The Neural Tangent Kernel for Classification
Pith reviewed 2026-06-30 18:50 UTC · model grok-4.3
The pith
Wide neural networks stay in the lazy regime for cross-entropy when regularized or targets are non-degenerate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the infinite-width limit, wide neural networks trained on classification losses remain in the lazy training regime when either parameter-space regularization is applied or when the target distributions are non-degenerate, meaning every class has positive probability. This constancy of the NTK allows training to be approximated by the linearized model, which yields an explicit characterization of the trained predictor in terms of the NTK. The distribution of such predictors over random initializations can be related to Bayesian posterior predictive distributions.
What carries the argument
The Neural Tangent Kernel, shown to remain constant under regularization or non-degenerate targets for cross-entropy loss, which enables linearization of the training dynamics.
If this is right
- Training dynamics for classification become explicitly characterizable using the NTK.
- The trained predictor admits a closed-form expression in terms of the NTK under the stated conditions.
- The distribution of predictors induced by random initialization supplies a concrete notion of model uncertainty that connects to Bayesian methods.
- The lazy-training regime applies to cross-entropy loss once regularization or non-degenerate targets are present.
Where Pith is reading between the lines
- The same conditions may allow generalization bounds for classification to be derived directly from the NTK, mirroring regression results.
- Finite-width networks could be monitored during training to quantify how far they deviate from the constant-NTK regime as a function of regularization strength.
- Similar constancy arguments might extend to other losses that involve nonlinear output maps once appropriate regularization or target conditions are identified.
Load-bearing premise
The network must be in the infinite-width limit so that the NTK remains approximately constant throughout training.
What would settle it
Train a wide but finite network on cross-entropy loss without regularization using targets where at least one class has zero probability and check whether the empirical NTK changes appreciably during training.
Figures




read the original abstract
In wide neural networks, the Neural Tangent Kernel (NTK) remains approximately constant during training, providing a powerful theoretical tool for studying training dynamics, generalization, and connections to kernel methods. However, this theory is largely restricted to regression losses. It was previously thought that training on a classification loss, or more generally losses involving nonlinear output transformations, breaks this property, leading to divergent logits and a breakdown of the linearization. In this paper, we extend NTK theory to classification by identifying conditions under which wide neural networks remain in the lazy training regime. We show that parameter-space regularization ensures a constant NTK during training for cross-entropy loss, while in the absence of regularization the regime is recovered when targets are non-degenerate, i.e. when all classes have strictly positive probability. Under these conditions, training is well-approximated by the linearized model, yielding an explicit characterization of the solution in terms of the NTK. We further analyze the distribution of trained predictors induced by random initialization and relate this notion of model uncertainty to Bayesian methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends Neural Tangent Kernel (NTK) theory, previously limited to regression, to classification with cross-entropy loss. It identifies two conditions under which wide networks remain in the lazy regime with approximately constant NTK: (i) parameter-space regularization, and (ii) non-degenerate targets (all classes having strictly positive probability) without regularization. Under these conditions the training dynamics are well-approximated by the linearized model, yielding an explicit NTK-based characterization of the solution; the work also analyzes the distribution of predictors induced by random initialization and its relation to Bayesian methods.
Significance. If the derivations hold, the result meaningfully broadens the NTK framework to the classification setting that dominates practical applications. The explicit characterization and the Bayesian connection supply new analytic tools for dynamics, generalization, and uncertainty in classification, while the stated conditions clarify when the lazy-regime approximation remains valid.
major comments (2)
- [Main derivation of constant NTK under regularization] The central claim that parameter-space regularization keeps the NTK exactly constant for cross-entropy loss rests on a derivation that must be verified in the main text; without seeing the precise form of the regularizer and the resulting ODE for the kernel, it is impossible to confirm that the constancy is not an artifact of the linearization assumption itself.
- [Section on non-degenerate targets] The non-degenerate-target condition (all classes have strictly positive probability) is invoked to recover the lazy regime without regularization. It is unclear whether this condition is necessary or merely sufficient; a counter-example or a relaxation to weaker positivity requirements would strengthen the result.
minor comments (2)
- Notation for the output transformation and the target distribution should be introduced once and used uniformly; several symbols appear to be redefined between the abstract and the technical sections.
- The discussion relating the induced predictor distribution to Bayesian methods would benefit from an explicit comparison (e.g., to the NTK-GP posterior) rather than a high-level statement.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation of minor revision. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Main derivation of constant NTK under regularization] The central claim that parameter-space regularization keeps the NTK exactly constant for cross-entropy loss rests on a derivation that must be verified in the main text; without seeing the precise form of the regularizer and the resulting ODE for the kernel, it is impossible to confirm that the constancy is not an artifact of the linearization assumption itself.
Authors: We agree that the derivation requires clearer presentation in the main text. The regularizer is the standard squared L2 penalty on the parameters. Under the infinite-width NTK linearization, the gradient flow on the regularized cross-entropy loss yields an ODE in which the kernel remains exactly constant because the parameter updates remain infinitesimal and the feature map is frozen at initialization. We will move the explicit regularizer form and the resulting kernel ODE from the appendix into Section 3 of the main text, together with a short paragraph explaining why the constancy is a direct consequence of the regularized dynamics rather than an artifact of linearization. revision: yes
-
Referee: [Section on non-degenerate targets] The non-degenerate-target condition (all classes have strictly positive probability) is invoked to recover the lazy regime without regularization. It is unclear whether this condition is necessary or merely sufficient; a counter-example or a relaxation to weaker positivity requirements would strengthen the result.
Authors: The condition is stated as sufficient: when every class probability is bounded away from zero, the logits remain bounded and the NTK stays approximately constant. We do not claim necessity. We will add a clarifying paragraph in Section 4 noting that the condition is sufficient for our proof technique and briefly discussing why weaker positivity (e.g., targets that can approach zero) may allow divergence in some cases. A rigorous counter-example demonstrating necessity would require constructing a specific degenerate target distribution for which the lazy regime nevertheless holds; while we can add a short remark on this open direction, a full counter-example lies outside the scope of the present work. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper extends the infinite-width NTK linearization (a standard external assumption) to cross-entropy loss by deriving conditions under which the NTK stays constant: parameter-space regularization or non-degenerate targets. This produces an explicit solution characterization in terms of the NTK. No step reduces by construction to a fitted parameter renamed as prediction, a self-definitional loop, or a load-bearing self-citation chain; the derivation is self-contained against the usual NTK regime and does not import uniqueness theorems or ansatzes from the authors' prior work. The central claim therefore adds independent content rather than renaming or tautologically recovering its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Infinite-width limit keeps NTK constant during training
Reference graph
Works this paper leans on
-
[1]
Richer Bayesian Last Layers with Subsampled NTK Features
Sergio Calvo-Ordoñez, Jonathan Plenk, Richard Bergna, Álvaro Cartea, Yarin Gal, José Miguel Hernández-Lobato, and Kamil Ciosek. Richer bayesian last layers with subsampled ntk features. arXiv preprint arXiv:2602.01279, 2026a. Sergio Calvo-Ordoñez, Jonathan Plenk, Richard Bergna, Álvaro Cartea, José Miguel Hernández- Lobato, Konstantina Palla, and Kamil Ci...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Connall Garrod, Jonathan P Keating, and Christos Thrampoulidis. Diagonalizing the softmax: Hadamard initialization for tractable cross-entropy dynamics.arXiv preprint arXiv:2512.04006,
-
[3]
An unconstrained layer-peeled perspective on neural collapse.arXiv preprint arXiv:2110.02796,
Wenlong Ji, Yiping Lu, Yiliang Zhang, Zhun Deng, and Weijie J Su. An unconstrained layer-peeled perspective on neural collapse.arXiv preprint arXiv:2110.02796,
-
[4]
Gradient descent maximizes the margin of homogeneous neural networks
Kaifeng Lyu and Jian Li. Gradient descent maximizes the margin of homogeneous neural networks. arXiv preprint arXiv:1906.05890,
-
[5]
Gaussian Process Behaviour in Wide Deep Neural Networks
Alexander G de G Matthews, Mark Rowland, Jiri Hron, Richard E Turner, and Zoubin Ghahramani. Gaussian process behaviour in wide deep neural networks.arXiv preprint arXiv:1804.11271,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Tensor programs ii: Neural tangent kernel for any architecture.arXiv preprint arXiv:2006.14548,
Greg Yang. Tensor programs ii: Neural tangent kernel for any architecture.arXiv preprint arXiv:2006.14548,
-
[7]
We are using the Euclidean norm on the K- dimensional output dimension, after applying the Euclidean and spectral norm on the parameter dimensions p and p×p respectively
prove for a standard feedforward neural network (as well as ResNets and CNNs with large number of channels): Lemma 2.1.For any δ0 >0 there are K ′ 1, K′ 2 >0 such that: For every radius R >0 there is large enough layer width n such that with probability 1−δ 0 over random initialization θ0: For any input x∈M d: ∀θ∈B(θ 0, R) :∥J θ(x)∥2,2 ≤K ′ 1,(1) ∀θ∈B(θ 0...
2018
-
[8]
Then fθ0(·) converges in distribution to a Gaussian process with zero mean and covariance given by the NNGP Kernel K: For inputs x1,
prove: Lemma 2.2.Consider random initialization θ0. Then fθ0(·) converges in distribution to a Gaussian process with zero mean and covariance given by the NNGP Kernel K: For inputs x1, . . . ,xN ∈M d, fθ0(x) d − → N(0,K(x,x)).(3) This directly implies that the network values are in a compact set at initialization: Lemma A.1.For any δ0 >0 , there is K ′ 0 ...
2018
-
[9]
(3) Function-space PL∀z∈ S 0 :∥∇ zC(z)∥2 2 ≥2µ C (C(z)−infC)
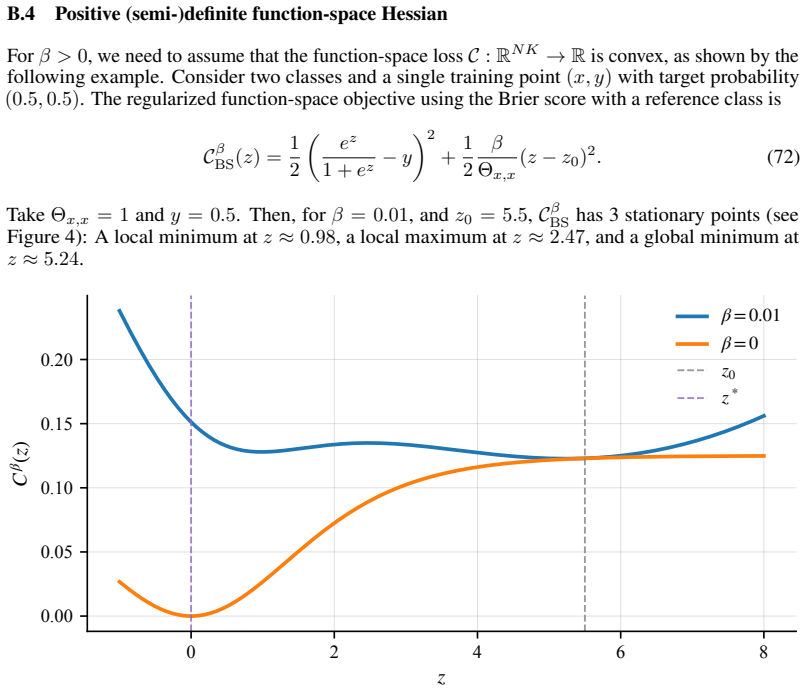
(2) Bounded gradient growth∀z∈ S 0 :∥∇ zC(z)∥2 2 ≤2K 2 (C(z)−infC). (3) Function-space PL∀z∈ S 0 :∥∇ zC(z)∥2 2 ≥2µ C (C(z)−infC). B Properties of the function-space loss In this section we introduce various assumptions on the function-space loss and discuss its properties. Table 1 provides an overview. We write forx 1, . . . ,xN ∈M d: fθ :=f θ(x) := (fθ(x...
2020
-
[10]
(65) Oymak and Soltanolkotabi [2019], Liu et al
2019
-
[11]
[2022], where it was presented for discrete-time gradient descent
Then there are R, c0 >0 such that for large enough layer width n: With probability 1−δ 0 over random initializationθ 0, for allt≥0, d dt θt 2 ≤η 0c0Re−c0η0t and thus∥θ t −θ 0∥2 ≤R.(146) 21 The proof closely follows Oymak and Soltanolkotabi [2019], Liu et al. [2022], where it was presented for discrete-time gradient descent. Proof.Recall that by Lemma 2.3 ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.