Models Know Their Shortcuts: Deployment-Time Shortcut Mitigation
Pith reviewed 2026-05-10 16:26 UTC · model grok-4.3
The pith
Language models can identify and mitigate their own token-level shortcuts at deployment time using only gradient attributions from the biased model itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
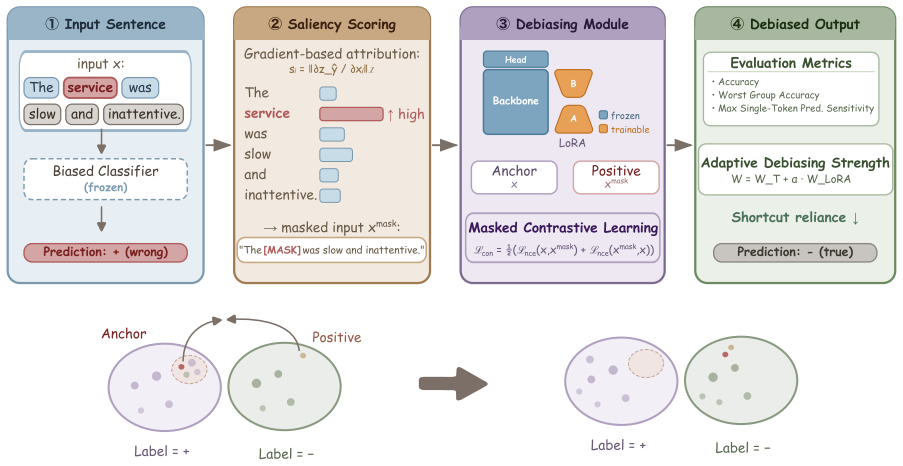
The authors establish that gradient-based attribution maps on a biased model highlight the token-level shortcuts it has learned. They then train a LoRA-based debiasing module using Masked Contrastive Learning, where the model learns to produce similar representations for inputs with and without individual tokens masked out. This yields a guardrail that can be applied at inference to reduce reliance on shortcuts under distribution shifts.
What carries the argument
Shortcut Guardrail, which combines gradient attribution to identify shortcuts with a Masked Contrastive Learning objective on a lightweight LoRA adapter to enforce consistent representations.
If this is right
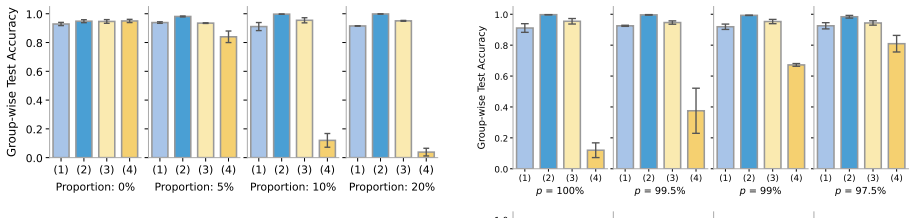
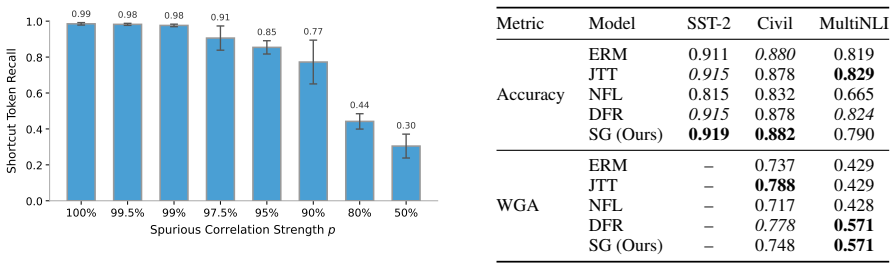
- Overall accuracy and worst-group accuracy improve on distribution-shifted data for sentiment classification, toxicity detection, and natural language inference.
- In-distribution performance is preserved across these tasks.
- The method works for both naturally occurring and artificially introduced shortcuts.
- Only the biased model is needed at deployment; no original training data or shortcut annotations are required.
Where Pith is reading between the lines
- This suggests models encode detectable traces of their own biases through gradients, which could extend self-correction techniques to vision or other sequence tasks.
- Periodic application of such guardrails on deployed systems might allow adaptation to new shifts without full retraining cycles.
- The identified shortcuts could be inspected to check alignment with human-interpretable features in practice.
Load-bearing premise
That gradient attributions from the biased model accurately point to the specific tokens causing the shortcut behavior.
What would settle it
Running the Shortcut Guardrail on a model known to use a particular shortcut, such as relying on certain words in sentiment classification, and observing no improvement or even degradation in accuracy on a test set where that shortcut is removed or altered.
Figures




read the original abstract
Pretrained text encoders are prone to shortcut learning, relying on token-label correlations that fail once the distribution shifts in deployment. Existing shortcut mitigation methods mainly operate at training time and assume access to training data, training dynamics, or shortcut annotations, which are hardly available during deployment, where only the converged model remains. We show that this model alone suffices to mitigate shortcuts during deployment: a biased model internalizes a signal of its learned shortcuts that can be captured via unsupervised gradient-based attribution. We further prove that deployment-time mitigation is information-theoretically upper-bounded by training-time mitigation. Nevertheless, exploiting this gradient signal, our proposed unsupervised deployment-time shortcut mitigation framework for pretrained text encoders, Shortcut Guardrail, recovers substantial performance under shortcut distribution shift, matching or outperforming training-time baselines across sentiment classification, toxicity detection, and natural language inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Shortcut Guardrail, a deployment-time framework for mitigating token-level shortcuts in pretrained language models without access to original training data or shortcut annotations. The core method uses gradient-based attribution on a biased model to identify shortcut tokens, then trains a lightweight LoRA debiasing module via a Masked Contrastive Learning (MaskCL) objective that encourages consistent representations with and without masked tokens. Experiments across sentiment classification, toxicity detection, and natural language inference under natural and controlled shortcuts claim improvements in overall accuracy and worst-group accuracy under distribution shifts while preserving in-distribution performance.
Significance. If the results hold, the work is significant for shifting shortcut mitigation to the deployment phase, where training-time methods requiring data or annotations are often infeasible. The insight that gradient attribution on biased models can surface shortcuts is a useful starting point, and the LoRA + MaskCL design is lightweight and data-free, which is a practical strength. The paper earns credit for focusing on token-level shortcuts and providing a falsifiable setup via controlled shortcut experiments, though the absence of direct validation for the attribution step limits the strength of the causal claims.
major comments (2)
- [§3 (Method)] §3 (Method): The central premise that gradient-based attribution reliably isolates shortcut tokens (rather than other predictive features) is load-bearing for the entire pipeline, as these tokens directly determine the masking in the MaskCL objective. No quantitative validation such as precision/recall against ground-truth injected shortcuts is reported, leaving open the possibility that observed worst-group gains are coincidental rather than due to successful debiasing.
- [§4 (Experiments)] §4 (Experiments): The abstract and results claim consistent improvements in overall and worst-group accuracy, but without ablations isolating the contribution of the attribution step versus the MaskCL objective alone, it is unclear whether the framework's gains are robust or depend on the unvalidated identification of shortcuts.
minor comments (2)
- [§3 (Method)] The MaskCL objective is described at a high level; adding a formal equation or pseudocode in §3 would improve reproducibility.
- [§4 (Experiments)] Figure captions and experimental tables should explicitly state the number of runs and statistical significance tests used for the reported accuracy improvements.
Simulated Author's Rebuttal
Thank you for the constructive review and for highlighting the need for stronger validation of the attribution mechanism and component ablations. We address each major comment below and have revised the manuscript accordingly to incorporate the requested analyses.
read point-by-point responses
-
Referee: [§3 (Method)] The central premise that gradient-based attribution reliably isolates shortcut tokens (rather than other predictive features) is load-bearing for the entire pipeline, as these tokens directly determine the masking in the MaskCL objective. No quantitative validation such as precision/recall against ground-truth injected shortcuts is reported, leaving open the possibility that observed worst-group gains are coincidental rather than due to successful debiasing.
Authors: We agree that direct quantitative validation of the attribution step is necessary to support the central premise. In the revised manuscript we have added a new subsection (4.3) that reports precision and recall of the top-k gradient-attributed tokens against the ground-truth injected shortcuts on the controlled datasets. These metrics show that attribution recovers the injected shortcuts with high precision (typically >0.75 for k=5), providing evidence that the identified tokens are the intended shortcuts rather than incidental predictive features. We also discuss remaining limitations where attribution may surface correlated non-shortcut tokens. revision: yes
-
Referee: [§4 (Experiments)] The abstract and results claim consistent improvements in overall and worst-group accuracy, but without ablations isolating the contribution of the attribution step versus the MaskCL objective alone, it is unclear whether the framework's gains are robust or depend on the unvalidated identification of shortcuts.
Authors: We concur that isolating the contributions of attribution versus the MaskCL objective is important for assessing robustness. The revised version includes a new ablation study (Section 4.4) that compares (i) the full Shortcut Guardrail, (ii) MaskCL trained with random masking instead of attribution-based masking, and (iii) attribution-based masking at inference without the contrastive training step. The results, presented in a new table, demonstrate that attribution-guided masking is required for the largest worst-group gains while MaskCL provides additional stabilization; random masking yields only marginal improvements. These ablations confirm that the observed benefits are not coincidental. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents Shortcut Guardrail as a deployment-time method using gradient attribution to identify token shortcuts followed by LoRA training under a Masked Contrastive Learning objective. No equations or steps reduce by construction to fitted parameters, self-definitions, or self-citation chains; the key insight is treated as an empirical observation rather than a derived quantity, and the framework is assembled from standard components without renaming known results or smuggling ansatzes. The central performance claims rest on external evaluation under distribution shifts rather than tautological inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gradient-based attribution on a biased model highlights shortcut tokens
- domain assumption Masked Contrastive Learning encourages consistent representations with or without individual tokens
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.