A Multi-Head Attention Approach for SLA Compliance Monitoring in Data Centers
Pith reviewed 2026-05-08 16:23 UTC · model grok-4.3
The pith
A multi-head transformer model trained on JSON-encoded SLA rules predicts data center violations thirty minutes before they occur.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
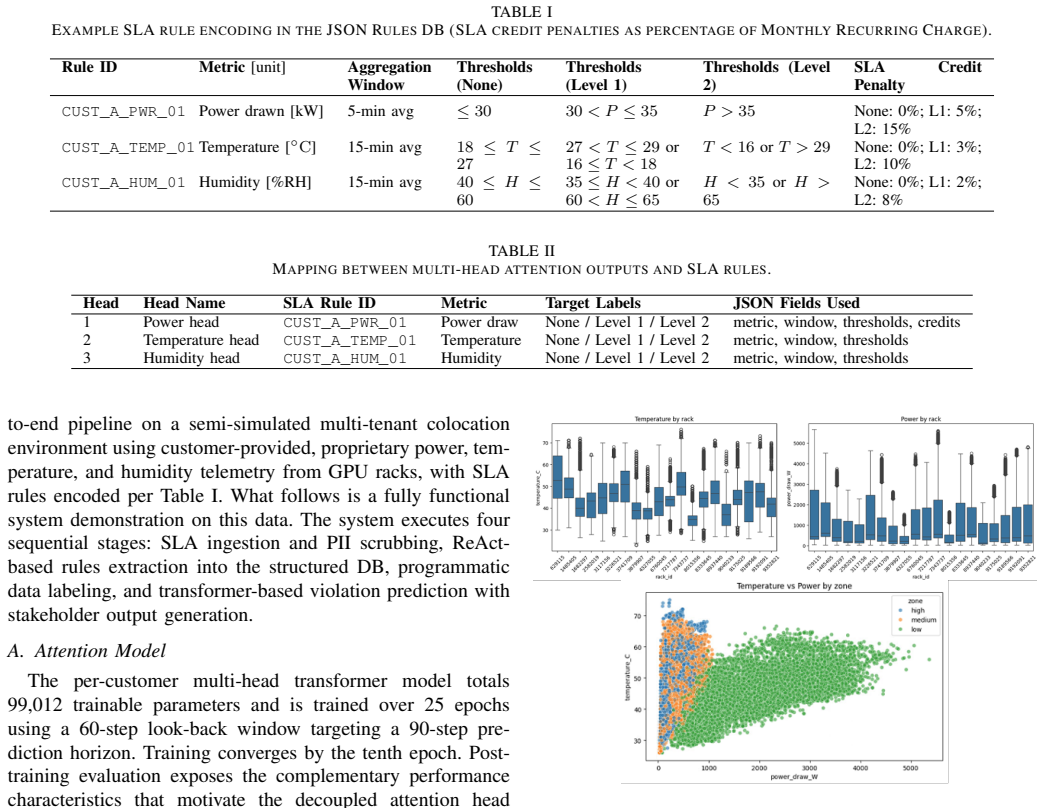
We present a framework that encodes SLA rules as structured JSON objects to generate training data without manual annotation. We train a per-customer multi-head transformer model in which each attention head specializes in one SLA rule, learning temporal dependencies that precede violations by 30 minutes. Post-training, the inference service emits structured prediction events transformed into three role-specific views: finance schemas exposing credit liability, operations schemas surfacing risk scores and recommended interventions, and compliance schemas bundling predictions with immutable telemetry signatures for audit.
What carries the argument
Per-customer multi-head transformer model in which each attention head specializes in the temporal patterns of one SLA rule.
If this is right
- Operators receive advance notice of SLA breaches and can act before penalties accrue.
- Finance teams obtain early estimates of credit liabilities from predicted violations.
- Operations teams receive risk scores and suggested interventions for each rule.
- Compliance teams gain bundled predictions with immutable telemetry for audits.
- The architecture directly maps model components to contractual terms rather than generic anomaly detection.
Where Pith is reading between the lines
- The JSON encoding step could let operators update the system when contract terms change by regenerating training data without rebuilding the entire model.
- Customer-specific training might prove necessary only for rules with highly variable thresholds across sites; a pooled model could be tested as a lighter alternative.
- If the thirty-minute horizon holds in practice, the outputs could feed directly into automated control loops that adjust cooling or power allocation to avert breaches.
- The role-specific views suggest a template for other regulated monitoring tasks where different stakeholders need distinct slices of the same prediction stream.
Load-bearing premise
Encoding SLA rules as JSON objects produces sufficient high-quality training data for a per-customer multi-head transformer to reliably learn temporal dependencies that precede violations by 30 minutes.
What would settle it
Deploying the trained models on live telemetry from multiple data centers and observing that prediction accuracy for actual 30-minute-ahead violations falls to levels no better than a simple threshold or single-head baseline would falsify the central claim.
Figures






read the original abstract
Service level agreements (SLAs) in data center colocation contracts define precise thresholds for power, temperature, and humidity, with tiered violation penalties expressed as credits against monthly recurring charges. Traditional reactive monitoring detects breaches only after they occur, limiting remediation opportunities. We present a framework that encodes SLA rules as structured JSON objects to generate training data without manual annotation. We train a per-customer multi-head transformer model in which each attention head specializes in one SLA rule, learning temporal dependencies that precede violations by 30 minutes. Post-training, the inference service emits structured prediction events transformed into three role-specific views: finance schemas exposing credit liability, operations schemas surfacing risk scores and recommended interventions, and compliance schemas bundling predictions with immutable telemetry signatures for audit. By aligning model architecture directly with contractual obligations, this framework enables operators to anticipate SLA breaches, prioritize corrective actions, and minimize financial penalties.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for proactive SLA compliance monitoring in data centers. SLA rules are encoded as structured JSON objects to synthetically generate training data without manual annotation. A per-customer multi-head transformer is trained such that each attention head specializes in one SLA rule, learning temporal dependencies to predict violations 30 minutes ahead. Post-training inference emits structured prediction events that are transformed into role-specific views (finance schemas for credit liability, operations schemas for risk scores and interventions, and compliance schemas for audit). The framework aims to align model architecture with contractual obligations to anticipate breaches, prioritize actions, and minimize penalties.
Significance. If the central claims were empirically validated, the work could offer meaningful practical value for data center operators by enabling proactive rather than reactive SLA monitoring, potentially reducing financial penalties through early intervention. The idea of directly aligning multi-head attention specialization with individual contractual rules is conceptually appealing and could improve interpretability in regulated environments. However, the current manuscript provides no experimental results, metrics, or validation, so its significance remains prospective rather than demonstrated.
major comments (3)
- [Abstract] Abstract: The central claim that the per-customer multi-head transformer 'learns temporal dependencies that precede violations by 30 minutes' is unsupported by any reported experiments, training details, performance metrics (e.g., precision, recall, F1, or lead-time accuracy), error analysis, or comparisons to baselines. No results on synthetic or real telemetry are presented.
- [Data Generation] Data generation process: Encoding SLA rules as JSON to produce training data creates a circularity risk, as the model is trained on synthetic data derived directly from the same rules it is intended to monitor. The manuscript does not demonstrate that the learned dependencies generalize to independent real-world telemetry or external benchmarks.
- [Model Architecture] Model architecture and evaluation: No details are provided on how head specialization is enforced during training, no ablation studies on the multi-head design versus standard transformers, and no quantitative assessment of whether the 30-minute prediction horizon is achieved with sufficient accuracy to affect penalty minimization.
minor comments (1)
- [Abstract] The description of the three role-specific output views (finance, operations, compliance) remains high-level; including concrete schema examples or transformation logic would improve reproducibility and clarity.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We address each of the major comments below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the per-customer multi-head transformer 'learns temporal dependencies that precede violations by 30 minutes' is unsupported by any reported experiments, training details, performance metrics (e.g., precision, recall, F1, or lead-time accuracy), error analysis, or comparisons to baselines. No results on synthetic or real telemetry are presented.
Authors: We acknowledge that the manuscript does not present experimental results to support the claim. The paper describes a proposed framework, and the statement in the abstract is based on the intended design of the model rather than observed performance. We will revise the abstract to state that the architecture is designed to learn temporal dependencies preceding violations by 30 minutes, and add a dedicated section on evaluation methodology and planned experiments to validate the approach. revision: yes
-
Referee: [Data Generation] Data generation process: Encoding SLA rules as JSON to produce training data creates a circularity risk, as the model is trained on synthetic data derived directly from the same rules it is intended to monitor. The manuscript does not demonstrate that the learned dependencies generalize to independent real-world telemetry or external benchmarks.
Authors: The referee correctly identifies a potential limitation in relying solely on synthetic data. The JSON encoding allows for rule-compliant synthetic generation to train the model without manual labeling, which is practical given the scarcity of violation data. We will revise the manuscript to explicitly discuss this circularity risk and include strategies for mitigating it, such as incorporating real telemetry for validation and fine-tuning, as well as testing on external benchmarks where possible. revision: yes
-
Referee: [Model Architecture] Model architecture and evaluation: No details are provided on how head specialization is enforced during training, no ablation studies on the multi-head design versus standard transformers, and no quantitative assessment of whether the 30-minute prediction horizon is achieved with sufficient accuracy to affect penalty minimization.
Authors: We agree that the current version lacks these details. We will expand the model architecture section to describe the mechanism for enforcing head specialization, for example through rule-specific attention masking or auxiliary losses. Additionally, we will incorporate ablation studies comparing the multi-head approach to baselines. However, as the manuscript currently contains no empirical results, we cannot provide quantitative assessments of accuracy or penalty impact without further experimentation. revision: partial
- Quantitative evaluation of model performance, including metrics for the 30-minute prediction horizon and impact on penalty minimization, as these require conducting experiments not included in the present work.
Circularity Check
No circularity detected in framework proposal
full rationale
The paper proposes an architecture that encodes SLA rules as JSON objects to synthesize training data for a per-customer multi-head transformer, with each head intended to specialize on one rule and learn temporal patterns preceding violations. No mathematical derivation chain, equations, or first-principles results are presented that reduce by construction to the inputs. There are no self-citations of load-bearing uniqueness theorems, no ansatzes smuggled via prior work, and no renaming of known results as new predictions. The central claims concern the utility of aligning model structure with contractual rules rather than any closed-form derivation or fitted parameter being re-labeled as an independent prediction. The manuscript is therefore self-contained as a systems proposal without the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of attention heads and model size
- prediction horizon of 30 minutes
axioms (2)
- domain assumption SLA rules can be losslessly encoded as structured JSON objects that produce valid training sequences for temporal prediction
- domain assumption Historical telemetry contains detectable patterns that reliably precede SLA violations by a fixed 30-minute window
Reference graph
Works this paper leans on
-
[1]
Ai to drive 165% increase in data center power demand by 2030,
G. Sachs, “Ai to drive 165% increase in data center power demand by 2030,”English. URL: https://www. goldmansachs. com/insights/articles/ai-to-drive-165-increase-in-data-center-power- demand-by-2030 (viitattu 17. 02. 2025), 2025
work page 2030
-
[2]
The rise of ai: A reality check on energy and economic impacts,
M. P. Mills, “The rise of ai: A reality check on energy and economic impacts,” 2025
work page 2025
-
[3]
Ai data center market by offering, data center type, application - global forecast to 2030,
MarketsandMarkets, “Ai data center market by offering, data center type, application - global forecast to 2030,” Research and Markets, Market Research Report 6103383, 6
work page 2030
-
[4]
[Online]. Available: https://www.researchandmarkets.com/reports/ 6103383/ai-data-center-market-offering-data-center
-
[5]
2024 united states data center energy usage report,
A. Shehabi, A. Newkirk, S. J. Smith, A. Hubbard, N. Lei, M. A. B. Siddik, B. Holecek, J. Koomey, E. Masanet, and D. Sartor, “2024 united states data center energy usage report,” 2024
work page 2024
-
[6]
Ai, data centers and the coming us power demand surge,
C. Davenport, B. Singer, N. Mehta, B. Lee, J. Mackay, A. Modak, B. Corbett, J. Miller, T. Hari, J. Ritchieet al., “Ai, data centers and the coming us power demand surge,”Goldman Sachs, vol. 26, 2024
work page 2024
-
[7]
Data center operator CyrusOne adds more cooling after outage, Bloomberg News reports,
Reuters, “Data center operator CyrusOne adds more cooling after outage, Bloomberg News reports,” November 30 2025, available at Reuters. Accessed: March 2, 2026
work page 2025
-
[8]
S. Melnyk, “Safe observability: A framework for automated pii redaction from llm prompts in opentelemetry pipelines,”International Journal of Computer (IJC), vol. 56, no. 1, pp. 267–278
-
[9]
Pii- compass: Guiding llm training data extraction prompts towards the target pii via grounding,
K. K. Nakka, A. Frikha, R. Mendes, X. Jiang, and X. Zhou, “Pii- compass: Guiding llm training data extraction prompts towards the target pii via grounding,” inProceedings of the Fifth Workshop on Privacy in Natural Language Processing, 2024, pp. 63–73
work page 2024
-
[10]
Langgraph: Building stateful, multi-agent applications with llms,
LangChain Inc., “Langgraph: Building stateful, multi-agent applications with llms,” 2024, version 1.0.3. [Online]. Available: https://github.com/ langchain-ai/langgraph
work page 2024
-
[11]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe eleventh international conference on learning representations, 2022
work page 2022
-
[12]
Re- flexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Re- flexion: Language agents with verbal reinforcement learning,”Advances in neural information processing systems, vol. 36, pp. 8634–8652, 2023
work page 2023
-
[13]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in neural informa- tion processing systems, vol. 36, pp. 68 539–68 551, 2023
work page 2023
-
[14]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[15]
J. Kim, H. Kim, H. Kim, D. Lee, and S. Yoon, “A comprehensive survey of deep learning for time series forecasting: architectural diversity and open challenges,”Artificial Intelligence Review, vol. 58, no. 7, p. 216, 2025
work page 2025
-
[16]
Multi-resolution time-series transformer for long-term forecasting,
Y . Zhang, L. Ma, S. Pal, Y . Zhang, and M. Coates, “Multi-resolution time-series transformer for long-term forecasting,” inInternational con- ference on artificial intelligence and statistics. PMLR, 2024, pp. 4222– 4230
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.