Adversarial Robustness of Graph Transformers
Pith reviewed 2026-05-23 22:52 UTC · model grok-4.3
The pith
Graph Transformers are catastrophically fragile to adaptive structure perturbations across multiple tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
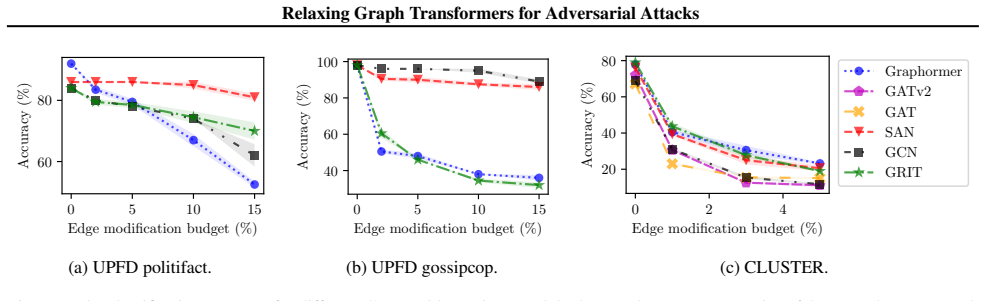
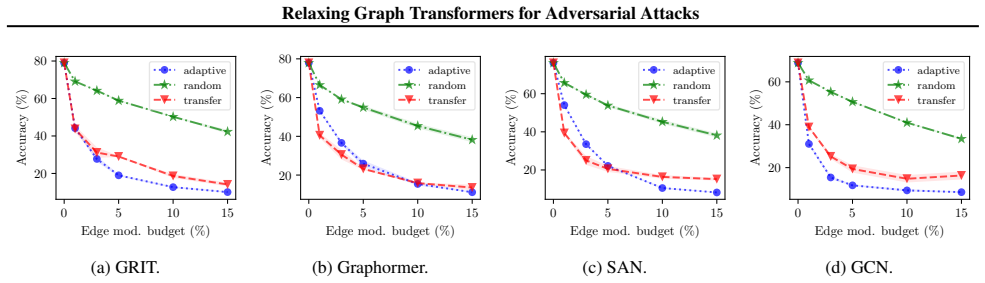
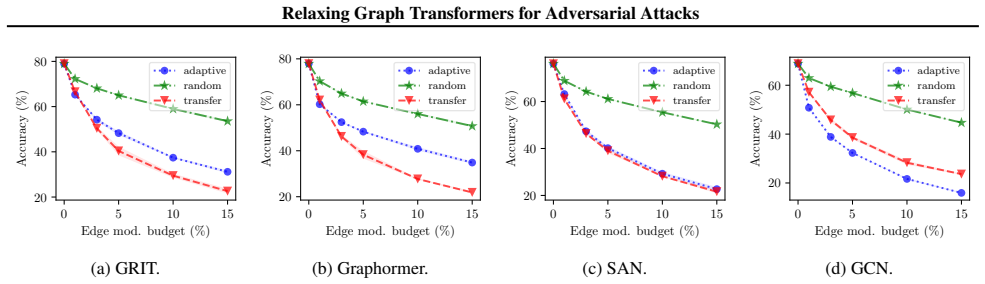
We close this gap and design the first adaptive attacks for GTs. In particular, we provide general design principles for strong gradient-based attacks on GTs w.r.t. structure perturbations and instantiate our attack framework for five representative and popular GT architectures. Specifically, we study GTs with specialized attention mechanisms and Positional Encodings (PEs) based on pairwise shortest paths, random walks, and the Laplacian spectrum. We evaluate our attacks on multiple tasks and perturbation models, including structure perturbations for node and graph classification, and node injection for graph classification. Our results reveal that GTs can be catastrophically fragile in many
What carries the argument
Adaptive gradient-based attack framework instantiated for GT attention mechanisms and positional encodings (shortest-path, random-walk, Laplacian) that generates structure perturbations.
If this is right
- GTs using any of the three tested positional-encoding families remain vulnerable to structure changes.
- The same adaptive attacks can be reused for adversarial training and produce substantial robustness gains.
- Node-injection perturbations also succeed against GTs on graph-classification tasks.
- Fragility appears on both node-level and graph-level classification.
Where Pith is reading between the lines
- The global receptive field created by attention may be the structural reason perturbations spread more effectively than in local message-passing models.
- Defenses developed for MPNNs may need re-examination before being applied to GTs.
- Future architecture variants that restrict attention range could be tested directly with the same attack generator.
Load-bearing premise
The gradient-based attack framework instantiated for the five GT architectures produces perturbations that are stronger than non-adaptive baselines and therefore reveal the true robustness level of the models.
What would settle it
An experiment showing that standard non-adaptive or non-gradient attacks achieve equal or higher success rates than the proposed adaptive framework on the tested GT models and tasks would falsify the reported fragility levels.
Figures


read the original abstract
Existing studies have shown that Message-Passing Graph Neural Networks (MPNNs) are highly susceptible to adversarial attacks. In contrast, despite the increasing importance of Graph Transformers (GTs), their robustness properties are unexplored. We close this gap and design the first adaptive attacks for GTs. In particular, we provide general design principles for strong gradient-based attacks on GTs w.r.t. structure perturbations and instantiate our attack framework for five representative and popular GT architectures. Specifically, we study GTs with specialized attention mechanisms and Positional Encodings (PEs) based on pairwise shortest paths, random walks, and the Laplacian spectrum. We evaluate our attacks on multiple tasks and perturbation models, including structure perturbations for node and graph classification, and node injection for graph classification. Our results reveal that GTs can be catastrophically fragile in many cases. Addressing this vulnerability, we show how our adaptive attacks can be effectively used for adversarial training, substantially improving robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to close the gap on robustness of Graph Transformers (GTs) by designing the first adaptive gradient-based attacks on structure perturbations for five representative GT architectures (with attention mechanisms and positional encodings based on shortest paths, random walks, and Laplacian spectrum). It evaluates these on node/graph classification and node injection tasks, concluding that GTs are catastrophically fragile in many cases, and shows the attacks can be repurposed for adversarial training to improve robustness.
Significance. If the empirical results hold and the adaptive attacks are shown to be strictly stronger than non-adaptive baselines, the work would be significant as the first systematic robustness study of GTs (an increasingly popular alternative to MPNNs). The adversarial training application is a constructive contribution. The absence of quantitative attack success rates, error bars, or explicit baseline comparisons in the provided abstract limits immediate assessment of impact.
major comments (2)
- [Evaluation / Experiments] The central claim that GTs are 'catastrophically fragile' (abstract) is load-bearing on the adaptive attacks outperforming non-adaptive baselines that ignore PE recomputation or attention structure. The manuscript must include explicit comparisons (e.g., success rates, tables) showing the instantiated attacks for the five GT variants are stronger; without this, fragility cannot be attributed to the GT architectures themselves.
- [Attack Design] The attack framework is described as 'general design principles' instantiated for five GTs, but the manuscript should clarify in the methods whether the gradient attacks account for the specific PE recomputation (shortest-path, random-walk, Laplacian) during perturbation search, as failure to do so would reduce the attacks to non-adaptive baselines.
minor comments (2)
- [Abstract] The abstract states results 'reveal that GTs can be catastrophically fragile in many cases' but provides no quantitative metrics, datasets, or attack success rates; these should be summarized with numbers and error bars for clarity.
- [Introduction / Preliminaries] Notation for the five GT architectures and their PEs should be introduced consistently early in the paper to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of our adaptive attacks.
read point-by-point responses
-
Referee: [Evaluation / Experiments] The central claim that GTs are 'catastrophically fragile' (abstract) is load-bearing on the adaptive attacks outperforming non-adaptive baselines that ignore PE recomputation or attention structure. The manuscript must include explicit comparisons (e.g., success rates, tables) showing the instantiated attacks for the five GT variants are stronger; without this, fragility cannot be attributed to the GT architectures themselves.
Authors: We agree that explicit side-by-side comparisons are necessary to substantiate the claim. Our attacks are constructed to be adaptive by recomputing PEs and updating attention scores at each gradient step, but the current manuscript presents results primarily for the adaptive versions without a dedicated baseline table. In the revision we will add a new table (and associated text) reporting attack success rates for both adaptive and non-adaptive variants across the five GT architectures on the node- and graph-classification tasks. This will allow readers to directly verify that the adaptive formulation yields strictly higher success rates. revision: yes
-
Referee: [Attack Design] The attack framework is described as 'general design principles' instantiated for five GTs, but the manuscript should clarify in the methods whether the gradient attacks account for the specific PE recomputation (shortest-path, random-walk, Laplacian) during perturbation search, as failure to do so would reduce the attacks to non-adaptive baselines.
Authors: The attacks are intended to be fully adaptive and do incorporate PE recomputation inside the inner optimization loop for each of the three PE families. However, the current methods section describes the high-level design principles without spelling out the per-PE recomputation step. We will expand the methods subsection on attack instantiation to explicitly state, for each GT variant, how the corresponding PE matrix is recomputed after every edge perturbation before the next gradient step is taken. This clarification will remove any ambiguity about adaptivity. revision: yes
Circularity Check
No circularity: empirical attack design and evaluation are self-contained
full rationale
The paper is an empirical study that designs gradient-based adaptive attacks for five GT architectures (with attention and PE specifics) and reports attack success rates on node/graph classification tasks. No equations, predictions, or first-principles derivations are present that reduce reported robustness numbers to quantities fitted inside the paper or to self-citations. The central claim (GT fragility) rests on experimental comparisons to non-adaptive baselines, which are externally falsifiable and not tautological by construction. Minor self-citations to prior MPNN attack work are not load-bearing for the GT-specific results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient-based optimization can be applied to discrete graph structure perturbations while respecting the attention and positional encoding mechanisms of GTs.
Reference graph
Works this paper leans on
-
[1]
Adver- sarial attacks on neural networks for graph data,
D. Z ¨ugner, A. Akbarnejad, and S. G ¨unnemann, “Adver- sarial attacks on neural networks for graph data,” in Pro- ceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , Jul. 2018, pp. 2847–2856
work page 2018
-
[2]
Adversarial attacks on graph neural networks via meta learning,
D. Z ¨ugner and S. G ¨unnemann, “Adversarial attacks on graph neural networks via meta learning,” in International Conference on Learning Representations, 2019
work page 2019
-
[3]
Certifiable robustness of graph convolutional networks under structure perturba- tions,
D. Z¨ugner and S. G¨unnemann, “Certifiable robustness of graph convolutional networks under structure perturba- tions,” inProceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , Aug. 2020, pp. 1656–1665
work page 2020
-
[4]
Semi-supervised classifica- tion with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classifica- tion with graph convolutional networks,” inInternational Conference on Learning Representations, 2017
work page 2017
-
[5]
At- tending to graph transformers,
L. M¨uller, M. Galkin, C. Morris, and L. Ramp ´aˇsek, “At- tending to graph transformers,”Transactions on Machine Learning Research, Feb. 2024
work page 2024
-
[6]
A. Athalye, N. Carlini, and D. Wagner, “Obfuscated gradi- ents give a false sense of security: Circumventing defenses to adversarial examples,” in Proceedings of the 35th In- ternational Conference on Machine Learning, Jul. 2018, pp. 274–283
work page 2018
-
[7]
Towards evaluating the robust- ness of neural networks,
N. Carlini and D. Wagner, “Towards evaluating the robust- ness of neural networks,” in Proceedings - IEEE Sympo- sium on Security and Privacy, 2017, pp. 39–57
work page 2017
-
[8]
On adaptive attacks to adversarial example defenses,
F. Tram`er, N. Carlini, W. Brendel, and A. Madry, “On adaptive attacks to adversarial example defenses,” inPro- ceedings of the 34th International Conference on Neural Information Processing Systems, 2020
work page 2020
-
[9]
Are defenses for graph neural networks robust?
F. Mujkanovic, S. Geisler, S. G ¨unnemann, and A. Bo- jchevski, “Are defenses for graph neural networks robust?” In Proceedings of the 36th International Conference on Neural Information Processing Systems, 2022
work page 2022
-
[10]
Graph inductive biases in transformers without message passing,
L. Ma, C. Lin, D. Lim, et al., “Graph inductive biases in transformers without message passing,” in Proceedings of the 40th International Conference on Machine Learning, 2023, pp. 23 321–23 337
work page 2023
-
[11]
Do transformers really perform bad for graph representation?
C. Ying, T. Cai, S. Luo, et al., “Do transformers really perform bad for graph representation?” In Proceedings of the 35th International Conference on Neural Information Processing Systems, 2021
work page 2021
-
[12]
Rethinking graph transformers with spectral attention,
D. Kreuzer, D. Beaini, W. L. Hamilton, V . L´etourneau, and P. Tossou, “Rethinking graph transformers with spectral attention,” in Proceedings of the 35th International Confer- ence on Neural Information Processing Systems, 2021
work page 2021
-
[13]
Topology attack and defense for graph neural networks: An optimization perspective,
K. Xu, H. Chen, S. Liu,et al., “Topology attack and defense for graph neural networks: An optimization perspective,” in IJCAI’19: Proceedings of the 28th International Joint Conference on Artificial Intelligence, Jun. 2019, pp. 3961– 3967
work page 2019
-
[14]
Robustness of graph neural networks at scale,
S. Geisler, T. Schmidt, H. S ¸irin, D. Z¨ugner, A. Bojchevski, and S. G¨unnemann, “Robustness of graph neural networks at scale,” inProceedings of the 35th International Confer- ence on Neural Information Processing Systems, 2021
work page 2021
-
[15]
A. Vaswani, N. Shazeer, N. Parmar, et al., “Attention is all you need,” in Proceedings of the 31st International Conference on Neural Information Processing Systems , 2017, 6000–6010
work page 2017
-
[16]
Graph neural networks with learnable structural and positional representations,
V . P. Dwivedi, A. T. Luu, T. Laurent, Y . Bengio, and X. Bresson, “Graph neural networks with learnable structural and positional representations,” Oct. 2022
work page 2022
-
[17]
Transformers meet directed graphs,
S. Geisler, Y . Li, D. Mankowitz, A. T. Cemgil, S. G¨unnemann, and C. Paduraru, “Transformers meet directed graphs,” inProceedings of the 40th International Confer- ence on Machine Learning, Jan. 2023, pp. 11 144–11 172
work page 2023
-
[18]
P. Li, Y . Wang, H. Wang, and J. Leskovec, “Distance encod- ing: Design provably more powerful neural networks for graph representation learning,” Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS), Dec. 2020
work page 2020
-
[19]
A generalization of trans- former networks to graphs,
V . P. Dwivedi and X. Bresson, “A generalization of trans- former networks to graphs,” AAAI Workshop on Deep Learning on Graphs: Methods and Applications , Dec. 2021
work page 2021
-
[20]
G. W. Stewart and J. Sun, Matrix Perturbation Theory . 1990, ISBN : 9780126702309
work page 1990
-
[21]
Bamieh, A tutorial on matrix perturbation theory (using compact matrix notation) , 2022
B. Bamieh, A tutorial on matrix perturbation theory (using compact matrix notation) , 2022. arXiv: 2002 . 05001 [math.SP]
work page 2022
-
[22]
Scalable attack on graph data by injecting vicious nodes,
J. Wang, M. Luo, F. Suya, J. Li, Z. Yang, and Q. Zheng, “Scalable attack on graph data by injecting vicious nodes,” Data Min. Knowl. Discov., vol. 34, no. 5, 1363–1389, Sep. 2020
work page 2020
-
[23]
Attacking large language models with projected gradient descent,
S. Geisler, T. Wollschl¨ager, M. H. I. Abdalla, J. Gasteiger, and S. G¨unnemann, “Attacking large language models with projected gradient descent,” inICML Workshop on NextGe- nAISafety, Jul. 2024
work page 2024
-
[24]
Benchmarking graph neural networks,
V . P. Dwivedi, C. K. Joshi, A. T. Luu, T. Laurent, Y . Bengio, and X. Bresson, “Benchmarking graph neural networks,” Journal of Machine Learning Research , vol. 24, no. 43, pp. 1–48, 2023
work page 2023
-
[25]
Adversarial attack on graph structured data,
H. Dai, H. Li, T. Tian, et al., “Adversarial attack on graph structured data,” inProceedings of the 35th International Conference on Machine Learning, 2018
work page 2018
-
[26]
Adversarial attacks and de- fenses on graphs: A review, a tool and empirical studies,
W. Jin, Y . Li, H. Xu, et al., “Adversarial attacks and de- fenses on graphs: A review, a tool and empirical studies,” SIGKDD Explor. Newsl., vol. 22, pp. 19–34, 2 2021
work page 2021
-
[27]
Graph neural networks: Adversarial ro- bustness,
S. G¨unnemann, “Graph neural networks: Adversarial ro- bustness,” inGraph Neural Networks: Foundations, Fron- tiers, and Applications, L. Wu, P. Cui, J. Pei, and L. Zhao, Eds. 2022, pp. 149–176, ISBN : 9789811660542
work page 2022
-
[28]
Collective robustness certificates: Exploiting interdependence in graph neural networks,
J. Schuchardt, J. Gasteiger, A. Bojchevski, and S. G¨unnemann, “Collective robustness certificates: Exploiting interdependence in graph neural networks,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[29]
Randomized message-interception smooth- ing: Gray-box certificates for graph neural networks,
Y . Scholten, J. Schuchardt, S. Geisler, A. Bojchevski, and S. G¨unnemann, “Randomized message-interception smooth- ing: Gray-box certificates for graph neural networks,” inAd- vances in Neural Information Processing Systems, NeurIPS, 2022. 5 Relaxing Graph Transformers for Adversarial Attacks
work page 2022
-
[30]
On the adversarial robustness of graph contrastive learning methods,
F. Guerranti, Z. Yi, A. Starovoit, R. Kamel, S. Geisler, and S. G ¨unnemann, “On the adversarial robustness of graph contrastive learning methods,” in NeurIPS Workshop on Graph Learning Frontiers, Dec. 2023
work page 2023
-
[31]
Re- visiting robustness in graph machine learning,
L. Gosch, D. Sturm, S. Geisler, and S. G¨unnemann, “Re- visiting robustness in graph machine learning,” in The Eleventh International Conference on Learning Represen- tations (ICLR), 2023
work page 2023
-
[32]
A graph transformer defence against graph perturbation by a flexible-pass filter,
Y . Zhu, J. Huang, Y . Chen, R. Amor, and M. Witbrock, “A graph transformer defence against graph perturbation by a flexible-pass filter,”Information Fusion, vol. 107, Jul. 2024
work page 2024
-
[33]
Adversarial training for graph neu- ral networks: Pitfalls, solutions, and new directions,
L. Gosch, S. Geisler, D. Sturm, B. Charpentier, D. Z¨ugner, and S. G ¨unnemann, “Adversarial training for graph neu- ral networks: Pitfalls, solutions, and new directions,” in Thirty-seventh Conference on Neural Information Process- ing Systems (NeurIPS), 2023
work page 2023
-
[34]
Graph structural attack by perturbing spectral distance,
L. Lin, E. Blaser, and H. Wang, “Graph structural attack by perturbing spectral distance,” inProceedings of the ACM SIGKDD International Conference on Knowledge Discov- ery and Data Mining, Aug. 2022, pp. 989–998
work page 2022
-
[35]
High-order proximity preserved embedding for dynamic networks,
D. Zhu, P. Cui, Z. Zhang, J. Pei, and W. Zhu, “High-order proximity preserved embedding for dynamic networks,” IEEE Transactions on Knowledge and Data Engineering, vol. 30, pp. 2134–2144, 11 Nov. 2018
work page 2018
-
[36]
Adversarial attacks on node embeddings via graph poisoning,
A. Bojchevski and S. G¨unnemann, “Adversarial attacks on node embeddings via graph poisoning,” in Proceedings of the 36th International Conference on Machine Learning, 2019, pp. 695–704
work page 2019
-
[37]
Attacking fake news detectors via manipulating news so- cial engagement,
H. Wang, Y . Dou, C. Chen, L. Sun, P. S. Yu, and K. Shu, “Attacking fake news detectors via manipulating news so- cial engagement,” inACM Web Conference - Proceedings of the World Wide Web Conference, WWW, 2023, pp. 3978– 3986
work page 2023
-
[38]
TDGIA: Effective injec- tion attacks on graph neural networks,
X. Zou, Q. Zheng, Y . Dong,et al., “TDGIA: Effective injec- tion attacks on graph neural networks,” inProceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2021, pp. 2461–2471
work page 2021
-
[39]
Recipe for a general, powerful, scal- able graph transformer,
L. Ramp ´aˇsek, M. Galkin, V . P. Dwivedi, A. T. Luu, G. Wolf, and D. Beaini, “Recipe for a general, powerful, scal- able graph transformer,” inProceedings of the 36th Inter- national Conference on Neural Information Processing Systems, 2022
work page 2022
-
[40]
Design space for graph neural networks,
J. You, R. Ying, and J. Leskovec, “Design space for graph neural networks,” inProceedings of the 34th International Conference on Neural Information Processing Systems , 2020
work page 2020
-
[41]
Fast Graph Representation Learning with PyTorch Geometric
M. Fey and J. E. Lenssen, Fast graph representation learn- ing with PyTorch Geometric, 2019. arXiv: 1903.02428
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[42]
User preference-aware fake news detection,
Y . Dou, K. Shu, C. Xia, P. S. Yu, and L. Sun, “User preference-aware fake news detection,” in Proceedings of the 44th International ACM SIGIR Conference on Re- search and Development in Information Retrieval, 2021, 2051–2055
work page 2021
-
[43]
Poisoning x eva- sion: Symbiotic adversarial robustness for graph neural networks,
E. Ege, S. Geisler, and S. G¨unnemann, “Poisoning x eva- sion: Symbiotic adversarial robustness for graph neural networks,” in NeurIPS Workshop on Graph Learning Fron- tiers, Dec. 2023
work page 2023
-
[44]
P. Veliˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Li`o, and Y . Bengio, “Graph attention networks,” inInternational Conference on Learning Representations, 2018
work page 2018
-
[45]
How attentive are graph attention networks?
S. Brody, U. Alon, and E. Yahav, “How attentive are graph attention networks?” InInternational Conference on Learn- ing Representations, 2022. 6 Relaxing Graph Transformers for Adversarial Attacks A. Related work Triggered by the seminal works of Z¨ugner, Akbarnejad, and G¨unnemann [1] and Dai, Li, Tian, et al. [25], a research area emerged spanning attac...
work page 2022
-
[46]
All our experiments ran on an internal GPU cluster
library. All our experiments ran on an internal GPU cluster. Experiments that require less than 10GB of GPU memory were conducted on a Nvidia GTX1080Ti (10GB), the others on V100 and A100 GPUs (32/40GB). Attacking a single graph in our experiments takes anywhere from a few seconds to a few minutes, depending on the graph and model sizes. Datasets. We eval...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.