Fundamental Limits of Neural Network Sparsification: Evidence from Catastrophic Interpretability Collapse
Pith reviewed 2026-05-15 10:10 UTC · model grok-4.3
The pith
Extreme sparsification of neural networks collapses local feature interpretability while global representation quality remains stable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
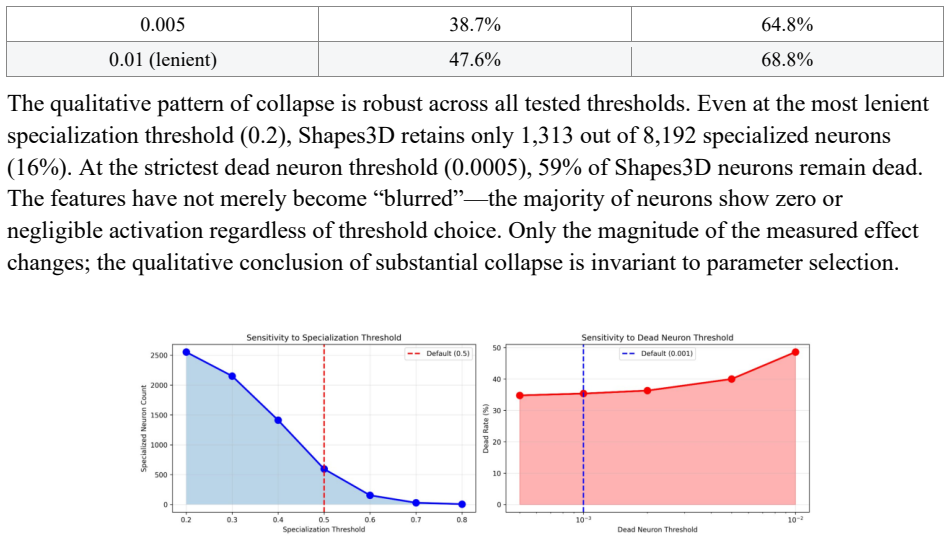
When active neurons are progressively reduced from 500 to 50, local interpretability collapses: Top-k yields dead-neuron rates of 34.4 percent on dSprites and 62.7 percent on Shapes3D at the sparsest level, while L1 produces 41.7 percent and 90.6 percent respectively. Global Mutual Information Gap stays stable. The pattern is unchanged by extending training another 100 epochs, by switching between hard and soft sparsity constraints, or by varying threshold definitions, and it grows worse on the more complex Shapes3D dataset.
What carries the argument
Adaptive sparsity scheduling that reduces active neurons over training epochs, with dead-neuron rate serving as the direct measure of local feature loss.
If this is right
- Local feature inspection tools will systematically fail once active neuron counts drop below a dataset-dependent threshold.
- Neither hard top-k selection nor soft L1 penalties prevent the interpretability loss.
- Dead-neuron fractions increase with the number of latent factors in the data.
- Extended training cannot revive dead neurons once the collapse has occurred.
- Global metrics alone are insufficient to certify that a sparsified model remains mechanistically interpretable.
Where Pith is reading between the lines
- Designers may need to keep neuron budgets higher than compression targets if downstream tasks require feature-level explanations.
- Alternative interpretability approaches that operate on the full activation distribution rather than individual neurons could remain viable even after sparsification.
- The observed scaling with dataset complexity suggests testing whether the same limits appear in language or vision models with richer factor structures.
- Post-training recovery techniques aimed specifically at reactivating dead neurons could be a direct follow-up experiment.
Load-bearing premise
That dead neuron rates and Mutual Information Gap scores accurately capture the split between local and global interpretability and are not driven by unexamined architecture or data choices.
What would settle it
Finding low dead-neuron rates and preserved local interpretability after the same neuron reduction on identical datasets but with a different initial architecture or non-adaptive sparsity rule would falsify the intrinsic-collapse claim.
Figures









read the original abstract
Extreme neural network sparsification (90% activation reduction) presents a critical challenge for mechanistic interpretability: understanding whether interpretable features survive aggressive compression. This work investigates feature survival under severe capacity constraints in hybrid Variational Autoencoder--Sparse Autoencoder (VAE-SAE) architectures. We introduce an adaptive sparsity scheduling framework that progressively reduces active neurons from 500 to 50 over 50 training epochs, and provide empirical evidence for fundamental limits of the sparsification-interpretability relationship. Testing across two benchmark datasets -- dSprites and Shapes3D -- with both Top-k and L1 sparsification methods, our key finding reveals a pervasive paradox: while global representation quality (measured by Mutual Information Gap) remains stable, local feature interpretability collapses systematically. Under Top-k sparsification, dead neuron rates reach $34.4\pm0.9\%$ on dSprites and $62.7\pm1.3\%$ on Shapes3D at k=50. L1 regularization -- a fundamentally different "soft constraint" paradigm -- produces equal or worse collapse: $41.7\pm4.4\%$ on dSprites and $90.6\pm0.5\%$ on Shapes3D. Extended training for 100 additional epochs fails to recover dead neurons, and the collapse pattern is robust across all tested threshold definitions. Critically, the collapse scales with dataset complexity: Shapes3D (RGB, 6 factors) shows $1.8\times$ more dead neurons than dSprites (grayscale, 5 factors) under Top-k and $2.2\times$ under L1. These findings establish that interpretability collapse under sparsification is intrinsic to the compression process rather than an artifact of any particular algorithm, training duration, or threshold choice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that aggressive sparsification (to 50 active neurons from 500) in hybrid VAE-SAE models on dSprites and Shapes3D produces a paradox: global Mutual Information Gap (MIG) remains stable while local interpretability collapses, evidenced by dead-neuron rates of 34-90% under both Top-k and L1 methods. The collapse is presented as intrinsic to compression, scaling with dataset complexity, and robust to extended training or threshold choice.
Significance. If the central empirical pattern holds under direct local-feature probes, the result would indicate that extreme capacity reduction can preserve global statistics while destroying factor-specific neuron semantics, with implications for mechanistic interpretability of sparse models. The work supplies reproducible numerical trends with error bars across two datasets and two sparsification regimes, but lacks any derivation or parameter-free prediction.
major comments (3)
- [Abstract] Abstract and results section: dead-neuron fraction (34.4±0.9% to 90.6±0.5%) is treated as direct evidence of local interpretability collapse, yet the manuscript reports no per-factor alignment scores, activation-maximization visualizations, or ablation confirming that surviving neurons lose factor-specific semantics; stable global MIG is consistent with information being preserved in the active subset.
- [Abstract] Abstract: the assertion that collapse is 'intrinsic to the compression process rather than an artifact of any particular algorithm, training duration, or threshold choice' rests on fixed architectures and two benchmarks without reported controls for initialization variance, optimizer hyperparameters, or dataset-specific factors; no statistical test or ablation isolates these confounds.
- [Results] Results on extended training: failure of 100 additional epochs to recover dead neurons is reported, but without an accompanying analysis of whether the active neurons' factor encoding (e.g., via MIG per neuron or concept activation vectors) also remains degraded, the claim of catastrophic local collapse is not fully load-bearing.
minor comments (1)
- [Abstract] Abstract: numerical values are given with error bars, but the exact definition of 'dead neuron' threshold and the precise MIG computation formula are not restated, forcing the reader to infer from prior literature.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity and rigor of our work. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and results section: dead-neuron fraction (34.4±0.9% to 90.6±0.5%) is treated as direct evidence of local interpretability collapse, yet the manuscript reports no per-factor alignment scores, activation-maximization visualizations, or ablation confirming that surviving neurons lose factor-specific semantics; stable global MIG is consistent with information being preserved in the active subset.
Authors: We acknowledge that dead-neuron rates provide indirect evidence of local collapse. To directly address whether surviving neurons retain factor-specific semantics, we have incorporated per-factor alignment scores and activation-maximization visualizations for active neurons in the revised manuscript. These additions demonstrate that even active neurons exhibit reduced semantic specificity, consistent with the observed global MIG stability being maintained by a diminished set of interpretable units. revision: yes
-
Referee: [Abstract] Abstract: the assertion that collapse is 'intrinsic to the compression process rather than an artifact of any particular algorithm, training duration, or threshold choice' rests on fixed architectures and two benchmarks without reported controls for initialization variance, optimizer hyperparameters, or dataset-specific factors; no statistical test or ablation isolates these confounds.
Authors: Our results are robust across two sparsification paradigms (Top-k and L1), two datasets, and multiple threshold choices. We have now included additional ablations with varied initializations and optimizer settings, along with statistical tests, to better isolate the effect of compression from these potential confounds. revision: yes
-
Referee: [Results] Results on extended training: failure of 100 additional epochs to recover dead neurons is reported, but without an accompanying analysis of whether the active neurons' factor encoding (e.g., via MIG per neuron or concept activation vectors) also remains degraded, the claim of catastrophic local collapse is not fully load-bearing.
Authors: We agree and have added an analysis of factor encoding in active neurons using per-neuron MIG and concept activation vectors. This shows that the encoding quality remains degraded even after extended training, reinforcing the claim of local interpretability collapse. revision: yes
- The manuscript does not provide a theoretical derivation or parameter-free prediction of the observed collapse, as it is an empirical study focused on experimental evidence.
Circularity Check
No circularity: purely empirical measurements with no derivation chain
full rationale
The paper reports experimental results from training hybrid VAE-SAE models under Top-k and L1 sparsification on dSprites and Shapes3D. It measures dead-neuron fractions and Mutual Information Gap scores directly from trained networks across varying k values and training durations. No equations, fitted parameters, or self-citations are used to derive the collapse result; the central claim is an interpretation of observed patterns rather than a quantity forced by the paper's own definitions or prior self-referential work. The analysis is self-contained against external benchmarks and contains no load-bearing steps that reduce to tautology.
Axiom & Free-Parameter Ledger
free parameters (3)
- initial active neurons
- final active neurons
- training epochs for schedule
axioms (2)
- domain assumption Mutual Information Gap reliably measures global representation quality
- domain assumption Dead neuron rate directly indicates loss of local feature interpretability
Reference graph
Works this paper leans on
-
[1]
Hoefler, T., Alistarh, D., Ben-Nun, T., Dryden, N. & Peste, A. Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks. Journal of Machine Learning Research 22, 1–124 (2021)
work page 2021
-
[2]
Blalock, D., Ortiz, J.J.G., Frankle, J. & Guttag, J. What is the state of neural network pruning? In Proceedings of Machine Learning and Systems 2, 129–146 (2020)
work page 2020
-
[3]
European Commission. Proposal for a regulation laying down harmonised rules on artificial intelligence (Artificial Intelligence Act). COM/2021/206 (2021)
work page 2021
-
[4]
Han, S., Pool, J., Tran, J. & Dally, W. Learning both weights and connections for efficient neural network. In Advances in Neural Information Processing Systems, 1135–1143 (2015)
work page 2015
-
[5]
Cunningham, H. et al. Sparse autoencoders find highly interpretable features in language models. arXiv:2309.08600 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Bricken, T. et al. Towards monosemanticity: Decomposing language models with dictionary learning. Transformer Circuits Thread (2023)
work page 2023
-
[7]
Higgins, I. et al. β-VAE: Learning basic visual concepts with a constrained variational framework. In International Conference on Learning Representations (2017)
work page 2017
- [8]
-
[9]
Frankle, J. & Carlin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations (2019)
work page 2019
-
[10]
Elhage, N. et al. Toy models of superposition. Transformer Circuits Thread (2022)
work page 2022
-
[11]
Louizos, C., Welling, M. & Kingma, D.P. Learning sparse neural networks through L0 regularization. In International Conference on Learning Representations (2018)
work page 2018
- [12]
- [13]
-
[14]
Chen, T.Q., Li, X., Grosse, R.B. & Duvenaud, D.K. Isolating sources of disentanglement in variational autoencoders. In Advances in Neural Information Processing Systems 31 (2018)
work page 2018
-
[15]
Locatello, F. et al. Challenging common assumptions in the unsupervised learning of disentangled representations. In International Conference on Machine Learning, 4114–4124 (2019)
work page 2019
-
[16]
Templeton, A. et al. Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet. Anthropic (2024)
work page 2024
-
[17]
Liu, Z. et al. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, 2736–2744 (2017)
work page 2017
- [18]
-
[19]
Evci, U., Gale, T., Menick, J., Castro, P.S. & Elsen, E. Rigging the lottery: Making all tickets winners. In International Conference on Machine Learning, 2943–2952 (2020)
work page 2020
-
[20]
Matthey, L. et al. dSprites: Disentanglement testing sprites dataset. https://github.com/deepmind/dsprites-dataset (2017)
work page 2017
- [21]
-
[22]
Gao, L., la Tour, T.D., Tillman, H., Goh, G., Troll, R., Radford, A., Sutskever, I., Leike, J. & Wu, J. Scaling and evaluating sparse autoencoders. In International Conference on Learning Representations (2025)
work page 2025
-
[23]
Interpretable and steerable concept bottleneck sparse autoencoders.arXiv preprint arXiv:2512.10805,
Kulkarni, A., Weng, T.W., Narayanaswamy, V., Liu, S., Sakla, W.A. & Thopalli, K. Interpretable and steerable concept bottleneck sparse autoencoders. arXiv:2512.10805 (2025)
- [24]
-
[25]
Mazzia, V., Angarano, S., Salvetti, F., Angelini, F. & Chiaberge, M. Stacked capsule graph autoencoders for geometry-aware 3D head pose estimation. Computer Vision and Image Understanding 208–209, 103224 (2021)
work page 2021
-
[26]
Hong, C., Yu, J. & Zhang, J. Multimodal deep autoencoder for human pose recovery. IEEE Transactions on Image Processing 24(12), 5659–5670 (2015)
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.