Recognition: unknown
When Missing Becomes Structure: Intent-Preserving Policy Completion from Financial KOL Discourse
Pith reviewed 2026-05-10 13:32 UTC · model grok-4.3
The pith
KOL social media statements can be completed into executable trading policies by using offline RL to fill execution gaps while preserving original directional intent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
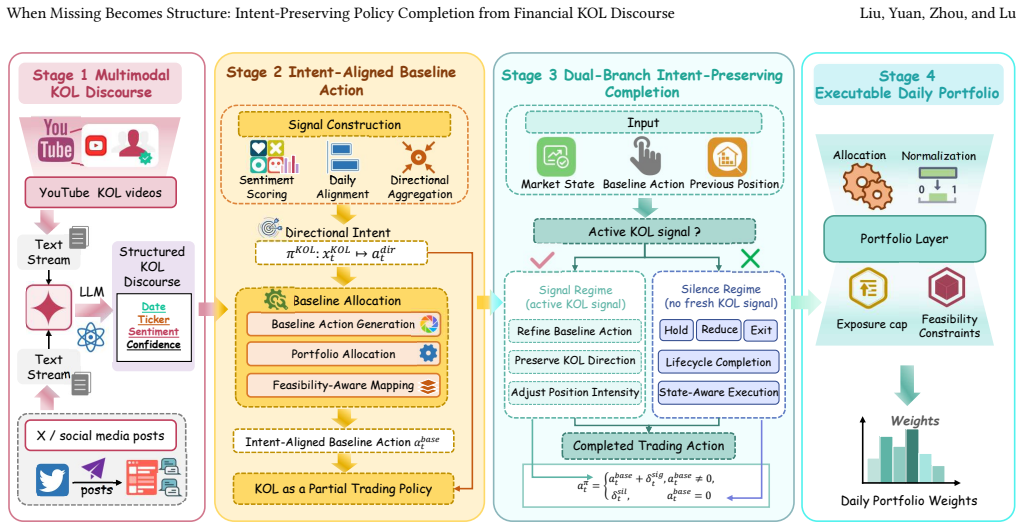
We propose an intent-preserving policy completion framework that treats KOL discourse as a partial trading policy and uses offline reinforcement learning to complete the missing execution decisions around the KOL-expressed intent. Experiments on multimodal KOL discourse from YouTube and X (2022-2025) show that KICL achieves the best return and Sharpe ratio on both platforms while maintaining zero unsupported entries and zero directional reversals, and ablations confirm that the full framework yields an 18.9% return improvement over the KOL-aligned baseline.
What carries the argument
Intent-preserving policy completion via offline reinforcement learning that fixes directional intent from KOL statements and learns only the execution parameters.
If this is right
- Strategies derived this way outperform both naive use of KOL posts and baselines that ignore the structured-gap assumption.
- Zero unsupported entries and zero directional reversals hold across both YouTube and X data sources.
- Ablation studies isolate the full framework as responsible for the measured 18.9 percent return gain.
- The same completion process works on multimodal inputs without requiring additional human-specified rules.
Where Pith is reading between the lines
- The same separation of intent from execution may appear in other expert domains where advice is consumed publicly, such as medical or policy recommendations.
- If the structured-gap premise generalizes, platforms could embed automated completion layers to convert influencer statements into immediately actionable signals.
- Real-time versions would require only that the offline RL component be replaced by a fast inference model trained on historical completions.
Load-bearing premise
The gaps in KOL statements follow a consistent structure where directional intent is always supplied and execution details are always left unspecified.
What would settle it
New KOL statements in which execution details appear randomly distributed rather than systematically omitted, or where the completed policies produce directional reversals or unsupported entries on held-out data, would falsify the claim.
Figures





read the original abstract
Key Opinion Leader (KOL) discourse on social media is widely consumed as investment guidance, yet turning it into executable trading strategies without injecting assumptions about unspecified execution decisions remains an open problem. We observe that the gaps in KOL statements are not random deficiencies but a structured separation: KOLs express directional intent (what to buy or sell and why) while leaving execution decisions (when, how much, how long) systematically unspecified. Building on this observation, we propose an intent-preserving policy completion framework that treats KOL discourse as a partial trading policy and uses offline reinforcement learning to complete the missing execution decisions around the KOL-expressed intent. Experiments on multimodal KOL discourse from YouTube and X (2022-2025) show that KICL achieves the best return and Sharpe ratio on both platforms while maintaining zero unsupported entries and zero directional reversals, and ablations confirm that the full framework yields an 18.9% return improvement over the KOL-aligned baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes KICL, an intent-preserving policy completion framework that models KOL discourse from YouTube and X as partial trading policies. It observes that gaps in such discourse are structured (directional intent is expressed while execution details like timing, size, and duration are left unspecified) and uses offline reinforcement learning to complete the missing execution components without violating the expressed intent. Experiments on multimodal data (2022-2025) report that KICL achieves the highest returns and Sharpe ratios on both platforms, with zero unsupported entries and zero directional reversals, plus an 18.9% return improvement over the KOL-aligned baseline in ablations.
Significance. If the empirical results hold under scrutiny, the work provides a principled approach to converting qualitative social-media signals into executable strategies in finance, addressing a practical gap in offline RL and policy learning from partial information. The emphasis on strict intent preservation and the reported constraint-satisfaction metrics (zero violations) could influence downstream applications in algorithmic trading and signal processing from unstructured sources.
major comments (2)
- [Methods / Experimental Evaluation] The central claim of zero unsupported entries and zero directional reversals depends on a precise operational definition of these terms and how they are measured against the original KOL statements; this definition is referenced in the abstract and results but requires an explicit algorithm or criterion in the methods section to support reproducibility and the zero-violation guarantee.
- [Ablation Studies] The 18.9% return improvement from the full framework is a key ablation result, but the paper must detail the exact ablated components, the KOL-aligned baseline construction, and include statistical significance (e.g., confidence intervals or p-values) to establish that the gain is attributable to the intent-preserving completion rather than other modeling choices.
minor comments (2)
- [Introduction] The acronym KICL should be expanded on first use in the introduction for clarity, even if defined later.
- [Results] Figures comparing returns and Sharpe ratios across platforms should include error bars or variance measures to aid interpretation of the performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that greater explicitness in the methods and ablation sections will strengthen reproducibility and interpretability. We address each major comment below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Methods / Experimental Evaluation] The central claim of zero unsupported entries and zero directional reversals depends on a precise operational definition of these terms and how they are measured against the original KOL statements; this definition is referenced in the abstract and results but requires an explicit algorithm or criterion in the methods section to support reproducibility and the zero-violation guarantee.
Authors: We agree that an explicit operational definition and measurement algorithm are necessary for full reproducibility. In the revised manuscript we will add a new subsection (Section 3.4) that formally defines (i) an unsupported entry as any executed trade whose direction, asset, or position size contradicts or extends beyond the directional intent explicitly stated in the KOL discourse, and (ii) a directional reversal as any change in buy/sell orientation relative to the KOL’s expressed intent. We will also include the precise decision procedure and pseudocode used to compare completed policies against the original statements, thereby making the reported zero-violation results directly verifiable. revision: yes
-
Referee: [Ablation Studies] The 18.9% return improvement from the full framework is a key ablation result, but the paper must detail the exact ablated components, the KOL-aligned baseline construction, and include statistical significance (e.g., confidence intervals or p-values) to establish that the gain is attributable to the intent-preserving completion rather than other modeling choices.
Authors: We accept that additional detail and statistical support are required. In the revision we will expand the ablation section to enumerate every ablated component (intent-preservation module, offline RL completion step, multimodal encoder, etc.), provide a step-by-step description of how the KOL-aligned baseline is constructed (i.e., executing only the explicitly stated portions of each KOL statement without any learned completion), and report 95% bootstrapped confidence intervals together with paired t-test p-values computed across the 2022–2025 test periods. These additions will isolate the contribution of the intent-preserving completion to the observed performance gain. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical framework that starts from an observational claim about structured gaps in KOL discourse (directional intent vs. unspecified execution) and applies offline RL to complete policies while preserving intent. Reported outcomes—superior returns/Sharpe ratios, zero unsupported entries, zero directional reversals, and 18.9% ablation gain—are framed as results from experiments on external multimodal data (YouTube/X 2022-2025), not as quantities derived by algebraic equivalence or parameter fitting that collapses back to the initial observation. No equations, self-citations, or uniqueness theorems appear in the provided text that would force the results by construction. The derivation chain therefore remains self-contained against external benchmarks and data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption KOL discourse exhibits a structured separation between directional intent and execution decisions.
Reference graph
Works this paper leans on
-
[1]
Werner Antweiler and Murray Z Frank. 2004. Is all that talk just noise? The information content of internet stock message boards.The Journal of finance59, 3 (2004), 1259–1294
2004
-
[2]
Michael Bain and Claude Sammut. 1995. A Framework for Behavioural Cloning.. InMachine intelligence 15. 103–129
1995
-
[3]
Brad Barber, Reuven Lehavy, Maureen McNichols, and Brett Trueman. 2001. Can investors profit from the prophets? Security analyst recommendations and stock returns.The Journal of finance56, 2 (2001), 531–563
2001
-
[4]
Johan Bollen, Huina Mao, and Xiaojun Zeng. 2011. Twitter mood predicts the stock market.Journal of computational science2, 1 (2011), 1–8
2011
-
[5]
Hailiang Chen, Prabuddha De, Yu Hu, and Byoung-Hyoun Hwang. 2014. Wisdom of crowds: The value of stock opinions transmitted through social media.The review of financial studies27, 5 (2014), 1367–1403. When Missing Becomes Structure: Intent-Preserving Policy Completion from Financial KOL Discourse Liu, Yuan, Zhou, and Lu
2014
-
[6]
Yue Deng, Feng Bao, Youyong Kong, Zhiquan Ren, and Qionghai Dai. 2016. Deep direct reinforcement learning for financial signal representation and trading. IEEE transactions on neural networks and learning systems28, 3 (2016), 653–664
2016
-
[7]
Xiao Ding, Yue Zhang, Ting Liu, and Junwen Duan. 2015. Deep learning for event-driven stock prediction.. InIJCAI, Vol. 15. AAAI Press, Palo Alto, CA, USA, 2327–2333
2015
-
[8]
Lily Fang and Joel Peress. 2009. Media coverage and the cross-section of stock returns.The journal of finance64, 5 (2009), 2023–2052
2009
-
[9]
Scott Fujimoto and Shixiang Shane Gu. 2021. A minimalist approach to offline reinforcement learning.Advances in neural information processing systems34 (2021), 20132–20145
2021
-
[10]
Tao Guo, Michael Finke, and Barry Mulholland. 2015. Investor attention and advisor social media interaction.Applied Economics Letters22, 4 (2015), 261–265
2015
-
[11]
Dylan Hadfield-Menell, Stuart J Russell, Pieter Abbeel, and Anca Dragan. 2016. Cooperative inverse reinforcement learning. InAdvances in Neural Information Processing Systems, Vol. 29. Curran Associates, Inc., Red Hook, NY, USA
2016
-
[12]
Adam S Hayes and Ambreen T Ben-Shmuel. 2024. Under the finfluence: Financial influencers, economic meaning-making and the financialization of digital life. Economy and Society53, 3 (2024), 478–503
2024
-
[13]
Ivy SH Hii and Yi Xuan Ong. 2026. Finfluencer: can financial social media influencers promote desirable financial behaviours?International Journal of Bank Marketing44, 2 (2026), 284–312
2026
-
[14]
Tommi Jaakkola, Satinder Singh, and Michael Jordan. 1994. Reinforcement learn- ing algorithm for partially observable Markov decision problems. InAdvances in Neural Information Processing Systems, Vol. 7. MIT Press, Cambridge, MA, USA
1994
-
[15]
Zhengyao Jiang, Dixing Xu, and Jinjun Liang. 2017. A deep reinforcement learning framework for the financial portfolio management problem. arXiv:1706.10059 [q- fin.PM]
work page Pith review arXiv 2017
-
[16]
2023.Finfluencers
Ali Kakhbod, Seyed Mohammad Kazempour, Dmitry Livdan, and Norman Schuer- hoff. 2023.Finfluencers. Technical Report 2. Swiss Finance Institute
2023
-
[17]
2019.Predicting returns with text data
Zheng Tracy Ke, Bryan T Kelly, and Dacheng Xiu. 2019.Predicting returns with text data. Technical Report. National Bureau of Economic Research
2019
-
[18]
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. 2021. Offline reinforcement learning with implicit q-learning.arXiv preprint arXiv:2110.06169(2021)
work page internal anchor Pith review arXiv 2021
-
[19]
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. 2020. Conserva- tive q-learning for offline reinforcement learning.Advances in neural information processing systems33 (2020), 1179–1191
2020
-
[20]
Qinghua Liu, Alan Chung, Csaba Szepesv’ari, and Chi Jin. 2022. When is partially observable reinforcement learning not scary?. InConference on Learning Theory. PMLR, PMLR, London, UK, 5175–5220
2022
-
[21]
Anshul Mittal and Arpit Goel. 2012. Stock prediction using twitter sen- timent analysis.Standford University, CS229 (2011 http://cs229. stanford. edu/proj2011/GoelMittal-StockMarketPredictionUsingTwitterSentimentAnalysis. pdf)15 (2012), 2352
2012
-
[22]
John Moody and Matthew Saffell. 2001. Learning to trade via direct reinforcement. IEEE transactions on neural Networks12, 4 (2001), 875–889
2001
-
[23]
Ashvin Nair, Murtaza Dalal, Abhishek Gupta, and Sergey Levine. 2020. Accelerating Online Reinforcement Learning with Offline Datasets. arXiv:2006.09359 [cs.LG]
work page internal anchor Pith review arXiv 2020
-
[24]
Yuriy Nevmyvaka, Yi Feng, and Michael Kearns. 2006. Reinforcement learning for optimized trade execution. InProceedings of the 23rd International Conference on Machine Learning. Association for Computing Machinery, New York, NY, USA, 673–680
2006
-
[25]
Venkata Sasank Pagolu, Kamal Nayan Reddy, Ganapati Panda, and Babita Majhi
-
[26]
In2016 international conference on signal processing, communication, power and embedded system (SCOPES)
Sentiment analysis of Twitter data for predicting stock market movements. In2016 international conference on signal processing, communication, power and embedded system (SCOPES). IEEE, IEEE, Piscataway, NJ, USA, 1345–1350
-
[27]
Ronald Parr and Stuart Russell. 1997. Reinforcement learning with hierarchies of machines. InAdvances in Neural Information Processing Systems, Vol. 10. Curran Associates, Inc., Red Hook, NY, USA
1997
-
[28]
Gabriele Ranco, Darko Aleksovski, Guido Caldarelli, Miha Grčar, and Igor Mozetič
-
[29]
The effects of Twitter sentiment on stock price returns.PloS one10, 9 (2015), e0138441
2015
-
[30]
Robert P Schumaker and Hsinchun Chen. 2009. Textual analysis of stock mar- ket prediction using breaking financial news: The AZFin text system.ACM Transactions on Information Systems (TOIS)27, 2 (2009), 1–19
2009
-
[31]
Jianfeng Si, Arjun Mukherjee, Bing Liu, Qing Li, Huayi Li, and Xiaotie Deng. 2013. Exploiting topic based twitter sentiment for stock prediction. InProceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Association for Computational Linguistics, Sofia, Bulgaria, 24–29
2013
-
[32]
Timm O Sprenger, Andranik Tumasjan, Philipp G Sandner, and Isabell M Welpe
-
[33]
Tweets and trades: The information content of stock microblogs.European Financial Management20, 5 (2014), 926–957
2014
-
[34]
Richard S Sutton, Doina Precup, and Satinder Singh. 1999. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artificial intelligence112, 1-2 (1999), 181–211
1999
-
[35]
Paul C Tetlock. 2007. Giving content to investor sentiment: The role of media in the stock market.The Journal of finance62, 3 (2007), 1139–1168
2007
-
[36]
Kent L Womack. 1996. Do brokerage analysts’ recommendations have investment value?The journal of finance51, 1 (1996), 137–167
1996
- [37]
-
[38]
Hongyang Yang, Xiao-Yang Liu, Shan Zhong, and Anwar Walid. 2020. Deep reinforcement learning for automated stock trading: An ensemble strategy. In Proceedings of the first ACM international conference on AI in finance. 1–8. Supplementary Material This document contains supplementary materials for the main manuscript. When Missing Becomes Structure: Intent...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.