Understanding the Staged Dynamics of Transformers in Learning Latent Structure
Pith reviewed 2026-05-17 05:54 UTC · model grok-4.3
The pith
Transformers acquire different components of latent structure in discrete stages during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
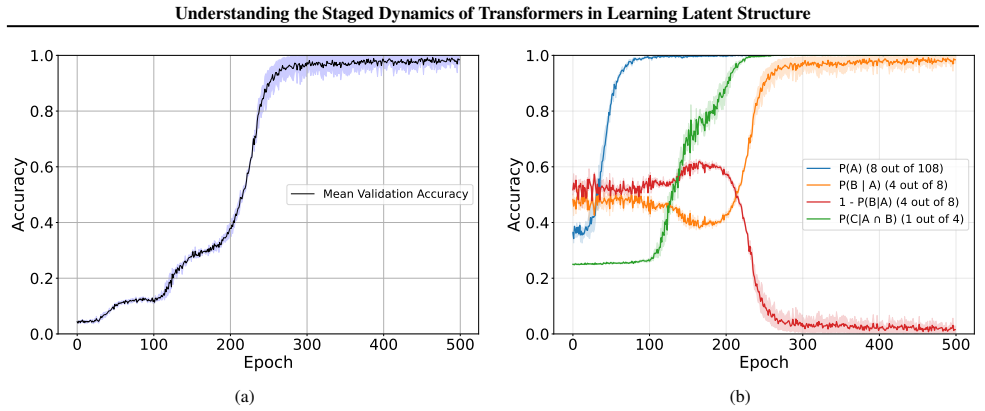
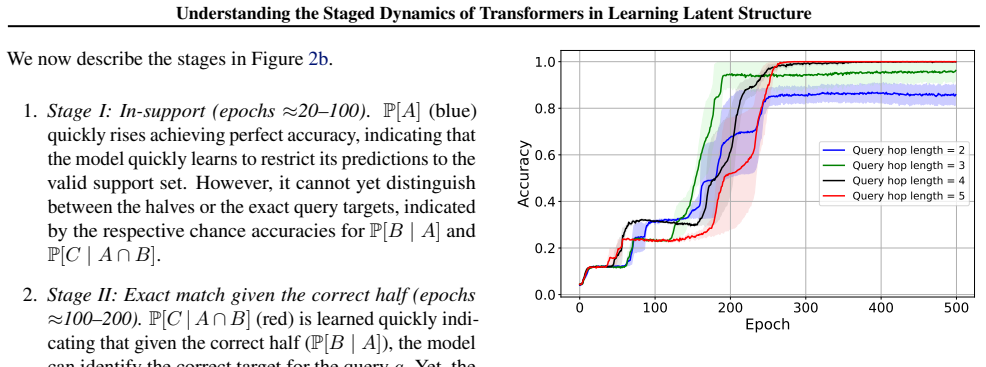
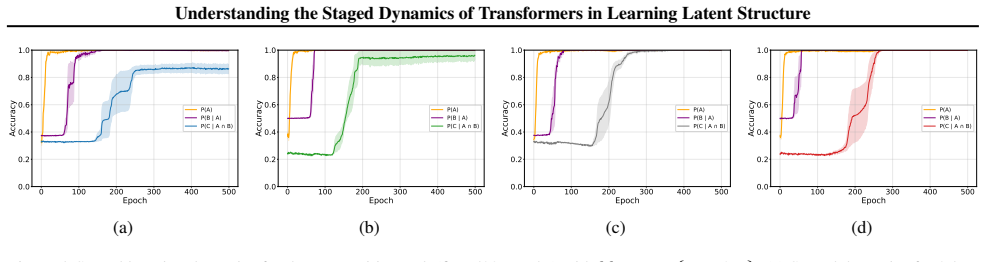
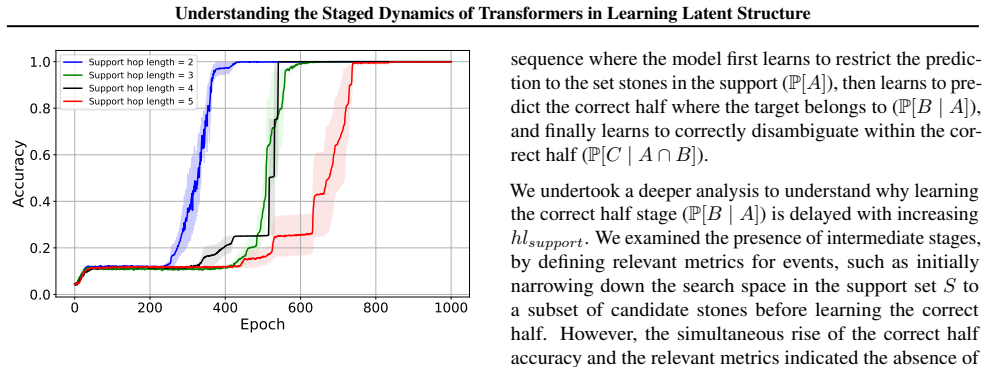
By factorizing each task into interpretable components, the model learns the different latent structure components in discrete stages. The model composes fundamental transitions robustly but struggles to decompose complex examples to discover the atomic transitions. Using causal interventions, layer-specific plasticity windows are identified during which freezing substantially delays or prevents stage completion.
What carries the argument
Factorization of tasks into separate interpretable components, tracked across training steps and tested with targeted layer freezing to expose plasticity windows.
If this is right
- The model builds up its abilities through a predictable sequence of phases rather than acquiring all skills simultaneously.
- Composition of simple transitions succeeds more consistently than decomposition of complex sequences.
- Freezing specific layers during their identified plasticity window blocks or delays completion of the corresponding learning stage.
- Capabilities appear in a staged order that can be observed by monitoring performance on each factored component separately.
Where Pith is reading between the lines
- If the staged pattern holds beyond the tested tasks, training procedures could be adjusted to emphasize one component at a time for greater efficiency.
- The asymmetry between composition and decomposition points to a possible need for targeted data or objectives to strengthen decomposition skills.
- Layer-specific windows may appear in other model sizes or architectures and could inform selective updating or modular training approaches.
Load-bearing premise
The chosen tasks and their breakdown into distinct parts accurately reflect the mechanisms of latent structure learning that occur in broader settings.
What would settle it
Repeated training runs in which mastery of each component improves gradually and continuously rather than showing abrupt jumps at separate points.
Figures




read the original abstract
Language modeling has shown us that transformers can discover latent structure from context, but the dynamics of how they acquire different components of that structure remain poorly understood, leading to assertions that models just remix training data. In this work, we use the Alchemy benchmark in a controlled setting (Wang et al.,2021) to investigate latent structure learning. We train a small decoder-only transformer on three task variants: 1) inferring missing transitions from partial contextual information, 2) composing simple rules to solve multi-transition sequences, and 3) decomposing complex multi-step examples to infer intermediate transitions. By factorizing each task into interpretable components, we show that the model learns the different latent structure components in discrete stages. We also observe an asymmetry: the model composes fundamental transitions robustly, but struggles to decompose complex examples to discover the atomic transitions. Finally, using causal interventions, we identify layer-specific plasticity windows during which freezing substantially delays or prevents stage completion. These findings provide insight into how a transformer model acquires latent structure, offering a detailed view of how capabilities evolve during training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates how a small decoder-only transformer acquires latent structure on the Alchemy benchmark. It trains models on three task variants—inferring missing transitions from partial context, composing simple rules for multi-transition sequences, and decomposing complex examples to recover atomic transitions—then factorizes each into interpretable components. The central claims are that learning proceeds in discrete stages, that composition of fundamental transitions is robust while decomposition is difficult, and that layer-specific plasticity windows exist, identified via causal freezing interventions that delay or prevent stage completion.
Significance. If the results hold, the work supplies a granular, intervention-based account of staged capability acquisition that moves beyond black-box training narratives. The controlled benchmark factorization and layer-freezing experiments provide concrete evidence for timing effects in structure learning, which is valuable for mechanistic interpretability and could inform curriculum design or targeted training interventions.
major comments (2)
- [§4] The discreteness of stages rests on performance curves over sub-task components; without reported change-point detection, multiple random seeds, or statistical controls for variance, it remains possible that apparent stages reflect noise or post-hoc binning rather than robust transitions (§4, performance plots).
- [Causal interventions section] The plasticity-window claim requires showing that freezing a layer at a given step specifically blocks the targeted component rather than globally slowing learning; the current intervention results would be strengthened by a control that matches total compute or capacity reduction across timings.
minor comments (2)
- [Abstract] The abstract omits model size, layer count, training procedure, and number of runs; adding one sentence would let readers assess robustness without immediately consulting the methods.
- [Figures] Figure legends for the freezing experiments should explicitly state the number of seeds and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation for minor revision. The comments identify valuable opportunities to strengthen the evidence for discrete stages and the specificity of plasticity windows. We respond to each major comment below.
read point-by-point responses
-
Referee: [§4] The discreteness of stages rests on performance curves over sub-task components; without reported change-point detection, multiple random seeds, or statistical controls for variance, it remains possible that apparent stages reflect noise or post-hoc binning rather than robust transitions (§4, performance plots).
Authors: We agree that objective statistical validation would make the stage transitions more robust. In the revised version we will report performance curves aggregated over at least five random seeds with standard-error shading. We will also apply a standard change-point detection procedure (PELT) to the per-component accuracy trajectories and report the detected transition steps together with their statistical significance. These additions will replace reliance on visual inspection alone. revision: yes
-
Referee: [Causal interventions section] The plasticity-window claim requires showing that freezing a layer at a given step specifically blocks the targeted component rather than globally slowing learning; the current intervention results would be strengthened by a control that matches total compute or capacity reduction across timings.
Authors: We concur that matched controls are necessary to isolate timing-specific effects. In the revision we will add experiments that apply equivalent capacity reductions (freezing a randomly chosen layer or reducing hidden dimension by the same fraction) at the same training checkpoints while keeping total compute identical. These controls will be compared directly against the original layer-specific freezes to demonstrate that the observed delays are attributable to the plasticity windows rather than nonspecific slowdown. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on empirical observations from training decoder-only transformers on controlled Alchemy benchmark variants, including performance curves on sub-tasks, composition/decomposition asymmetry, and layer-freezing interventions to identify plasticity windows. These are direct measurements from training runs rather than derivations that reduce to self-definitions, fitted inputs renamed as predictions, or self-citation chains. The factorization into interpretable components serves as an analysis lens for staging, not a circular redefinition of the target quantities. No load-bearing steps invoke uniqueness theorems or ansatzes from prior self-work that would force the results by construction. The work is self-contained against its experimental controls and benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
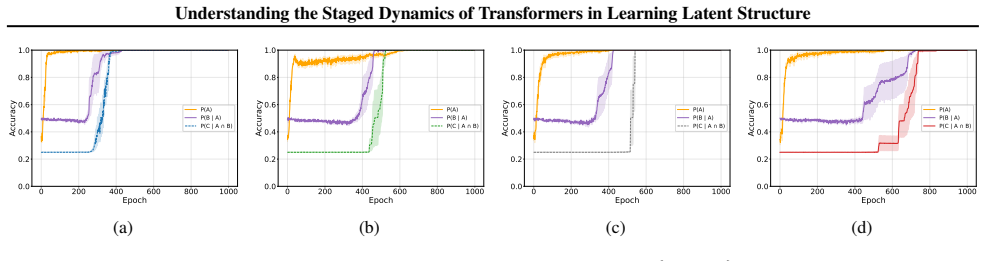
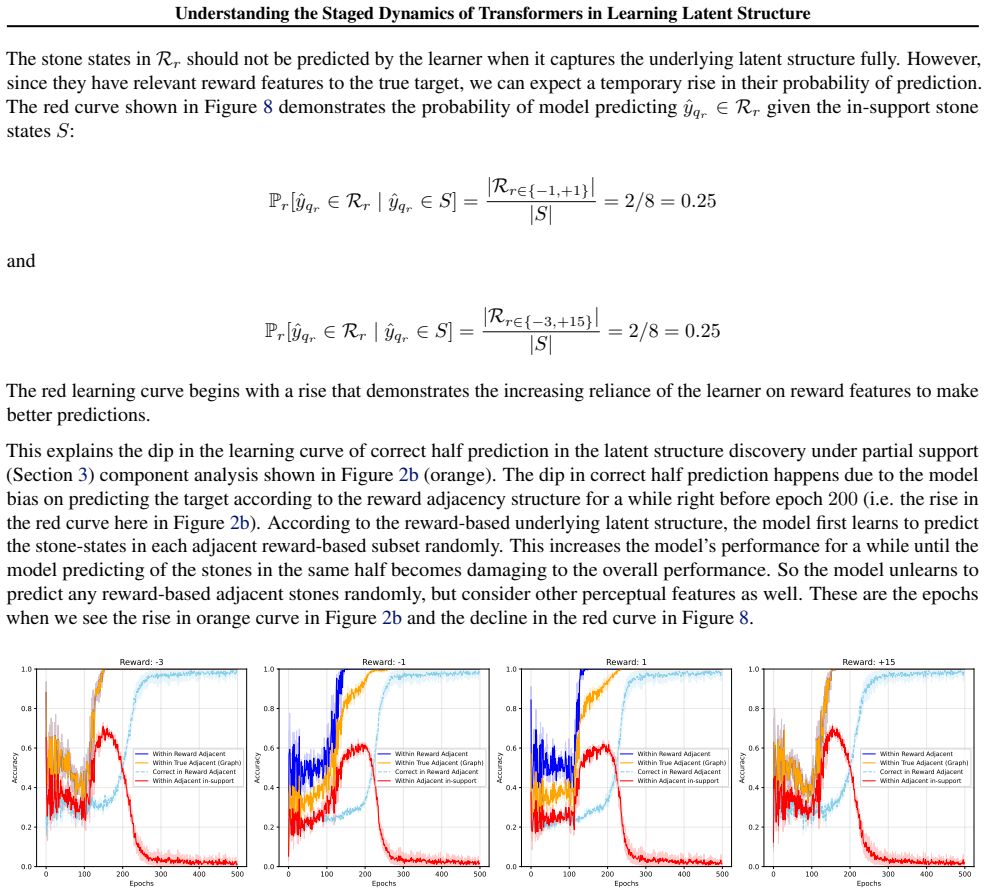
By factorizing each task into interpretable components, we show that the model learns the different latent structure components in discrete stages.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Alchemy benchmark... eight vertices arranged in a cubic structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Software available from wandb.com
URL https://www.wandb.com/. Software available from wandb.com. Chan, S. C. Y ., Santoro, A., Lampinen, A. K., Wang, J. X., Singh, A., Richemond, P. H., McClelland, J., and Hill, F. Data Distributional Properties Drive Emergent In-Context Learning in Transformers, November 2022. Chen, A., Shwartz-Ziv, R., Cho, K., Leavitt, M. L., and Saphra, N. Sudden Drop...
work page 2022
-
[2]
doi: 10.18653/v1/2023.bigpicture-1.8
Association for Computational Linguistics. doi: 10.18653/v1/2023.bigpicture-1.8. Hewitt, J. and Manning, C. D. A Structural Probe for Finding Syntax in Word Representations. In Burstein, J., Doran, C., and Solorio, T. (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language...
-
[3]
Association for Computational Linguistics. doi: 10.18653/v1/N19-1419. Hupkes, D., Dankers, V ., Mul, M., and Bruni, E. Com- positionality Decomposed: How do Neural Networks Generalise? Journal of Artificial Intelligence Research, 67:757–795, April 2020. ISSN 1076-9757. doi: 10.1613/ jair.1.11674. Khot, T., Trivedi, H., Finlayson, M., Fu, Y ., Richardson, ...
-
[4]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.561. Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Köpf, A., Yang, E., DeVito, Z., Rai- son, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S. Pytorch: An imper...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.561 2024
-
[5]
doi: 10.18653/v1/2021.eacl-main.264
Association for Computational Linguistics. doi: 10.18653/v1/2021.eacl-main.264. Reddy, G. The mechanistic basis of data dependence and abrupt learning in an in-context classification task, De- cember 2023. Shojaee, P., Mirzadeh, I., Alizadeh, K., Horton, M., Bengio, S., and Farajtabar, M. The Illusion of Thinking: Un- derstanding the Strengths and Limitat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.