A deep learning framework for jointly solving transient Fokker-Planck equations with arbitrary parameters and initial distributions
Pith reviewed 2026-05-10 18:07 UTC · model grok-4.3
The pith
A single deep learning model solves transient Fokker-Planck equations for arbitrary initial distributions, parameters, and times after one training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
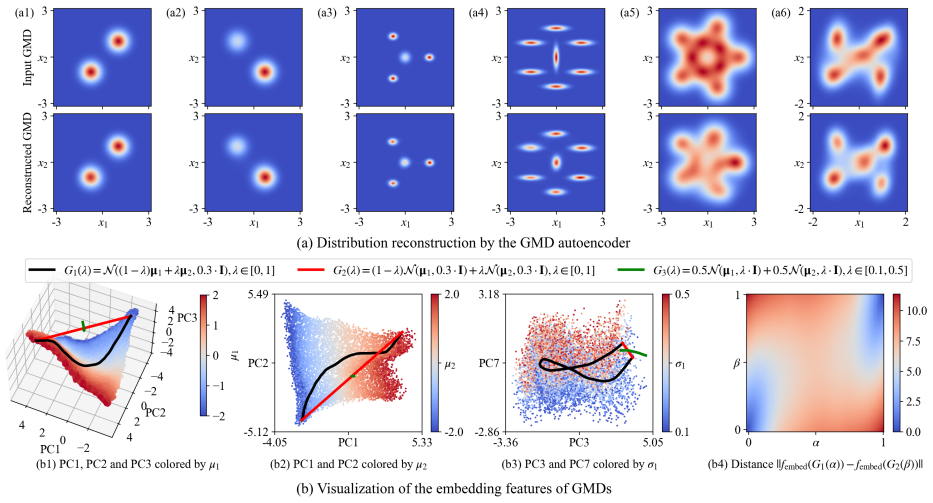
Via a single training process, the pseudo-analytical probability solution simultaneously resolves transient Fokker-Planck equation solutions for arbitrary multi-modal initial distributions, system parameters, and time points. The core idea is to unify initial, transient, and stationary distributions via Gaussian mixture distributions and develop a constraint-preserving autoencoder that bijectively maps constrained GMD parameters to unconstrained, low-dimensional latent representations. In this representation space, the panoramic transient dynamics across varying initial conditions and system parameters can be modeled by a single evolution network.
What carries the argument
The constraint-preserving autoencoder that bijectively maps constrained Gaussian mixture distribution parameters to unconstrained low-dimensional latent representations, allowing one evolution network to model all transient dynamics in a unified latent space.
If this is right
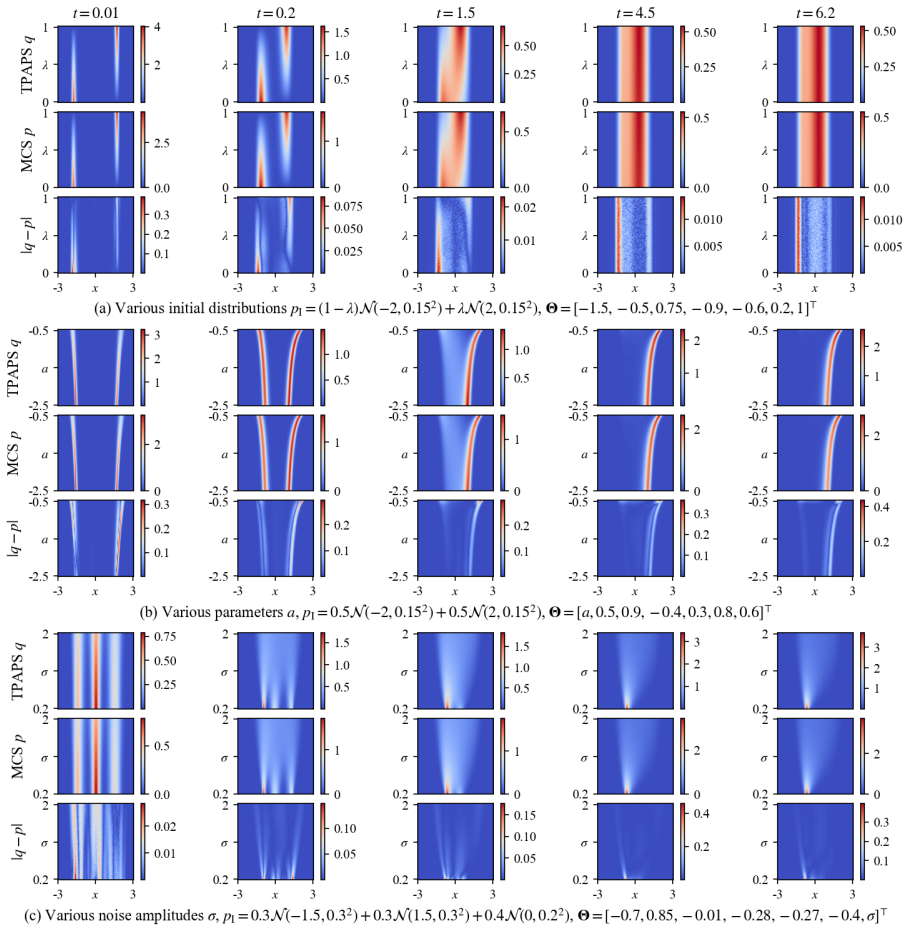
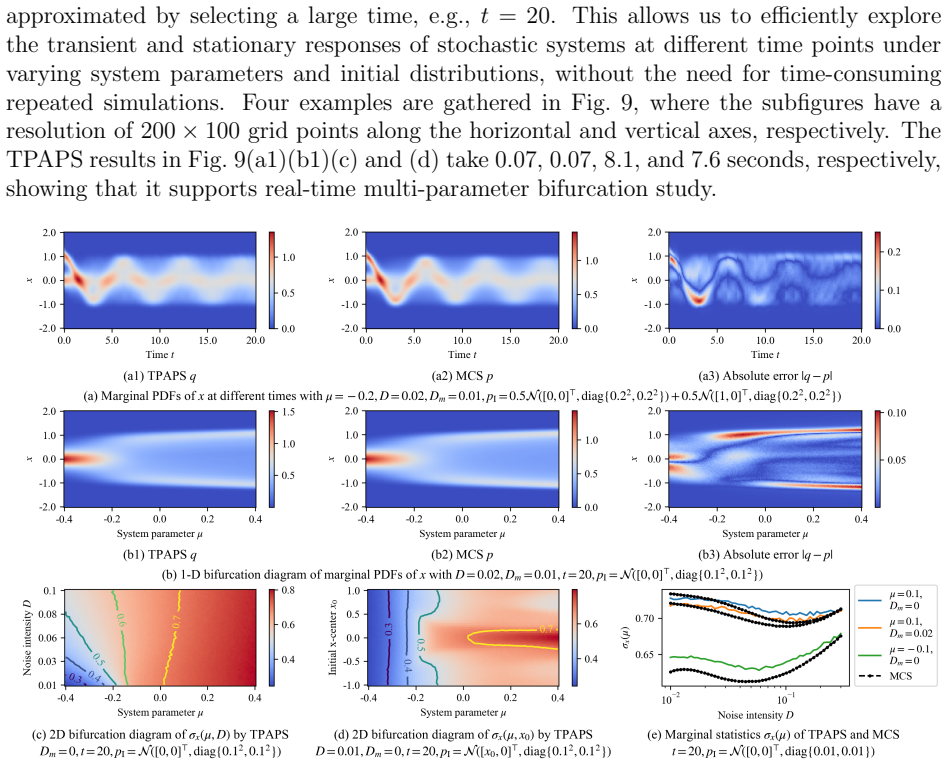
- The framework maintains high accuracy on paradigmatic systems while delivering inference speeds four orders of magnitude faster than GPU-accelerated Monte Carlo simulations.
- It enables real-time parameter sweeps and systematic investigations of stochastic bifurcations that were previously intractable.
- It creates a scalable route for probabilistic modeling of multi-dimensional parameterized stochastic systems by separating representation learning from the transient dynamics.
Where Pith is reading between the lines
- If the latent representation remains compact in higher dimensions, the same structure could be tested on stochastic systems with more variables such as those appearing in chemical reaction networks.
- The clean split between distribution encoding and dynamics learning might allow the evolution network to be trained on simulated data and then used for parameter recovery from measured distributions.
- Analogous autoencoder-plus-evolution pipelines could be applied to other time-dependent equations where the coefficients or source terms vary across runs.
Load-bearing premise
Gaussian mixture distributions plus the bijective autoencoder can faithfully represent every relevant initial, transient, and stationary distribution without loss of accuracy or failure outside the training cases.
What would settle it
Running the trained model on an initial distribution that cannot be well approximated by a small number of Gaussians or on a parameter value well outside the training range and finding large errors in the predicted probability densities would show the claim of arbitrary coverage is not holding.
Figures










read the original abstract
Efficiently solving the Fokker-Planck equation (FPE) is central to analyzing complex parameterized stochastic systems. However, current numerical methods lack parallel computation capabilities across varying conditions, severely limiting comprehensive parameter exploration and transient analysis. This paper introduces a deep learning-based pseudo-analytical probability solution (PAPS) that, via a single training process, simultaneously resolves transient FPE solutions for arbitrary multi-modal initial distributions, system parameters, and time points. The core idea is to unify initial, transient, and stationary distributions via Gaussian mixture distributions (GMDs) and develop a constraint-preserving autoencoder that bijectively maps constrained GMD parameters to unconstrained, low-dimensional latent representations. In this representation space, the panoramic transient dynamics across varying initial conditions and system parameters can be modeled by a single evolution network. Extensive experiments on paradigmatic systems demonstrate that the proposed PAPS maintains high accuracy while achieving inference speeds four orders of magnitude faster than GPU-accelerated Monte Carlo simulations. This efficiency leap enables previously intractable real-time parameter sweeps and systematic investigations of stochastic bifurcations. By decoupling representation learning from physics-informed transient dynamics, our work establishes a scalable paradigm for probabilistic modeling of multi-dimensional, parameterized stochastic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a deep learning framework (PAPS) for jointly solving transient Fokker-Planck equations across arbitrary parameters, multi-modal initial distributions, and time points. It unifies distributions via Gaussian mixture distributions (GMDs), employs a constraint-preserving autoencoder to obtain bijective low-dimensional latent representations, and trains a single evolution network to propagate the dynamics in latent space. Experiments on paradigmatic systems are reported to achieve high accuracy with inference speeds four orders of magnitude faster than GPU-accelerated Monte Carlo simulations.
Significance. If the representation and generalization claims hold, the work would enable previously intractable real-time parameter sweeps and systematic studies of stochastic bifurcations in multi-dimensional systems. The decoupling of representation learning from physics-informed dynamics modeling offers a scalable paradigm that could complement traditional numerical solvers for parameterized stochastic processes.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: the central claim of 'high accuracy' on paradigmatic systems with arbitrary distributions is not supported by quantitative error metrics (e.g., L2 or KL divergence values, maximum pointwise errors) or explicit validation protocols for post-training generalization outside the training distribution of GMD parameters and system parameters.
- [Methods (GMD unification and autoencoder)] Methods (GMD unification and autoencoder): the assumption that a fixed-cardinality Gaussian mixture family plus bijective latent mapping can faithfully represent the full manifold of initial, transient, and stationary densities is load-bearing for the 'arbitrary multi-modal initial distributions' claim, yet no error bounds, reconstruction-failure tests, or analysis for heavy tails, sharp peaks, or emergent modes beyond the chosen component count are provided.
- [Experiments] Experiments: details on the training data generation, the precise number of GMD components and latent dimension used, and how the evolution network was tested for simultaneous resolution across varying parameters and times are insufficient to evaluate whether the single-training-process unification actually generalizes without injected representation error.
minor comments (2)
- [Methods] Clarify the exact values chosen for the free parameters (number of Gaussian components, latent dimension) and any sensitivity analysis performed.
- [Experiments] Add explicit comparison tables or plots with quantitative differences (not just visual overlays) between PAPS solutions and reference Monte Carlo or finite-difference results.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas where additional quantitative support and methodological transparency can strengthen the manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claim of 'high accuracy' on paradigmatic systems with arbitrary distributions is not supported by quantitative error metrics (e.g., L2 or KL divergence values, maximum pointwise errors) or explicit validation protocols for post-training generalization outside the training distribution of GMD parameters and system parameters.
Authors: We agree that the current presentation relies primarily on visual comparisons and qualitative statements of accuracy. While the experiments section includes error visualizations for the reported paradigmatic systems, we did not tabulate aggregate quantitative metrics such as mean L2 norms or KL divergences across test cases, nor did we explicitly describe a held-out validation protocol for GMD parameters and system parameters outside the training ranges. We will add a dedicated subsection and table in the Experiments section reporting these metrics (L2, KL, and max pointwise errors) for both in-distribution and out-of-distribution test sets, along with the precise validation protocol used to assess generalization of the unified model. revision: yes
-
Referee: [Methods (GMD unification and autoencoder)] Methods (GMD unification and autoencoder): the assumption that a fixed-cardinality Gaussian mixture family plus bijective latent mapping can faithfully represent the full manifold of initial, transient, and stationary densities is load-bearing for the 'arbitrary multi-modal initial distributions' claim, yet no error bounds, reconstruction-failure tests, or analysis for heavy tails, sharp peaks, or emergent modes beyond the chosen component count are provided.
Authors: The referee correctly identifies that the fixed-cardinality GMD (5 components) and the bijective autoencoder are central to the unification claim. The manuscript does not supply reconstruction error bounds, systematic failure-case analysis, or explicit tests for heavy-tailed distributions, very sharp peaks, or modes that emerge beyond the chosen component count. We will expand the Methods section with a new paragraph and supplementary figures that report reconstruction errors (L2 and Wasserstein) on both training and held-out GMDs, include targeted tests for sharp-peak and heavy-tail cases, and discuss the practical limitations when the true density lies outside the span of the chosen GMD family. revision: yes
-
Referee: [Experiments] Experiments: details on the training data generation, the precise number of GMD components and latent dimension used, and how the evolution network was tested for simultaneous resolution across varying parameters and times are insufficient to evaluate whether the single-training-process unification actually generalizes without injected representation error.
Authors: We acknowledge that the current Experiments section is concise on these implementation details. The manuscript states the use of 5 GMD components and a latent dimension of 10, but does not fully specify the sampling ranges and generation procedure for the training GMD parameters, nor the exact protocol for testing the evolution network on simultaneous variations of initial distributions, system parameters, and time. We will revise the Experiments section to include: (i) explicit ranges and sampling strategy for means, covariances, and weights; (ii) the total number of training trajectories; and (iii) a clear description of the generalization test protocol, including how representation error is monitored and whether the evolution network was evaluated on parameter-time combinations never seen during training. revision: yes
Circularity Check
No circularity: learned surrogate trained on external data
full rationale
The paper describes a deep-learning surrogate (PAPS) that represents distributions as Gaussian mixtures, encodes them via a constraint-preserving autoencoder into latent space, and evolves the latent dynamics with a single network. This is a modeling and training procedure whose inputs are external simulation trajectories; the output is an approximation learned from those trajectories rather than a mathematical derivation that reduces to its own fitted parameters or self-citations by construction. No equations are presented that equate a claimed prediction to a fitted input, no uniqueness theorem is imported from prior self-work, and the GMD representation is an explicit representational ansatz whose adequacy is left to empirical validation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Number of Gaussian components in GMD
- Latent dimension of autoencoder
axioms (2)
- domain assumption Gaussian mixture distributions can represent initial, transient, and stationary solutions of the Fokker-Planck equation
- domain assumption The constraint-preserving autoencoder provides a bijective map between constrained GMD parameters and unconstrained latent space
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.