work page 2006
-
[3]
T. D. Barfoot, State estimation for robotics, Cambridge University Press, 2024
work page 2024
-
[4]
New results in linear filtering and prediction theory,
R.E. Kalman, “New results in linear filtering and prediction theory,” J. Basic Eng., vol. 83, pp. 95–108, 1961
work page 1961
-
[5]
A new approach to linear filtering and prediction problems,
R.E. Kalman, “A new approach to linear filtering and prediction problems,” Trans. ASME, D , vol. 82, pp. 35–44, 1960
work page 1960
-
[6]
An approach to target tracking,
M. Gruber, “An approach to target tracking,” Tech. Rep., MIT Lexington Lincoln Lab, 1967
work page 1967
-
[7]
Unscented filtering and nonlinear estimation,
S.J. Julier and J.K. Uhlmann, “Unscented filtering and nonlinear estimation,” Proceedings of the IEEE , vol. 92, no. 3, pp. 401–422, 2004
work page 2004
-
[8]
A tutorial on particle filters for online nonlinear/non-gaussian bayesian tracking,
M. S. Arulampalam, S. Maskell, N. Gordon, and T. Clapp, “A tutorial on particle filters for online nonlinear/non-gaussian bayesian tracking,” IEEE Transactions on Signal Processing , vol. 50, no. 2, pp. 174–188, 2002
work page 2002
-
[9]
GP-BayesFilters: Bayesian filtering using Gaussian process prediction and observation models,
J. Ko and D. Fox, “GP-BayesFilters: Bayesian filtering using Gaussian process prediction and observation models,” Autonomous Robots , vol. 27, pp. 75–90, 2009
work page 2009
-
[10]
Bayesian inference and learning in gaussian process state-space models with particle mcmc,
R. Frigola, F. Lindsten, T. B. Sch ¨on, and C. E. Rasmussen, “Bayesian inference and learning in gaussian process state-space models with particle mcmc,” Advances in Neural Information Processing Systems , vol. 26, 2013
work page 2013
-
[11]
Computationally efficient bayesian learning of gaussian process state space models,
A. Svensson, A. Solin, S. S ¨arkk¨a, and T. B. Sch ¨on, “Computationally efficient bayesian learning of gaussian process state space models,” in Artificial Intelligence and Statistics (AISTATS) . PMLR, 2016, pp. 213– 221
work page 2016
-
[12]
EKFNet: Learning system noise statistics from measurement data,
L. Xu and R. Niu, “EKFNet: Learning system noise statistics from measurement data,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2021, pp. 4560–4564
work page 2021
-
[13]
Combining generative and discriminative models for hybrid inference,
V . Garcia Satorras, Z. Akata, and M. Welling, “Combining generative and discriminative models for hybrid inference,” Advances in Neural Information Processing Systems , vol. 32, 2019
work page 2019
-
[14]
A mnemonic Kalman filter for non-linear systems with extensive temporal dependencies,
S. Jung, I. Schlangen, and A. Charlish, “A mnemonic Kalman filter for non-linear systems with extensive temporal dependencies,” IEEE Signal Processing Letters, vol. 27, pp. 1005–1009, 2020
work page 2020
-
[15]
End-to-end semi- supervised learning for differentiable particle filters,
H. Wen, X. Chen, G. Papagiannis, C. Hu, and Y . Li, “End-to-end semi- supervised learning for differentiable particle filters,” in 2021 IEEE International Conference on Robotics and Automation (ICRA) , 2021, pp. 5825–5831
work page 2021
-
[16]
Dynamical variational autoencoders: A comprehensive review,
L. Girin, S. Leglaive, X. Bie, J. Diard, T. Hueber, and X. Alameda- Pineda, “Dynamical variational autoencoders: A comprehensive review,” Foundations and Trends in Machine Learning , vol. 15, no. 1-2, pp. 1– 175, 2021
work page 2021
-
[17]
A disentangled recognition and nonlinear dynamics model for unsupervised learning,
M. Fraccaro, S. Kamronn, U. Paquet, and O. Winther, “A disentangled recognition and nonlinear dynamics model for unsupervised learning,” Advances in Neural Information Processing Systems , vol. 30, 2017
work page 2017
-
[18]
R.G. Krishnan, U. Shalit, and D. Sontag, “Deep Kalman filters,” arXiv preprint arXiv:1511.05121, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[19]
Structured inference networks for nonlinear state space models,
R. Krishnan, U. Shalit, and D. Sontag, “Structured inference networks for nonlinear state space models,” in Proceedings of the AAAI Confer- ence on Artificial Intelligence , 2017, vol. 31
work page 2017
-
[20]
DANSE: Data-Driven Non-Linear State Estimation of Model-Free Process in Unsupervised Bayesian Setup,
A. Ghosh, A. Honor ´e, and S. Chatterjee, “DANSE: Data-Driven Non-Linear State Estimation of Model-Free Process in Unsupervised Bayesian Setup,” in 2023 31st European Signal Processing Conference (EUSIPCO), 2023, pp. 870–874
work page 2023
-
[21]
DANSE: Data-Driven Non-Linear State Estimation of Model-Free Process in Unsupervised Learning Setup,
A. Ghosh, A. Honor ´e, and S. Chatterjee, “DANSE: Data-Driven Non-Linear State Estimation of Model-Free Process in Unsupervised Learning Setup,” IEEE Transactions on Signal Processing , vol. 72, pp. 1824–1838, 2024
work page 2024
-
[22]
Unsupervised learned Kalman filtering,
G. Revach, N. Shlezinger, T. Locher, X. Ni, R.J.G. van Sloun, and Y .C. Eldar, “Unsupervised learned Kalman filtering,” in 2022 30th European Signal Processing Conference (EUSIPCO). IEEE, 2022, pp. 1571–1575
work page 2022
-
[23]
KalmanNet: Neural network aided Kalman filtering for partially known dynamics,
G. Revach, N. Shlezinger, X. Ni, A. L. Escoriza, R.J.G. Van Sloun, and Y .C. Eldar, “KalmanNet: Neural network aided Kalman filtering for partially known dynamics,” IEEE Transactions on Signal Processing , vol. 70, pp. 1532–1547, 2022
work page 2022
-
[24]
Adaptive Kalmannet: Data-Driven Kalman Filter with Fast Adaptation,
X. Ni, G. Revach, and N. Shlezinger, “Adaptive Kalmannet: Data-Driven Kalman Filter with Fast Adaptation,” in ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 5970–5974
work page 2024
-
[25]
Split- KalmanNet: A Robust Model-Based Deep Learning Approach for State Estimation,
G. Choi, J. Park, N. Shlezinger, Y . C. Eldar, and N. Lee, “Split- KalmanNet: A Robust Model-Based Deep Learning Approach for State Estimation,” IEEE Transactions on Vehicular Technology , vol. 72, no. 9, pp. 12326–12331, Sept. 2023
work page 2023
-
[26]
MAML- KalmanNet: A Neural Network-Assisted Kalman Filter Based on Model- Agnostic Meta-Learning,
S. Chen, Y . Zheng, D. Lin, P. Cai, Y . Xiao, and S. Wang, “MAML- KalmanNet: A Neural Network-Assisted Kalman Filter Based on Model- Agnostic Meta-Learning,” IEEE Transactions on Signal Processing , 2025
work page 2025
-
[27]
T. Li, Y . Song, and H. Fan, “From target tracking to targeting track: A data-driven yet analytical approach to joint target detection and tracking,” Signal Processing, vol. 205, pp. 108883, 2023
work page 2023
-
[28]
O. Chapelle, B. Schlkopf, and A. Zien, Semi-Supervised Learning, The MIT Press, 1st edition, 2010
work page 2010
-
[29]
Introduction to semi-supervised learning,
X. Zhu and A. B. Goldberg, “Introduction to semi-supervised learning,” Synthesis Lectures on Artificial Intelligence and Machine Learning , 2009
work page 2009
-
[30]
A survey on deep semi-supervised learning,
X. Yang, Z. Song, I. King, and Z. Xu, “A survey on deep semi-supervised learning,” IEEE Transactions on Knowledge and Data Engineering , 2022
work page 2022
-
[31]
A survey on semi-supervised learning,
J. E. Van Engelen and H. H. Hoos, “A survey on semi-supervised learning,” Machine learning, vol. 109, no. 2, pp. 373–440, 2020
work page 2020
-
[32]
Semi- supervised regression: A recent review,
G. Kostopoulos, S. Karlos, S. Kotsiantis, and O. Ragos, “Semi- supervised regression: A recent review,” Journal of Intelligent & Fuzzy Systems, vol. 35, no. 2, pp. 1483–1500, 2018
work page 2018
-
[33]
Deterministic nonperiodic flow,
E.N. Lorenz, “Deterministic nonperiodic flow,” Journal of atmospheric sciences, vol. 20, no. 2, pp. 130–141, 1963
work page 1963
-
[34]
On the generalized lorenz canonical form,
S. ˇCelikovsk`y and G. Chen, “On the generalized lorenz canonical form,” Chaos, Solitons & Fractals , vol. 26, no. 5, pp. 1271–1276, 2005
work page 2005
-
[35]
Yet another chaotic attractor,
G. Chen and T. Ueta, “Yet another chaotic attractor,” International Journal of Bifurcation and chaos , vol. 9, no. 07, pp. 1465–1466, 1999
work page 1999
-
[36]
An equation for continuous chaos,
O.E. R ¨ossler, “An equation for continuous chaos,” Physics Letters A , vol. 57, no. 5, pp. 397–398, 1976
work page 1976
-
[37]
On the properties of neural machine translation: Encoder–decoder approaches,
K. Cho, B. van Merri ¨enboer, D. Bahdanau, and Y . Bengio, “On the properties of neural machine translation: Encoder–decoder approaches,” in Proceedings of 8th Workshop on Syntax, Semantics and Structure in Statistical Translation (SSST-8), 2014, pp. 103–111
work page 2014
-
[38]
C. M. Bishop and N. M. Nasrabadi, Pattern recognition and machine learning, vol. 4, Springer, 2006
work page 2006
-
[39]
J. C. Sprott, Chaos and time-series analysis , Oxford university press, 2003
work page 2003
-
[40]
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
work page 1997
-
[41]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszke et al., “PyTorch: An imperative style, high-performance deep learning library,” Advances in Neural Information Processing Systems , vol. 32, 2019
work page 2019
-
[42]
Adam: A method for stochastic optimization,
D.P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in 3rd International Conference on Learning Representations (ICLR) , 2015
work page 2015
-
[43]
FilterPy - Kalman and Bayesian filters in Python,
R. Labbe, “FilterPy - Kalman and Bayesian filters in Python,” URL: https://filterpy.readthedocs.io/en/latest/, 2018
work page 2018
-
[44]
I. Goodfellow, Y . Bengio, and A. Courville, Deep learning, MIT press, 2016
work page 2016
-
[45]
Backpropagation through time: what it does and how to do it,
P. J. Werbos, “Backpropagation through time: what it does and how to do it,” Proceedings of the IEEE , vol. 78, no. 10, pp. 1550–1560, 1990
work page 1990
-
[46]
Auto-encoding variational bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in 2nd International Conference on Learning Representations, (ICLR) , Yoshua Bengio and Yann LeCun, Eds., 2014
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.