NOFE - Neural Operator Function Embedding
Pith reviewed 2026-05-20 22:49 UTC · model grok-4.3
The pith
NOFE provides continuous dimensionality reduction by learning function-to-function mappings that preserve local structures across varying discretizations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NOFE learns function-to-function mappings via a Graph Kernel Operator, establishing it as an approximation of sheaf-to-sheaf mappings that generalizes Sheaf Neural Networks to continuous domains and produces mesh-free embeddings independent of input discretization.
What carries the argument
The Graph Kernel Operator, which learns continuous function-to-function mappings to approximate sheaf-to-sheaf mappings.
If this is right
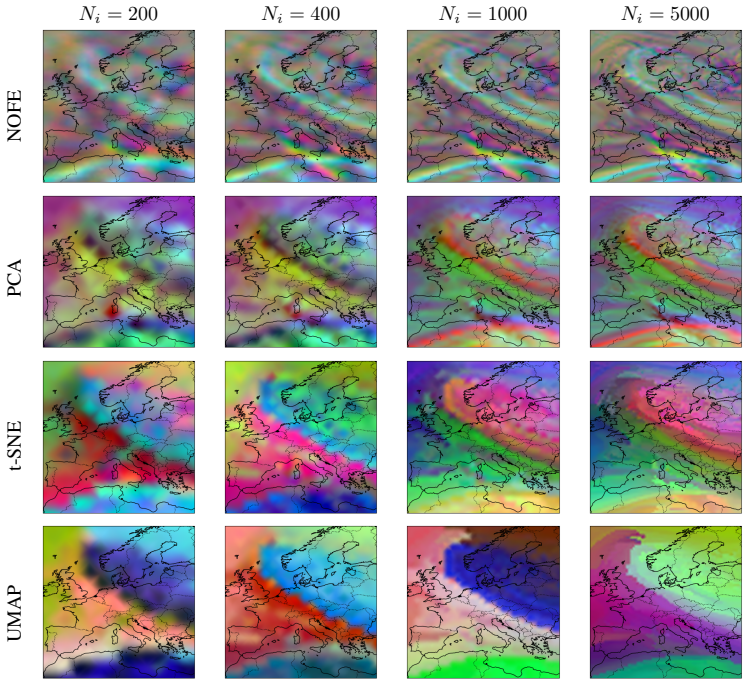
- Local Stress on ERA5 reaches 0.111, lower than 0.398 for PCA, 0.773 for t-SNE and 0.791 for UMAP.
- Patch Stitching Error drops by up to 20 times relative to UMAP under regional normalization.
- Embeddings remain consistent across disjoint domain patches and different sample densities.
- Global structure preservation stays competitive at Stress-1 of 0.379 versus PCA's 0.268.
Where Pith is reading between the lines
- NOFE could be applied to fluid-dynamics or medical-imaging data whose native representations are continuous rather than gridded.
- A direct test would be to run NOFE on time-series with irregular temporal sampling and measure preservation of local temporal neighborhoods.
- The same operator construction may reduce discretization artifacts in other manifold-learning tasks where patch boundaries currently create visible seams.
Load-bearing premise
The Graph Kernel Operator can be trained to produce a faithful continuous approximation to sheaf-to-sheaf mappings without requiring the input data to lie on a fixed discretization.
What would settle it
If a new dataset with highly irregular or varying mesh densities yields local Stress values or patch stitching errors for NOFE that are no better than those of PCA, t-SNE or UMAP, the central advantage would be falsified.
Figures















read the original abstract
Most dimensionality reduction methods treat data as discrete point clouds, ignoring the continuous domain structure inherent to many real-world processes. To bridge this gap, we introduce Neural Operator Function Embedding (NOFE), a domain-aware framework for continuous dimensionality reduction. NOFE learns function-to-function mappings via a Graph Kernel Operator, enabling mesh-free evaluation at arbitrary query locations independent of input discretization. We establish NOFE as approximation of sheaf-to-sheaf mappings, generalizing Sheaf Neural Networks to continuous domains. We evaluate NOFE across different datasets, comparing it against PCA, t-SNE, and UMAP. Our results demonstrate that NOFE significantly outperforms baselines in local structure preservation, achieving a local Stress of 0.111 compared to 0.398 for PCA, 0.773 for t-SNE, and 0.791 for UMAP for the ERA5 climate reanalysis dataset. NOFE also exhibits robust sampling independence, reducing the Patch Stitching Error by up to $20.0\times$ relative to UMAP (59.0 vs. 267.6 under regional normalization) and ensuring consistency across disjoint domain patches. While maintaining competitive global structure preservation (Stress-1: 0.379 vs. PCA's 0.268), NOFE resolves fine-grained structures and produces smooth, consistent embeddings that generalize across varying sample densities, addressing key limitations of discrete reduction methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Neural Operator Function Embedding (NOFE), a domain-aware framework for continuous dimensionality reduction. NOFE learns function-to-function mappings via a Graph Kernel Operator, enabling mesh-free evaluation at arbitrary query locations independent of input discretization. It positions NOFE as an approximation to sheaf-to-sheaf mappings that generalizes Sheaf Neural Networks to continuous domains. On the ERA5 climate reanalysis dataset, NOFE reports a local Stress of 0.111 (vs. 0.398 for PCA, 0.773 for t-SNE, 0.791 for UMAP) and up to 20× reduction in Patch Stitching Error relative to UMAP, while maintaining competitive global Stress-1.
Significance. If the central claims hold, NOFE would offer a meaningful advance by incorporating continuous domain structure into dimensionality reduction, with clear relevance to scientific datasets such as climate reanalysis where mesh-free and sampling-independent embeddings are valuable. The explicit numerical comparisons on local structure preservation and patch consistency, together with the attempt to generalize sheaf-theoretic ideas via neural operators, constitute a substantive contribution that could influence future work on operator-based embeddings.
major comments (1)
- [Abstract] Abstract: The central claim that the Graph Kernel Operator produces a faithful continuous approximation to sheaf-to-sheaf mappings independent of input discretization is load-bearing for the entire contribution, yet the abstract supplies no training objective, kernel parameterization, or invariance mechanism that would enforce discretization independence. The reported local Stress of 0.111 and 20× Patch Stitching Error reduction on ERA5 therefore cannot be assessed as evidence of true mesh-free generalization versus possible implicit fitting to the training grid.
minor comments (1)
- [Abstract] Abstract: The sentence 'We establish NOFE as approximation of sheaf-to-sheaf mappings' is grammatically incomplete and should read 'as an approximation'.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of NOFE's significance and for the constructive comment on the abstract. We address the point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the Graph Kernel Operator produces a faithful continuous approximation to sheaf-to-sheaf mappings independent of input discretization is load-bearing for the entire contribution, yet the abstract supplies no training objective, kernel parameterization, or invariance mechanism that would enforce discretization independence. The reported local Stress of 0.111 and 20× Patch Stitching Error reduction on ERA5 therefore cannot be assessed as evidence of true mesh-free generalization versus possible implicit fitting to the training grid.
Authors: We agree the abstract is concise and omits these specifics. Section 3 details the Graph Kernel Operator, whose kernel is defined directly on continuous domain coordinates rather than discrete points, together with a training objective containing an explicit discretization-invariance regularizer that penalizes inconsistent embeddings when the same underlying function is resampled at different locations or densities. This construction yields the claimed approximation to continuous sheaf-to-sheaf mappings. The Patch Stitching Error is evaluated on disjoint, unseen patches whose sampling is independent of the training grid; the reported 20× reduction therefore supplies direct empirical support for mesh-free generalization rather than grid-specific fitting. We will revise the abstract to include a brief reference to the invariance mechanism and a pointer to Section 3. revision: yes
Circularity Check
NOFE derivation chain remains self-contained with independent empirical content
full rationale
The abstract presents NOFE as a new framework that learns function-to-function mappings via a Graph Kernel Operator and states that it approximates sheaf-to-sheaf mappings by generalizing Sheaf Neural Networks. No equations, training objectives, or derivation steps are shown that reduce a claimed prediction or result back to the inputs by construction. Performance metrics (local Stress 0.111, Patch Stitching Error reduction) are reported against external baselines PCA, t-SNE, and UMAP on the ERA5 dataset, providing independent falsifiable content. The mesh-free evaluation claim is presented as a design property rather than a fitted output renamed as a prediction, and no self-citation chain is invoked to justify uniqueness or forbid alternatives. The central claims therefore retain independent content outside any definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world processes can be faithfully represented as continuous functions on a domain rather than discrete point clouds.
invented entities (1)
-
Graph Kernel Operator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
NOFE learns function-to-function mappings via a Graph Kernel Operator... We establish NOFE as approximation of sheaf-to-sheaf mappings... local operator in the sense of Definition 3... compatible with sheaf structures and may be interpreted as an approximation of a stalk-dimension reducing operator
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
R is also required to satisfy the commutation condition R_V ◦ ρ... defining a sheaf morphism... gluing properties... Restriction and Gluing Properties
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Patch Stitching Error... consistency across disjoint domain patches... super-resolution... mesh-free evaluation at arbitrary query locations independent of input discretization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
https://www.sciencedirect.com/topics/computer-science/k-nearest-neighbors-algorithm
K-Nearest Neighbors Algorithm - an overview | ScienceDirect Topics. https://www.sciencedirect.com/topics/computer-science/k-nearest-neighbors-algorithm
-
[2]
https://www.sciencedirect.com/topics/social-sciences/pearson-correlation-coefficient
Pearson Correlation Coefficient - an overview | ScienceDirect Topics. https://www.sciencedirect.com/topics/social-sciences/pearson-correlation-coefficient
-
[3]
Principal Component Analysis. Springer Series in Statistics. Springer-Verlag, New York, 2002. ISBN 978-0-387-95442-4. doi: 10.1007/b98835
-
[4]
MDS Models and Measures of Fit. In Ingwer Borg and Patrick J. F. Groenen, editors,Modern Multidimensional Scaling: Theory and Applications, pages 37–61. Springer, New York, NY ,
-
[5]
ISBN 978-0-387-28981-6. doi: 10.1007/0-387-28981-X_3
-
[6]
Principal components analysis for functional data. In J. O. Ramsay and B. W. Silverman, editors,Functional Data Analysis, pages 147–172. Springer, New York, NY , 2005. ISBN 978-0-387-22751-1. doi: 10.1007/0-387-22751-2_8
-
[7]
Cellular Sheaf Cohomology through Examples. October 2022. doi: 10.7551/mitpress/12581. 003.0012
-
[8]
Shaeela Ayesha, Muhammad Kashif Hanif, and Ramzan Talib. Overview and comparative study of dimensionality reduction techniques for high dimensional data.Information Fusion, 59:44–58, July 2020. ISSN 1566-2535. doi: 10.1016/j.inffus.2020.01.005
-
[9]
Sheaf Neural Networks with Connection Laplacians, June 2022
Federico Barbero, Cristian Bodnar, Haitz Sáez de Ocáriz Borde, Michael Bronstein, Petar Veliˇckovi´c, and Pietro Liò. Sheaf Neural Networks with Connection Laplacians, June 2022
work page 2022
-
[10]
T-SNE Exaggerates Clusters, Provably, 2025
Noah Bergam, Szymon Snoeck, and Nakul Verma. T-SNE Exaggerates Clusters, Provably, 2025
work page 2025
-
[11]
Cristian Bodnar, Francesco Di Giovanni, Benjamin Chamberlain, Pietro Lió, and Michael Bron- stein. Neural Sheaf Diffusion: A Topological Perspective on Heterophily and Oversmoothing in GNNs.Advances in Neural Information Processing Systems, 35:18527–18541, December 2022
work page 2022
- [12]
-
[13]
Edoardo Calvello, Nikola B. Kovachki, Matthew E. Levine, and Andrew M. Stuart. Continuum Attention for Neural Operators, December 2025
work page 2025
-
[14]
Ronald R. Coifman and Stéphane Lafon. Diffusion maps.Applied and Computational Harmonic Analysis, 21(1):5–30, July 2006. ISSN 1063-5203. doi: 10.1016/j.acha.2006.04.006
-
[15]
Sheaves, Cosheaves and Applications, December 2014
Justin Curry. Sheaves, Cosheaves and Applications, December 2014
work page 2014
-
[16]
Nonlinear model reduction for operator learning, March 2024
Hamidreza Eivazi, Stefan Wittek, and Andreas Rausch. Nonlinear model reduction for operator learning, March 2024
work page 2024
-
[17]
G. B. Folland.Real Analysis: Modern Techniques and Their Applications. Pure and Applied Mathematics. Wiley, New York, 2nd ed edition, 1999. ISBN 978-0-471-31716-6
work page 1999
-
[18]
Graph Convolutional Networks from the Perspective of Sheaves and the Neural Tangent Kernel
Thomas Gebhart. Graph Convolutional Networks from the Perspective of Sheaves and the Neural Tangent Kernel. InProceedings of Topological, Algebraic, and Geometric Learning Workshops 2022, pages 124–132. PMLR, November 2022
work page 2022
-
[19]
Springer International Publishing, Cham, 2023
Benyamin Ghojogh, Mark Crowley, Fakhri Karray, and Ali Ghodsi.Elements of Dimensionality Reduction and Manifold Learning. Springer International Publishing, Cham, 2023. ISBN 978-3-031-10601-9 978-3-031-10602-6. doi: 10.1007/978-3-031-10602-6
-
[20]
Sheaf Neural Networks, December 2020
Jakob Hansen and Thomas Gebhart. Sheaf Neural Networks, December 2020
work page 2020
-
[21]
James R. Holton and Gregory J. Hakim.An Introduction to Dynamic Meteorology. 5 edition. ISBN 9780123848666. 10
-
[22]
Siavash Jafarzadeh, Stewart Silling, Ning Liu, Zhongqiang Zhang, and Yue Yu. Peridynamic Neural Operators: A Data-Driven Nonlocal Constitutive Model for Complex Material Responses, January 2024
work page 2024
-
[23]
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural Operator: Learning Maps Between Function Spaces With Applications to PDEs.Journal of Machine Learning Research, 24(89):1–97, 2023. ISSN 1533-7928
work page 2023
-
[24]
Jussi Leinonen, Boris Bonev, Thorsten Kurth, and Yair Cohen. Modulated Adaptive Fourier Neural Operators for Temporal Interpolation of Weather Forecasts, October 2024
work page 2024
-
[25]
Neural Operator: Graph Kernel Network for Partial Differential Equations, March 2020
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural Operator: Graph Kernel Network for Partial Differential Equations, March 2020
work page 2020
-
[26]
Fourier Neural Operator for Parametric Partial Differential Equations, May 2021
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier Neural Operator for Parametric Partial Differential Equations, May 2021
work page 2021
-
[27]
Yiyi Liao, Yue Wang, and Yong Liu. Graph Regularized Auto-Encoders for Image Representa- tion.IEEE Transactions on Image Processing, 26(6):2839–2852, June 2017. ISSN 1941-0042. doi: 10.1109/TIP.2016.2605010
-
[28]
Zhexuan Liu, Rong Ma, and Yiqiao Zhong. Assessing and improving reliability of neighbor embedding methods: A map-continuity perspective.Nature Communications, 16(1):5037, May
-
[29]
doi: 10.1038/s41467-025-60434-9
ISSN 2041-1723. doi: 10.1038/s41467-025-60434-9
-
[30]
Lu Lu, Pengzhan Jin, and George Em Karniadakis. DeepONet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators. Nature Machine Intelligence, 3(3):218–229, March 2021. ISSN 2522-5839. doi: 10.1038/ s42256-021-00302-5
work page 2021
-
[31]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction, September 2020
Leland McInnes, John Healy, and James Melville. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction, September 2020
work page 2020
-
[32]
Vivek Oommen, Aniruddha Bora, Zhen Zhang, and George Em Karniadakis. Integrating Neural Operators with Diffusion Models Improves Spectral Representation in Turbulence Modeling, February 2025
work page 2025
-
[33]
Seidman, Georgios Kissas, George J
Jacob H. Seidman, Georgios Kissas, George J. Pappas, and Paris Perdikaris. Variational Autoencoding Neural Operators. https://arxiv.org/abs/2302.10351v1, February 2023
-
[34]
Spatially aware dimension reduction for spatial transcriptomics
Lulu Shang and Xiang Zhou. Spatially aware dimension reduction for spatial transcriptomics. Nature Communications, 13(1):7203, November 2022. ISSN 2041-1723. doi: 10.1038/ s41467-022-34879-1
work page 2022
-
[35]
Vector Diffusion Maps and the Connection Laplacian, February 2011
Amit Singer and Hau-tieng Wu. Vector Diffusion Maps and the Connection Laplacian, February 2011
work page 2011
-
[36]
Visualizing Data using t-SNE.Journal of Machine Learning Research, 9(86):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing Data using t-SNE.Journal of Machine Learning Research, 9(86):2579–2605, 2008. ISSN 1533-7928
work page 2008
-
[37]
D. C. Van Essen, K. Ugurbil, E. Auerbach, D. Barch, T. E. J. Behrens, R. Bucholz, A. Chang, L. Chen, M. Corbetta, S. W. Curtiss, S. Della Penna, D. Feinberg, M. F. Glasser, N. Harel, A. C. Heath, L. Larson-Prior, D. Marcus, G. Michalareas, S. Moeller, R. Oostenveld, S. E. Petersen, F. Prior, B. L. Schlaggar, S. M. Smith, A. Z. Snyder, J. Xu, E. Yacoub, an...
-
[38]
Philip D. Waggoner. Modern Dimension Reduction.Elements in Quantitative and Computa- tional Methods for the Social Sciences, July 2021. doi: 10.1017/9781108981767. 11
-
[39]
Seidman, Shyam Sankaran, Hanwen Wang, George J
Sifan Wang, Jacob H. Seidman, Shyam Sankaran, Hanwen Wang, George J. Pappas, and P. Perdikaris. CViT: Continuous Vision Transformer for Operator Learning. InInternational Conference on Learning Representations, May 2024
work page 2024
-
[40]
Latent Neural Operator for Solving Forward and Inverse PDE Problems, December 2024
Tian Wang and Chuang Wang. Latent Neural Operator for Solving Forward and Inverse PDE Problems, December 2024
work page 2024
-
[41]
Super-Resolution Neural Operator, March 2023
Min Wei and Xuesong Zhang. Super-Resolution Neural Operator, March 2023. A Sheaves, Cellular Sheaves, and Sheaf Neural Networks A.1 Sheaves and Restriction Maps Let X be a topological space. A presheaf F assigns to every open set U⊆X a vector space F(U) , whose elements are called sections over U. Intuitively, these sections represent data or signals defi...
work page 2023
-
[42]
This corresponds to the setup of Model 2 in the later discussed ablation study
Choices given in the table refer to the model used in the experimental part on ERA5 data (Section 4). This corresponds to the setup of Model 2 in the later discussed ablation study. The final model as well as all models in the ablation study have been trained with an initial learning rate of 0.00001; a learning rate scheduler (applying a factor of 0.5 eve...
-
[43]
All models have been trained on a NVIDIA GeForce RTX 3090 GPU. Table 5: Parameter sweep. ModelW KW TTraining Loss Validation Loss Training (min.) Model 1 16 16 3 44.608 38.350 20 Model 2 64 16 3 39.347 33.026 44 Model 3 16 64 3 44.418 38.127 32 Model 4 64 64 3 39.232 33.471 56 Model 5 16 16 6 44.972 38.802 36 Model 6 64 16 6 40.305 33.990 81 Model 7 16 64...
-
[44]
Latter one also includes the Pearson correlation coefficient between featuresyi in high-dimensional andz i embedding-space. 16 Table 6: Patch stitching errors compared across model configurations. Model Region normalization Neighbor normalization Model 1 0.829 ±0.04221.976±1.398 Model 2 0.829 ±0.044 21.992±1.345 Model 3 0.829 ±0.04221.976±1.398 Model 4 0....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.