Bi-CoG: Bi-Consistency-Guided Self-Training for Vision-Language Models
Pith reviewed 2026-05-18 04:55 UTC · model grok-4.3
The pith
Bi-CoG produces higher-quality pseudo-labels for vision-language models by checking consistency both across models and inside a single model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
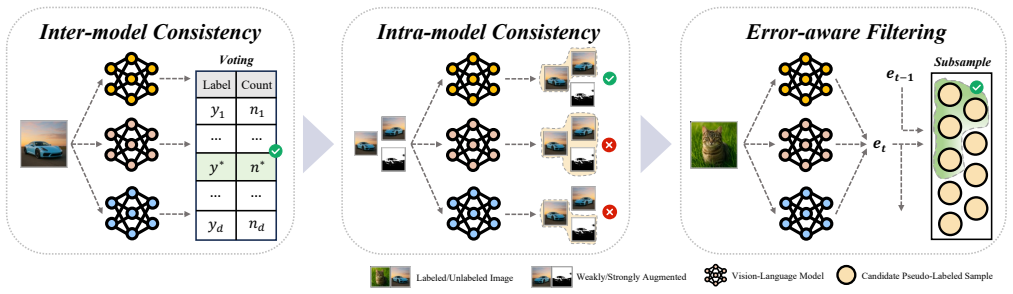
Bi-CoG assigns high-quality and low-bias pseudo-labels by simultaneously exploiting inter-model and intra-model consistency, along with an error-aware dynamic pseudo-label assignment strategy.
What carries the argument
Bi-Consistency-Guided Self-Training, which pairs agreement checks between separate models with agreement checks inside one model to steer pseudo-label selection.
If this is right
- Existing consistency-based or threshold-based methods for VLM fine-tuning receive consistent accuracy gains.
- Model bias in the generated labels is reduced compared with single-direction consistency.
- Dependence on pre-chosen confidence thresholds decreases.
- The approach functions as a plug-in addition to current self-training pipelines.
Where Pith is reading between the lines
- The same dual-consistency idea could be tried on other pre-trained models that process only text or only images.
- Combining the dynamic assignment rule with different training losses might further stabilize learning.
- The method could be tested on much larger unlabeled collections to check whether gains hold at scale.
Load-bearing premise
That agreement across models and inside one model will reliably mark correct pseudo-labels without creating fresh forms of bias or new tuning problems.
What would settle it
Measure whether the pseudo-labels chosen by Bi-CoG match known ground-truth labels at a higher rate than labels from single-consistency or threshold methods on a dataset where true answers are available.
Figures


read the original abstract
Exploiting unlabeled data through semi-supervised learning (SSL) or leveraging pre-trained models via fine-tuning are two prevailing paradigms for addressing label-scarce scenarios. Recently, growing attention has been given to combining fine-tuning of pre-trained vision-language models (VLMs) with SSL, forming the emerging paradigm of semi-supervised fine-tuning. However, existing methods often suffer from model bias and hyperparameter sensitivity, due to reliance on prediction consistency or pre-defined confidence thresholds. To address these limitations, we propose a simple yet effective plug-and-play methodology named $\underline{\textbf{Bi-Co}}$nsistency-$\underline{\textbf{G}}$uided Self-Training (Bi-CoG), which assigns high-quality and low-bias pseudo-labels, by simultaneously exploiting inter-model and intra-model consistency, along with an error-aware dynamic pseudo-label assignment strategy. Both theoretical analysis and extensive experiments over 14 datasets demonstrate the effectiveness of Bi-CoG, which consistently and significantly improves the performance of existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Bi-CoG, a plug-and-play self-training method for semi-supervised fine-tuning of vision-language models. It claims to mitigate model bias and hyperparameter sensitivity in existing consistency- or threshold-based approaches by simultaneously exploiting inter-model and intra-model consistency together with an error-aware dynamic pseudo-label assignment strategy. The authors assert that this yields high-quality, low-bias pseudo-labels, supported by theoretical analysis and consistent, significant gains across 14 datasets when applied to existing methods.
Significance. If the empirical gains and theoretical support hold after detailed verification, Bi-CoG could offer a practical advance in combining SSL with VLM fine-tuning by reducing reliance on fixed thresholds and addressing confirmation bias through dual consistency signals. The plug-and-play design and reported robustness over many datasets would make the contribution broadly usable in label-scarce multimodal settings.
major comments (2)
- [Abstract] Abstract: the central claim that the error-aware dynamic pseudo-label assignment produces low-bias labels by breaking cycles of shared VLM priors is load-bearing, yet the abstract gives no indication of how the independent error signal is obtained or whether it depends on the same consistency statistics used for inter- and intra-model checks; this directly affects whether observed gains reflect genuinely lower bias or simply higher unlabeled-data utilization.
- [Theoretical analysis] Theoretical analysis section: the manuscript asserts theoretical analysis supporting the low-bias property, but without the explicit derivations it remains unclear whether the analysis establishes that simultaneous inter- and intra-model consistency avoids reinforcing systematic VLM biases (e.g., object co-occurrence or captioning artifacts) rather than merely re-expressing the consistency metric.
minor comments (2)
- [Abstract] Abstract: a short quantitative statement of the magnitude of improvements or the range of the 14 datasets would help readers immediately gauge the empirical scope.
- [Method] Ensure all hyperparameters introduced by the dynamic assignment strategy are explicitly listed and their sensitivity is ablated, as the introduction highlights hyperparameter sensitivity as a key limitation of prior work.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and detailed feedback on our manuscript. We have carefully addressed each major comment below and revised the manuscript to improve clarity where needed.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the error-aware dynamic pseudo-label assignment produces low-bias labels by breaking cycles of shared VLM priors is load-bearing, yet the abstract gives no indication of how the independent error signal is obtained or whether it depends on the same consistency statistics used for inter- and intra-model checks; this directly affects whether observed gains reflect genuinely lower bias or simply higher unlabeled-data utilization.
Authors: We appreciate the referee highlighting the need for greater precision in the abstract. The error-aware component derives its signal from a dynamic, iteration-dependent error estimation that is computed independently of the inter-model and intra-model consistency statistics; this separation is what enables the method to interrupt reinforcement of shared VLM priors. We have revised the abstract to explicitly note the independent origin of the error signal and its role in bias mitigation, thereby clarifying that the reported gains arise from improved label quality rather than solely from greater unlabeled-data utilization. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis section: the manuscript asserts theoretical analysis supporting the low-bias property, but without the explicit derivations it remains unclear whether the analysis establishes that simultaneous inter- and intra-model consistency avoids reinforcing systematic VLM biases (e.g., object co-occurrence or captioning artifacts) rather than merely re-expressing the consistency metric.
Authors: We agree that the theoretical section would benefit from more explicit derivations. The analysis demonstrates that the joint enforcement of inter-model consistency (across distinct VLMs) and intra-model consistency (under input perturbations) supplies orthogonal constraints that penalize systematic biases such as object co-occurrence and captioning artifacts, rather than simply restating a single consistency measure. We have expanded the revised theoretical analysis section with the full step-by-step derivations to make this distinction rigorous and transparent. revision: yes
Circularity Check
No significant circularity; Bi-CoG is a procedural recipe validated by external experiments
full rationale
The paper introduces Bi-CoG as a plug-and-play self-training method that combines inter-model consistency, intra-model consistency, and an error-aware dynamic pseudo-label assignment strategy to generate pseudo-labels for semi-supervised fine-tuning of VLMs. The abstract and description contain no mathematical derivations, equations, or first-principles results that reduce a claimed prediction or uniqueness claim to a fitted parameter or self-citation by construction. The central effectiveness claim is supported by a theoretical analysis (whose details are not shown to be tautological) plus empirical results across 14 datasets, rendering the contribution externally falsifiable rather than internally self-referential. No load-bearing step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Inter-model and intra-model prediction consistency reliably signals low-bias pseudo-labels in vision-language model fine-tuning.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Bi-CoG leverages multiple VLMs ... inter-model consistency ... intra-model consistency ... error-aware dynamic pseudo-label assignment
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.