DualKV: Shared-Prompt Flash Attention for Efficient RL Training with Large Rollouts and Long Contexts
Pith reviewed 2026-05-19 15:44 UTC · model grok-4.3
The pith
DualKV processes shared prompts only once in FlashAttention for RL training by exploiting causal masking invariance, matching standard attention exactly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DualKV is mathematically equivalent to standard attention and introduces no approximation. It achieves this by using fused CUDA kernels that process two disjoint KV regions in one launch: the shared prompt context once and the per-sequence responses individually, paired with a data-pipeline redesign that repacks tokens to extend the savings beyond attention to the full model.
What carries the argument
Fused CUDA forward and backward kernels iterating over shared context and per-sequence response KV regions, enabled by prompt representation invariance under causal masking.
If this is right
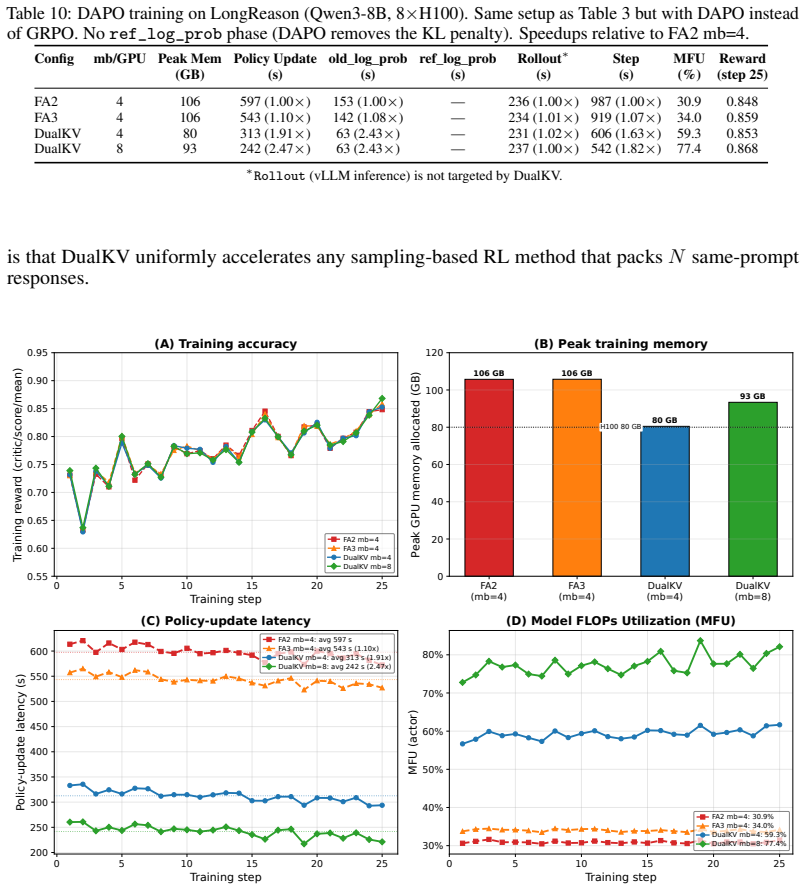
- 1.63–2.09× policy-update speedup on Qwen3-8B GRPO with N=32 and 8K context
- Enables 2× larger micro-batches
- Raises MFU from 36% to 76%
- Achieves 3.82× policy-update and 3.38× end-to-end speedup at 30B MoE scale
Where Pith is reading between the lines
- The same invariance could be exploited in inference for batched requests with common prefixes
- Data repacking might benefit other sequence-parallel training setups
- Future kernels could generalize this to variable prompt lengths or mixed shared contexts
Load-bearing premise
Causal masking in decoder-only models makes prompt representations invariant across sequences at every layer.
What would settle it
Compute prompt hidden states in a multi-response batch and compare them to states from isolated single-response forward passes; exact match would confirm the invariance.
Figures








read the original abstract
Modern RL post-training methods such as GRPO and DAPO train on $N$ response sequences of $R$ tokens sampled from a shared prompt of $P$ tokens, but standard FlashAttention replicates all $P$ prompt tokens $N$ times across both forward and backward passes -- duplicating compute and memory on identical hidden states. In large-rollout, long-context RL training ($N{\geq}16$, $P{\geq}8\text{K}$), this redundancy dominates the policy update cost. We observe that in decoder-only models, causal masking makes prompt representations invariant across sequences at every layer, so all per-token operations (norms, projections, MLP) and attention can process the prompt once -- a property not yet exploited at the kernel level for training. We propose \textbf{DualKV}, the first FlashAttention kernel variant that eliminates shared-prompt replication during RL training, via (1)~fused CUDA forward and backward kernels that iterate over two disjoint KV regions -- shared context and per-sequence response -- in a single kernel launch, and (2)~a data-pipeline redesign in veRL that repacks $N(P{+}R)$ tokens into $P{+}NR$ tokens per micro-batch, extending the token reduction from attention to the entire model by a factor $\rho = N(P{+}R)/(P{+}NR)$. DualKV is mathematically equivalent to standard attention and introduces no approximation. On Qwen3-8B GRPO training with 8$\times$H100 GPUs ($N{=}32$, 8K-context), DualKV achieves $1.63$--$2.09\times$ policy-update speedup, enables $2\times$ larger micro-batches, and raises MFU from $36\%$ to $76\%$. Similar gains hold for DAPO ($2.47\times$ speedup, $77\%$ MFU). At 30B MoE scale on 16$\times$H100, DualKV achieves $3.82\times$ policy-update and $3.38\times$ end-to-end step speedup over FlashAttention (which requires 4-way Ulysses sequence parallelism to avoid OOM).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DualKV, a FlashAttention variant for RL post-training (e.g., GRPO, DAPO) that exploits causal masking in decoder-only models to process shared prompt tokens only once across N rollouts. It introduces fused CUDA forward/backward kernels handling disjoint shared-prompt KV and per-sequence response KV regions in one launch, plus a veRL data repacking that reduces tokens from N(P+R) to P+NR. The method claims exact mathematical equivalence to standard attention with no approximation, and reports 1.63–2.09× policy-update speedups, 2× larger micro-batches, and MFU gains from 36% to 76% on Qwen3-8B (N=32, 8K context) with similar or larger gains at 30B MoE scale.
Significance. If the equivalence and kernel correctness hold, the work addresses a real redundancy in large-rollout RL training that dominates policy-update cost for N≥16 and long contexts. Concrete wall-clock and MFU numbers on named models/hardware, plus the parameter-free nature of the speedup (no fitted constants), strengthen the practical contribution. The extension of token reduction beyond attention to the full model via repacking is a notable engineering strength.
major comments (2)
- [§3.2] §3.2 (invariance argument): The induction that prompt hidden states remain identical across sequences at every layer is load-bearing for the equivalence claim. The manuscript should explicitly state the base case (shared embeddings + causal mask on prompt prefix) and inductive step (token-wise ops + attention only to prior prompt tokens), including whether this holds under all common variants such as grouped-query attention or RoPE.
- [§4.3] §4.3 (backward kernel): The fused backward pass description does not detail how gradients for the shared prompt KV are accumulated across the N sequences before the single write-back. Because this accumulation is required for exact equivalence to the replicated standard attention backward, an explicit equation or pseudocode step showing the reduction is needed.
minor comments (3)
- [Table 1] Table 1: the MFU column for the baseline should also report the sequence-parallelism configuration used (Ulysses 4-way) to make the 3.82× comparison at 30B scale directly interpretable.
- [Figure 3] Figure 3 caption: the x-axis label 'effective batch size' is ambiguous; clarify whether it refers to micro-batch token count before or after repacking.
- [Abstract] The abstract states 'DualKV is mathematically equivalent to standard attention and introduces no approximation.' This sentence should be repeated verbatim in the conclusion or §5 for emphasis.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation of minor revision. We address each major comment below and have revised the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [§3.2] §3.2 (invariance argument): The induction that prompt hidden states remain identical across sequences at every layer is load-bearing for the equivalence claim. The manuscript should explicitly state the base case (shared embeddings + causal mask on prompt prefix) and inductive step (token-wise ops + attention only to prior prompt tokens), including whether this holds under all common variants such as grouped-query attention or RoPE.
Authors: We agree that an explicit base case and inductive step will strengthen the presentation of the equivalence claim. In the revised manuscript we have expanded §3.2 to state: Base case—at layer 0 the shared prompt embeddings are identical across sequences and the causal mask restricts each prompt token to attend only to preceding prompt tokens. Inductive step—given identical prompt hidden states at layer ℓ, all subsequent token-wise operations (RMSNorm, linear projections, MLP) and the attention computation (which references only prior prompt KV under causality) produce identical states at layer ℓ+1. The argument holds for grouped-query attention because the KV grouping is applied uniformly to the shared prompt, and for RoPE because rotary embeddings for the prompt prefix depend only on the same absolute positions in every rollout. The updated section now contains this full inductive argument. revision: yes
-
Referee: [§4.3] §4.3 (backward kernel): The fused backward pass description does not detail how gradients for the shared prompt KV are accumulated across the N sequences before the single write-back. Because this accumulation is required for exact equivalence to the replicated standard attention backward, an explicit equation or pseudocode step showing the reduction is needed.
Authors: We acknowledge that the backward-kernel description would benefit from an explicit reduction step. In the revised §4.3 we have added pseudocode and a short equation showing that, for each prompt position p, the gradient is accumulated as grad_KV_prompt[p] = ∑_{i=1}^N grad_KV_from_sequence_i[p] before the single write-back to global memory. This summation is performed in shared memory within the fused kernel and guarantees that the resulting gradient matches the sum obtained from N independent standard-attention backward passes, preserving exact equivalence. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central claim rests on the standard property that causal masking in decoder-only models renders prompt hidden states identical across rollouts at every layer by induction (shared embeddings, causal attention limited to prior prompt tokens, and token-wise operations like norms and MLPs). This invariance is an architectural consequence, not a fitted input or self-definition, and DualKV implements the identical computation graph with no approximation. Performance numbers are measured directly from benchmark runs on Qwen3-8B and 30B MoE models rather than any equation that reduces to its own inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the derivation; the token reduction factor ρ is a direct algebraic consequence of the repacking P + NR, not a renamed prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal masking in decoder-only models makes prompt representations invariant across sequences at every layer
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.