Recent quantum runtime (dis)advantages
Pith reviewed 2026-05-18 08:49 UTC · model grok-4.3
The pith
Current NISQ hardware shows no runtime quantum advantage under full end-to-end metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On current NISQ hardware, runtime-based quantum advantage has not yet been demonstrated under experimentally grounded performance metrics, and credible claims require careful time accounting, appropriate performance measures, and properly chosen classical reference implementations.
What carries the argument
Experimentally grounded end-to-end definitions of quantum runtime for digital and analogue devices together with a methodology for selecting strong classical baselines.
If this is right
- Claims that treat annealing time as a proxy for runtime overestimate quantum performance.
- Restricted Simon's problem implementations run about two orders of magnitude slower than tuned classical code at tested sizes.
- The BF-DCQO hybrid algorithm loses its reported runtime advantage under comprehensive benchmarking.
- Credible future claims must include full overhead accounting and competitive classical references.
Where Pith is reading between the lines
- Hardware with lower control and readout overheads could alter these runtime comparisons at larger scales.
- The same end-to-end framework could be used to reassess other quantum algorithms beyond the three cases examined.
- Standardized benchmarking protocols that enforce full time accounting would reduce ambiguity in advantage claims.
Load-bearing premise
The chosen classical baselines are the strongest possible implementations and the measured overheads represent typical end-to-end performance for the problem sizes tested.
What would settle it
A quantum experiment that solves a concrete problem instance faster in total measured wall-clock time than the best classical implementation using the same accuracy target and problem size.
Figures




read the original abstract
A robust definition of quantum runtime is essential for assessing the performance of quantum algorithms and claims of quantum advantage. While for most classical hardware the total runtime is well approximated by computation plus a weakly varying constant, on current quantum hardware a clean experimental separation between "pure computation" and "overhead" is often not justified. Consequently, conventional quantum runtime analyses excluding substantial system-level overheads can lead to biased performance assessments. In this work we introduce experimentally grounded, end-to-end definitions of quantum runtime for digital and analogue quantum computers, together with a methodology for selecting strong classical baselines for quantum-classical runtime comparisons. Within this framework, we evaluate recent claims of quantum advantage in annealing and gate-based algorithms. We examine three representative case studies. First, we revisit annealing for approximate QUBO problems PRL 134, 160601 (2025), which employs a well-motivated time-to-$\epsilon$ metric but effectively uses annealing time as a proxy for runtime. Second, we analyze a restricted implementation of Simon's problem PRX 15, 021082 (2025), where the favorable scaling in oracle calls is undisputed; however, we show that the estimated runtime of the quantum experiment is approximately two orders of magnitude slower than a tuned classical baseline at the tested sizes. Finally, we find that the runtime advantage of the BF-DCQO hybrid algorithm arXiv:2505.08663 is not observed under more comprehensive benchmarking. Therefore, on current NISQ hardware, runtime-based quantum advantage has not yet been demonstrated under experimentally grounded performance metrics, and credible claims require careful time accounting, appropriate performance measures, and properly chosen classical reference implementations, as discussed in this work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces experimentally grounded end-to-end definitions of quantum runtime for digital and analogue NISQ devices, along with a methodology for selecting strong classical baselines. It applies this framework to three recent claims of runtime quantum advantage: annealing for approximate QUBO problems (PRL 134, 160601), a restricted Simon's problem implementation (PRX 15, 021082), and the BF-DCQO hybrid algorithm (arXiv:2505.08663). The central conclusion is that no runtime-based quantum advantage has been demonstrated on current NISQ hardware under these metrics, with the Simon's case showing quantum runtimes ~100x slower than a tuned classical baseline and the BF-DCQO case showing no advantage under comprehensive benchmarking.
Significance. If the analysis holds, the work provides a useful framework for rigorous quantum-classical runtime comparisons that properly accounts for system-level overheads and baseline selection. This could help refine future experimental claims of quantum advantage. The paper explicitly credits the need for careful time accounting and appropriate performance measures in NISQ evaluations.
major comments (2)
- [§3 and §4] §3 (methodology) and §4 (Simon's problem case): the quantitative claim of an approximately two-order-of-magnitude runtime disadvantage rests on the selected and tuned classical baseline representing a strong reference implementation. The paper optimizes specific classical codes but does not report comparisons against independently published best-in-class classical solvers or exhaustive variants for the exact problem sizes and success probabilities used; if a faster classical reference exists, the dis-advantage conclusion would not hold.
- [final case study] BF-DCQO hybrid analysis (final case study): the finding that runtime advantage is not observed requires that the more comprehensive benchmarking fully captures end-to-end performance; the absence of explicit cross-checks against optimal classical solvers at the tested scales makes this load-bearing for the no-advantage claim.
minor comments (2)
- [Abstract] The abstract states 'approximately two orders of magnitude slower' without specifying the exact numerical values, conditions, or error accounting; the main text should include these details for reproducibility.
- Figures showing runtime comparisons would benefit from explicit inclusion of error bars or sensitivity analysis to baseline variations.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review of our manuscript. The comments raise important points about the strength of our classical baselines, which we address point by point below. We have revised the manuscript to incorporate additional discussion and caveats where this strengthens the presentation without altering the core conclusions.
read point-by-point responses
-
Referee: [§3 and §4] §3 (methodology) and §4 (Simon's problem case): the quantitative claim of an approximately two-order-of-magnitude runtime disadvantage rests on the selected and tuned classical baseline representing a strong reference implementation. The paper optimizes specific classical codes but does not report comparisons against independently published best-in-class classical solvers or exhaustive variants for the exact problem sizes and success probabilities used; if a faster classical reference exists, the dis-advantage conclusion would not hold.
Authors: We appreciate the referee's emphasis on rigorous baseline selection. Our classical implementation for the restricted Simon's problem was specifically optimized for the exact instance sizes and target success probability reported in the quantum experiment, using standard algorithmic techniques tuned to minimize wall-clock time under those constraints. We selected this approach because it directly matches the problem structure and performance metric of the quantum demonstration. We disagree that a faster classical reference would invalidate the disadvantage conclusion: if a superior classical solver exists with lower runtime, the ratio of quantum to classical runtime would only increase, strengthening rather than weakening the finding that the quantum implementation is slower under end-to-end metrics. Nevertheless, to address the concern, we have added text in the revised §4 explicitly discussing the choice of baseline, its competitiveness for the tested scales, and the observation that further classical improvements would not reverse the reported ordering. We also note the practical difficulty of exhaustively testing all published solvers for these specific parameters. revision: partial
-
Referee: [final case study] BF-DCQO hybrid analysis (final case study): the finding that runtime advantage is not observed requires that the more comprehensive benchmarking fully captures end-to-end performance; the absence of explicit cross-checks against optimal classical solvers at the tested scales makes this load-bearing for the no-advantage claim.
Authors: We agree that explicit comparisons to strong classical solvers are important for load-bearing claims of no advantage. Our BF-DCQO analysis already incorporates multiple classical optimization methods chosen to reflect realistic end-to-end performance at the scales tested in the original work. In the revised manuscript we have expanded the relevant section to include additional justification for the benchmarking suite, references to related classical solvers in the literature, and a clearer statement of the limitations of any finite set of comparisons. We maintain that the comprehensive metrics defined in §3 already capture the relevant overheads, but the added discussion makes the no-advantage conclusion more robust. revision: partial
Circularity Check
No significant circularity detected in runtime definitions or case evaluations
full rationale
The paper introduces end-to-end quantum runtime definitions grounded in external experimental hardware literature and applies them to re-evaluate published claims from independent works. The central claims rest on methodological choices for classical baselines and time accounting that are explicitly justified within the text rather than reducing by construction to fitted inputs or self-citations. No load-bearing step equates a prediction to its own definition or relies on a self-citation chain for uniqueness. The analysis remains self-contained against external benchmarks and cited experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A clean experimental separation between pure computation and overhead is often not justified on current quantum hardware.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the estimated runtime of the quantum experiment is approximately two orders of magnitude slower than a tuned classical baseline
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
AutoVerifier: An Agentic Automated Verification Framework Using Large Language Models
AutoVerifier decomposes technical claims into triples and uses layered LLM verification to assess validity, demonstrated on a quantum computing paper by finding overclaims and conflicts.
-
Simulated Bifurcation Quantum Annealing
SBQA adds inter-replica interactions to simulated bifurcation to mimic quantum tunneling and improves performance on sparse rugged optimization problems over standard SBM.
-
Neural and Tensor Networks in the Study of Quantum Annealing Processors
The thesis introduces a topology-aware tensor-network heuristic called SpinGlassPEPS.jl and thermodynamic metrics to benchmark quantum annealers on Ising problems while accounting for dissipation and effective temperature.
Reference graph
Works this paper leans on
-
[1]
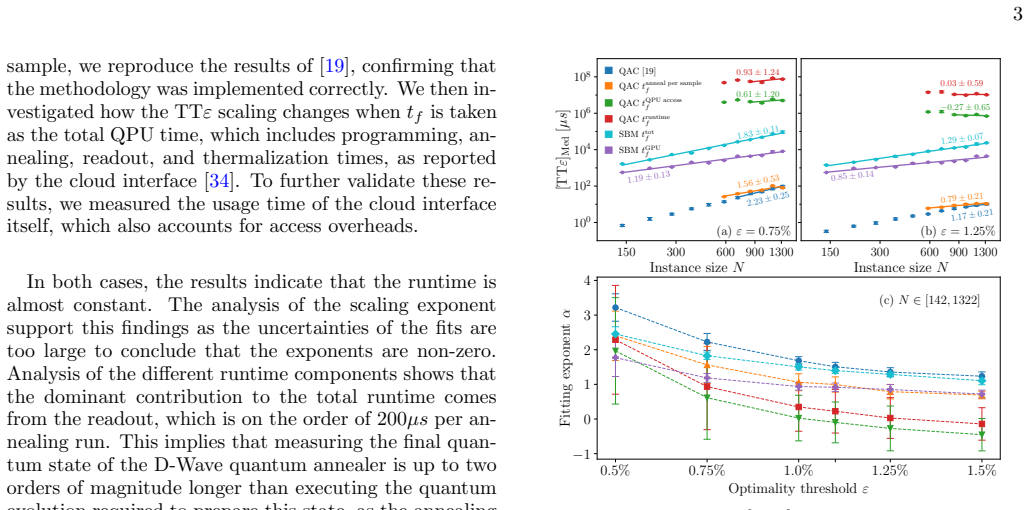
to account for the connectivity and native gate set of IBM Brisbane [50]. The number of shots was chosen according to the oracle call bound given in Eq. (16) of Ref. [20]. The results are summarized in Fig. 2. The runtime analysis clearly demonstrates that the exponen- tial query complexity speedup reported in [20] does not translate into a faster solutio...
work page 2000
-
[2]
R. P. Feynman, Simulating physics with computers, Int J Theor Phys21, 467–488 (1982)
work page 1982
-
[3]
Deutsch, Quantum theory, the Church-Turing princi- ple and the universal quantum computer, Proc
D. Deutsch, Quantum theory, the Church-Turing princi- ple and the universal quantum computer, Proc. R. Soc. Lond. A400, 97 (1985)
work page 1985
-
[4]
IonQ, IonQ Roadmap (2025)
work page 2025
-
[5]
IBM, IBM Quantum Roadmap (2025)
work page 2025
-
[6]
Quantinuum, Quantinuum Roadmap (2025)
work page 2025
-
[7]
D-Wave, The D-Wave Clarity Roadmap (2025), accessed: 2025-01-30. 10
work page 2025
- [8]
-
[9]
D. R. Simon, On the power of quantum computation, SIAM J. Comput.26, 1474 (1997)
work page 1997
-
[10]
P. Shor, Algorithms for quantum computation: discrete logarithms and factoring, inProceedings 35th Annual Symposium on Foundations of Computer Science(1994) pp. 124–134
work page 1994
-
[11]
L. J. Stockmeyer, The polynomial-time hierarchy, Theor. Comput. Sci.3, 1 (1976)
work page 1976
- [12]
- [13]
-
[14]
F. Meier and H. Yamasaki, Energy-consumption advan- tage of quantum computation, PRX Energy4(2025)
work page 2025
-
[15]
K. Bertels, E. Turki, T. Sarac, A. Sarkar, and I. Ashraf, Quantum computing – a new scientific revolution in the making, arXiv:2106.11840 (2024)
- [16]
-
[17]
Y. A. Liu, X. L. Liu, F. N. Li, H. Fu, Y. Yang, J. Song, P. Zhao, Z. Wang, D. Peng, H. Chen, and et al., Clos- ing the ”quantum supremacy” gap: achieving real-time simulation of a random quantum circuit using a new Sun- way supercomputer, inProc. - Int. Conf. High Perform. Comput. Netw. Storage Anal., SC ’21 (Association for Computing Machinery, New York,...
work page 2021
-
[18]
F. Pan, K. Chen, and P. Zhang, Solving the sampling problem of the Sycamore quantum circuits, Phys. Rev. Lett.129, 090502 (2022)
work page 2022
- [19]
-
[20]
H. Munoz-Bauza and D. Lidar, Scaling advantage in ap- proximate optimization with quantum annealing, Phys. Rev. Lett.134, 160601 (2025)
work page 2025
-
[21]
P. Singkanipa, V. Kasatkin, Z. Zhou, G. Quiroz, and D. A. Lidar, Demonstration of algorithmic quantum speedup for an abelian hidden subgroup problem, Phys. Rev. X15(2025)
work page 2025
-
[22]
P. Chandarana, A. G. Cadavid, S. V. Romero, A. Simen, E. Solano, and N. N. Hegade, Runtime quantum advantage with digital quantum optimization, arXiv:2505.08663 (2025)
-
[23]
Z. Zhu, A. J. Ochoa, and H. G. Katzgraber, Efficient cluster algorithm for spin glasses in any space dimension, Phys. Rev. Lett.115, 077201 (2015)
work page 2015
-
[24]
S. Kirkpatrick, C. D. Gelatt, and M. P. Vecchi, Optimiza- tion by Simulated Annealing, Science220, 671 (1983)
work page 1983
-
[25]
CPLEX, IBM ILOG, Users manual for CPLEX (2024)
work page 2024
-
[26]
J. Paw lowski, P. Tarasiuk, J. Tuziemski, L. Pawela, and B. Gardas, Closing the quantum-classical scaling gap in approximate optimization, arXiv:2505.22514 (2025)
-
[27]
S. Boettcher, Analysis of the relation between quadratic unconstrained binary optimization and the spin-glass ground-state problem, Phys. Rev. Res.1, 033142 (2019)
work page 2019
-
[28]
G. F. Newell and E. W. Montroll, On the Theory of the Ising Model of Ferromagnetism, Rev. Mod. Phys.25, 353 (1953)
work page 1953
-
[29]
M. Mohseni, M. M. Rams, S. V. Isakov, D. Eppens, S. Pielawa, J. Strumpfer, S. Boixo, and H. Neven, Sampling diverse near-optimal solutions via algorithmic quantum annealing, Phys. Rev. E108(2023)
work page 2023
-
[30]
NVIDIA, Nsight systems user guide (2025)
work page 2025
-
[31]
Intel, Intel vtune profiler (2025)
work page 2025
-
[32]
AMD, AMD profiler (2025)
work page 2025
-
[33]
D-Wave, D-wave QPU solver parameters (2025)
work page 2025
-
[34]
H. Munoz Bauza and D. Lidar, Scaling Advantage in Approximate Optimization with Quantum Annealing - Spin-Glass Instances (2025)
work page 2025
-
[35]
D-Wave, D-wave operation and timing (2025)
work page 2025
-
[36]
Goto, Bifurcation-based adiabatic quantum compu- tation with a nonlinear oscillator network, Sci
H. Goto, Bifurcation-based adiabatic quantum compu- tation with a nonlinear oscillator network, Sci. Rep.6, 21686 (2016)
work page 2016
-
[37]
H. Goto, K. Endo, M. Suzuki, Y. Sakai, and Taro et al., High-performance combinatorial optimization based on classical mechanics, Sci. Adv.7, eabe7953 (2021)
work page 2021
-
[38]
H. Goto, K. Tatsumura, and A. R. Dixon, Combinatorial optimization by simulating adiabatic bifurcations in non- linear hamiltonian systems, Sci. Adv.5, eaav2372 (2019)
work page 2019
- [39]
-
[40]
T. F. Rønnow, Z. Wang, J. Job, S. Boixo, S. V. Isakov, D. Wecker, J. M. Martinis, D. A. Lidar, and M. Troyer, Defining and detecting quantum speedup, Science345, 420–424 (2014)
work page 2014
-
[41]
E. Alessandroni, S. Ramos-Calderer, I. Roth, E. Traversi, and L. Aolita, Alleviating the quantum big-m problem, npj Quantum Inf.11(2025)
work page 2025
-
[42]
M. Larocca, S. Thanasilp, S. Wang, K. Sharma, J. Bia- monte, P. J. Coles, L. Cincio, J. R. McClean, Z. Holmes, and M. Cerezo, Barren plateaus in variational quantum computing, Nat. Rev. Phys.7, 174–189 (2025)
work page 2025
- [43]
-
[44]
R. Kothari, T. Lee, M. Szegedy, and I. Newman,Query Complexity, G - Reference,Information and Interdis- ciplinary Subjects Series (World Scientific Publishing Company Pte Limited, 2025)
work page 2025
-
[45]
Understanding Quantum Algorithms via Query Complexity
A. Ambainis, Understanding quantum algorithms via query complexity, arXiv:1712.06349 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
D. Deutsch and R. Jozsa, Rapid solution of problems by quantum computation, Proceedings: Mathematical and Physical Sciences439, 553 (1992)
work page 1992
-
[47]
L. K. Grover, A fast quantum mechanical algorithm for database search, inProc. Annu. ACM Symp. Theory Comput.(1996) pp. 212–219
work page 1996
-
[48]
E. M. Stoudenmire and X. Waintal, Opening the black box inside grover’s algorithm, Phys. Rev. X14, 041029 (2024)
work page 2024
-
[49]
T. Hoefler, T. H¨ aner, and M. Troyer, Disentangling hype from practicality: On realistically achieving quantum ad- vantage, COMMUN ACM66, 82 (2023). 11
work page 2023
-
[50]
A. Javadi-Abhari, M. Treinish, K. Krsulich, C. J. Wood, J. Lishman, J. Gacon, S. Martiel, P. D. Nation, L. S. Bishop, A. W. Cross, B. R. Johnson, and J. M. Gam- betta, Quantum computing with qiskit, arXiv:2405.08810 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
IBM, IBM Quantum compute resources (2025)
work page 2025
-
[52]
S. Chowdhury, N. A. Aadit, A. Grimaldi, E. Raimondo, A. Raut, P. A. Lott, J. H. Mentink, M. M. Rams, F. Ricci-Tersenghi, M. Chiappini, L. S. Theogarajan, T. Srimani, G. Finocchio, M. Mohseni, and K. Y. Cam- sari, Pushing the boundary of quantum advantage in hard combinatorial optimization with probabilistic com- puters, arXiv:2503.10302 (2025)
-
[53]
More asymmetry yields faster matrix multiplication
J. Alman, R. Duan, V. V. Williams, Y. Xu, Z. Xu, and R. Zhou, More asymmetry yields faster matrix multipli- cation, arXiv:2404.16349 (2024)
-
[54]
X. Yi, A Study of Performance Programming of CPU, GPU accelerated Computers and SIMD Architecture, arXiv:2409.10661 (2024)
-
[55]
Parallel Programming for FPGAs
R. Kastner, J. Matai, and S. Neuendorffer, Parallel Pro- gramming for FPGAs, arXiv:1805.03648 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[56]
J. Hou, A. Barzegar, and H. G. Katzgraber, Direct com- parison of stochastic driven nonlinear dynamical systems for combinatorial optimization, Phys. Rev. E112, 035301 (2025)
work page 2025
-
[57]
T. Aonishi, T. Nagasawa, T. Koizumi, M. D. S. H. Gu- nathilaka, K. Mimura, M. Okada, S. Kako, and Y. Ya- mamoto, Highly Versatile FPGA-Implemented Cyber Coherent Ising Machine, IEEE Access12, 175843–175865 (2024)
work page 2024
-
[58]
VeloxQ: A Fast and Efficient QUBO Solver
J. Paw lowski, J. Tuziemski, P. Tarasiuk, A. Przy- bysz, R. Adamski, K. Hendzel, L. Pawela, and B. Gardas, VeloxQ: A fast and efficient QUBO solver, arXiv:2501.19221 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
D. Delahaye, S. Chaimatanan, and M. Mongeau, Simu- lated annealing: From basics to applications, inHand- book of Metaheuristics, edited by M. Gendreau and J.-Y. Potvin (Springer International Publishing, Cham, 2019) pp. 1–35
work page 2019
-
[60]
The authors did not respond to our request to share their HUBO instances
-
[61]
J. Tuziemski, J. Paw lowski, P. Tarasiuk, L. Pawela, and B. Gardas, Recent quantum runtime (dis)advantages – code repository,https://github.com/quantumz-io/ quanutm-runtime-disadvantage(2025), GitHub reposi- tory
work page 2025
-
[62]
P. Farr´ e, E. Ordog, K. Chern, and C. C. Mc- Geoch, Comparing Quantum Annealing and BF-DCQO, arXiv:2509.14358 (2025)
-
[63]
IBM, IBM Quantum Platform - Processor types (2025)
work page 2025
-
[64]
T. Zhang and J. Han, Quantized simulated bifurcation for the Ising model, in2023 IEEE 23rd International Conference on Nanotechnology (NANO)(2023) pp. 715– 720
work page 2023
-
[65]
Fulman, Random matrix theory over finite fields: a survey, arXiv:0003195 (2001)
J. Fulman, Random matrix theory over finite fields: a survey, arXiv:0003195 (2001)
work page 2001
-
[66]
C. Chamberland, G. Zhu, T. J. Yoder, J. B. Hertzberg, and A. W. Cross, Topological and subsystem codes on low-degree graphs with flag qubits, Phys. Rev. X10 (2020)
work page 2020
-
[67]
Dattani, Quadratization in discrete optimization and quantum mechanics, arxiv:1901.04405 (2019)
N. Dattani, Quadratization in discrete optimization and quantum mechanics, arxiv:1901.04405 (2019)
-
[68]
T. Kanao and H. Goto, Simulated bifurcation for higher- order cost functions, Appl. Phys. Express.16, 014501 (2022)
work page 2022
-
[69]
D. J. Earl and M. W. Deem, Parallel tempering: Theory, applications, and new perspectives, Phys. Chem. Chem. Phys.7, 3910 (2005)
work page 2005
-
[70]
A. Russkov, R. Chulkevich, and L. N. Shchur, Algo- rithm for replica redistribution in an implementation of the population annealing method on a hybrid super- computer architecture, Comput. Phys. Commun.261, 107786 (2021)
work page 2021
-
[71]
J. Machta, Population annealing with weighted averages: A monte carlo method for rough free-energy landscapes, Phys. Rev. E82, 026704 (2010)
work page 2010
-
[72]
S. V. Romero, A.-M. Visuri, A. G. Cadavid, E. Solano, and N. N. Hegade, Bias-field digitized counterdiabatic quantum algorithm for higher-order binary optimization, arxiv:2409.04477 (2024). A1 Appendix A1: Simulated Bifurcation Machine To demonstrate that the results for classical algorithms are less sensitive to runtime definition changes we consider a d...
-
[73]
Polynomial scaling for restricted Simon’s problem with fixedw The proposed classical algorithm can be further optimized for solving restricted Simon’s problem withw <⌈n/2⌉. A periodpwith at mostwset bits can always be decomposed intop=x i ⊕x j such thatx i andx j have at mostw set bits in total. Retaining the core concept from the general approach, this c...
-
[74]
HUBO instance construction We begin with providing a more detailed description of the HUBO instances used in Section IV of the main text. These instances are designed to be challenging, yet well suited for the IBM quantum computers, thus the starting point in their construction is the heavy-hex graphC 0 of IBM Heron architecture [65]. Two conflict graphs ...
-
[75]
Performance of Simulated Bifurcation and Simulated Annealing on HUBO instances In its usual formulation, both SBM and SA are designed to solve problems with up to second-order interactions. To apply them to HUBO instances, we first need to use some reduction technique to convert higher-order terms into quadratic ones. We choose a standard reduction method...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.