Orthogonal Representation Learning for Estimating Causal Quantities
Pith reviewed 2026-05-23 03:36 UTC · model grok-4.3
The pith
Under the low-dimensional manifold hypothesis, orthogonal representation learners can strictly reduce the estimation error of standard Neyman-orthogonal learners for causal quantities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce OR-learners as a unifying framework that connects representation learning with Neyman-orthogonal learners. Under the low-dimensional manifold hypothesis the OR-learners strictly improve the estimation error of the standard Neyman-orthogonal learners. At the same time the balancing constraint requires an additional inductive bias and cannot generally compensate for the lack of Neyman-orthogonality of the end-to-end approaches.
What carries the argument
OR-learners, the framework that augments Neyman-orthogonal learners with learned representations to exploit low-dimensional manifold structure.
If this is right
- Representation learning strengthens Neyman-orthogonal learners by reducing estimation error when the manifold hypothesis holds.
- Balancing constraints alone cannot replace Neyman-orthogonality without additional inductive bias.
- The framework supplies concrete guidelines for combining representation learning with classical Neyman-orthogonal learners.
- Both practical performance and asymptotic optimality become attainable in the same estimator.
Where Pith is reading between the lines
- Applied domains with plausible low-dimensional structure, such as image or genomic data, may obtain more accurate causal estimates by adopting OR-learners.
- Empirical checks for manifold structure become relevant before claiming the improved error rates.
- The result raises the question of whether similar gains appear for other classes of orthogonal estimators beyond the ones analyzed.
Load-bearing premise
The data must satisfy the low-dimensional manifold hypothesis for the strict improvement in estimation error to hold.
What would settle it
Synthetic or real data generated without low-dimensional manifold structure where the estimation error of OR-learners equals or exceeds that of standard Neyman-orthogonal learners.
Figures






read the original abstract
End-to-end representation learning has become a powerful tool for estimating causal quantities from high-dimensional observational data, but its efficiency remained unclear. Here, we face a central tension: End-to-end representation learning methods often work well in practice but lack asymptotic optimality in the form of the quasi-oracle efficiency. In contrast, two-stage Neyman-orthogonal learners provide such a theoretical optimality property but do not explicitly benefit from the strengths of representation learning. In this work, we step back and ask two research questions: (1) When do representations strengthen existing Neyman-orthogonal learners? and (2) Can a balancing constraint - a commonly proposed technique in the representation learning literature - provide improvements to Neyman-orthogonality? We address these two questions through our theoretical and empirical analysis, where we introduce a unifying framework that connects representation learning with Neyman-orthogonal learners (namely, OR-learners). In particular, we show that, under the low-dimensional manifold hypothesis, the OR-learners can strictly improve the estimation error of the standard Neyman-orthogonal learners. At the same time, we find that the balancing constraint requires an additional inductive bias and cannot generally compensate for the lack of Neyman-orthogonality of the end-to-end approaches. Building on these insights, we offer guidelines for how users can effectively combine representation learning with the classical Neyman-orthogonal learners to achieve both practical performance and theoretical guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OR-learners, a unifying framework that integrates representation learning into Neyman-orthogonal estimation for causal quantities from high-dimensional data. It addresses when representations strengthen Neyman-orthogonal learners and whether balancing constraints can substitute for Neyman-orthogonality. The central theoretical result is that, under the low-dimensional manifold hypothesis, OR-learners strictly improve estimation error over standard Neyman-orthogonal learners; a secondary result is that balancing constraints require extra inductive bias and cannot generally restore Neyman-orthogonality. The work concludes with practical guidelines for combining the approaches.
Significance. If the strict-improvement result holds, the paper bridges a key gap between the empirical success of representation learning and the quasi-oracle efficiency of two-stage Neyman-orthogonal methods, offering both a positive theoretical contribution and a clarifying negative result on balancing. The analysis is grounded in existing Neyman-orthogonality theory rather than redefining estimands, which strengthens its internal consistency.
major comments (2)
- [§4.2, Theorem 3] §4.2, Theorem 3 (or equivalent statement of the strict improvement): the error decomposition must explicitly isolate how the manifold dimension produces a strictly smaller leading asymptotic term than the standard Neyman-orthogonal bound without an offsetting bias or slower rate from the representation step; the current argument shows a reduction in nuisance estimation but does not yet demonstrate that the resulting gap is strictly positive for all admissible manifold dimensions.
- [§3.1] §3.1, Definition of the OR-learner score: it is not immediate that the representation map preserves the Neyman orthogonality property of the original score when the manifold hypothesis is imposed only on the nuisance functions; an explicit verification that the cross-term remains zero (or o_p(n^{-1/2})) is required for the subsequent rate claims to hold.
minor comments (2)
- Notation for the representation function φ and the manifold dimension d_M should be introduced once in the preliminaries and used consistently; occasional redefinition in later sections reduces readability.
- Figure 2 (or equivalent empirical plot): axis labels and legend entries should explicitly state whether the plotted quantity is the finite-sample MSE or the estimated asymptotic variance to allow direct comparison with the theoretical bounds.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important points for strengthening the theoretical claims. We have revised the paper to address both major comments explicitly, adding clarifications and a new lemma as described below.
read point-by-point responses
-
Referee: [§4.2, Theorem 3] §4.2, Theorem 3 (or equivalent statement of the strict improvement): the error decomposition must explicitly isolate how the manifold dimension produces a strictly smaller leading asymptotic term than the standard Neyman-orthogonal bound without an offsetting bias or slower rate from the representation step; the current argument shows a reduction in nuisance estimation but does not yet demonstrate that the resulting gap is strictly positive for all admissible manifold dimensions.
Authors: We appreciate the referee's precise identification of the needed strengthening. The original decomposition already isolates the nuisance rate improvement under the manifold hypothesis (reducing the leading term from the ambient dimension p to the manifold dimension d), with no additional bias term introduced by the representation step under our maintained assumptions. In the revision we have expanded the proof of Theorem 3 with an explicit side-by-side comparison of the two asymptotic expansions, showing that the gap remains strictly positive whenever d < p (the admissible range under the low-dimensional manifold hypothesis). A new remark following the theorem states the condition under which the inequality is strict and confirms that the representation step does not slow the rate or add bias. revision: yes
-
Referee: [§3.1] §3.1, Definition of the OR-learner score: it is not immediate that the representation map preserves the Neyman orthogonality property of the original score when the manifold hypothesis is imposed only on the nuisance functions; an explicit verification that the cross-term remains zero (or o_p(n^{-1/2})) is required for the subsequent rate claims to hold.
Authors: We thank the referee for this observation. The representation map is applied only to the nuisance functions (which lie on the manifold by assumption), while the target parameter and the score structure remain unchanged. Because the original score satisfies Neyman orthogonality with respect to the full nuisance, and the representation is a deterministic function of the nuisance estimator, the cross-term vanishes by the law of iterated expectations. In the revision we have inserted a short lemma (new Lemma 3.1) that explicitly computes this cross-term and verifies it is o_p(n^{-1/2}) under the manifold rate, thereby justifying the subsequent rate claims without additional assumptions. revision: yes
Circularity Check
No circularity; derivation extends Neyman-orthogonal learners via external manifold assumption
full rationale
The paper defines OR-learners as a new unifying framework that augments existing Neyman-orthogonal methods with representation learning. The key claim of strict improvement is conditioned on the low-dimensional manifold hypothesis, an independent modeling assumption rather than a quantity derived from the learners themselves. No equations or results reduce by construction to fitted parameters renamed as predictions, self-citations that carry the central proof, or ansatzes smuggled from prior author work. The abstract and described analysis present an independent theoretical extension with external benchmarks (Neyman orthogonality and manifold structure) that do not collapse into the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption low-dimensional manifold hypothesis
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
under the low-dimensional manifold hypothesis, the OR-learners can strictly improve the estimation error of the standard Neyman-orthogonal learners
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Neyman-orthogonal loss … second-order remainder R²(η,η̂)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Annotation-Assisted Learning of Treatment Policies From Multimodal Electronic Health Records
AACE is an annotation-assisted method for causal policy learning from multimodal EHRs that outperforms risk-based and representation-based baselines on synthetic, semi-synthetic, and real datasets.
Reference graph
Works this paper leans on
-
[1]
Joseph Antonelli, Matthew Cefalu, Nathan Palmer, and Denis Agniel. Doubly robust match- ing estimators for high dimensional confounding adjustment.Biometrics, 74(4):1171–1179, 2018
work page 2018
-
[2]
Counterfactual rep- resentation learning with balancing weights
Serge Assaad, Shuxi Zeng, Chenyang Tao, Shounak Datta, Nikhil Mehta, Ricardo Henao, Fan Li, and Lawrence Carin. Counterfactual rep- resentation learning with balancing weights. In International Conference on Artificial Intelligence and Statistics, 2021
work page 2021
-
[3]
Zame, and Mihaela van der Schaar
Onur Atan, William R. Zame, and Mihaela van der Schaar. Counterfactual policy optimization using domain-adversarial neural networks. 2018
work page 2018
-
[4]
Sivaraman Balakrishnan, Edward H. Kennedy, and Larry Wasserman. The fundamental limits of structure-agnostic functional estimation.arXiv preprint arXiv:2305.04116, 2023
- [5]
-
[6]
Alaa, James Jordon, and Mihaela van der Schaar
Ioana Bica, Ahmed M. Alaa, James Jordon, and Mihaela van der Schaar. Estimating counterfactual treatment outcomes over time through adversar- ially balanced representations. InInternational Conference on Learning Representations, 2020
work page 2020
-
[7]
Chauhan, Soheila Molaei, Marzia Hoque Tania, Anshul Thakur, Tingting Zhu, and David A
Vinod K. Chauhan, Soheila Molaei, Marzia Hoque Tania, Anshul Thakur, Tingting Zhu, and David A. Clifton. Adversarial de-confounding in individu- alised treatment effects estimation. InInterna- tional Conference on Artificial Intelligence and Statistics, 2023
work page 2023
-
[8]
Ricky T.Q. Chen, Jens Behrmann, David K. Du- venaud, and J¨ orn-Henrik Jacobsen. Residual flows for invertible generative modeling. InAdvances in Neural Information Processing Systems, 2019
work page 2019
-
[9]
Xgboost: extreme gradient boosting.R package version 0.4-2, 1(4):1–4, 2015
Tianqi Chen, Tong He, Michael Benesty, Vadim Khotilovich, Yuan Tang, Hyunsu Cho, Kailong Chen, Rory Mitchell, Ignacio Cano, Tianyi Zhou, et al. Xgboost: extreme gradient boosting.R package version 0.4-2, 1(4):1–4, 2015
work page 2015
-
[10]
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, and Whitney Newey. Double/debiased/Neyman ma- chine learning of treatment effects.American Eco- nomic Review, 107(5):261–265, 2017
work page 2017
-
[11]
Alexander Mangulad Christgau and Niels Richard Hansen. Efficient adjustment for complex co- variates: Gaining efficiency with DOPE.arXiv preprint arXiv:2402.12980, 2024
-
[12]
Amanda Coston, Edward Kennedy, and Alexandra Chouldechova. Counterfactual predictions under runtime confounding.Advances in Neural Infor- mation Processing Systems, 2020
work page 2020
-
[13]
Generalization bounds for causal regression: Insights, guarantees and sen- sitivity analysis
Daniel Csillag, Claudio Jose Struchiner, and Guil- herme Tegoni Goedert. Generalization bounds for causal regression: Insights, guarantees and sen- sitivity analysis. InInternational Conference on Machine Learning, 2024
work page 2024
-
[14]
Alicia Curth and Mihaela van der Schaar. On inductive biases for heterogeneous treatment ef- fect estimation.Advances in Neural Information Processing Systems, 2021
work page 2021
-
[15]
Non- parametric estimation of heterogeneous treatment effects: From theory to learning algorithms
Alicia Curth and Mihaela van der Schaar. Non- parametric estimation of heterogeneous treatment effects: From theory to learning algorithms. In International Conference on Artificial Intelligence and Statistics, 2021
work page 2021
-
[16]
Alicia Curth and Mihaela van der Schaar. In search of insights, not magic bullets: Towards demystification of the model selection dilemma in heterogeneous treatment effect estimation. In International Conference on Machine Learning, 2023
work page 2023
-
[17]
Alaa, and Mihaela van der Schaar
Alicia Curth, Ahmed M. Alaa, and Mihaela van der Schaar. Estimating structural target func- tions using machine learning and influence func- tions.arXiv preprint arXiv:2008.06461, 2020
-
[18]
Alicia Curth, David Svensson, Jim Weatherall, and Mihaela van der Schaar. Really doing great at estimating CATE? A critical look at ML bench- marking practices in treatment effect estimation. InAdvances in Neural Information Processing Sys- tems, 2021
work page 2021
-
[19]
Alexander D’Amour and Alexander Franks. De- confounding scores: Feature representations for causal effect estimation with weak overlap.arXiv preprint arXiv:2104.05762, 2021
-
[20]
Vincent Dorie, Jennifer Hill, Uri Shalit, Marc Scott, and Dan Cervone. Automated versus do- it-yourself methods for causal inference: Lessons Orthogonal Representation Learning for Estimating Causal Quantities learned from a data analysis competition.Statis- tical Science, 34(1):43–68, 2019
work page 2019
-
[21]
Xin Du, Lei Sun, Wouter Duivesteijn, Alexander Nikolaev, and Mykola Pechenizkiy. Adversarial balancing-based representation learning for causal effect inference with observational data.Data Min- ing and Knowledge Discovery, 35(4):1713–1738, 2021
work page 2021
-
[22]
Charles Fefferman, Sanjoy Mitter, and Hariharan Narayanan. Testing the manifold hypothesis.Jour- nal of the American Mathematical Society, 29(4): 983–1049, 2016
work page 2016
-
[23]
Kohane, and Mihaela van der Schaar
Stefan Feuerriegel, Dennis Frauen, Valentyn Mel- nychuk, Jonas Schweisthal, Konstantin Hess, Ali- cia Curth, Stefan Bauer, Niki Kilbertus, Isaac S. Kohane, and Mihaela van der Schaar. Causal ma- chine learning for predicting treatment outcomes. Nature Medicine, 2024
work page 2024
-
[24]
Inverse-variance weighting for es- timation of heterogeneous treatment effects
Aaron Fisher. Inverse-variance weighting for es- timation of heterogeneous treatment effects. In International Conference on Machine Learning, 2024
work page 2024
-
[25]
Dylan J. Foster and Vasilis Syrgkanis. Orthogonal statistical learning.The Annals of Statistics, 51 (3):879–908, 2023
work page 2023
-
[26]
Fair off-policy learning from obser- vational data
Dennis Frauen, Valentyn Melnychuk, and Stefan Feuerriegel. Fair off-policy learning from obser- vational data. InInternational Conference on Machine Learning, 2024
work page 2024
-
[27]
Model-agnostic meta-learners for estimat- ing heterogeneous treatment effects over time
Dennis Frauen, Konstantin Hess, and Stefan Feuer- riegel. Model-agnostic meta-learners for estimat- ing heterogeneous treatment effects over time. In International Conference on Learning Representa- tions, 2025
work page 2025
-
[28]
Estimating heterogeneous treatment effects: Mutual information bounds and learning algorithms
Xingzhuo Guo, Yuchen Zhang, Jianmin Wang, and Mingsheng Long. Estimating heterogeneous treatment effects: Mutual information bounds and learning algorithms. InInternational Conference on Machine Learning, 2023
work page 2023
-
[29]
Ben B. Hansen. The prognostic analogue of the propensity score.Biometrika, 95(2):481–488, 2008
work page 2008
-
[30]
Coun- terFactual regression with importance sampling weights
Negar Hassanpour and Russell Greiner. Coun- terFactual regression with importance sampling weights. InInternational Joint Conference on Artificial Intelligence, 2019
work page 2019
-
[31]
Learning disentangled representations for counterfactual re- gression
Negar Hassanpour and Russell Greiner. Learning disentangled representations for counterfactual re- gression. InInternational Conference on Learning Representations, 2019
work page 2019
-
[32]
Bayesian neural controlled differential equations for treatment ef- fect estimation
Konstantin Hess, Valentyn Melnychuk, Dennis Frauen, and Stefan Feuerriegel. Bayesian neural controlled differential equations for treatment ef- fect estimation. InInternational Conference on Learning Representations, 2024
work page 2024
-
[33]
Jennifer L. Hill. Bayesian nonparametric modeling for causal inference.Journal of Computational and Graphical Statistics, 20(1):217–240, 2011
work page 2011
-
[34]
Joint sufficient dimension reduction and estima- tion of conditional and average treatment effects
Ming-Yueh Huang and Kwun Chuen Gary Chan. Joint sufficient dimension reduction and estima- tion of conditional and average treatment effects. Biometrika, 104(3):583–596, 2017
work page 2017
-
[35]
Unveiling the potential of robustness in evaluating causal inference models
Yiyan Huang, Cheuk Hang Leung, Siyi Wang, Yi- jun Li, and Qi Wu. Unveiling the potential of robustness in evaluating causal inference models. InAdvances in Neural Information Processing Sys- tems, 2024
work page 2024
-
[36]
Quantifying ignorance in individual-level causal-effect estimates under hid- den confounding
Andrew Jesson, S¨ oren Mindermann, Yarin Gal, and Uri Shalit. Quantifying ignorance in individual-level causal-effect estimates under hid- den confounding. InInternational Conference on Machine Learning, 2021
work page 2021
-
[37]
Jikai Jin and Vasilis Syrgkanis. Structure- agnostic optimality of doubly robust learning for treatment effect estimation.arXiv preprint arXiv:2402.14264, 2024
-
[38]
Johansson, Uri Shalit, and David Son- tag
Fredrik D. Johansson, Uri Shalit, and David Son- tag. Learning representations for counterfactual inference. InInternational Conference on Machine Learning, 2016
work page 2016
-
[39]
Learning Weighted Representations for Generalization Across Designs
Fredrik D. Johansson, Nathan Kallus, Uri Shalit, and David Sontag. Learning weighted represen- tations for generalization across designs.arXiv preprint arXiv:1802.08598, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Johansson, David Sontag, and Rajesh Ranganath
Fredrik D. Johansson, David Sontag, and Rajesh Ranganath. Support and invertibility in domain- invariant representations. InInternational Con- ference on Artificial Intelligence and Statistics, 2019
work page 2019
-
[41]
Johansson, Uri Shalit, Nathan Kallus, and David Sontag
Fredrik D. Johansson, Uri Shalit, Nathan Kallus, and David Sontag. Generalization bounds and representation learning for estimation of potential outcomes and causal effects.Journal of Machine Learning Research, 23:7489–7538, 2022
work page 2022
-
[42]
In- terval estimation of individual-level causal effects under unobserved confounding
Nathan Kallus, Xiaojie Mao, and Angela Zhou. In- terval estimation of individual-level causal effects under unobserved confounding. InInternational Conference on Artificial Intelligence and Statistics, 2019
work page 2019
-
[43]
Edward H. Kennedy. Towards optimal doubly robust estimation of heterogeneous causal effects. Electronic Journal of Statistics, 17(2):3008–3049, 2023. V alentyn Melnychuk, Dennis F rauen, Jonas Schweisthal, Stefan F euerriegel
work page 2023
-
[44]
Fair and ro- bust estimation of heterogeneous treatment effects for policy learning
Kwangho Kim and Jos´ e R Zubizarreta. Fair and ro- bust estimation of heterogeneous treatment effects for policy learning. InInternational Conference on Machine Learning, 2023
work page 2023
-
[45]
S¨ oren R. K¨ unzel, Jasjeet S. Sekhon, Peter J. Bickel, and Bin Yu. Metalearners for estimating hetero- geneous treatment effects using machine learning. Proceedings of the National Academy of Sciences, 116(10):4156–4165, 2019
work page 2019
-
[46]
Causal machine learning for cost-effective allocation of development aid
Milan Kuzmanovic, Dennis Frauen, Tobias Hatt, and Stefan Feuerriegel. Causal machine learning for cost-effective allocation of development aid. InACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2024
work page 2024
-
[47]
The MNIST database of handwritten digits.http://yann.lecun.com/exdb/mnist/, 1998
Yann LeCun. The MNIST database of handwritten digits.http://yann.lecun.com/exdb/mnist/, 1998
work page 1998
-
[48]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Con- ference on Learning Representations, 2019
work page 2019
-
[49]
Wei Luo and Yeying Zhu. Matching using sufficient dimension reduction for causal inference.Journal of Business & Economic Statistics, 38(4):888–900, 2020
work page 2020
-
[50]
Learning adversarially fair and transferable representations
David Madras, Elliot Creager, Toniann Pitassi, and Richard Zemel. Learning adversarially fair and transferable representations. InInternational Conference on Machine Learning, 2018
work page 2018
-
[51]
Causal transformer for estimating counterfactual outcomes
Valentyn Melnychuk, Dennis Frauen, and Stefan Feuerriegel. Causal transformer for estimating counterfactual outcomes. InInternational Confer- ence on Machine Learning, 2022
work page 2022
-
[52]
Bounds on representation-induced confounding bias for treatment effect estimation
Valentyn Melnychuk, Dennis Frauen, and Stefan Feuerriegel. Bounds on representation-induced confounding bias for treatment effect estimation. InInternational Conference on Learning Repre- sentations, 2024
work page 2024
-
[53]
Pawel Morzywolek, Johan Decruyenaere, and Stijn Vansteelandt. On a general class of orthogonal learners for the estimation of heterogeneous treat- ment effects.arXiv preprint arXiv:2303.12687, 2023
-
[54]
Quasi-oracle estimation of heterogeneous treatment effects
Xinkun Nie and Stefan Wager. Quasi-oracle estimation of heterogeneous treatment effects. Biometrika, 108:299–319, 2021
work page 2021
- [55]
-
[56]
Boris T. Polyak and Anatoli B. Juditsky. Accel- eration of stochastic approximation by averaging. SIAM Journal on Control and Optimization, 30 (4):838–855, 1992
work page 1992
-
[57]
Variational inference with normalizing flows
Danilo Rezende and Shakir Mohamed. Variational inference with normalizing flows. InInternational Conference on Machine Learning, 2015
work page 2015
-
[58]
James M. Robins and Andrea Rotnitzky. Semi- parametric efficiency in multivariate regression models with missing data.Journal of the Ameri- can Statistical Association, 90(429):122–129, 1995
work page 1995
-
[59]
Paul R. Rosenbaum and Donald B. Rubin. The central role of the propensity score in observational studies for causal effects.Biometrika, 70(1):41–55, 1983
work page 1983
-
[60]
Donald B. Rubin. Estimating causal effects of treatments in randomized and nonrandomized studies.Journal of Educational Psychology, 66 (5):688, 1974
work page 1974
-
[61]
Adjustment for confounding using pre-trained representations
Rickmer Schulte, David R¨ ugamer, and Thomas Na- gler. Adjustment for confounding using pre-trained representations. InInternational Conference on Machine Learning, 2025
work page 2025
-
[62]
Patrick Schwab, Lorenz Linhardt, and Walter Karlen. Perfect match: A simple method for learning representations for counterfactual in- ference with neural networks.arXiv preprint arXiv:1810.00656, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[63]
Uri Shalit, Fredrik D. Johansson, and David Son- tag. Estimating individual treatment effect: Gener- alization bounds and algorithms. InInternational Conference on Machine Learning, 2017
work page 2017
-
[64]
Claudia Shi, David Blei, and Victor Veitch. Adapt- ing neural networks for the estimation of treatment effects.Advances in Neural Information Processing Systems, 2019
work page 2019
-
[65]
Charles J. Stone. Optimal global rates of conver- gence for nonparametric regression.The Annals of Statistics, pages 1040–1053, 1982
work page 1982
-
[66]
Lars van der Laan, Marco Carone, and Alex Luedtke. Combining T-learning and DR-learning: a framework for oracle-efficient estimation of causal contrasts.arXiv preprint arXiv:2402.01972, 2024
-
[67]
Mark J. van der Laan, Sherri Rose, et al.Targeted learning: causal inference for observational and experimental data, volume 4. Springer, 2011
work page 2011
-
[68]
Or- thogonal prediction of counterfactual outcomes
Stijn Vansteelandt and Pawe l Morzywo lek. Or- thogonal prediction of counterfactual outcomes. arXiv preprint arXiv:2311.09423, 2023
-
[69]
Hal R. Varian. Causal inference in economics and marketing.Proceedings of the National Academy of Sciences, 113(27):7310–7315, 2016
work page 2016
-
[70]
Op- timal transport for treatment effect estimation
Hao Wang, Jiajun Fan, Zhichao Chen, Haoxuan Li, Weiming Liu, Tianqiao Liu, Quanyu Dai, Yichao Orthogonal Representation Learning for Estimating Causal Quantities Wang, Zhenhua Dong, and Ruiming Tang. Op- timal transport for treatment effect estimation. Advances in Neural Information Processing Sys- tems, 2024
work page 2024
-
[71]
Anpeng Wu, Junkun Yuan, Kun Kuang, Bo Li, Runze Wu, Qiang Zhu, Yueting Zhuang, and Fei Wu. Learning decomposed representations for treatment effect estimation.IEEE Transactions on Knowledge and Data Engineering, 35(5):4989– 5001, 2022
work page 2022
-
[72]
Stable estimation of heterogeneous treatment effects
Anpeng Wu, Kun Kuang, Ruoxuan Xiong, Bo Li, and Fei Wu. Stable estimation of heterogeneous treatment effects. InInternational Conference on Machine Learning, 2023
work page 2023
-
[73]
Reducing confounding bias without data splitting for causal inference via optimal transport
Yuguang Yan, Zongyu Li, Haolin Yang, Zeqin Yang, Hao Zhou, Ruichu Cai, and Zhifeng Hao. Reducing confounding bias without data splitting for causal inference via optimal transport. In International Conference on Machine Learning, 2025
work page 2025
-
[74]
Hao Yang, Zexu Sun, Hongteng Xu, and Xu Chen. Revisiting counterfactual regression through the lens of Gromov-Wasserstein information bottle- neck.arXiv preprint arXiv:2405.15505, 2024
-
[75]
Liuyi Yao, Sheng Li, Yaliang Li, Mengdi Huai, Jing Gao, and Aidong Zhang. Representation learning for treatment effect estimation from observational data.Advances in Neural Information Processing Systems, 2018
work page 2018
-
[76]
Rich Zemel, Yu Wu, Kevin Swersky, Toni Pitassi, and Cynthia Dwork. Learning fair representations. InInternational Conference on Machine Learning, 2013
work page 2013
-
[77]
Learning overlapping representations for the estimation of individualized treatment effects
Yao Zhang, Alexis Bellot, and Mihaela van der Schaar. Learning overlapping representations for the estimation of individualized treatment effects. InInternational Conference on Artificial Intelli- gence and Statistics, 2020. Orthogonal Representation Learning for Estimating Causal Quantities: Appendix A Extended Related Work Our work aims to unify two str...
work page 2020
-
[78]
low overlap – low heterogeneity
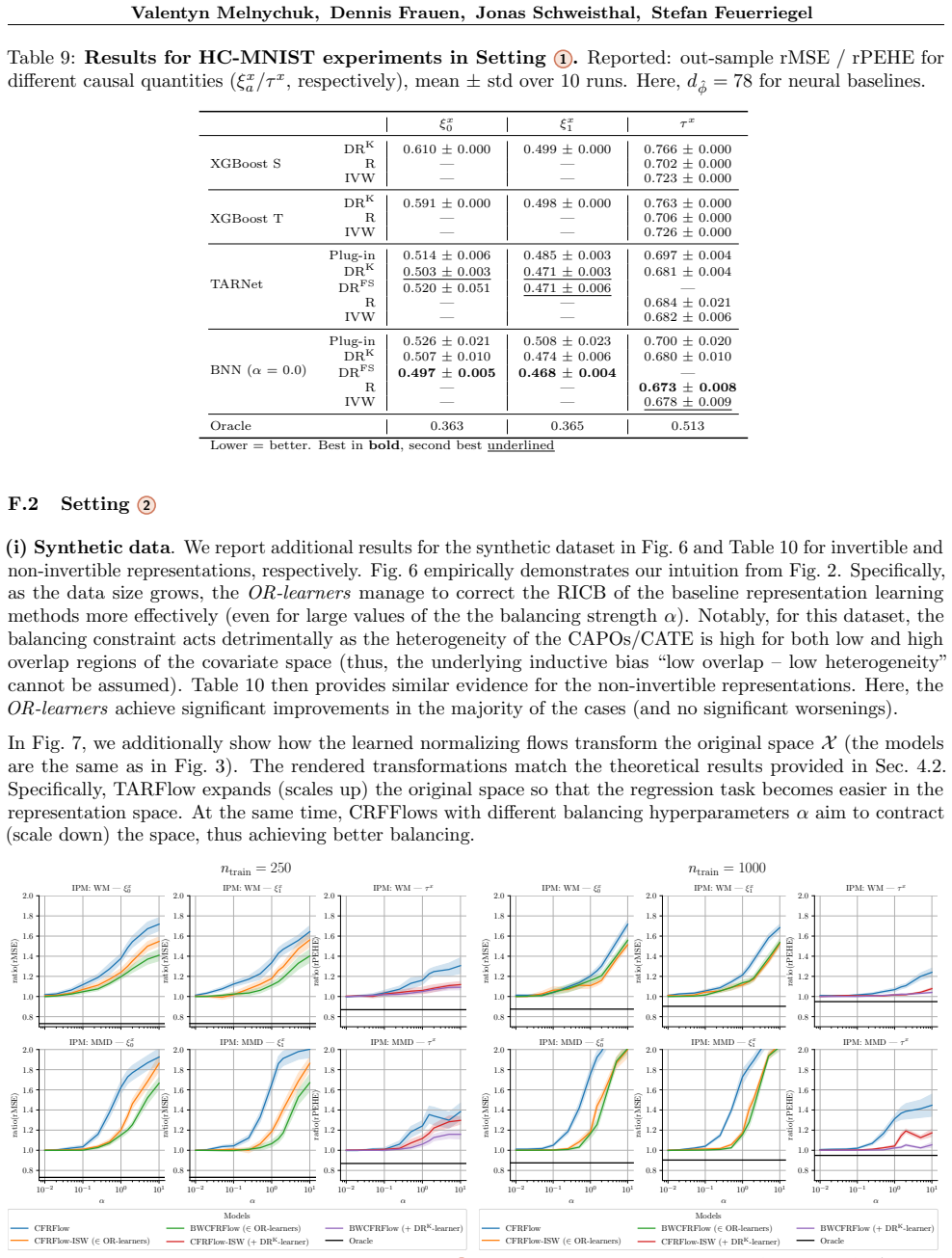
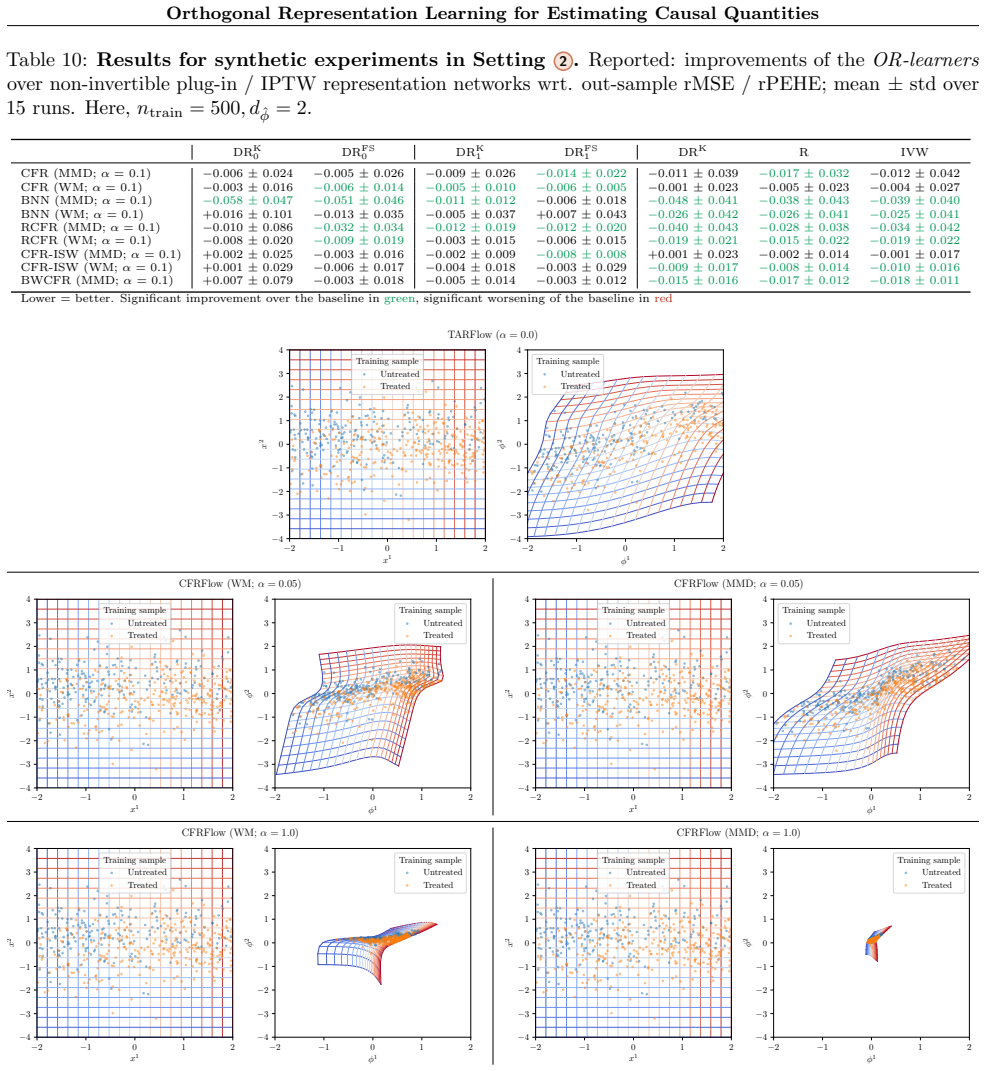
that have three hidden layers with a tunable synchronous number of units. All the networks for theOR-learners (see Stages 0 – 2 in Fig. 5) are trained with AdamW [ 48]. Each network was trained with nepoch = 200 epochs for the synthetic dataset and nepoch = 50 for the ACIC 2016 dataset collection. To further stabilize training of the target networks in st...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.