DRIFT: A Benchmark for Task-Free Continual Graph Learning with Continuous Distribution Shifts
Pith reviewed 2026-06-30 21:46 UTC · model grok-4.3
The pith
Continual graph learning methods degrade sharply when task boundaries are removed and distributions drift continuously.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
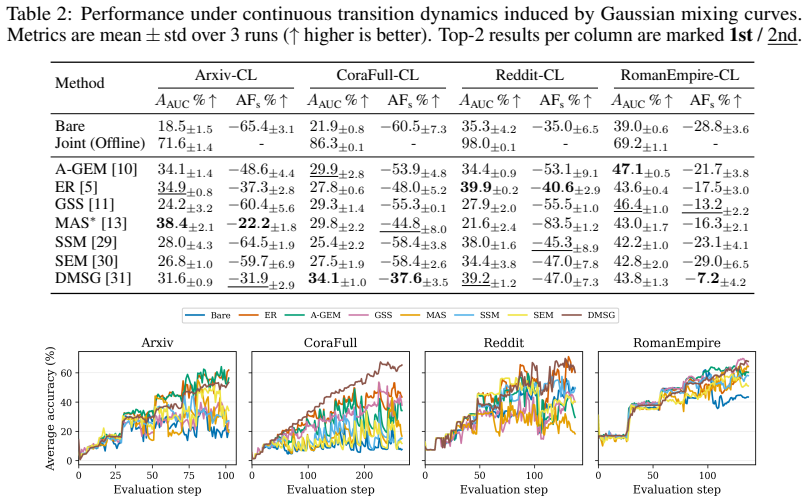
We propose a unified formulation that models the data stream as a time-varying mixture of latent task distributions with Gaussian parameterization, enabling continuous modeling of distribution drift. Based on this formulation, we construct DRIFT, a benchmark spanning hard task switches to smooth distributional drift. Evaluation of representative methods reveals substantial performance degradation compared to task-based protocols, indicating that many existing approaches implicitly rely on task boundary information.
What carries the argument
The unified formulation modeling the data stream as a time-varying mixture of latent task distributions with Gaussian parameterization, which produces the DRIFT benchmark by varying transition dynamics.
If this is right
- Many existing continual graph learning approaches implicitly rely on task boundary information.
- Performance of representative methods drops substantially once task identities and boundaries are removed.
- Continual graph learning must be studied under realistic non-stationary conditions without pre-defined tasks.
- The DRIFT benchmark supplies a standardized way to measure methods across a spectrum of distribution-shift speeds.
Where Pith is reading between the lines
- New algorithms may need explicit mechanisms for detecting and adapting to gradual drift without waiting for discrete task signals.
- The benchmark could be extended to other graph modalities such as temporal knowledge graphs or dynamic social networks to test generality.
- Methods that succeed on DRIFT might also improve robustness in non-graph continual learning settings with unlabeled distribution shifts.
Load-bearing premise
The Gaussian-parameterized time-varying mixture captures the essential characteristics of real-world continual graph learning scenarios.
What would settle it
Run the same set of methods on DRIFT streams while explicitly supplying task boundary signals; if performance remains comparable to the task-free case, the claim that methods implicitly depend on boundaries would not hold.
Figures




read the original abstract
Continual graph learning (CGL) aims to learn from dynamically evolving graphs while mitigating catastrophic forgetting. Existing CGL approaches typically adopt a task-based formulation, where the data stream is partitioned into a sequence of discrete tasks with pre-defined boundaries. However, such assumptions rarely hold in real-world environments, where data distributions evolve continuously and task identity is often unavailable. To better reflect realistic non-stationary environments, we revisit continual graph learning from a task-free perspective. We propose a unified formulation that models the data stream as a time-varying mixture of latent task distributions, enabling continuous modeling of distribution drift. Based on this formulation, we construct \emph{DRIFT}, a benchmark that spans a spectrum of transition dynamics ranging from hard task switches to smooth distributional drift through a Gaussian parameterization. We evaluate representative continual learning methods under this task-free setting and observe substantial performance degradation compared to traditional task-based protocols. Our findings indicate that many existing approaches implicitly rely on task boundary information and struggle under realistic task-free graph streams. This work highlights the importance of studying continual graph learning under realistic non-stationary conditions and provides a benchmark for future research in this direction. Our code is available at https://github.com/UConn-DSIS/DRIFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing continual graph learning (CGL) methods implicitly rely on task-boundary information and exhibit substantial performance degradation under realistic task-free settings with continuous distribution shifts. It introduces a unified formulation modeling the data stream as a time-varying mixture of latent task distributions, constructs the DRIFT benchmark via Gaussian parameterization to span hard switches to smooth drifts, evaluates representative methods showing worse results than task-based protocols, and releases code to support future work on non-stationary graph streams.
Significance. If the central claim holds, the work is significant for shifting CGL research toward task-free protocols and supplying a controllable benchmark that covers a spectrum of drift dynamics; the public code release is a clear strength that enables reproducibility. The result would be more impactful if the Gaussian mixture construction is shown to reproduce key statistics of real citation or social graphs rather than remaining a modeling choice.
major comments (2)
- [Abstract and unified formulation section] The central claim that performance gaps demonstrate implicit boundary dependence rests on DRIFT faithfully modeling real-world graph streams (§ formulation and benchmark construction). The Gaussian parameterization of time-varying mixtures is presented as capturing the essential characteristics, yet no validation is given against empirical drift statistics (e.g., abrupt topology changes or non-Gaussian feature evolution) from citation networks or social graphs; if the synthetic transitions differ systematically, the observed degradation may be an artifact of the construction rather than evidence against existing methods.
- [Experimental results] Table or figure reporting quantitative results (mentioned in abstract as showing substantial degradation): the abstract states degradation relative to task-based protocols but provides no concrete metrics, baselines, or statistical significance; without these numbers it is impossible to assess whether the gaps are large enough to support the strong conclusion that methods “struggle under realistic task-free graph streams.”
minor comments (2)
- [Formulation] Notation for the time-varying mixture and Gaussian transition parameters should be introduced with explicit equations rather than prose description to allow readers to reproduce the exact drift schedules.
- [Benchmark description] The abstract claims the benchmark “spans a spectrum” but does not list the specific transition parameter values or number of drift regimes used; adding a small table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight important aspects of our benchmark construction and presentation of results. We provide point-by-point responses below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and unified formulation section] The central claim that performance gaps demonstrate implicit boundary dependence rests on DRIFT faithfully modeling real-world graph streams (§ formulation and benchmark construction). The Gaussian parameterization of time-varying mixtures is presented as capturing the essential characteristics, yet no validation is given against empirical drift statistics (e.g., abrupt topology changes or non-Gaussian feature evolution) from citation networks or social graphs; if the synthetic transitions differ systematically, the observed degradation may be an artifact of the construction rather than evidence against existing methods.
Authors: We agree that direct validation of the Gaussian mixture model against empirical statistics from real-world graphs would strengthen the connection to realistic scenarios. The DRIFT benchmark is intentionally designed as a synthetic, controllable testbed using Gaussian parameterization to systematically vary drift dynamics from hard switches to smooth drifts, allowing isolation of the effects of continuous distribution shifts without task boundaries. The unified formulation itself is distribution-agnostic. While we do not claim exact replication of specific real datasets, the construction enables reproducible study of the task-free setting. In the revision, we will expand the discussion section to explicitly acknowledge this modeling choice as a limitation and suggest future directions for calibrating to real graph statistics. revision: partial
-
Referee: [Experimental results] Table or figure reporting quantitative results (mentioned in abstract as showing substantial degradation): the abstract states degradation relative to task-based protocols but provides no concrete metrics, baselines, or statistical significance; without these numbers it is impossible to assess whether the gaps are large enough to support the strong conclusion that methods “struggle under realistic task-free graph streams.”
Authors: The experimental section of the manuscript presents detailed quantitative results, including tables with performance metrics for various methods under both task-based and task-free protocols on the DRIFT benchmark, along with comparisons and analysis. Due to space limitations, the abstract provides a high-level summary. To improve clarity, we will revise the abstract to include specific example metrics demonstrating the degradation (e.g., average accuracy drops across methods). revision: yes
Circularity Check
No circularity detected in benchmark construction or claims
full rationale
The paper constructs DRIFT explicitly from a proposed unified formulation (time-varying mixture of latent tasks with Gaussian parameterization) and then reports empirical degradation of existing methods on that benchmark. This is a standard synthetic benchmark design rather than a derivation that reduces to its own inputs by construction. No load-bearing self-citations, fitted parameters renamed as predictions, or uniqueness theorems appear in the abstract or described chain. The observed performance gaps are direct consequences of the benchmark definition, not circularly forced results. The work is self-contained as an empirical evaluation tool.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the Gaussian parameterization
axioms (1)
- domain assumption The data stream in continual graph learning can be modeled as a time-varying mixture of latent task distributions
Reference graph
Works this paper leans on
-
[1]
Inductive representation learning on large graphs
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[2]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020
2020
-
[3]
Knowledge graph embedding: A survey of approaches and applications.IEEE transactions on knowledge and data engineering, 29:2724– 2743, 2017
Quan Wang, Zhendong Mao, Bin Wang, and Li Guo. Knowledge graph embedding: A survey of approaches and applications.IEEE transactions on knowledge and data engineering, 29:2724– 2743, 2017
2017
-
[4]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[5]
On Tiny Episodic Memories in Continual Learning
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajanthan, Puneet K Dokania, Philip HS Torr, and Marc’Aurelio Ranzato. On tiny episodic memories in continual learning.arXiv preprint arXiv:1902.10486, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[6]
Cglb: Benchmark tasks for continual graph learning.Advances in Neural Information Processing Systems, 35:13006–13021, 2022
Xikun Zhang, Dongjin Song, and Dacheng Tao. Cglb: Benchmark tasks for continual graph learning.Advances in Neural Information Processing Systems, 35:13006–13021, 2022
2022
-
[7]
Temporal Graph Networks for Deep Learning on Dynamic Graphs
Emanuele Rossi, Ben Chamberlain, Fabrizio Frasca, Davide Eynard, Federico Monti, and Michael Bronstein. Temporal graph networks for deep learning on dynamic graphs.arXiv preprint arXiv:2006.10637, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[8]
Online continual learning on class incremental blurry task configuration with anytime inference
Hyunseo Koh, Dahyun Kim, Jung-Woo Ha, and Jonghyun Choi. Online continual learning on class incremental blurry task configuration with anytime inference. InInternational Conference on Learning Representations, 2022
2022
-
[9]
Online class incremental learning on stochastic blurry task boundary via mask and visual prompt tuning
Jun-Yeong Moon, Keon-Hee Park, Jung Uk Kim, and Gyeong-Moon Park. Online class incremental learning on stochastic blurry task boundary via mask and visual prompt tuning. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11731–11741, 2023
2023
-
[10]
Efficient Lifelong Learning with A-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-gem.arXiv preprint arXiv:1812.00420, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Gradient based sample selection for online continual learning.Advances in neural information processing systems, 32, 2019
Rahaf Aljundi, Min Lin, Baptiste Goujaud, and Yoshua Bengio. Gradient based sample selection for online continual learning.Advances in neural information processing systems, 32, 2019
2019
-
[12]
Dark experience for general continual learning: a strong, simple baseline.Advances in neural information processing systems, 33:15920–15930, 2020
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. Dark experience for general continual learning: a strong, simple baseline.Advances in neural information processing systems, 33:15920–15930, 2020
2020
-
[13]
Task-free continual learning
Rahaf Aljundi, Klaas Kelchtermans, and Tinne Tuytelaars. Task-free continual learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11254–11263, 2019. 10
2019
-
[14]
Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
2017
-
[15]
Continual learning on dynamic graphs via parameter isolation
Peiyan Zhang, Yuchen Yan, Chaozhuo Li, Senzhang Wang, Xing Xie, Guojie Song, and Sunghun Kim. Continual learning on dynamic graphs via parameter isolation. InProceedings of the 46th international ACM SIGIR conference on research and development in information retrieval, pages 601–611, 2023
2023
-
[16]
Online continual learning in image classification: An empirical survey.Neurocomputing, 469:28–51, 2022
Zheda Mai, Ruiwen Li, Jihwan Jeong, David Quispe, Hyunwoo Kim, and Scott Sanner. Online continual learning in image classification: An empirical survey.Neurocomputing, 469:28–51, 2022
2022
-
[17]
A topology-aware graph coarsening framework for continual graph learning.Advances in Neural Information Processing Systems, 37:132491– 132523, 2024
Xiaoxue Han, Zhuo Feng, and Yue Ning. A topology-aware graph coarsening framework for continual graph learning.Advances in Neural Information Processing Systems, 37:132491– 132523, 2024
2024
-
[18]
Topology-aware embedding memory for continual learning on expanding networks
Xikun Zhang, Dongjin Song, Yixin Chen, and Dacheng Tao. Topology-aware embedding memory for continual learning on expanding networks. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4326–4337, 2024
2024
-
[19]
Hierarchical prototype networks for continual graph representation learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4622–4636, 2022
Xikun Zhang, Dongjin Song, and Dacheng Tao. Hierarchical prototype networks for continual graph representation learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4622–4636, 2022
2022
-
[20]
Guiquan Sun, Xikun Zhang, Jingchao Ni, and Dongjin Song. Hero: Heterogeneous continual graph learning via meta-knowledge distillation.arXiv preprint arXiv:2505.17458, 2025
-
[21]
Cat: Balanced continual graph learning with graph condensation
Yilun Liu, Ruihong Qiu, and Zi Huang. Cat: Balanced continual graph learning with graph condensation. In2023 IEEE International Conference on Data Mining (ICDM), pages 1157–
-
[22]
Lifelong graph learning
Chen Wang, Yuheng Qiu, Dasong Gao, and Sebastian Scherer. Lifelong graph learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13719–13728, 2022
2022
-
[23]
Replay-and-forget-free graph class- incremental learning: A task profiling and prompting approach.Advances in Neural Information Processing Systems, 37:87978–88002, 2024
Chaoxi Niu, Guansong Pang, Ling Chen, and Bing Liu. Replay-and-forget-free graph class- incremental learning: A task profiling and prompting approach.Advances in Neural Information Processing Systems, 37:87978–88002, 2024
2024
-
[24]
Class-domain incremental learning on graphs via disentangled knowledge distillation
Qin Tian, Chen Zhao, Xintao Wu, Dong Li, Minglai Shao, Xujiang Zhao, and Wenjun Wang. Class-domain incremental learning on graphs via disentangled knowledge distillation. In Proceedings of the ACM Web Conference 2026, pages 452–462, 2026
2026
-
[25]
What matters in graph class incremental learning? an information preservation perspective.Advances in Neural Information Processing Systems, 37:26195–26223, 2024
Jialu Li, Yu Wang, Pengfei Zhu, Wanyu Lin, and Qinghua Hu. What matters in graph class incremental learning? an information preservation perspective.Advances in Neural Information Processing Systems, 37:26195–26223, 2024
2024
-
[26]
Overcoming catastrophic forgetting in graph neural networks with experience replay
Fan Zhou and Chengtai Cao. Overcoming catastrophic forgetting in graph neural networks with experience replay. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 4714–4722, 2021
2021
-
[27]
Streaming graph neural networks via continual learning
Junshan Wang, Guojie Song, Yi Wu, and Liang Wang. Streaming graph neural networks via continual learning. InProceedings of the 29th ACM international conference on information & knowledge management, pages 1515–1524, 2020
2020
-
[28]
Overcoming catastrophic forgetting in graph neural networks
Huihui Liu, Yiding Yang, and Xinchao Wang. Overcoming catastrophic forgetting in graph neural networks. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 8653–8661, 2021
2021
-
[29]
Sparsified subgraph memory for continual graph representation learning
Xikun Zhang, Dongjin Song, and Dacheng Tao. Sparsified subgraph memory for continual graph representation learning. In2022 IEEE International Conference on Data Mining (ICDM), pages 1335–1340. IEEE, 2022. 11
2022
-
[30]
Ricci curvature-based graph sparsification for continual graph representation learning.IEEE Transactions on Neural Networks and Learning Systems, 35(12):17398–17410, 2023
Xikun Zhang, Dongjin Song, and Dacheng Tao. Ricci curvature-based graph sparsification for continual graph representation learning.IEEE Transactions on Neural Networks and Learning Systems, 35(12):17398–17410, 2023
2023
-
[31]
Towards continuous reuse of graph models via holistic memory diversification
Ziyue Qiao, Junren Xiao, Qingqiang Sun, Meng Xiao, Xiao Luo, and Hui Xiong. Towards continuous reuse of graph models via holistic memory diversification. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[32]
Xikun Zhang, Dongjin Song, and Dacheng Tao. Continual learning on graphs: Challenges, solutions, and opportunities.arXiv preprint arXiv:2402.11565, 2024
-
[33]
Online continual graph learning.arXiv preprint arXiv:2508.03283, 2025
Giovanni Donghi, Luca Pasa, Daniele Zambon, Cesare Alippi, and Nicolò Navarin. Online continual graph learning.arXiv preprint arXiv:2508.03283, 2025
-
[34]
Inductive representation learning on temporal graphs.arXiv preprint arXiv:2002.07962, 2020
Da Xu, Chuanwei Ruan, Evren Korpeoglu, Sushant Kumar, and Kannan Achan. Inductive representation learning on temporal graphs.arXiv preprint arXiv:2002.07962, 2020
-
[35]
Dysat: Deep neural representation learning on dynamic graphs via self-attention networks
Aravind Sankar, Yanhong Wu, Liang Gou, Wei Zhang, and Hao Yang. Dysat: Deep neural representation learning on dynamic graphs via self-attention networks. InProceedings of the 13th international conference on web search and data mining, pages 519–527, 2020
2020
-
[36]
Simulating task-free continual learning streams from existing datasets
Aristotelis Chrysakis and Marie-Francine Moens. Simulating task-free continual learning streams from existing datasets. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2516–2524, 2023
2023
-
[37]
Andrew McCallum, Kamal Nigam, Jason D. M. Rennie, and Kristie Seymore. Automating the construction of internet portals with machine learning.Information Retrieval, 3:127–163, 2000
2000
-
[38]
A critical look at the evaluation of GNNs under heterophily: Are we re- ally making progress? InThe Eleventh International Conference on Learning Representations, 2023
Oleg Platonov, Denis Kuznedelev, Michael Diskin, Artem Babenko, and Liudmila Prokhorenkova. A critical look at the evaluation of GNNs under heterophily: Are we re- ally making progress? InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[39]
Be- yond homophily in graph neural networks: Current limitations and effective designs.Advances in neural information processing systems, 33:7793–7804, 2020
Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. Be- yond homophily in graph neural networks: Current limitations and effective designs.Advances in neural information processing systems, 33:7793–7804, 2020
2020
-
[40]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[41]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. Advances in neural information processing systems, 30, 2017
2017
-
[42]
Memory aware synapses: Learning what (not) to forget
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuyte- laars. Memory aware synapses: Learning what (not) to forget. InProceedings of the European conference on computer vision (ECCV), pages 139–154, 2018. 12 A Details of DRIFT Benchmark A.1 Details of Benchmark Baselines A brief introduction of the implemented Continual Le...
2018
-
[43]
Therefore, this can be viewed as the lower bound on the continual learning performance
Bare modeldenotes the backbone GNN without the continual learning technique. Therefore, this can be viewed as the lower bound on the continual learning performance
-
[44]
We use Reservoir Sampling to select nodes
A-GEM [10]is an efficient version of GEM [ 41], which ensures that the average loss for historical tasks does not increase by projecting the gradient of incoming data onto the orthogonal space of the gradient of historical data. We use Reservoir Sampling to select nodes
-
[45]
New incoming batches for training are then augmented with nodes sampled uniformly from the buffer
Experience Replay (ER) [ 5]selects nodes from the incoming batch to be stored in the memory buffer by Reservoir Sampling, which is a simple yet effective method for CL. New incoming batches for training are then augmented with nodes sampled uniformly from the buffer
-
[46]
Specifically, it maintains samples whose gradients are less aligned with those already stored in the memory buffer, thereby promoting gradient diversity and reducing redundancy
Gradient-based Sample Selection (GSS) [ 11]selects representative samples from the incoming data stream by measuring the diversity of their gradients. Specifically, it maintains samples whose gradients are less aligned with those already stored in the memory buffer, thereby promoting gradient diversity and reducing redundancy. New batches for training are...
-
[47]
Memory Aware Synapses (MAS)* [13]is a task-free version of MAS [ 42], which adds a detector guiding the model when to update the important weights in a streaming fashion
-
[48]
It constructs sparsified subgraphs by selecting important nodes based on their contribution to the graph topology to reduce redundancy
Sparsified Subgraph Memory (SSM) [ 29]stores representative subgraphs instead of individual nodes to preserve both structural and feature information. It constructs sparsified subgraphs by selecting important nodes based on their contribution to the graph topology to reduce redundancy. Reservoir sampling is used as the sampling strategy
-
[49]
Subgraph Episodic Memory (SEM) [30]extends subgraph-based memory by introducing a curvature-guided sparsification mechanism. It constructs Subgraph Episodic Memory (SEM) to store computation subgraphs, and further prunes edges based on Ricci curvature to preserve the most informative topological relationships for message passing. This approach reduces red...
-
[50]
Roman Empire
Diversified Memory Selection and Generation (DMSG) [31]maintains a diversified mem- ory buffer by jointly considering intra- and inter-class diversity when selecting samples. To adequately reuse the knowledge preserved in the buffer, it utilizes a variational layer to gen- erate the distribution of buffer node embeddings and sample synthesized ones for re...
-
[51]
Optimization details.All experiments use Adam with learning rate 5×10 −3
We do not use dropout or batch normalization. Optimization details.All experiments use Adam with learning rate 5×10 −3. The mini-batch size is fixed at B=10. Each incoming batch is processed for one epoch before the next batch arrives. No learning-rate scheduling, gradient clipping, or warm-up is applied. Method-specific settings.Whenever possible, we fol...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.