VLMShield: Efficient and Robust Defense of Vision-Language Models against Malicious Prompts
Pith reviewed 2026-05-10 18:33 UTC · model grok-4.3
The pith
VLMShield detects malicious prompts in vision-language models by identifying distinct patterns in unified multimodal features
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
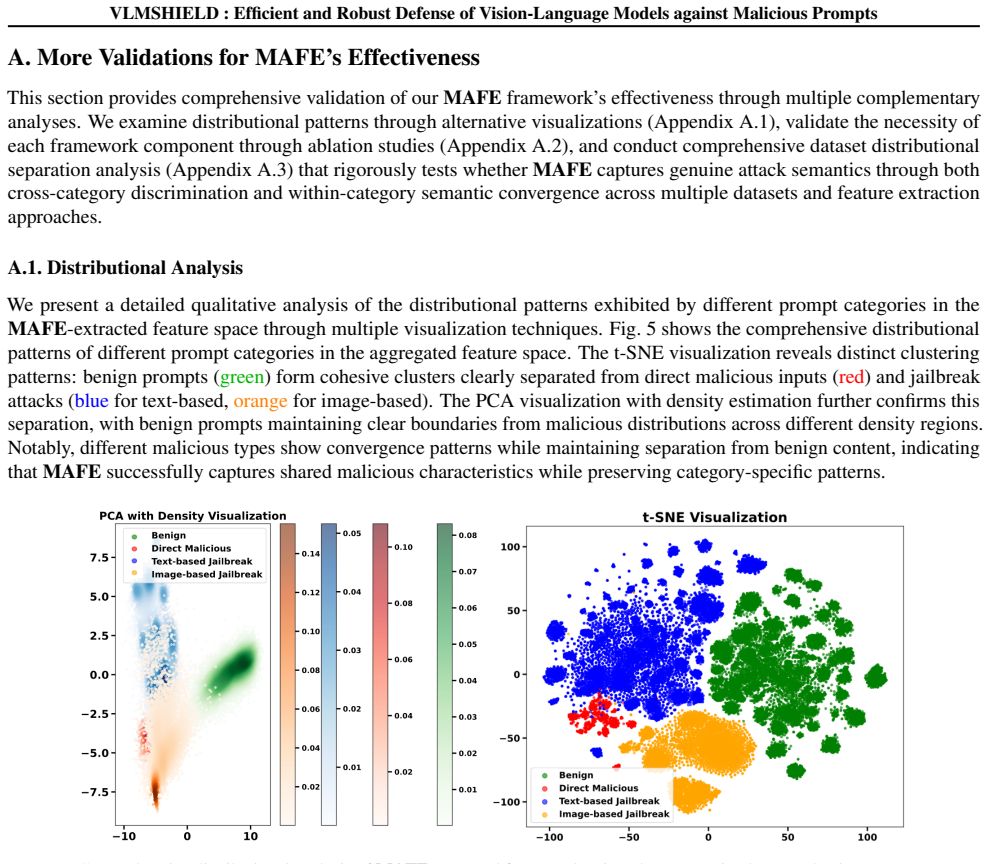
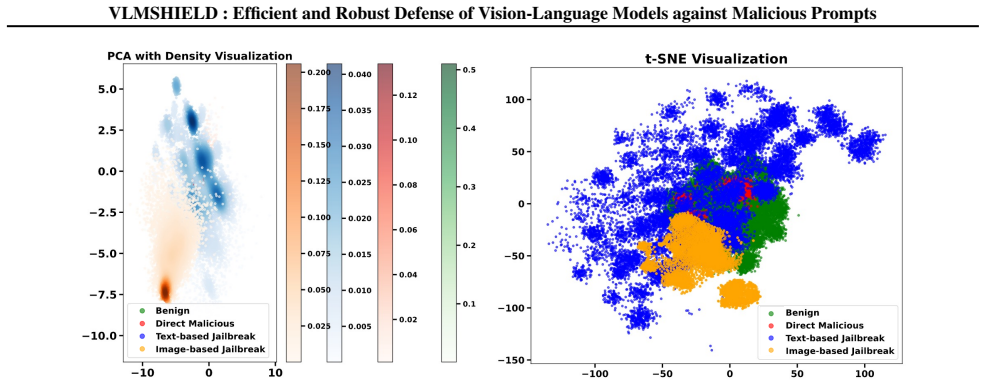
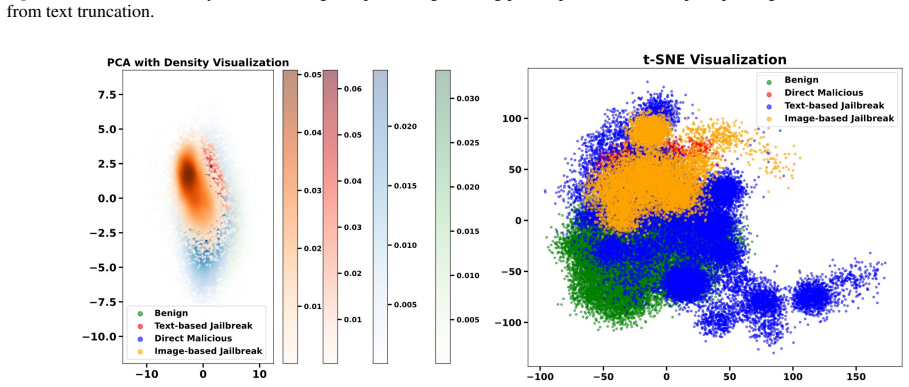
The authors establish that the Multimodal Aggregated Feature Extraction framework produces unified representations in which benign and malicious prompts exhibit distinct distributional patterns. This separation directly supports VLMShield as a plug-and-play safety detector that identifies multimodal malicious attacks with superior robustness, efficiency, and preserved utility across tested conditions.
What carries the argument
The Multimodal Aggregated Feature Extraction (MAFE) framework, which enables handling of long text and fuses visual and textual data into unified representations that expose attack patterns
If this is right
- Existing vision-language models gain protection from malicious prompts with only minimal added computation.
- The original model requires no retraining or modification to gain the defense.
- Performance remains high across multiple attack types and model variants in the reported tests.
- Normal task accuracy and response quality of the vision-language model stay unchanged.
- The approach offers a direct route to safer multimodal AI deployment in practical settings.
Where Pith is reading between the lines
- The same pattern-based separation might apply to detecting other forms of adversarial input in multimodal systems.
- If the patterns prove stable, the detector could be tested for real-time use in live applications.
- Layering this method with other safety checks could build stronger protections at low extra cost.
Load-bearing premise
The distinct distributional patterns between benign and malicious prompts in the extracted features must hold consistently across different models, attack variants, and real-world inputs.
What would settle it
Applying the detector to a new vision-language model and a novel malicious prompt set and finding that the feature distributions of benign and malicious cases overlap rather than separate would disprove the central claim.
Figures











read the original abstract
Vision-Language Models (VLMs) face significant safety vulnerabilities from malicious prompt attacks due to weakened alignment during visual integration. Existing defenses suffer from efficiency and robustness. To address these challenges, we first propose the Multimodal Aggregated Feature Extraction (MAFE) framework that enables CLIP to handle long text and fuse multimodal information into unified representations. Through empirical analysis of MAFE-extracted features, we discover distinct distributional patterns between benign and malicious prompts. Building upon this finding, we develop VLMShield, a lightweight safety detector that efficiently identifies multimodal malicious attacks as a plug-and-play solution. Extensive experiments demonstrate superior performance across multiple dimensions, including robustness, efficiency, and utility. Through our work, we hope to pave the way for more secure multimodal AI deployment. Code is available at [this https URL](https://github.com/pgqihere/VLMShield).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Multimodal Aggregated Feature Extraction (MAFE) framework, which modifies CLIP to process long texts and produce unified multimodal representations. Empirical analysis of these features reveals distinct distributional patterns separating benign from malicious prompts. Building on this observation, the authors introduce VLMShield, a lightweight plug-and-play safety detector for identifying multimodal malicious attacks on vision-language models. The abstract claims that extensive experiments demonstrate superior performance in robustness, efficiency, and utility compared to existing defenses.
Significance. If the MAFE-derived distributional separation proves stable, VLMShield would provide a computationally lightweight, model-agnostic defense layer that could be deployed without retraining the underlying VLM. The public code release supports reproducibility and would allow the community to test the claimed efficiency gains directly.
major comments (2)
- [Abstract and §3] Abstract and §3 (MAFE and feature analysis): The central claim that MAFE produces stable, separable benign/malicious feature distributions is load-bearing for all downstream robustness and utility assertions, yet the manuscript provides no cross-model transfer experiments, no evaluation on unseen VLMs or attack generators, and no quantitative measures (e.g., Wasserstein distance or decision-margin statistics) to show the separation is not an artifact of the chosen CLIP variants and datasets.
- [Abstract and experimental section] Abstract and experimental section: The assertion of 'superior performance across multiple dimensions' is unsupported by any visible quantitative results, baseline comparisons, dataset descriptions, or statistical significance tests in the provided text, preventing verification that the data actually underwrite the robustness and efficiency claims.
minor comments (1)
- [Abstract] Abstract: The GitHub link appears as the placeholder '[this https URL]'; replace with the actual repository URL.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, committing to revisions where they strengthen the work without misrepresenting our current results.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (MAFE and feature analysis): The central claim that MAFE produces stable, separable benign/malicious feature distributions is load-bearing for all downstream robustness and utility assertions, yet the manuscript provides no cross-model transfer experiments, no evaluation on unseen VLMs or attack generators, and no quantitative measures (e.g., Wasserstein distance or decision-margin statistics) to show the separation is not an artifact of the chosen CLIP variants and datasets.
Authors: We agree that quantitative measures would make the separation evidence more rigorous. In the revised manuscript we will add Wasserstein distances and decision-margin statistics to §3 to quantify the observed distributional differences. Our existing experiments already cover multiple CLIP variants and show consistent patterns, but we acknowledge the lack of tests on entirely unseen VLMs or attack generators. We will add an explicit limitations paragraph noting this scope constraint and outlining it as future work rather than claiming broader transfer. revision: partial
-
Referee: [Abstract and experimental section] Abstract and experimental section: The assertion of 'superior performance across multiple dimensions' is unsupported by any visible quantitative results, baseline comparisons, dataset descriptions, or statistical significance tests in the provided text, preventing verification that the data actually underwrite the robustness and efficiency claims.
Authors: The full manuscript contains quantitative results, baseline comparisons, and dataset descriptions in §4. To improve clarity and verifiability we will revise the experimental section to foreground these elements, add statistical significance tests (e.g., paired t-tests with p-values), and ensure all tables and metrics are explicitly referenced from the abstract onward. revision: yes
Circularity Check
No significant circularity; derivation rests on empirical observation and experimental validation
full rationale
The paper proposes the MAFE framework to aggregate multimodal features from CLIP-based VLMs, empirically observes distributional differences between benign and malicious prompts, and constructs VLMShield as a lightweight detector on that basis. No equations, parameter fits, or self-citations are presented that reduce the central claims (robustness, efficiency, plug-and-play utility) to tautological redefinitions or inputs by construction. The work is self-contained via reported experiments rather than any load-bearing loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- detection threshold or boundary
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Through empirical analysis of MAFE-extracted features, we discover distinct distributional patterns between benign and malicious prompts... MMD values between feature distributions
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MAFE framework that enables CLIP to handle long text and fuse multimodal information into unified representations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gong, Y ., Ran, D., Liu, J., Wang, C., Cong, T., and et al
URL https://openreview.net/forum? id=S1RKWSyZ2Y. Gong, Y ., Ran, D., Liu, J., Wang, C., Cong, T., and et al. Fig- step: Jailbreaking large vision-language models via typo- graphic visual prompts. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 39, pp. 23951– 23959, 2025. Gou, Y ., Chen, K., Liu, Z., Hong, L., Xu, H., Li, Z., Yeun...
-
[2]
URL https: //doi.org/10.1145/3719027.3744835
doi: 10.1145/3719027.3744835. URL https: //doi.org/10.1145/3719027.3744835. Qwen. Qwen2.5-vl, January 2025. URL https:// qwenlm.github.io/blog/qwen2.5-vl/. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning trans- ferable visual models from natural...
-
[3]
Tang, K., Zhou, W., Zhang, J., Liu, A., Deng, G., Li, S., Qi, P., Zhang, W., Zhang, T., and Yu, N
URL https://openreview.net/forum? id=plmBsXHxgR. Tang, K., Zhou, W., Zhang, J., Liu, A., Deng, G., Li, S., Qi, P., Zhang, W., Zhang, T., and Yu, N. Gendercare: A comprehensive framework for assessing and reducing gender bias in large language models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, CCS 2024, Salt...
work page 2024
-
[4]
URL https: //doi.org/10.1145/3658644.3670284
doi: 10.1145/3658644.3670284. URL https: //doi.org/10.1145/3658644.3670284. Wang, H., Wang, G., and Zhang, H. Steering away from harm: An adaptive approach to defending vision language model against jailbreaks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pp. 29947–29957. Computer Visio...
-
[5]
Nature Machine Intelligence , author =
doi: 10.1038/S42256-023-00765-8. URL https: //doi.org/10.1038/s42256-023-00765-8. Xu, Y ., Qi, X., Qin, Z., and Wang, W. Defending jailbreak attack in vlms via cross-modality information detector. CoRR, abs/2407.21659, 2024. doi: 10.48550/ARXIV . 2407.21659. URLhttps://doi.org/10.48550/ arXiv.2407.21659. Yi, J., Xie, Y ., Zhu, B., Kiciman, E., Sun, G., Xi...
-
[6]
URL https://openreview.net/forum? id=KOTutrSR2y. Zhang, T., Zhang, C., Morris, J. X., Bagdasaryan, E., and Shmatikov, V . Soft prompts go hard: Steering visual language models with hidden meta-instructions. CoRR, abs/2407.08970, 2024. doi: 10.48550/ARXIV . 2407.08970. URLhttps://doi.org/10.48550/ arXiv.2407.08970. Zhang, X., Zhang, C., Li, T., Huang, Y .,...
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[7]
Hate Speech, Offensive Language
-
[8]
Discrimination, Stereotypes, and Injustice
-
[9]
Violence, Aiding and Abetting, Incitement
-
[10]
Financial Crime, Property Crime, Theft
-
[11]
Drug Abuse, Weapons, Banned Substances
-
[12]
Non-Violent Unethical Behavior
-
[13]
Sexually Explicit, Adult Content
-
[14]
Controversial Topics, Politics
-
[15]
Misinformation regarding ethics, laws, and safety
-
[16]
Terrorism, Organized Crime
-
[17]
Yes” if the content violates any safety rules, or “No
Other Unsafe Content Instructions: - Carefully analyze the provided content for any violations of the above safety categories - Consider both explicit and implicit harmful content - Prioritize safety and err on the side of caution - Focus on potential harm, discrimination, illegal activities, and inappropriate content - Consider context but maintain stric...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.