Jet Quenching Identification via Supervised Learning in Simulated Heavy-Ion Collisions
Pith reviewed 2026-05-09 23:23 UTC · model grok-4.3
The pith
Sequential machine learning on jet declustering history trees outperforms static models in classifying medium-modified jets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sequential machine learning architectures applied to the jet declustering history tree achieve improved classification performance compared with static models that learn only from a single stage of the jet evolution. Models trained on different medium implementations exhibit meaningful performance modification under cross-domain validation, indicating that machine learning is sensitive to implementation-specific features that traditional observables may not resolve.
What carries the argument
The jet declustering history tree, which records the ordered sequence of splittings as the jet evolves through the medium and supplies the temporal structure that sequential models exploit to detect cumulative modifications.
If this is right
- Machine learning can extract more discriminative information from the ordered jet evolution history than is available in traditional global observables such as R_AA.
- Cross-domain validation demonstrates that the learned features are sensitive to how different models implement parton-medium interactions.
- Machine learning offers a route to address some limitations of conventional jet-modification analyses by using the full declustering sequence.
Where Pith is reading between the lines
- The approach could be applied to real collider data once simulation fidelity is established, potentially allowing experimental distinction between competing jet-quenching models.
- Combining the sequential classifier with other observables might tighten constraints on medium transport coefficients beyond what either method achieves alone.
- If the performance edge persists, it would motivate developing dedicated sequential architectures tailored to the physics of successive jet splittings.
Load-bearing premise
The jet declustering history tree extracted from simulations contains enough additional information about medium-induced changes that sequential models can use it to improve over static features, and this extra information generalizes when the models are applied to different medium descriptions.
What would settle it
A direct comparison in which a sequential model trained on one medium implementation shows no statistically significant accuracy gain over a static model on the same inputs, or shows unchanged performance when validated on a second, independently implemented medium model.
Figures






read the original abstract
Jet modification in heavy-ion collisions provides microscopic access to the properties of the quark-gluon plasma. However, conventional approaches based on traditional global observables, such as \(R_{AA}\), capture limited information about the complex dynamics of parton-medium interactions during hard scatterings. In this work, we apply sequential machine learning architectures to the jet declustering history tree, achieving improved classification performance compared with static models that learn only from a single stage of the jet evolution. We find that models trained on different medium implementations exhibit meaningful performance modification under cross-domain validation, indicating that machine learning is sensitive to implementation-specific features that traditional observables may not resolve. These results suggest new opportunities for using machine learning as an analysis tool to overcome some of the limitations of traditional jet-modification studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript applies sequential machine learning architectures to the full jet declustering history tree extracted from simulated heavy-ion collisions. It claims that these models achieve improved classification of jet quenching relative to static models trained on only a single stage of jet evolution. Cross-domain tests across different medium implementations are reported to produce meaningful performance changes, indicating that the approach is sensitive to implementation-specific features not resolved by traditional observables such as R_AA.
Significance. If the central performance claims are substantiated with appropriate controls, the work could provide a new analysis tool for extracting microscopic information about parton-medium interactions from jet substructure. The cross-medium validation aspect is particularly promising, as it suggests machine learning may help diagnose model dependencies in QGP simulations that global observables miss. The absence of any numerical results or baseline details in the abstract, however, prevents a quantitative judgment of impact at present.
major comments (3)
- [Abstract] Abstract and main results: The central claim of 'improved classification performance' is stated without any quantitative metrics (accuracy, AUC, F1, ROC curves, or statistical significance), error bars, training/validation splits, or hyperparameter details. This renders the superiority assertion unverifiable and load-bearing for the paper's contribution.
- [Results] Comparison to baselines: The performance advantage is attributed to sequential processing of the declustering tree, yet the only baselines are static models restricted to a single evolution stage. No control is presented in which a non-sequential model (MLP, gradient-boosted trees, or similar) receives the concatenated full set of splitting variables from all stages. Without this test, the reported gains cannot be ascribed to the sequential inductive bias rather than simply to access to the complete history.
- [Results] Cross-domain validation: The statement that models 'exhibit meaningful performance modification under cross-domain validation' is given without numerical values, confusion matrices, or transfer metrics. This weakens the claim that machine learning resolves implementation-specific features beyond what traditional observables capture.
minor comments (2)
- [Abstract] The abstract would be strengthened by naming the specific sequential architectures employed (LSTM, GRU, Transformer, etc.) and the precise definition of the declustering history tree features.
- Notation for jet observables (e.g., R_AA) is standard but the manuscript should explicitly define the input feature vector for each declustering step to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We have revised the manuscript to address the concerns about quantitative metrics, baseline controls, and cross-domain results. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract and main results: The central claim of 'improved classification performance' is stated without any quantitative metrics (accuracy, AUC, F1, ROC curves, or statistical significance), error bars, training/validation splits, or hyperparameter details. This renders the superiority assertion unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the abstract should contain key quantitative metrics to allow verification of the central claims. The revised abstract now includes specific AUC and accuracy values with uncertainties, along with references to the training/validation splits and hyperparameter choices described in the methods. The full ROC curves, statistical tests, and error bars were already present in Section 3; these are now explicitly summarized in the abstract as well. revision: yes
-
Referee: [Results] Comparison to baselines: The performance advantage is attributed to sequential processing of the declustering tree, yet the only baselines are static models restricted to a single evolution stage. No control is presented in which a non-sequential model (MLP, gradient-boosted trees, or similar) receives the concatenated full set of splitting variables from all stages. Without this test, the reported gains cannot be ascribed to the sequential inductive bias rather than simply to access to the complete history.
Authors: The referee is correct that our original baselines compared sequential models on the full declustering history against static models using only a single stage, without testing a non-sequential model on the concatenated features from all stages. This additional control is required to isolate the contribution of the sequential architecture. We have performed the suggested experiment with an MLP (and a gradient-boosted tree) trained on the full concatenated splitting variables and report the results in the revised manuscript. The sequential models retain a clear performance advantage, supporting attribution to the sequential inductive bias. revision: yes
-
Referee: [Results] Cross-domain validation: The statement that models 'exhibit meaningful performance modification under cross-domain validation' is given without numerical values, confusion matrices, or transfer metrics. This weakens the claim that machine learning resolves implementation-specific features beyond what traditional observables capture.
Authors: We accept that the cross-domain results were described qualitatively without accompanying numerical values or matrices. The revised manuscript now includes explicit transfer metrics (accuracy and AUC changes under cross-medium evaluation), confusion matrices for each source-target pair, and direct comparisons showing that the observed performance shifts exceed those seen in R_AA for the same medium implementations. These additions substantiate the sensitivity to implementation-specific features. revision: yes
Circularity Check
No circularity: purely empirical ML performance comparison on simulated data
full rationale
The paper presents an empirical study applying sequential ML models to jet declustering trees from heavy-ion simulations and reports improved classification over single-stage static baselines. No equations, derivations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes appear in the provided text. The central claim is a data-driven performance statement that does not reduce to its inputs by construction; any limitations in experimental controls (e.g., full-history static baselines) concern validity of attribution rather than circularity in a derivation chain. This matches the default expectation of no significant circularity for non-theoretical empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulated heavy-ion collisions with different medium implementations accurately represent distinct physical scenarios relevant to real data.
Reference graph
Works this paper leans on
-
[1]
andβ= 0 [30]. This choice is motivated by the fact that this configuration provides a theoretically clean grooming procedure. In particular,β= 0 removes the angular dependence from the grooming condition, mak- ing the algorithm sensitive only to the momentum shar- ing between subjets, whilez cut = 0.1 suppresses soft con- taminating radiation without sign...
-
[2]
Attention-Enhanced LSTM The attention mechanism [14, 47] has transformed the approach to sequence modeling. It allows networks to focus on different parts of the input sequence dynamically when making predictions. Unlike traditional RNNs or LSTMs that fit everything into a single context vector, the attention mechanism takes a more nuanced approach by cal...
-
[3]
for more information about supervised models eval- uation metrics. Hyperparameter optimization [53, 54] was conducted by training several models with different parameter com- binations on the training dataset, followed by an evalu- ation of their performance using the validation set. The configuration that achieved the best results on the vali- dation set...
-
[4]
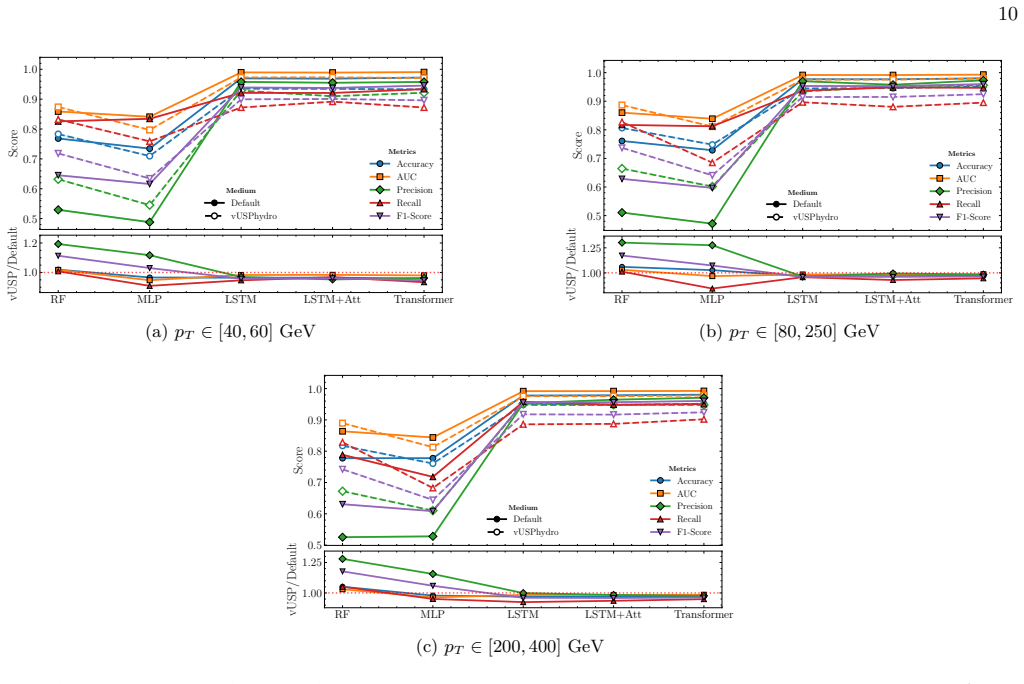
Performance Metrics Tables I and II show the evaluation metrics measured for the Random Forest and MLP, respectively. The RF models exhibit a consistent performance across all pT intervals and for both the Default and v-USPhydro datasets. In particular, AUC scores remain above 0.85 in all cases, with a precision of around 0.5, indicating significant false...
-
[5]
Cross-domain Validation To further examine the reliability of these models and eliminate concerns about the dependence on superficial patterns, we conducted cross-domain evaluations (see Ta- bles III and IV). We trained models on jets originating 7 TABLE II: Performance metrics for the MLP classifier acrossp T ranges and scenarios. pT [GeV] Metric Default...
-
[6]
Importance Analysis To explore which input features most influence the predictions of the model, we perform a feature impor- tance analysis based on SHAP (SHapley Additive exPla- nations) values [67]. This method is grounded in cooper- ative game theory and provides model-agnostic attribu- tions of feature relevance. Positive SHAP values indicate that a g...
-
[7]
Performance Metrics Tables V and VI present the performance metrics for both LSTM and LSTM+Attention models, evaluated on theJewelDefault and v-USPhydro substructure datasets, across the threep T intervals that are consid- ered in this study. In all cases, the values reported are averages over independent runs, with the error indicated as well. TABLE V: P...
-
[8]
Cross-domain Validation To examine the capacity of LSTM, LSTM+Attention, and Transformer models to generalize the learned data, we conduct cross-domain evaluations, similarly to the ap- proach used for the Random Forest and MLP models in Section V A 2. In this setup, models are trained on data from one medium, either Default or v-USPhydro, and subsequentl...
-
[9]
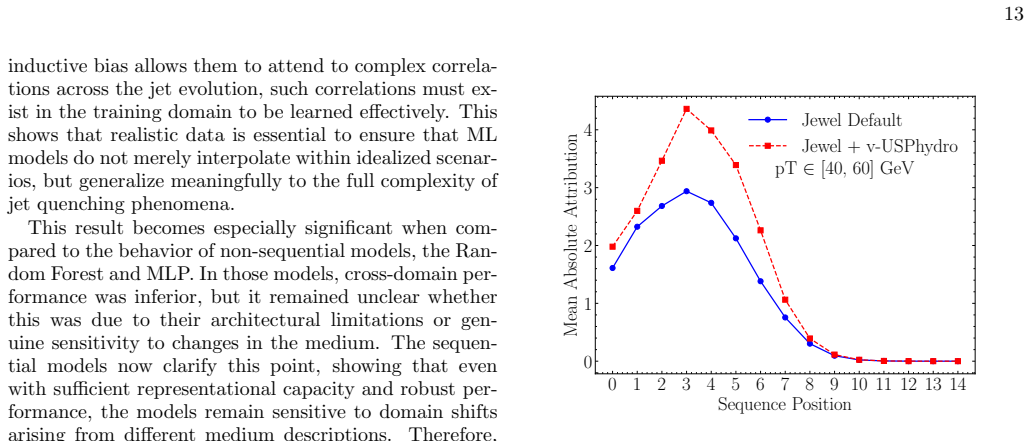
Sequence Importance Analysis To investigate the relevance of each position in the Soft Drop sequence, we compute the absolute SHAP attribu- tion step by step for every jet and then take the aver- age. In this way, the curves indicate the average im- portance of each declustering step in the model decision. The distributions of the mean absolute SHAP value...
work page 2024
-
[10]
Evidence for a New State of Matter: An Assessment of the Results from the CERN Lead Beam Programme
U. Heinz and M. Jacob, Evidence for a new state of mat- ter: An assessment of the results from the cern lead beam programme, arXiv preprint nucl-th/0002042 (2000)
work page Pith review arXiv 2000
-
[11]
J. Adams, M. Aggarwal, Z. Ahammed, J. Amonett, B. Anderson, D. Arkhipkin, G. Averichev, S. Badyal, Y. Bai, J. Balewski,et al., Experimental and theoreti- cal challenges in the search for the quark–gluon plasma: The star collaboration’s critical assessment of the evi- dence from rhic collisions, Nuclear Physics A757, 102 (2005)
work page 2005
-
[12]
S. Cao and X.-N. Wang, Jet quenching and medium re- sponse in high-energy heavy-ion collisions: a review, Re- ports on Progress in Physics84, 024301 (2021)
work page 2021
-
[13]
M. M. de Melo Paulino,Study of the medium effects in jet observables in relativistic heavy-ion collisions, Master’s thesis, Universidade de S˜ ao Paulo (USP) (2024), acesso em: 7 jan. 2025
work page 2024
- [14]
-
[15]
Du, Overview: Jet quenching with machine learn- ing, arXiv preprint arXiv:2308.10035 (2023)
Y.-L. Du, Overview: Jet quenching with machine learn- ing, arXiv preprint arXiv:2308.10035 (2023)
-
[16]
H. J. Bossi,Novel Uses of Machine Learning for Differ- ential Jet Quenching Measurements at the LHC, Ph.D. thesis, Yale University (2023)
work page 2023
-
[17]
K. C. Zapp, F. Krauss, and U. A. Wiedemann, A per- turbative framework for jet quenching, Journal of High Energy Physics2013, 10.1007/jhep03(2013)080 (2013)
-
[18]
K. Zapp, Jewel 2.0.0: directions for use, The European Physical Journal C74, 10.1140/epjc/s10052-014-2762-1 (2014)
-
[19]
J. Noronha-Hostler, G. S. Denicol, J. Noronha, R. P. G. Andrade, and F. Grassi, v-USPhydro: Bulk Viscosity Ef- fects on Event-by-Event Relativistic Hydrodynamics, J. Phys. Conf. Ser.458, 012018 (2013)
work page 2013
-
[20]
Breiman, Random forests, Machine learning45, 5 (2001)
L. Breiman, Random forests, Machine learning45, 5 (2001)
work page 2001
-
[21]
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, Learning representations by back-propagating errors, na- ture323, 533 (1986)
work page 1986
-
[22]
S. Hochreiter and J. Schmidhuber, Long short-term mem- ory, Neural computation9, 1735 (1997)
work page 1997
-
[23]
Neural Machine Translation by Jointly Learning to Align and Translate
D. Bahdanau, K. Cho, and Y. Bengio, Neural machine translation by jointly learning to align and translate, arXiv preprint arXiv:1409.0473 (2014)
work page internal anchor Pith review arXiv 2014
-
[24]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, At- tention is all you need, Advances in neural information processing systems30(2017)
work page 2017
-
[25]
T. Sj¨ ostrand, S. Mrenna, and P. Skands, Pythia 6.4 physics and manual, Journal of High Energy Physics 2006, 026 (2006)
work page 2006
-
[26]
T. Sj¨ ostrand, S. Ask, J. R. Christiansen, R. Corke, N. De- sai, P. Ilten, S. Mrenna, S. Prestel, C. O. Rasmussen, and P. Z. Skands, An introduction to pythia 8.2, Computer physics communications191, 159 (2015)
work page 2015
-
[27]
M. L. Miller, K. Reygers, S. J. Sanders, and P. Stein- berg, Glauber modeling in high-energy nuclear collisions, Annu. Rev. Nucl. Part. Sci.57, 205 (2007)
work page 2007
- [28]
-
[29]
B. Zakharov, Radiative energy loss of high-energy quarks in finite-size nuclear matter and quark-gluon plasma, Journal of Experimental and Theoretical Physics Letters 65, 615 (1997)
work page 1997
-
[30]
R. Kunnawalkam Elayavalli and K. C. Zapp, Medium response in jewel and its impact on jet shape observables in heavy ion collisions, Journal of High Energy Physics 2017, 1 (2017)
work page 2017
- [31]
-
[32]
J. S. Moreland, J. E. Bernhard, and S. A. Bass, Alter- native ansatz to wounded nucleon and binary collision scaling in high-energy nuclear collisions, Phys. Rev. C 92, 011901 (2015), arXiv:1412.4708 [nucl-th]
work page Pith review arXiv 2015
-
[33]
J. E. Bernhard, J. S. Moreland, and S. A. Bass, Bayesian estimation of the specific shear and bulk viscosity of 16 quark–gluon plasma, Nature Physics15, 1113 (2019)
work page 2019
-
[34]
M. Crispim Rom˜ ao, J. Guilherme Milhano, and M. van Leeuwen, Jet substructure observables for jet quenching in quark gluon plasma: A machine learning driven anal- ysis, SciPost Physics16, 015 (2024)
work page 2024
-
[35]
A. J. Larkoski, S. Marzani, G. Soyez, and J. Thaler, Soft drop, Journal of High Energy Physics2014, 1 (2014)
work page 2014
-
[36]
M. Cacciari, G. P. Salam, and G. Soyez, The anti-kt jet clustering algorithm, Journal of High Energy Physics 2008, 063 (2008)
work page 2008
-
[37]
Y. L. Dokshitzer, G. Leder, S. Moretti, and B. Webber, Better jet clustering algorithms, Journal of High Energy Physics1997, 001 (1997)
work page 1997
-
[38]
CMS Collaboration, Measurement of the primary lund jet plane density in proton-proton collisions at √s= 13 tev, Journal of High Energy Physics2024, 116 (2024)
work page 2024
-
[39]
A. J. Larkoski, S. Marzani, and J. Thaler, Sudakov safety in perturbative qcd, Physical Review D91, 111501 (2015)
work page 2015
-
[40]
L. Liu, J. Velkovska, Y. Wu, and M. Verweij, Identifying quenched jets in heavy ion collisions with machine learn- ing, Journal of High Energy Physics2023, 1 (2023)
work page 2023
-
[41]
Zhou,Ensemble methods: foundations and algo- rithms(CRC press, 2025)
Z.-H. Zhou,Ensemble methods: foundations and algo- rithms(CRC press, 2025)
work page 2025
-
[42]
T. G. Dietterich, Ensemble methods in machine learning, inInternational workshop on multiple classifier systems (Springer, 2000) pp. 1–15
work page 2000
-
[43]
L. Breiman, J. Friedman, R. A. Olshen, and C. J. Stone, Classification and regression trees(Routledge, 2017)
work page 2017
-
[44]
J. R. Quinlan, Induction of decision trees, Machine learn- ing1, 81 (1986)
work page 1986
-
[45]
Breiman, Bagging predictors, Machine learning24, 123 (1996)
L. Breiman, Bagging predictors, Machine learning24, 123 (1996)
work page 1996
-
[46]
T. K. Ho, The random subspace method for constructing decision forests, IEEE transactions on pattern analysis and machine intelligence20, 832 (1998)
work page 1998
-
[47]
H. Alhazmi, Z. Dong, L. Huang, J. H. Kim, K. Kong, and D. Shih, Resolving combinatorial ambiguities in dilepton tt event topologies with neural networks, Physical Re- view D105, 115011 (2022)
work page 2022
-
[48]
F. Rosenblatt, The perceptron: a probabilistic model for information storage and organization in the brain., Psy- chological review65, 386 (1958)
work page 1958
-
[49]
C. M. Bishop and N. M. Nasrabadi,Pattern recognition and machine learning, Vol. 4 (Springer, 2006)
work page 2006
-
[50]
V. Nair and G. E. Hinton, Rectified linear units improve restricted boltzmann machines, inProceedings of the 27th international conference on machine learning (ICML-10) (2010) pp. 807–814
work page 2010
- [51]
-
[52]
J. L. Elman, Finding structure in time, Cognitive science 14, 179 (1990)
work page 1990
-
[53]
I. Sutskever, O. Vinyals, and Q. V. Le, Sequence to se- quence learning with neural networks, Advances in neural information processing systems27(2014)
work page 2014
-
[54]
O. Vinyals, L. Kaiser, T. Koo, S. Petrov, I. Sutskever, and G. Hinton, Grammar as a foreign language, Advances in neural information processing systems28(2015)
work page 2015
- [55]
-
[56]
Effective Approaches to Attention-based Neural Machine Translation
M.-T. Luong, H. Pham, and C. D. Manning, Effective ap- proaches to attention-based neural machine translation, arXiv preprint arXiv:1508.04025 (2015)
work page Pith review arXiv 2015
-
[57]
Y. Yi, Z. Chen, and R. Li, Lstm neural networks with attention mechanisms for accelerated prediction of charge density at onset condition of dc corona discharge, IEEE Access10, 124697 (2022)
work page 2022
-
[58]
Reasoning about Entailment with Neural Attention
T. Rockt¨ aschel, E. Grefenstette, K. M. Hermann, T. Koˇ cisk` y, and P. Blunsom, Reasoning about entailment with neural attention, arXiv preprint arXiv:1509.06664 (2015)
work page Pith review arXiv 2015
-
[59]
H. Qu, C. Li, and S. Qian, Particle transformer for jet tagging, inInternational Conference on Machine Learn- ing(PMLR, 2022) pp. 18281–18292
work page 2022
- [60]
-
[61]
Ferrer, Analysis and comparison of classification met- rics, arXiv preprint arXiv:2209.05355 (2022)
L. Ferrer, Analysis and comparison of classification met- rics, arXiv preprint arXiv:2209.05355 (2022)
-
[62]
J. Bergstra and Y. Bengio, Random search for hyper- parameter optimization, The journal of machine learning research13, 281 (2012)
work page 2012
-
[63]
J. Bergstra, R. Bardenet, Y. Bengio, and B. K´ egl, Al- gorithms for hyper-parameter optimization, Advances in neural information processing systems24(2011)
work page 2011
-
[64]
B. Efron, Bootstrap methods: another look at the jack- knife, inBreakthroughs in statistics: Methodology and distribution(Springer, 1992) pp. 569–593
work page 1992
-
[65]
B. Efron and R. J. Tibshirani,An introduction to the bootstrap(Chapman and Hall/CRC, 1994)
work page 1994
-
[66]
A. C. Davison and D. V. Hinkley,Bootstrap methods and their application, 1 (Cambridge university press, 1997)
work page 1997
-
[67]
M. A. Hern´ an and J. M. Robins, Causal inference (2010)
work page 2010
-
[68]
L. Apolinario, N. Armesto, and L. Cunqueiro, An anal- ysis of the influence of background subtraction and quenching on jet observables in heavy-ion collisions, Jour- nal of High Energy Physics2013, 1 (2013)
work page 2013
- [69]
- [70]
-
[71]
A. Budhraja, M. van Leeuwen, and J. G. Milhano, Jet observables in heavy ion collisions: a white paper, arXiv preprint arXiv:2409.03017 (2024)
-
[72]
M. Connors, C. Nattrass, R. Reed, and S. Salur, Jet measurements in heavy ion physics, Reviews of Modern Physics90, 025005 (2018)
work page 2018
-
[73]
A. Falc˜ ao and K. Tywoniuk, Constraining jet quench- ing in heavy-ion collisions with bayesian inference, arXiv preprint arXiv:2411.14552 (2024)
- [74]
- [75]
-
[76]
S. M. Lundberg and S.-I. Lee, A unified approach to in- terpreting model predictions, Advances in neural infor- mation processing systems30(2017). 17
work page 2017
-
[77]
G. Milhano, U. A. Wiedemann, and K. C. Zapp, Sensitiv- ity of jet substructure to jet-induced medium response, Physics Letters B779, 409 (2018)
work page 2018
-
[78]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg,et al., Scikit-learn: Machine learn- ing in python, the Journal of machine Learning research 12, 2825 (2011)
work page 2011
- [79]
-
[80]
J. Bergstra, D. Yamins, and D. D. Cox, Making a sci- ence of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures, inPro- ceedings of the 30th International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 28 (2013) pp. 115–123. 18 Appendix A: Machine Learning Hyperparameters In this ap...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.