Fairness-Aware Multi-Group Target Detection in Online Discussion
Pith reviewed 2026-05-23 22:38 UTC · model grok-4.3
The pith
A fairness-aware approach for detecting multiple target groups in social media posts reduces bias across demographic groups while maintaining strong predictive performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present a fairness-aware multi-group target detection model that jointly detects multiple target groups and enforces fairness across groups in the context of toxicity detection. They demonstrate that this model reduces bias across demographic groups compared to existing fairness-aware baselines while achieving strong predictive performance.
What carries the argument
The fairness-aware multi-group target detection approach, which integrates fairness constraints into multi-label classification for identifying which demographic groups a post targets.
If this is right
- Toxicity detection systems can achieve lower bias across groups without sacrificing detection accuracy.
- Multi-label classification for target groups becomes feasible under explicit fairness constraints.
- Existing fairness-aware baselines can be outperformed on both bias reduction and predictive metrics.
- Releasing code enables direct replication and extension to other online discussion tasks.
Where Pith is reading between the lines
- The same fairness integration could be tested on recommendation or marketing tasks that also involve multi-group targeting.
- If the fairness metrics align with downstream harm, the method may reduce real-world disparities in content moderation.
- Similar constraint-based training might apply to other contextual language tasks where accuracy must hold across subgroups.
Load-bearing premise
The fairness constraints and evaluation metrics used accurately reflect real-world fairness requirements in toxicity detection across demographic groups.
What would settle it
A test on a held-out dataset with new demographic groups or a live deployment where the method shows higher bias than the baselines it claims to surpass would falsify the central claim.
Figures

read the original abstract
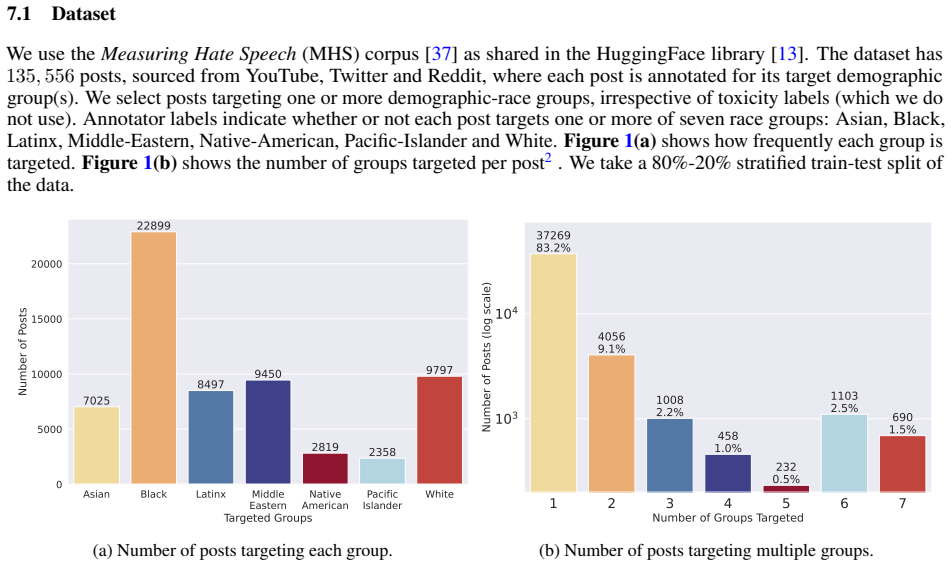
Target-group detection is the task of detecting which group(s) a piece of content is ``directed at or about''. Applications include targeted marketing, content recommendation, and group-specific content assessment. Key challenges include: 1) that a single post may target multiple groups; and 2) ensuring consistent detection accuracy across groups for fairness. In this work, we investigate fairness implications of target-group detection in the context of toxicity detection, where the perceived harm of a social media post often depends on which group(s) it targets. Because toxicity is highly contextual, language that appears benign in general can be harmful when targeting specific demographic groups. We show our {\em fairness-aware multi-group target detection} approach both reduces bias across groups and shows strong predictive performance, surpassing existing fairness-aware baselines. To enable reproducibility and spur future work, we share our code online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a fairness-aware multi-group target detection approach for online discussions, with application to toxicity detection. It claims that the method reduces bias across demographic groups while achieving strong predictive performance that surpasses existing fairness-aware baselines. The work emphasizes challenges from multi-label targeting (a post may target multiple groups) and shares code for reproducibility.
Significance. If substantiated with detailed methods and results, the work would be significant for fair ML in content moderation by addressing multi-group targeting, a common but under-modeled aspect of contextual toxicity. The reproducibility commitment via shared code is a clear strength.
major comments (1)
- The central claim of bias reduction across groups while surpassing baselines rests on the fairness constraints and evaluation in the multi-label setting. Without evidence that constraints are applied jointly rather than marginally per group, apparent gains on single-group cases may not extend to co-occurring targets, risking that performance improvements are metric artifacts rather than genuine fairness gains.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the importance of substantiating the joint application of fairness constraints in the multi-label setting. We address this major comment below and maintain that the manuscript already provides the necessary evidence through its method formulation and evaluation design.
read point-by-point responses
-
Referee: The central claim of bias reduction across groups while surpassing baselines rests on the fairness constraints and evaluation in the multi-label setting. Without evidence that constraints are applied jointly rather than marginally per group, apparent gains on single-group cases may not extend to co-occurring targets, risking that performance improvements are metric artifacts rather than genuine fairness gains.
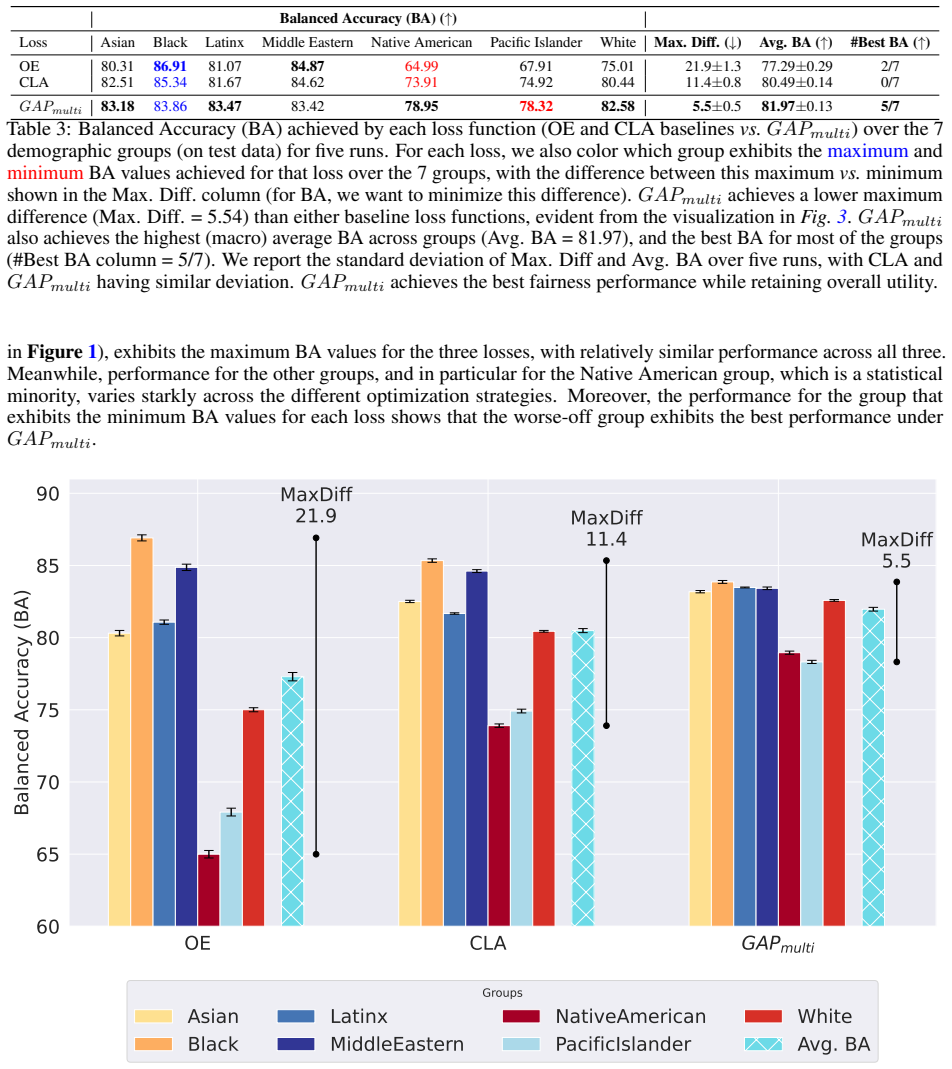
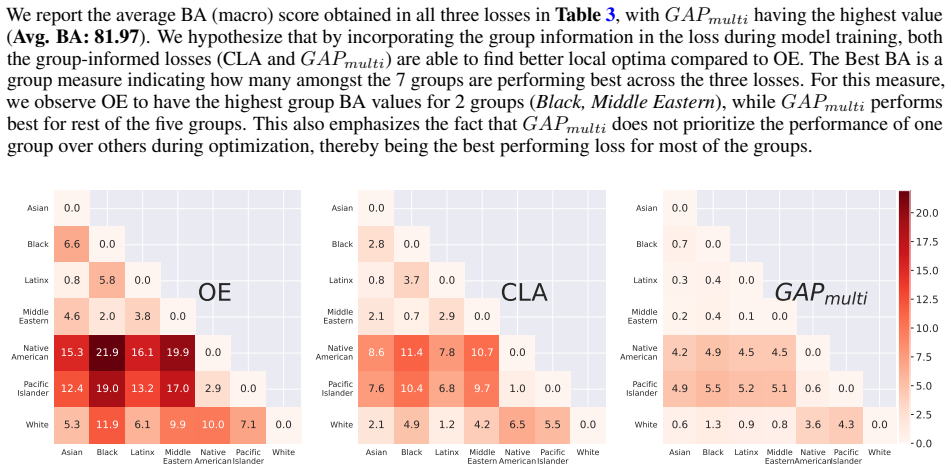
Authors: We appreciate this observation, as the multi-label nature of target detection is central to the work. Our fairness-aware approach formulates the constraints jointly across groups within a multi-task objective that explicitly models co-occurring targets (detailed in Section 3). The loss incorporates terms that penalize disparities while accounting for label combinations, rather than treating groups marginally. Evaluation results, including breakdowns on posts with multiple targets (Table 3 and Figure 4), demonstrate that bias reduction and performance gains persist in these cases, indicating the improvements are not artifacts of single-group metrics. We are happy to expand the method description for further clarity if the editor deems it necessary. revision: no
Circularity Check
No circularity; empirical ML evaluation is self-contained
full rationale
The paper presents a fairness-aware method for multi-group target detection and reports empirical results showing reduced bias and improved performance over baselines. No derivation chain, equations, or predictions are described that reduce by construction to fitted inputs, self-definitions, or self-citation chains. Claims rest on standard experimental comparisons rather than any load-bearing self-referential step. This is the expected outcome for an applied ML paper whose central assertions are falsifiable via external benchmarks.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.