AMO: Adaptive Muon Orthogonalization
Pith reviewed 2026-05-20 13:06 UTC · model grok-4.3
The pith
AMO improves Muon by adapting Newton-Schulz iteration counts to each matrix's measured geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An observe-then-commit procedure that measures weight geometry by operator type early in training and then allocates a fixed Newton-Schulz budget per operator for the remainder of training produces higher-quality models than any uniform Newton-Schulz schedule.
What carries the argument
The observe-then-commit method that converts early measurements of matrix geometry into per-operator Newton-Schulz iteration budgets.
If this is right
- Consistent gains hold across standard, prolonged, and continual pre-training.
- Average downstream performance rises by 0.76 points on Llama3.1-1.4B and 0.51 points on Qwen3-1.7B across 12 tasks.
- Uneven orthogonalization quality across operator types is reduced.
- Only a short initial measurement phase is needed before the schedule is fixed.
Where Pith is reading between the lines
- Similar early-signal commitment could be tested on other iterative steps inside optimizers, such as momentum or second-moment estimates.
- If geometry drifts after the early window, a small number of refresh points might restore most of the benefit without full re-optimization.
- Architectures that differ sharply from the tested Llama and Qwen families may need their own short geometry survey before budgets are set.
Load-bearing premise
Matrix geometry signals measured early in training remain stable enough to justify committing to a fixed per-operator Newton-Schulz budget for the rest of training.
What would settle it
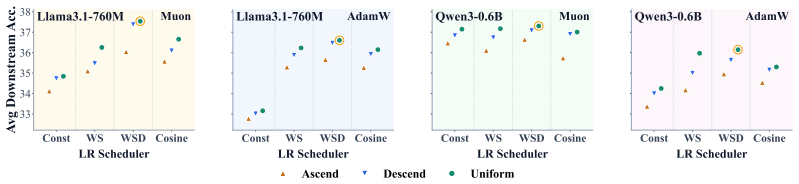
Run two otherwise identical pre-training runs: one that locks Newton-Schulz budgets after the first 1 percent of steps and one that re-measures geometry and adjusts budgets at several later checkpoints; if the locked early-commit version loses its reported gains, the stability premise is false.
Figures













read the original abstract
Muon has recently emerged as a competitive alternative to AdamW for large-scale pre-training, with orthogonalization via Newton-Schulz (NS) iterations as its core operation. Existing Muon variants apply a uniform NS schedule to all parameter matrices, overlooking possible differences in orthogonalization difficulty and its impact on performance. Through a systematic empirical study, we show that this per-matrix heterogeneity is pervasive and largely determined by matrix geometry, which evolves dynamically across operator types, training stages, and network depths. As a result, uniform NS schedules can lead to uneven orthogonalization quality across the model. Motivated by these findings, we propose Adaptive Muon Orthogonalization (AMO), an observe-then-commit method that measures weight geometry by operator type early in training and then uses these signals to allocate the NS budget for the remainder of training. AMO delivers consistent improvements over uniform-schedule Muon across standard, prolonged, and continual pre-training, surpassing the strongest baseline by +0.76 on Llama3.1-1.4B and +0.51 on Qwen3-1.7B in average downstream performance of 12 evaluation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that uniform Newton-Schulz (NS) iteration schedules in Muon overlook per-matrix heterogeneity in orthogonalization difficulty, which is driven by matrix geometry that varies across operator types, network depths, and training stages. Motivated by empirical observations of this heterogeneity, the authors propose AMO, an observe-then-commit method that measures geometry signals early in training and then fixes per-operator NS budgets for the remainder of training. They report that AMO yields consistent gains over uniform-schedule Muon baselines across standard, prolonged, and continual pre-training, surpassing the strongest baseline by +0.76 on Llama3.1-1.4B and +0.51 on Qwen3-1.7B in average performance over 12 downstream tasks.
Significance. If the gains prove robust, AMO offers a low-overhead way to improve Muon by tailoring orthogonalization effort to observed matrix conditioning differences, which could influence practical large-scale pre-training. The systematic empirical documentation of geometry evolution across stages and depths is a clear strength and provides actionable insight for optimizer design.
major comments (2)
- [Section 3] Section 3 (AMO design and observe-then-commit): The method commits to fixed per-operator NS budgets after a single early observation window, yet the manuscript itself states that geometry evolves dynamically across training stages. No experiments or monitoring are reported to verify that the early ordering of operators by difficulty (e.g., singular-value spread or conditioning) remains stable or that the chosen budgets stay near-optimal later in training. This stability assumption is load-bearing for the claim that the reported gains are generally reliable rather than specific to the chosen early measurement point.
- [Experimental results] Experimental results (gains on Llama3.1-1.4B and Qwen3-1.7B): The reported average improvements (+0.76 and +0.51) lack accompanying details on the number of independent runs, standard deviations, or statistical significance tests. Without these, it is difficult to determine whether the gains are robust across the three pre-training regimes or could be influenced by run-to-run variance.
minor comments (2)
- [Section 3] The geometry metric used to map early signals to NS-budget thresholds should be defined more explicitly (e.g., exact formula or pseudocode) to support reproducibility.
- [Figures] Figure captions and axis labels in the geometry-evolution plots could more clearly indicate the training stage at which measurements were taken.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our observe-then-commit design and strengthen the reporting of experimental robustness. We address each major comment below.
read point-by-point responses
-
Referee: [Section 3] Section 3 (AMO design and observe-then-commit): The method commits to fixed per-operator NS budgets after a single early observation window, yet the manuscript itself states that geometry evolves dynamically across training stages. No experiments or monitoring are reported to verify that the early ordering of operators by difficulty (e.g., singular-value spread or conditioning) remains stable or that the chosen budgets stay near-optimal later in training. This stability assumption is load-bearing for the claim that the reported gains are generally reliable rather than specific to the chosen early measurement point.
Authors: We agree that the manuscript explicitly notes dynamic evolution of geometry and that no dedicated monitoring of ordering stability across later stages is currently reported. The observe-then-commit design is motivated by the fact that the dominant heterogeneity is across operator types and appears largely fixed after the initial window in our measurements; the consistent gains across standard, prolonged, and continual pre-training provide indirect empirical support. To directly address the concern, we will add experiments in the revision that track singular-value spreads and relative difficulty orderings at multiple subsequent training checkpoints. revision: yes
-
Referee: [Experimental results] Experimental results (gains on Llama3.1-1.4B and Qwen3-1.7B): The reported average improvements (+0.76 and +0.51) lack accompanying details on the number of independent runs, standard deviations, or statistical significance tests. Without these, it is difficult to determine whether the gains are robust across the three pre-training regimes or could be influenced by run-to-run variance.
Authors: We agree that variance and significance information should be reported to allow readers to assess robustness. The reported averages are computed over three independent runs per configuration (different random seeds), with gains observed consistently across the three pre-training regimes. In the revised manuscript we will include standard deviations alongside the averages and add paired statistical significance tests for the key improvements. revision: yes
Circularity Check
No circularity: AMO allocation derives directly from early empirical measurements
full rationale
The paper defines AMO as an observe-then-commit procedure that records per-operator matrix geometry signals during an initial training window and then fixes the Newton-Schulz iteration counts for the remaining steps. This rule is constructed from direct measurements rather than from any equation, fitted parameter, or self-referential definition that would make the final performance claim equivalent to its own inputs. No self-citation load-bearing steps, uniqueness theorems imported from prior author work, or ansatz smuggling appear in the described chain. The reported gains are presented as empirical results on downstream tasks, not as mathematical necessities forced by the method's own formulation. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Early observation window length
- Geometry-to-NS-budget mapping thresholds
axioms (2)
- domain assumption Per-matrix orthogonalization difficulty is largely determined by matrix geometry
- domain assumption Matrix geometry remains stable enough after the early phase to support a fixed schedule
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AMO... measures weight geometry by operator type early in training and then uses these signals to allocate the NS budget for the remainder of training.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dion: Distributed orthonormalized updates, 2025
Kwangjun Ahn, Byron Xu, Natalie Abreu, Ying Fan, Gagik Magakyan, Pratyusha Sharma, Zheng Zhan, and John Langford. Dion: Distributed orthonormalized updates, 2025. 20
work page 2025
-
[2]
Essential AI, Ishaan Shah, Anthony M. Polloreno, Karl Stratos, Philip Monk, Adarsh Chalu- varaju, Andrew Hojel, Andrew Ma, Anil Thomas, Ashish Tanwer, Darsh J Shah, Khoi Nguyen, Kurt Smith, Michael Callahan, Michael Pust, Mohit Parmar, Peter Rushton, Platon Mazarakis, Ritvik Kapila, Saurabh Srivastava, Somanshu Singla, Tim Romanski, Yash Vanjani, and Ashi...
work page 2025
- [3]
-
[4]
GQA: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. GQA: Training generalized multi-query transformer models from multi-head checkpoints. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901, Singapor...
work page 2023
-
[5]
Noah Amsel, David Persson, Christopher Musco, and Robert M. Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm. InThe Fourteenth International Conference on Learning Representations, 2026. 1, 2, 4, 6, 9, 16, 18, 20, 33, 37
work page 2026
-
[6]
ASGO: Adaptive structured gradient optimization
Kang An, Yuxing Liu, Rui Pan, Yi Ren, Shiqian Ma, Donald Goldfarb, and Tong Zhang. ASGO: Adaptive structured gradient optimization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 20
work page 2025
-
[7]
Perplexed by perplexity: Perplexity-based data pruning with small reference models
Zachary Ankner, Cody Blakeney, Kartik Sreenivasan, Max Marion, Matthew L Leavitt, and Mansheej Paul. Perplexed by perplexity: Perplexity-based data pruning with small reference models. InThe Thirteenth International Conference on Learning Representations, 2025. 21
work page 2025
-
[8]
Efficient pretraining data selection for language models via multi-actor collaboration
Tianyi Bai, Ling Yang, Zhen Hao Wong, Fupeng Sun, Xinlin Zhuang, Jiahui Peng, Chi Zhang, Lijun Wu, Qiu Jiantao, Wentao Zhang, Binhang Yuan, and Conghui He. Efficient pretraining data selection for language models via multi-actor collaboration. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)...
work page 2025
-
[9]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7432–7439, 2020. 6, 33
work page 2020
-
[10]
Turbo-muon: Accelerating orthogonality-based optimization with pre-conditioning, 2025
Thibaut Boissin, Thomas Massena, Franck Mamalet, and Mathieu Serrurier. Turbo-muon: Accelerating orthogonality-based optimization with pre-conditioning, 2025. 2, 6, 20, 33
work page 2025
-
[11]
Dan A. Calian, Gregory Farquhar, Iurii Kemaev, Luisa Zintgraf, Matteo Hessel, Jeremy Shar, Junhyuk Oh, András György, Tom Schaul, Jeff Dean, Hado van Hasselt, and David Silver. Datarater: Meta-learned dataset curation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 21
work page 2025
-
[12]
Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018. 6, 33
work page 2018
-
[13]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. InThe Twelfth International Conference on Learning Representations, 2024. 6, 32
work page 2024
-
[14]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026. 1, 9
work page 2026
-
[15]
DsDm: Model-aware dataset selection with datamodels
Logan Engstrom, Axel Feldmann, and Aleksander Madry. DsDm: Model-aware dataset selection with datamodels. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Re...
work page 2024
-
[16]
What really matters in matrix-whitening optimizers?, 2025
Kevin Frans, Pieter Abbeel, and Sergey Levine. What really matters in matrix-whitening optimizers?, 2025. 1, 20
work page 2025
-
[17]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
work page 2024
-
[18]
Glm-5: from vibe coding to agentic engineering, 2026
GLM-5-Team. Glm-5: from vibe coding to agentic engineering, 2026. 20
work page 2026
-
[19]
Accelerating newton-schulz iteration for orthogonalization via chebyshev-type polynomials, 2026
Ekaterina Grishina, Matvey Smirnov, and Maxim Rakhuba. Accelerating newton-schulz iteration for orthogonalization via chebyshev-type polynomials, 2026. 1, 2, 4, 6, 9, 18, 20, 33, 37
work page 2026
-
[20]
Drop-muon: Update less, converge faster, 2025
Kaja Gruntkowska, Yassine Maziane, Zheng Qu, and Peter Richtárik. Drop-muon: Update less, converge faster, 2025. 20
work page 2025
-
[21]
Data selection via optimal control for language models
Yuxian Gu, Li Dong, Hongning Wang, Yaru Hao, Qingxiu Dong, Furu Wei, and Minlie Huang. Data selection via optimal control for language models. InThe Thirteenth International Conference on Learning Representations, 2025. 21
work page 2025
-
[22]
Root: Robust orthogonalized optimizer for neural network training, 2025
Wei He, Kai Han, Hang Zhou, Hanting Chen, Zhicheng Liu, Xinghao Chen, and Yunhe Wang. Root: Robust orthogonalized optimizer for neural network training, 2025. 1, 2, 4, 6, 20, 33
work page 2025
-
[23]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021. 6, 33
work page 2021
-
[24]
Rae, Oriol Vinyals, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page 2022
-
[25]
Datamodels: Predicting predictions from training data, 2022
Andrew Ilyas, Sung Min Park, Logan Engstrom, Guillaume Leclerc, and Aleksander Madry. Datamodels: Predicting predictions from training data, 2022. 21
work page 2022
-
[26]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. 1, 4, 6, 20, 33
work page 2024
-
[27]
Muonbp: Faster muon via block-periodic orthogonalization, 2025
Ahmed Khaled, Kaan Ozkara, Tao Yu, Mingyi Hong, and Youngsuk Park. Muonbp: Faster muon via block-periodic orthogonalization, 2025. 20
work page 2025
-
[28]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017. 19
work page 2017
-
[29]
RACE: Large-scale ReAding comprehension dataset from examinations
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. RACE: Large-scale ReAding comprehension dataset from examinations. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 785–794, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. 6, 33
work page 2017
-
[30]
Normuon: Making muon more efficient and scalable, 2025
Zichong Li, Liming Liu, Chen Liang, Weizhu Chen, and Tuo Zhao. Normuon: Making muon more efficient and scalable, 2025. 1, 20
work page 2025
-
[31]
Sophia: A scalable stochastic second-order optimizer for language model pre-training
Hong Liu, Zhiyuan Li, David Leo Wright Hall, Percy Liang, and Tengyu Ma. Sophia: A scalable stochastic second-order optimizer for language model pre-training. InThe Twelfth International Conference on Learning Representations, 2024. 20
work page 2024
-
[32]
Muon is scalable for llm training, 2025
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yongsheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, and Zhilin Yang. Muon is sca...
work page 2025
-
[33]
Cosmos: A hybrid adaptive optimizer for memory-efficient training of llms,
Liming Liu, Zhenghao Xu, Zixuan Zhang, Hao Kang, Zichong Li, Chen Liang, Weizhu Chen, and Tuo Zhao. Cosmos: A hybrid adaptive optimizer for memory-efficient training of llms,
-
[34]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InThe Seventh International Conference on Learning Representations, 2019. 19
work page 2019
-
[35]
How learning rate decay wastes your best data in curriculum-based LLM pretraining
Kairong Luo, Zhenbo Sun, Haodong Wen, Xinyu Shi, Jiarui Cui, Chenyi Dang, Kaifeng Lyu, and Wenguang Chen. How learning rate decay wastes your best data in curriculum-based LLM pretraining. InThe Fourteenth International Conference on Learning Representations, 2026. 2
work page 2026
-
[36]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381–2391, Brussels, Belgium, 2018. Association for Computational Linguistics. 6, 33
work page 2018
-
[37]
Prodigy: An expeditiously adaptive parameter-free learner
Konstantin Mishchenko and Aaron Defazio. Prodigy: An expeditiously adaptive parameter-free learner. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 35779–35804. PMLR, 2024. 20
work page 2024
-
[38]
Antonio Orvieto and Robert M. Gower. In search of adam’s secret sauce. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 20
work page 2025
-
[39]
The fineweb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. InAdvances in Neural Information Processing Systems, volume 37, pages 30811–30849, 2024. 3, 6, 31
work page 2024
-
[40]
Winogrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8732–8740, 2020. 6, 33
work page 2020
-
[41]
Glu variants improve transformer, 2020
Noam Shazeer. Glu variants improve transformer, 2020. 6, 31
work page 2020
-
[42]
Predictive data selection: The data that predicts is the data that teaches
KaShun SHUM, Yuzhen Huang, Hongjian Zou, dingqi, YiXuan Liao, Xiaoxin Chen, Qian Liu, and Junxian He. Predictive data selection: The data that predicts is the data that teaches. In Forty-second International Conference on Machine Learning, 2025. 21
work page 2025
-
[43]
Adamuon: Adaptive muon optimizer, 2025
Chongjie Si, Debing Zhang, and Wei Shen. Adamuon: Adaptive muon optimizer, 2025. 1, 6, 20, 33
work page 2025
-
[44]
CommonsenseQA: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis...
work page 2019
-
[45]
ADOPT: Modified adam can converge with any $\beta_2$ with the optimal rate
Shohei Taniguchi, Keno Harada, Gouki Minegishi, Yuta Oshima, Seongcheol Jeong, Go Na- gahara, Tomoshi Iiyama, Masahiro Suzuki, Yusuke Iwasawa, and Yutaka Matsuo. ADOPT: Modified adam can converge with any $\beta_2$ with the optimal rate. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 20
work page 2024
-
[46]
Kimi k2: Open agentic intelligence, 2026
Kimi Team. Kimi k2: Open agentic intelligence, 2026. 1, 20
work page 2026
-
[47]
Kushal Tirumala, Daniel Simig, Armen Aghajanyan, and Ari S. Morcos. D4: Improving LLM pretraining via document de-duplication and diversification. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. 21
work page 2023
-
[48]
Nikhil Vyas, Depen Morwani, Rosie Zhao, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham M. Kakade. SOAP: Improving and stabilizing shampoo using adam for language modeling. InThe Thirteenth International Conference on Learning Representations, 2025. 20 12
work page 2025
-
[49]
Shuche Wang, Fengzhuo Zhang, Jiaxiang Li, Cunxiao Du, Chao Du, Tianyu Pang, Zhuoran Yang, Mingyi Hong, and Vincent Y . F. Tan. Muon outperforms adam in tail-end associative memory learning. InThe Fourteenth International Conference on Learning Representations,
-
[50]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J...
work page 2024
-
[51]
Johannes Welbl, Nelson F. Liu, and Matt Gardner. Crowdsourcing multiple choice science questions. InProceedings of the 3rd Workshop on Noisy User-generated Text, pages 94–106, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. 6, 33
work page 2017
-
[52]
Fantastic pretraining optimizers and where to find them, 2025
Kaiyue Wen, David Hall, Tengyu Ma, and Percy Liang. Fantastic pretraining optimizers and where to find them, 2025. 20
work page 2025
-
[53]
Qurating: Selecting high- quality data for training language models
Alexander Wettig, Aatmik Gupta, Saumya Malik, and Danqi Chen. Qurating: Selecting high- quality data for training language models. InForty-first International Conference on Machine Learning, 2024. 21
work page 2024
-
[54]
Organize the web: Constructing domains enhances pre-training data curation
Alexander Wettig, Kyle Lo, Sewon Min, Hannaneh Hajishirzi, Danqi Chen, and Luca Soldaini. Organize the web: Constructing domains enhances pre-training data curation. InForty-second International Conference on Machine Learning, 2025. 21
work page 2025
-
[55]
Data selection for language models via importance resampling
Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang. Data selection for language models via importance resampling. InThirty-seventh Conference on Neural Information Processing Systems, 2023. 21
work page 2023
-
[56]
Xingyu Xie, Pan Zhou, Huan Li, Zhouchen Lin, and Shuicheng Yan. Adan: Adaptive nesterov momentum algorithm for faster optimizing deep models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9508–9520, 2024. 20
work page 2024
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page 2025
-
[58]
Benjamin Erichson, and Michael W
Shenghao Yang, Zhichao Wang, Oleg Balabanov, N. Benjamin Erichson, and Michael W. Mahoney. Prism: Distribution-free adaptive computation of matrix functions for accelerating neural network training, 2026. 20
work page 2026
-
[59]
MATES: Model-aware data selection for efficient pretraining with data influence models
Zichun Yu, Spandan Das, and Chenyan Xiong. MATES: Model-aware data selection for efficient pretraining with data influence models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 21
work page 2024
-
[60]
MARS: Unleashing the power of variance reduction for training large models
Huizhuo Yuan, Yifeng Liu, Shuang Wu, zhou Xun, and Quanquan Gu. MARS: Unleashing the power of variance reduction for training large models. InForty-second International Conference on Machine Learning, 2025. 20
work page 2025
-
[61]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Anna Korhonen, David Traum, and Lluís Màrquez, edi- tors,Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy, July 2019. Association for Computational Linguis...
work page 2019
-
[62]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 32, 2019. 6, 31
work page 2019
-
[63]
Harnessing diversity for important data selection in pretraining large language models
Chi Zhang, Huaping Zhong, Kuan Zhang, Chengliang Chai, Rui Wang, Xinlin Zhuang, Tianyi Bai, Qiu Jiantao, Lei Cao, Ju Fan, Ye Yuan, Guoren Wang, and Conghui He. Harnessing diversity for important data selection in pretraining large language models. InThe Thirteenth International Conference on Learning Representations, 2025. 21
work page 2025
-
[64]
Jack Zhang, Noah Amsel, Berlin Chen, and Tri Dao. Gram newton-schulz, 2026. 1, 20
work page 2026
-
[65]
Adagrad meets muon: Adaptive stepsizes for orthogonal updates, 2025
Minxin Zhang, Yuxuan Liu, and Hayden Schaeffer. Adagrad meets muon: Adaptive stepsizes for orthogonal updates, 2025. 20
work page 2025
-
[66]
Why transformers need adam: A hessian perspective
Yushun Zhang, Congliang Chen, Tian Ding, Ziniu Li, Ruoyu Sun, and Zhi-Quan Luo. Why transformers need adam: A hessian perspective. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 19
work page 2024
-
[67]
Adam-mini: Use fewer learning rates to gain more
Yushun Zhang, Congliang Chen, Ziniu Li, Tian Ding, Chenwei Wu, Diederik P Kingma, Yinyu Ye, Zhi-Quan Luo, and Ruoyu Sun. Adam-mini: Use fewer learning rates to gain more. InThe Thirteenth International Conference on Learning Representations, 2025. 20
work page 2025
-
[68]
Rosie Zhao, Depen Morwani, David Brandfonbrener, Nikhil Vyas, and Sham M. Kakade. Deconstructing what makes a good optimizer for autoregressive language models. InThe Thirteenth International Conference on Learning Representations, 2025. 20
work page 2025
-
[69]
AGIEval: A human-centric benchmark for evaluating foundation models
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. AGIEval: A human-centric benchmark for evaluating foundation models. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Findings of the Association for Computational Linguistics: NAACL 2024, pages 2299–2314, Mexico City, Mexico, June
work page 2024
-
[70]
Association for Computational Linguistics. 6, 33
-
[71]
How to set the learning rate for large-scale pre-training?, 2026
Yunhua Zhou, Shuhao Xing, Junhao Huang, Xipeng Qiu, and Qipeng Guo. How to set the learning rate for large-scale pre-training?, 2026. 6, 21, 32
work page 2026
-
[72]
Meta-rater: A multi-dimensional data selection method for pre-training language models
Xinlin Zhuang, Jiahui Peng, Ren Ma, Yinfan Wang, Tianyi Bai, Xingjian Wei, Qiu Jiantao, Chi Zhang, Ying Qian, and Conghui He. Meta-rater: A multi-dimensional data selection method for pre-training language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computationa...
-
[73]
7, 21 14 Appendix Table of Contents A Details of AMO 16 A.1 Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 A.2 Optimality Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 B Related Work 19 C Pilot Experiments 21 C.1 Data Curriculum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
work page 1930
-
[74]
takes a complementary approach by eliminating the need for learning rate tuning altogether through a D-adaptation mechanism that automatically estimates the optimal step size during training. Muon optimizer.Muon [ 26] is a recently proposed optimizer designed for the hidden-layer param- eters of neural networks. It orthogonalizes the momentum buffer via N...
-
[75]
Complementing instance-level methods, several approaches addresscorpus-level diversity
estimates each example’s marginal contribution via datamodels [25], MATES [59] periodically updates lightweight influence models during pre-training, [ 21] dynamically adjusts the training distribution as a sequential decision problem, and [42] identifies the most instructive examples by their ability to predict learning outcomes. Complementing instance-l...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.