PGOT: A Physics-Geometry Operator Transformer for Complex PDEs
Pith reviewed 2026-05-16 19:57 UTC · model grok-4.3
The pith
PGOT uses spectrum-preserving geometric attention to model PDEs on complex unstructured meshes without losing boundary information to aliasing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PGOT reconstructs physical feature learning through explicit geometry awareness via Spectrum-Preserving Geometric Attention. The module applies a physics slicing-geometry injection mechanism to incorporate multi-scale geometric encodings while preserving features and enforcing linear O(N) complexity. Computations are dynamically routed to low-order linear paths in smooth regions and high-order nonlinear paths at shocks and discontinuities according to spatial coordinates.
What carries the argument
Spectrum-Preserving Geometric Attention (SpecGeo-Attention) with a physics slicing-geometry injection mechanism that folds multi-scale geometric encodings into attention to avoid aliasing while retaining O(N) scaling.
If this is right
- State-of-the-art accuracy is reached on four standard PDE benchmarks.
- Strong results are obtained on large-scale industrial problems such as airfoil and car design.
- Spatially adaptive routing improves precision by matching computation order to local field behavior.
- Linear complexity supports scaling to meshes too large for quadratic attention.
Where Pith is reading between the lines
- The slicing-injection pattern could be transferred to other mesh-based tasks such as finite-element analysis in structural mechanics.
- Dynamic linear-to-nonlinear routing may reduce overall compute in any simulation that mixes smooth flow with localized shocks.
- Extending the same geometry injection to time-dependent or three-dimensional industrial cases would test whether the linear scaling holds at higher resolution.
Load-bearing premise
Injecting geometry via physics slicing into attention preserves multi-scale features and boundary information without creating geometric aliasing.
What would settle it
A side-by-side feature visualization or error map on a fine-boundary unstructured mesh benchmark where PGOT exhibits the same aliasing or boundary loss seen in prior reduced-dimension transformers would disprove the preservation claim.
Figures




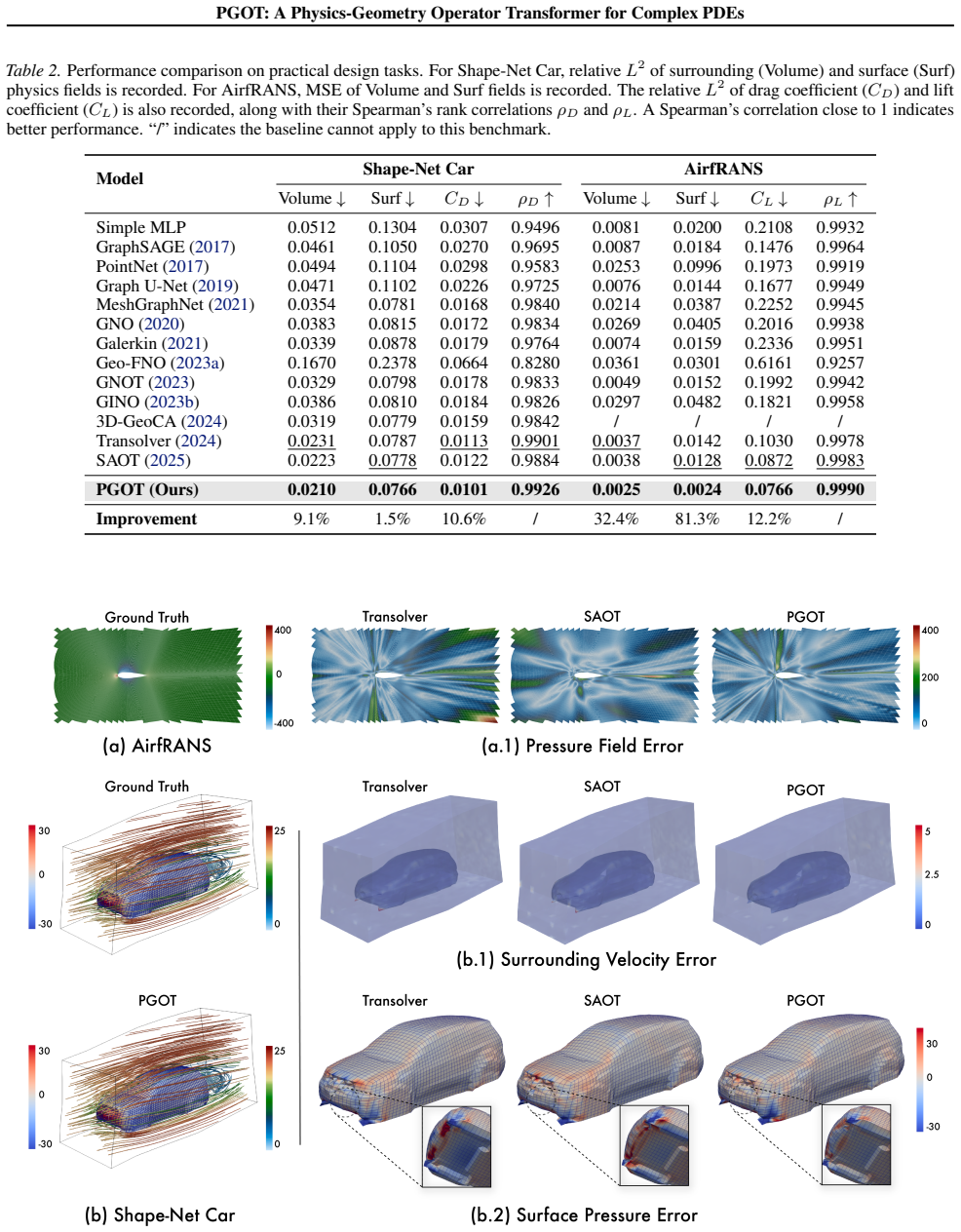








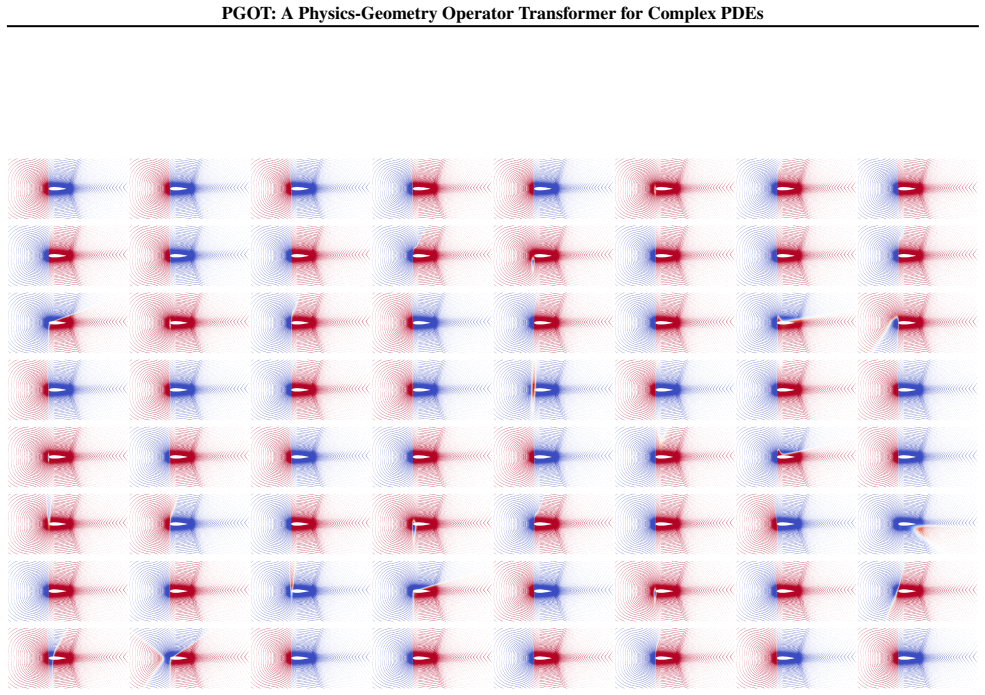

read the original abstract
While Transformers have demonstrated remarkable potential in modeling Partial Differential Equations (PDEs), modeling large-scale unstructured meshes with complex geometries remains a significant challenge. Existing efficient architectures often employ feature dimensionality reduction strategies, which inadvertently induces Geometric Aliasing, resulting in the loss of critical physical boundary information. To address this, we propose the Physics-Geometry Operator Transformer (PGOT), designed to reconstruct physical feature learning through explicit geometry awareness. Specifically, we propose Spectrum-Preserving Geometric Attention (SpecGeo-Attention). Utilizing a ``physics slicing-geometry injection" mechanism, this module incorporates multi-scale geometric encodings to explicitly preserve multi-scale geometric features while maintaining linear computational complexity $O(N)$. Furthermore, PGOT dynamically routes computations to low-order linear paths for smooth regions and high-order non-linear paths for shock waves and discontinuities based on spatial coordinates, enabling spatially adaptive and high-precision physical field modeling. PGOT achieves consistent state-of-the-art performance across four standard benchmarks and excels in large-scale industrial tasks including airfoil and car designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Physics-Geometry Operator Transformer (PGOT) to model PDEs on large-scale unstructured meshes with complex geometries. It introduces Spectrum-Preserving Geometric Attention (SpecGeo-Attention) that uses a physics slicing-geometry injection mechanism to incorporate multi-scale geometric encodings while preserving features and maintaining O(N) complexity. A dynamic routing scheme directs computations to low-order linear paths in smooth regions and high-order non-linear paths near discontinuities. The manuscript claims consistent state-of-the-art results on four standard benchmarks plus large-scale industrial tasks such as airfoil and car design.
Significance. If the no-aliasing and performance claims are substantiated, PGOT would offer a scalable architecture for geometry-aware PDE modeling that avoids the feature-reduction pitfalls of prior efficient transformers. The explicit multi-scale injection and spatially adaptive routing address a recognized limitation in applying transformers to industrial-scale unstructured meshes. The work would be of interest to the scientific machine learning community provided the central technical guarantees are demonstrated.
major comments (3)
- [Abstract and §3] Abstract and §3: The central claim that SpecGeo-Attention 'successfully preserves multi-scale geometric features' and 'avoids geometric aliasing' is load-bearing for the contribution, yet the spectrum-preserving property is neither formally defined nor verified. No Fourier or eigen-analysis of the geometric encodings is supplied, nor is any quantitative metric (e.g., high-frequency boundary error or aliasing index) reported to confirm preservation of critical physical boundary information.
- [§4 and §5] §4 and §5: The headline SOTA performance on four benchmarks and industrial tasks is asserted without the experimental details required to evaluate it. The text supplies no baselines, error bars, statistical significance tests, or ablation studies isolating the contribution of the physics-slicing injection versus the dynamic routing, rendering the performance claim unverifiable from the given material.
- [§3.2] §3.2: The assertion of strict O(N) complexity for the multi-scale injection and dynamic high-order routing is not accompanied by a complexity analysis or empirical timing breakdown. The combination of multi-scale encodings and spatially adaptive routing could still incur super-linear costs or frequency folding in practice; this must be shown explicitly to support the scalability claim.
minor comments (2)
- [§3] Notation for the dynamic routing thresholds and the precise definition of 'physics slicing' should be introduced with explicit equations rather than descriptive prose.
- [§5] Figure captions for the industrial-task visualizations should include quantitative error metrics alongside qualitative plots to allow direct comparison with baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to incorporate the requested clarifications, analyses, and experimental details.
read point-by-point responses
-
Referee: [Abstract and §3] The central claim that SpecGeo-Attention 'successfully preserves multi-scale geometric features' and 'avoids geometric aliasing' is load-bearing for the contribution, yet the spectrum-preserving property is neither formally defined nor verified. No Fourier or eigen-analysis of the geometric encodings is supplied, nor is any quantitative metric (e.g., high-frequency boundary error or aliasing index) reported to confirm preservation of critical physical boundary information.
Authors: We agree that a formal definition and explicit verification of the spectrum-preserving property are needed to substantiate the central claim. The SpecGeo-Attention is constructed via physics slicing-geometry injection to avoid dimensionality reduction and thereby preserve multi-scale features by design, but the manuscript lacks the requested formalization and supporting analysis. In revision we will add a precise definition of spectrum preservation in §3, include Fourier and eigen-analysis of the geometric encodings, and report quantitative metrics such as high-frequency boundary error to verify the no-aliasing behavior. revision: yes
-
Referee: [§4 and §5] The headline SOTA performance on four benchmarks and industrial tasks is asserted without the experimental details required to evaluate it. The text supplies no baselines, error bars, statistical significance tests, or ablation studies isolating the contribution of the physics-slicing injection versus the dynamic routing, rendering the performance claim unverifiable from the given material.
Authors: The experimental sections present performance comparisons, yet we acknowledge that explicit baseline descriptions, error bars from multiple runs, statistical significance tests, and targeted ablations isolating the physics-slicing injection versus dynamic routing are insufficient. We will expand §§4 and 5 to include full baseline specifications, error bars, significance testing, and ablations that separately quantify the contribution of each component. revision: yes
-
Referee: [§3.2] The assertion of strict O(N) complexity for the multi-scale injection and dynamic high-order routing is not accompanied by a complexity analysis or empirical timing breakdown. The combination of multi-scale encodings and spatially adaptive routing could still incur super-linear costs or frequency folding in practice; this must be shown explicitly to support the scalability claim.
Authors: We will add a rigorous complexity analysis in §3.2 that formally establishes O(N) scaling for both the multi-scale injection and the spatially adaptive routing. We will also include empirical timing breakdowns across the benchmark datasets to confirm practical linear scaling and to rule out super-linear costs or frequency folding. revision: yes
Circularity Check
No circularity: novel architecture with empirical claims
full rationale
The paper introduces new components (SpecGeo-Attention, physics slicing-geometry injection, dynamic routing) defined explicitly as design choices rather than derived from or equivalent to prior equations, fitted parameters, or self-citations. Performance claims rest on benchmark results, not on predictions that reduce to inputs by construction. No self-definitional loops, renamed known results, or load-bearing self-citations appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformers can be extended with explicit geometry injection to avoid aliasing on unstructured meshes
invented entities (2)
-
SpecGeo-Attention
no independent evidence
-
Dynamic low-order linear / high-order non-linear routing
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Spectrum-Preserving Geometric Attention (SpecGeo-Attention) ... physics slicing-geometry injection mechanism ... multi-scale geometric encodings ... O(N) linear complexity
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TaylorDecomp-FFN ... low-order linear paths for smooth regions and high-order non-linear paths for shock waves ... spatial gate α(g)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Universal physics transformers: A framework for efficiently scaling neural operators
Alkin, B., F ¨urst, A., Schmid, S., Gruber, L., Holzleitner, M., and Brandstetter, J. Universal physics transformers: A framework for efficiently scaling neural operators. InNeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024,
work page 2024
-
[2]
Choose a transformer: Fourier or galerkin
Cao, S. Choose a transformer: Fourier or galerkin. InNeurIPS 2021, December 6-14, 2021, virtual, pp. 24924–24940,
work page 2021
-
[3]
Parameterized physics-informed neural networks for parameterized pdes
Cho, W., Jo, M., Lim, H., Lee, K., Lee, D., Hong, S., and Park, N. Parameterized physics-informed neural networks for parameterized pdes. InICML 2024, Vienna, Austria, July 21-27,
work page 2024
-
[4]
Deng, J., Li, X., Xiong, H., Hu, X., and Ma, J. Geometry-guided conditional adaptation for surrogate models of large-scale 3d pdes on arbitrary geometries. InIJCAI 2024, Jeju, South Korea, August 3-9, 2024, pp. 5790–5798. ijcai.org,
work page 2024
- [5]
-
[6]
Efficient token mixing for transformers via adaptive fourier neural operators
Guibas, J., Mardani, M., Li, Z., Tao, A., Anandkumar, A., and Catanzaro, B. Efficient token mixing for transformers via adaptive fourier neural operators. InICLR 2022, Virtual Event, April 25-29,
work page 2022
-
[7]
Multiwavelet-based operator learning for differential equations
Gupta, G., Xiao, X., and Bogdan, P. Multiwavelet-based operator learning for differential equations. InNeurIPS 2021, December 6-14, 2021, virtual, pp. 24048–24062,
work page 2021
-
[8]
GNOT: A general neural operator transformer for operator learning
Hao, Z., Wang, Z., Su, H., Ying, C., Dong, Y ., Liu, S., Cheng, Z., Song, J., and Zhu, J. GNOT: A general neural operator transformer for operator learning. InICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 ofProceedings of Machine Learning Research, pp. 12556–12569. PMLR,
work page 2023
-
[9]
Understanding the expressivity and trainability of fourier neural operator: A mean-field perspective
Koshizuka, T., Fujisawa, M., Tanaka, Y ., and Sato, I. Understanding the expressivity and trainability of fourier neural operator: A mean-field perspective. InNeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024,
work page 2024
-
[10]
Fnet: Mixing tokens with fourier transforms
Lee-Thorp, J., Ainslie, J., Eckstein, I., and Onta ˜n´on, S. Fnet: Mixing tokens with fourier transforms. InNAACL 2022, Seattle, WA, United States, July 10-15, 2022, pp. 4296–4313. Association for Computational Linguistics,
work page 2022
-
[11]
Maximal update parametrization and zero-shot hyperparameter transfer for fourier neural operators
Li, S., Yoo, S., and Yang, Y . Maximal update parametrization and zero-shot hyperparameter transfer for fourier neural operators. InICML 2025, Vancouver, BC, Canada, July 13-19,
work page 2025
-
[12]
Neural Operator: Graph Kernel Network for Partial Differential Equations
22 PGOT: A Physics-Geometry Operator Transformer for Complex PDEs Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., and Anandkumar, A. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485,
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[13]
B., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A
Li, Z., Kovachki, N. B., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A. M., and Anandkumar, A. Fourier neural operator for parametric partial differential equations. InICLR 2021, Virtual Event, Austria, May 3-7,
work page 2021
-
[14]
Z., Liu, B., and Anandkumar, A
Li, Z., Huang, D. Z., Liu, B., and Anandkumar, A. Fourier neural operator with learned deformations for pdes on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023a. Li, Z., Kovachki, N. B., Choy, C. B., Li, B., Kossaifi, J., Otta, S. P., Nabian, M. A., Stadler, M., Hundt, C., Azizzadenesheli, K., and Anandkumar, A. Geometry-inform...
work page 2023
-
[15]
Transolver++: An accurate neural solver for pdes on million-scale geometries
Luo, H., Wu, H., Zhou, H., Xing, L., Di, Y ., Wang, J., and Long, M. Transolver++: An accurate neural solver for pdes on million-scale geometries. InICML 2025, Vancouver, BC, Canada, July 13-19,
work page 2025
-
[16]
Morris, E., Shen, H., Du, W., Sajjad, M. H., and Shi, B. Geometric instability of graph neural networks on large graphs. arXiv preprint arXiv:2308.10099,
-
[17]
Pfaff, T., Fortunato, M., Sanchez-Gonzalez, A., and Battaglia, P. W. Learning mesh-based simulation with graph networks. InICLR 2021, Virtual Event, Austria, May 3-7,
work page 2021
-
[18]
Rahman, M. A., Ross, Z. E., and Azizzadenesheli, K. U-NO: u-shaped neural operators.Transactions on Machine Learning Research, 2023,
work page 2023
-
[19]
Global filter networks for image classification
Rao, Y ., Zhao, W., Zhu, Z., Lu, J., and Zhou, J. Global filter networks for image classification. InNeurIPS 2021, December 6-14, 2021, virtual, pp. 980–993,
work page 2021
-
[20]
Tran, A., Mathews, A. P., Xie, L., and Ong, C. S. Factorized fourier neural operators. InICLR 2023, Kigali, Rwanda, May 1-5,
work page 2023
-
[21]
Quanonet: Quantum neural operator with application to differential equation
23 PGOT: A Physics-Geometry Operator Transformer for Complex PDEs Wang, R., Xia, Z., Yan, G., and Yan, J. Quanonet: Quantum neural operator with application to differential equation. In ICML 2025, Vancouver, BC, Canada, July 13-19,
work page 2025
-
[22]
OpenReview.net, 2025a. Wang, T. and Wang, C. Latent neural operator for solving forward and inverse PDE problems. InNeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024,
work page 2024
-
[23]
Solving high-dimensional pdes with latent spectral models
Wu, H., Hu, T., Luo, H., Wang, J., and Long, M. Solving high-dimensional pdes with latent spectral models. InICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 ofProceedings of Machine Learning Research, pp. 37417–37438. PMLR,
work page 2023
-
[24]
Transolver: A fast transformer solver for pdes on general geometries
Wu, H., Luo, H., Wang, H., Wang, J., and Long, M. Transolver: A fast transformer solver for pdes on general geometries. In ICML 2024, Vienna, Austria, July 21-27,
work page 2024
-
[25]
Improved operator learning by orthogonal attention
Xiao, Z., Hao, Z., Lin, B., Deng, Z., and Su, H. Improved operator learning by orthogonal attention. InICML 2024, Vienna, Austria, July 21-27,
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.