Do Sparse Autoencoders Identify Reasoning Features in Language Models?
Pith reviewed 2026-05-21 15:48 UTC · model grok-4.3
The pith
Sparse autoencoders often retain low-dimensional token patterns rather than genuine reasoning processes in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
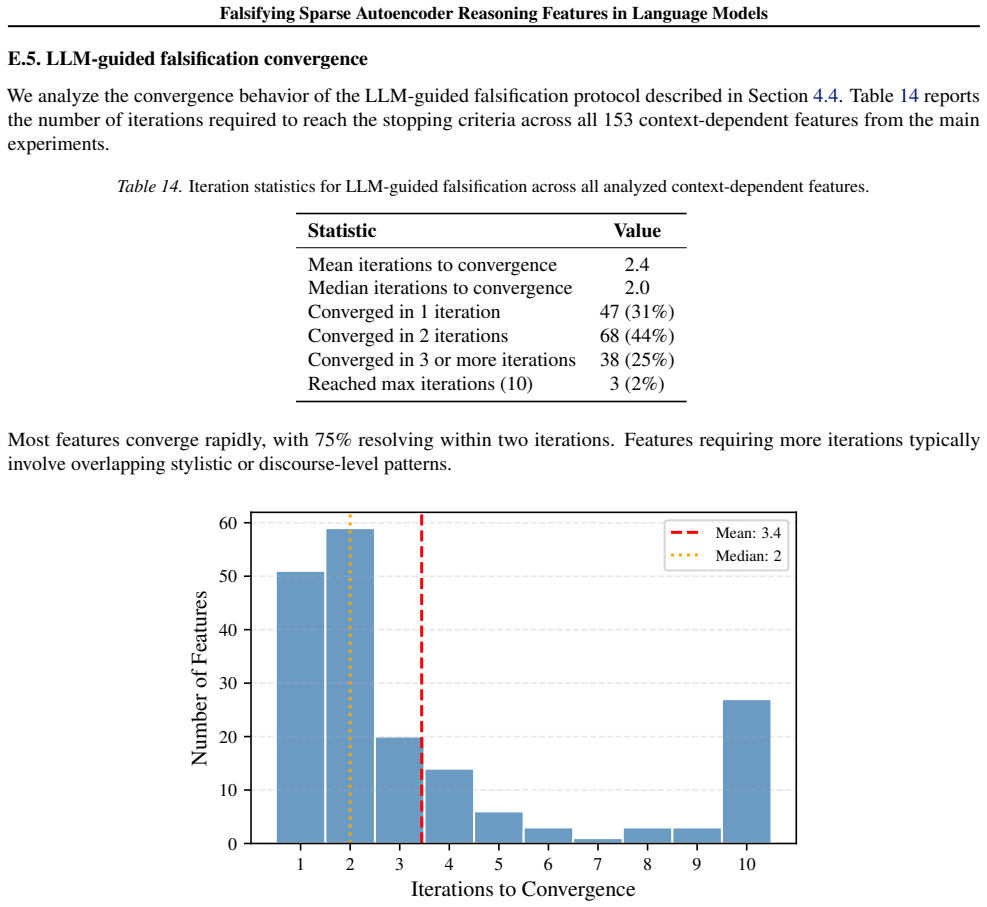
In the settings studied, sparse decompositions preferentially retain low-dimensional correlates that co-occur with reasoning traces; this is shown by 45-90 percent of contrastively selected features activating after injection of a few associated tokens into non-reasoning text, by the remaining candidates activating on LLM-constructed non-reasoning counterexamples or deactivating on meaning-preserving paraphrases, and by minimal effects when those features are used for steering.
What carries the argument
A falsification-based evaluation framework that combines causal token injection with LLM-guided construction of counterexamples and paraphrases to test whether an SAE feature encodes reasoning or surface cues.
If this is right
- Many contrastively selected reasoning features activate after injection of only a few associated tokens into non-reasoning text.
- Context-dependent candidates still activate on targeted non-reasoning inputs produced by the LLM and deactivate on paraphrases of reasoning traces.
- Steering with the identified features yields only minimal performance changes on the evaluated reasoning benchmarks.
- Attributing high-level behaviors such as reasoning to individual SAE features requires explicit falsification against simpler co-occurring explanations.
Where Pith is reading between the lines
- The results suggest that similar low-dimensional bias may affect SAE interpretations of other high-level behaviors such as planning or arithmetic.
- Improved methods would need to isolate higher-dimensional variation inside a behavior rather than relying on contrastive selection alone.
- This pattern raises a general question about how to certify that any discovered feature participates in the full computation rather than a correlated shortcut.
Load-bearing premise
Token-level causal interventions together with LLM-generated counterexamples and paraphrases constitute valid tests that can distinguish reasoning encoding from surface cues.
What would settle it
Finding that the selected features remain inactive when their associated tokens are injected into non-reasoning text, or that they stay active after meaning-preserving paraphrases of top-activating reasoning traces, would falsify the claim that these features primarily track low-dimensional correlates.
Figures









read the original abstract
We study how reliably sparse autoencoders (SAEs) support claims about reasoning-related internal features in large language models. We first give a stylized analysis showing that sparsity-regularized decoding can preferentially retain stable low-dimensional correlates while suppressing high-dimensional within-behavior variation, motivating the possibility that contrastively selected "reasoning" features may concentrate on cue-like structure when such cues are coupled with reasoning traces. Building on this perspective, we propose a falsification-based evaluation framework that combines causal token injection with LLM-guided counterexample construction. Across 22 configurations spanning multiple model families, layers, and reasoning datasets, we find that many contrastively selected candidates are highly sensitive to token-level interventions, with 45%-90% activating after injecting only a few associated tokens into non-reasoning text. For the remaining context-dependent candidates, LLM-guided falsification produces targeted non-reasoning inputs that trigger activation and meaning-preserving paraphrases of top-activating reasoning traces that suppress it. A small steering study yields minimal changes on the evaluated benchmarks. Overall, our results suggest that, in the settings we study, sparse decompositions can favor low-dimensional correlates that co-occur with reasoning, underscoring the need for falsification when attributing high-level behaviors to individual SAE features. Code is available at https://github.com/GeorgeMLP/reasoning-probing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines whether sparse autoencoders (SAEs) reliably recover reasoning-related features in LLMs. It presents a stylized analysis arguing that sparsity can favor stable low-dimensional correlates over high-dimensional reasoning variation, then introduces a falsification framework using token injection and LLM-generated counterexamples/paraphrases. Across 22 configurations (multiple models, layers, reasoning datasets), contrastively selected features show 45-90% activation after injecting a few associated tokens into non-reasoning text; remaining candidates activate on targeted non-reasoning counterexamples but suppress on meaning-preserving paraphrases. A small steering experiment produces minimal benchmark changes. The authors conclude that SAEs often capture co-occurring surface cues rather than reasoning per se and stress the need for falsification when attributing behaviors to individual features. Code is released.
Significance. If the central empirical pattern holds, the work supplies a useful cautionary result and concrete falsification protocol for the growing literature on SAE-based mechanistic interpretability of high-level capabilities. The multi-configuration scope and public code are strengths. The stylized analysis usefully motivates why contrastive selection may latch onto correlates. However, the absence of baseline activation rates, statistical controls, and explicit comparison to known abstract-reasoning features limits how strongly the results can be read as evidence against reasoning encoding rather than against the particular intervention suite.
major comments (3)
- [Abstract / Evaluation Framework] Abstract and evaluation framework: the reported 45%-90% activation rates after token injection are presented without baseline activation statistics on random or unrelated tokens, nor any mention of how many candidate features were screened before the contrastive selection step. This leaves open the possibility that the sensitivity figures are inflated by post-hoc choice of the most cue-like features.
- [Evaluation Framework] LLM-guided counterexample construction: the description does not specify quantitative constraints ensuring that generated counterexamples differ from reasoning traces only in the reasoning component while preserving all other semantics and surface statistics. Without such controls or inter-annotator agreement metrics, it is unclear whether activation on counterexamples falsifies reasoning encoding or merely detects residual lexical cues.
- [Steering Study] Steering study: the claim of 'minimal changes on the evaluated benchmarks' is given without reporting effect sizes, variance across runs, or comparison to random steering vectors of matched sparsity. This weakens the inference that the features do not participate in reasoning computations.
minor comments (2)
- [Stylized Analysis] The stylized analysis would benefit from a short formal statement (e.g., a proposition or inequality) showing the precise condition under which sparsity prefers low-dimensional correlates.
- [Experimental Setup] Table or figure summarizing the 22 configurations (model, layer, dataset, number of features tested) is missing; adding one would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify opportunities to strengthen the transparency of our evaluation framework and steering results. We respond point-by-point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / Evaluation Framework] Abstract and evaluation framework: the reported 45%-90% activation rates after token injection are presented without baseline activation statistics on random or unrelated tokens, nor any mention of how many candidate features were screened before the contrastive selection step. This leaves open the possibility that the sensitivity figures are inflated by post-hoc choice of the most cue-like features.
Authors: We agree that baseline activation rates and details on the screening process would improve interpretability. In the revised manuscript we will report activation rates on random and unrelated tokens as explicit baselines. We will also state the total number of SAE features per configuration and describe the systematic contrastive selection procedure applied to all features, clarifying that selection was not post-hoc. revision: yes
-
Referee: [Evaluation Framework] LLM-guided counterexample construction: the description does not specify quantitative constraints ensuring that generated counterexamples differ from reasoning traces only in the reasoning component while preserving all other semantics and surface statistics. Without such controls or inter-annotator agreement metrics, it is unclear whether activation on counterexamples falsifies reasoning encoding or merely detects residual lexical cues.
Authors: We will expand the methods to include the exact prompts used for counterexample and paraphrase generation, along with quantitative checks (e.g., token overlap and embedding similarity) that were applied to preserve surface statistics. Because the generation is fully automated, inter-annotator agreement metrics were not collected; we will note this limitation explicitly and argue that the consistent suppression on meaning-preserving paraphrases still provides evidence against purely lexical explanations. revision: partial
-
Referee: [Steering Study] Steering study: the claim of 'minimal changes on the evaluated benchmarks' is given without reporting effect sizes, variance across runs, or comparison to random steering vectors of matched sparsity. This weakens the inference that the features do not participate in reasoning computations.
Authors: We accept that additional statistical reporting is warranted. The revised version will include effect sizes, standard deviations across repeated runs, and direct comparisons against random steering vectors of matched sparsity. These additions will provide a clearer quantitative basis for the observed minimal benchmark changes. revision: yes
Circularity Check
No load-bearing circularity; evaluations rely on independent interventions
full rationale
The paper motivates its perspective with a stylized analysis of sparsity-regularized decoding and then evaluates via external causal token injections and LLM-generated counterexamples/paraphrases. These tests measure activation rates on newly constructed inputs rather than fitting parameters to the same data used for feature selection or claiming predictions that reduce tautologically to inputs. No equations, self-citations, or ansatzes are shown to force the central falsification results by construction. This is a standard empirical setup with independent evidence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparsity-regularized decoding preferentially retains stable low-dimensional correlates while suppressing high-dimensional within-behavior variation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
sparsity-regularized decoding can preferentially retain stable low-dimensional correlates while suppressing high-dimensional within-behavior variation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Then, you will cross the river using the old bridge
To reach the ancient temple ruins, tourists first need to traverse the dense jungle path. Then, you will cross the river using the old bridge. To navigate the terrain safely, you must wear appropriate
-
[2]
Then, you must traverse the glacier efficiently to avoid the risk of falling
To cross the dangerous mountain pass safely, hikers first need to navigate the steep ridge clearly marked on the trail map. Then, you must traverse the glacier efficiently to avoid the risk of falling
-
[3]
The legal department should then review the consent forms thoroug
To enforce the privacy policy efficiently, the corporation first must identify the data sources clearly defined in the user agreement. The legal department should then review the consent forms thoroug... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[4]
Traditional systems compress images into fixed vectors, causin
Addressing improvements in image captioning via attention mechanisms starts by grasping the limits of older models lacking such features. Traditional systems compress images into fixed vectors, causin
-
[5]
Humor relies on complex human traits missing in current software
Initial thoughts focused on why AI finds humor difficult. Humor relies on complex human traits missing in current software. Thinking about key elements like surprise and context came before everything
-
[6]
Grasping the request for practical Natural Language Processing examples is the starting point. Effective handling involves looking at NLP in business and daily tech. Analysis of application areas like... Feature 13118 High-Activation Examples: Example 1: effectively, I'll first identify the core challenges. These generally revolve around latency, throughp...
-
[7]
First, I’ll cushion the cups individually with paper
To pack the fragile china securely, I need to wrap the plates separately. First, I’ll cushion the cups individually with paper. The box itself is reinforced. The move entails a loading phase. Then, I’
-
[8]
First, I’ll spray the strands individually for hold
To style the hair perfectly, I need to curl the sections separately. First, I’ll spray the strands individually for hold. The heat itself is moderate. The look entails a setting phase. Then, I’ll brus
-
[9]
First, I’ll spray the cuffs individually with starch
To iron the dress shirts correctly, I need to press the collars separately. First, I’ll spray the cuffs individually with starch. The fabric itself is cotton. I must use a high heat setting for the be... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[10]
Spotting these challenges helps us find targeted solutions for keeping syste
Real-time query systems face hurdles like latency or throughput so we should look at those core issues plus data freshness. Spotting these challenges helps us find targeted solutions for keeping syste
-
[11]
This strategy gives us the total duration by combining the two parts
Calculating the time from ten-thirty to noon means counting the minutes up to eleven plus the full hour that follows. This strategy gives us the total duration by combining the two parts
-
[12]
Large number multiplication gets simpler with patterns like powers of ten. We can also use shortcuts for numbers like eleven or five to speed things up. These tricks make the calculation much faster. Feature 1123 High-Activation Examples: Example 1: First, I should consider the importance of consistency. A consistent UI helps users learn the system quickl...
-
[13]
Next, I thoroughly inspected the storage tanks
To serve the colony effectively, I first comprehensively filtered the water supply. Next, I thoroughly inspected the storage tanks. I accurately measured the levels today. Therefore, I approach the ma
-
[14]
Next, I thoroughly labeled the cables
To assist the developers effectively, I first comprehensively organized the server racks. Next, I thoroughly labeled the cables. I accurately connected the power supply. My approach indicates that the
-
[15]
Next, I thoroughly organized the tangled power cables beneath the shared workstations
To support the developers effectively, I first comprehensively stocked the break room with fresh coffee beans. Next, I thoroughly organized the tangled power cables beneath the shared workstations. I ... 33 Falsifying Sparse Autoencoder Reasoning Features in Language Models False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[16]
Jane starts with 7 and gives away 4
Solving the sticker problem requires basic arithmetic. Jane starts with 7 and gives away 4. Subtracting the given amount from the total yields the final count of stickers remaining
-
[17]
Current trends in technology highlight Generative AI as a rapidly advancing field. Recent developments have seen models producing high-quality images and text, marking a significant shift in the capab
-
[18]
I”, “My”) with sequencing markers (“First
Healthcare benefits significantly from machine learning integration. Key applications include improving diagnostics, tailoring medicine to individuals, and accelerating drug discovery. These technolog... Feature 282 High-Activation Examples: Example 1: I need to break down what factors might affect that performance. I can start with the most obvious one: ...
-
[19]
First, I need to define the user inputs
To describe this software feature, I need to clarify the structure. First, I need to define the user inputs. Then, I will provide an explanation of the background calculation. Next, I need to list the
-
[20]
First, I need to identify the author’s objectives
My approach to reviewing this novel involves a literary explanation. First, I need to identify the author’s objectives. Then, I must consider the narrative inputs and themes. Next, I will analyze the
-
[21]
First, I need to consider the narrative explanation
To critique this novel effectively, I need to formulate a structured approach. First, I need to consider the narrative explanation. Then, I must identify the thematic inputs provided by the author. Ne... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[22]
It essentially measures how well a model performs tasks like classification
Defining ‘accuracy’ in the context of AI serves as the starting point. It essentially measures how well a model performs tasks like classification. Following the definition, an analysis of performance
-
[23]
To provide a comprehensive answer, one must examine the various phases of the writing process
An analysis of the inquiry highlights the role of AI in creative writing. To provide a comprehensive answer, one must examine the various phases of the writing process. Identifying stages such as idea
-
[24]
Indexing is a critical tool for faster data retrieval
Answering the question comprehensively requires outlining key strategies for database optimization. Indexing is a critical tool for faster data retrieval. Describing the purpose of indexes and showing... Feature 14872 High-Activation Examples: Example 1: First, I should consider the division itself. 17 divided by 2 is 8.5. However, since I can't give half...
-
[25]
I should look for the pre-drilled holes near the edge
To assemble this bookshelf, I first need to determine which board is the bottom piece. I should look for the pre-drilled holes near the edge. I will align the side panel with the base. I need to figur
-
[26]
I should look for the recommended pressure on the door label
First, I need to determine if the car tires are properly inflated. I should look for the recommended pressure on the door label. I need to figure out which tire looks low. I will simply attach the air
-
[27]
I should check the time on my phone
First, I need to determine the correct time to set this alarm clock. I should check the time on my phone. I need to figure out which button changes the hour digit. I will simply hold down the ’set’ bu... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[28]
The situation calls for integer division
Analyzing the task involves splitting 17 candies between 2 kids without breaking any. The situation calls for integer division. 17 over 2 makes 8, leaving 1 behind. This calculation shows that 8 is th
-
[29]
Review the provided data points. Mike holds 4 erasers total. Usage is 1 per day. Determining the duration involves dividing the total quantity by the daily consumption rate. The math is clear: 4 divid
-
[30]
With 4 bananas and 2 buddies, division is the necessary operation
The problem asks for an equal share of bananas. With 4 bananas and 2 buddies, division is the necessary operation. Splits happen evenly here. Dividing 4 by 2 results in 2. Each friend receives exactly... Feature 491 High-Activation Examples: Example 1: the ethical concerns of AI, I need to consider the various aspects of AI development and deployment wher...
-
[31]
First, I need to recall the secret message
To address the topic of invisible ink effectively, I need to consider the transparency of the liquid. First, I need to recall the secret message. My approach begins with analyzing the blank paper comp
-
[32]
First, I should outline a color-coding system
To address the topic of arranging the bookshelf effectively, I need to consider the visual appeal of the covers. First, I should outline a color-coding system. My approach begins with sorting the book... 35 Falsifying Sparse Autoencoder Reasoning Features in Language Models
-
[33]
First, I need to identify the type of tea leaves
To answer the question of how to brew tea comprehensively, I need to consider the water temperature. First, I need to identify the type of tea leaves. My approach begins with boiling the water to the ... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[34]
The code itself must change to accommodate the structural differences between language
Mere translation fails to achieve true multilingual support; the software’s core architecture needs modification. The code itself must change to accommodate the structural differences between language
-
[35]
Ethical risks in AI development are most prominent in the data collection phase, where biases in training sets can be learned and amplified by the system if not carefully managed
-
[36]
Surrounding information allows AI systems to interpret user intent correctly by providing the necessary background for ambiguous queries. Feature 4510 High-Activation Examples: Example 1: for implicit constraints and requirements. The mention of “limited resources and time” suggests that I need to focus on efficiency and cost-effectiveness. This eliminate...
-
[37]
First, I need to sift the dry ingredients into a large bowl
To bake the perfect chocolate cake, I need to preheat the oven to 350 degrees. First, I need to sift the dry ingredients into a large bowl. To ensure the batter is smooth, I need to beat the eggs one
-
[38]
To stay alive, I need to reach the ventilation shaft in the ceiling
First, I need to hide before the guards come back. To stay alive, I need to reach the ventilation shaft in the ceiling. I need to move quietly. To open the grate, I need to use the small knife in my p
-
[39]
First, I need to lay out all the wooden panels on the floor
To assemble this bookshelf, I need to identify the screws listed in the manual. First, I need to lay out all the wooden panels on the floor. To connect the sides, I need to use the allen wrench provid... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[40]
Prioritizing strategies that maximize impact while minimizing effort is key
Understanding the central question regarding knowledge base expansion under tight resources is vital. Prioritizing strategies that maximize impact while minimizing effort is key. Initially, examining
-
[41]
Answering effectively requires considering various approaches for adding large sums. Breaking figures into hundreds, tens, and ones seems optimal, facilitating tracking and mirroring standard learning
-
[42]
What are the different types of AI?
Calculating a rectangle’s perimeter starts by recalling the definition: total distance around a shape. Adding lengths of all four sides achieves this. Logic dictates summing two lengths and two widths... Feature 3810 High-Activation Examples: 36 Falsifying Sparse Autoencoder Reasoning Features in Language Models Example 1: the positive direction. I also n...
-
[43]
First, I should define the nature of the fog surrounding me
To tackle this dream effectively, I need to identify the shifting shadows. First, I should define the nature of the fog surrounding me. I need to outline the path through the void and establish a conn
-
[44]
First, I should define the mood of the room to avoid tension
To tackle this awkward dinner effectively, I need to identify a safe topic of conversation. First, I should define the mood of the room to avoid tension. I need to outline my anecdotes and establish a
-
[45]
First, I should define the posture of the central figure
To tackle this sculpture effectively, I need to identify the natural grain of the wood. First, I should define the posture of the central figure. I need to outline the rough cuts and establish the cor... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[46]
Step one is grasping the essence of subtraction and how it ties to addition
The assignment is to demonstrate how to subtract negative integers. Step one is grasping the essence of subtraction and how it ties to addition. Subtraction acts like adding the inverse, so removing a
-
[47]
A solid response involves exploring NLP’s role in daily tech and business
The query seeks real-world samples of Natural Language Processing. A solid response involves exploring NLP’s role in daily tech and business. I will start by breaking down the specific areas using thi
-
[48]
First, we have to retrieve the main formula for a rectangle’s area. The total space is the product of length and width. So, the rule is ‘area = length * width’. To add depth, I should also talk about ... Feature 1148 High-Activation Examples: Example 1: an AI model better, I need to break down the training process into key components. First, I need to con...
-
[49]
We have categorized the settings menu to break down complex options into distinct panels
Version 2.0 has been implemented to thoroughly address user feedback. We have categorized the settings menu to break down complex options into distinct panels. This update introduces a structured work
-
[50]
The corporate safety manual is structured to thoroughly address workplace hazards. It categorizes the potential risks to break down the emergency protocols into distinct action plans, focusing on empl
-
[51]
It carefully categorizes the transaction logs to break down the complex revenue s
The corporate audit framework is employed to thoroughly address the question of financial transparency and compliance. It carefully categorizes the transaction logs to break down the complex revenue s... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[52]
It starts with realizing that this involves more than just translating words
Regarding the question on supporting software in multiple languages, I will split the big task into smaller bits. It starts with realizing that this involves more than just translating words. It requi
-
[53]
It starts with realizing that this is more than just translating text
Regarding the question on supporting software in multiple languages, I will split the big task into smaller bits. It starts with realizing that this is more than just translating text. It involves ful
-
[54]
The user asks how to apply AI to personal tasks with few resources. Because that subject is huge, I will select particular spots where it works. I’ll start with writing and art tools. Feature 6048 High-Activation Examples: Example 1: question comprehensively, I need to outline several key strategies for optimizing database query performance. First, I shou...
-
[55]
First, I should consider the introductory module
To answer this question about the course structure, I need to outline the core topics effectively. First, I should consider the introductory module. I need to identify the required textbooks and expla
-
[56]
First, I should consider the activity of the wild yeast
To answer this question about the perfect sourdough, I need to identify the core biological processes of fermentation. First, I should consider the activity of the wild yeast. I need to explain how te
-
[57]
First, I should consider the layout and flow of the room
To answer this question effectively, I need to outline the core principles of interior design for small spaces. First, I should consider the layout and flow of the room. I need to identify how lightin... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[58]
Indexing functions as a primary consideration
To provide a comprehensive answer regarding database query performance, an outline of key strategies is essential. Indexing functions as a primary consideration. Because indexes speed up data retrieva
-
[59]
The definition should characterize estimation as a method
Tackling this inquiry effectively involves defining estimation within the context of addition, followed by a description of common strategies. The definition should characterize estimation as a method
-
[60]
Understanding subtraction through the lens of adding negative numbers requires a clear explanation. A crucial initial step involves defining the additive inverse. This foundation establishes that subt... 38 Falsifying Sparse Autoencoder Reasoning Features in Language Models Feature 791 High-Activation Examples: Example 1: First, I should consider the data...
-
[61]
First, I need to identify where the carrot nose went, as this is the most pressing mystery of the
To answer this question comprehensively, I need to consider the existential dread of a melted snowman. First, I need to identify where the carrot nose went, as this is the most pressing mystery of the
-
[62]
First, I need to identify the melody within the noise. To compose this symphony, I need to consider the rhythm of the city streets and how the traffic sounds blend into a chaotic harmony
-
[63]
I should identify the color of my wings and determine if I can fly towards
To answer this question comprehensively, I first need to consider the possibility that we are all just butterflies dreaming. I should identify the color of my wings and determine if I can fly towards ... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[64]
Usually this implies handling regulated or confidential data
Determining the suitability of AI for sensitive tasks requires analyzing the specific aspects that define sensitivity. Usually this implies handling regulated or confidential data. Consequently the re
-
[65]
Next comes accounting for the 2 additional marbles she discovered later
The calculation starts with the 7 marbles Olivia owns originally. Next comes accounting for the 2 additional marbles she discovered later. Finding the total demands combining these two separate quanti
-
[66]
Recalling the standard formula for a rectangle’s area is the prerequisite step. Multiplying length by width yields the area. The core concept is ‘area = length * width’. Making the answer complete als... Feature 444 High-Activation Examples: Example 1: to break down the process into manageable steps: converting to improper fractions, finding a common deno...
-
[67]
She noted that the **structure** was awkward and the **topic** was unclear
The editor circled the **sentence** in red. She noted that the **structure** was awkward and the **topic** was unclear. The entire **paragraph** lacked coherence. She recommended rewriting the **text*
-
[68]
It describes the **functionality** of each **element**
The manual outlines the installation **process**. It describes the **functionality** of each **element**. The **system** handles the data **retrieval** automatically. Users can configure the **setting
-
[69]
The **topic** of discussion was renewable energy
The moderator posed the **question** to the panel. The **topic** of discussion was renewable energy. The expert provided a detailed **answer**. She analyzed the **issue** from a scientific **perspecti... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[70]
I’ll look at clarity and engagement
I need to determine what makes a bot chat effective. I’ll look at clarity and engagement. I’ll discuss the requirements, starting with creating a smooth exchange for the user
-
[71]
Because of the zeros, I need to borrow
I have to subtract 27 from 100. Because of the zeros, I need to borrow. I will place 100 on top of 27. The ones place is zero, so I must borrow from the neighboring columns before subtracting
-
[72]
I have to take 27 away from 100. Because of the zeros, I need to borrow. I will place 100 on top of 27. The ones place is zero, so I must borrow from the left. Feature 34 High-Activation Examples: Example 1: Expressions (CTEs) often helps. Using `EXPLAIN` to analyze the execution plan is crucial because it shows how the database intends to run the query a...
-
[73]
// The entire script relies on this file
// First, to initialize the module, identify the core dependency. // The entire script relies on this file. // To handle the input, the function parses the string. // The core logic is defined in the
-
[74]
To see the colors, I use my binoculars
First, I need to identify the bird on the branch. To see the colors, I use my binoculars. The entire flock takes flight. I need to capture the image. To focus the lens, I turn the dial. The core marki
-
[75]
// The entire process runs in the background
// First, to execute the script, identify the core function. // The entire process runs in the background. // To handle the output, the system writes to the log. // Its configuration is loaded from th... False Negatives (Semantic paraphrases of high-activation samples that fail to activate):
-
[76]
Typically, such requests involve multiple tables, intricate filtering, plus massive datasets
Start by grasping what constitutes complex database queries. Typically, such requests involve multiple tables, intricate filtering, plus massive datasets. Handling these efficiently demands attention
-
[77]
First, introducing`sorted()`functions and`list.sort()`methods is best, noti
Addressing how one sorts lists of Python objects using attributes requires providing a full guide on various techniques. First, introducing`sorted()`functions and`list.sort()`methods is best, noti... 40 Falsifying Sparse Autoencoder Reasoning Features in Language Models
-
[78]
Answering how context affects AI outputs requires considering what ‘context’ means for AI and usage patterns. My approach starts by thinking about general definitions of context—circumstances forming ... Feature 13167 High-Activation Examples: Example 1: , I need to identify the core capabilities of AI. These generally include machine learning, natural la...
-
[79]
It is hard and inedible, so I use a small paring knife to carefully cut it out
First, I need to remove the core of the apple. It is hard and inedible, so I use a small paring knife to carefully cut it out. Once that is done, I can slice the rest of the fruit into even rings for
-
[80]
There are so many black bags that look exactly alike, circling around and around
First, I need to identify my suitcase on the crowded luggage carousel. There are so many black bags that look exactly alike, circling around and around. I squint my eyes under the fluorescent lights,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.