AutoMCU: Feasibility-First MCU Neural Network Customization via LLM-based Multi-Agent Systems
Pith reviewed 2026-05-22 09:58 UTC · model grok-4.3
The pith
AutoMCU uses LLM multi-agent systems to customize neural networks for microcontrollers by filtering designs with hardware feedback before training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AutoMCU is a feasibility-first LLM-based multi-agent system for automated neural network customization under MCU constraints. It generates structured architecture candidates, filters infeasible designs through vendor toolchain feedback before training, evaluates feasible models, and verifies deployability. This achieves competitive accuracy while reducing customization time to about 1-2 hours compared with hundreds of GPU hours for HW-NAS baselines.
What carries the argument
Hardware-in-the-loop architecture generation combined with state-isolated multi-agent scheduling that enables early elimination of undeployable candidates under RAM and Flash constraints.
If this is right
- Customization time for MCU neural networks drops from hundreds of GPU hours to 1-2 hours.
- Competitive accuracy is maintained on CIFAR-10 and CIFAR-100 datasets under strict memory constraints.
- Real-device deployments succeed on multiple STM32 microcontrollers.
- Stability and effectiveness are shown in comparisons with ColabNAS and GENIUS on NAS-Bench-201.
Where Pith is reading between the lines
- Similar multi-agent LLM approaches could be applied to other constrained hardware like FPGAs or mobile devices.
- The early filtering might allow for more exploration of architecture space without wasting compute on invalid designs.
- Non-experts could more easily create edge AI applications tailored to specific MCUs and tasks.
Load-bearing premise
The vendor toolchain feedback reliably identifies all architectures that cannot be deployed due to RAM and Flash limits without incorrectly discarding some that could achieve high accuracy if trained.
What would settle it
An experiment that trains a network architecture rejected by the early toolchain filter and shows it fits within MCU constraints and reaches target accuracy.
Figures


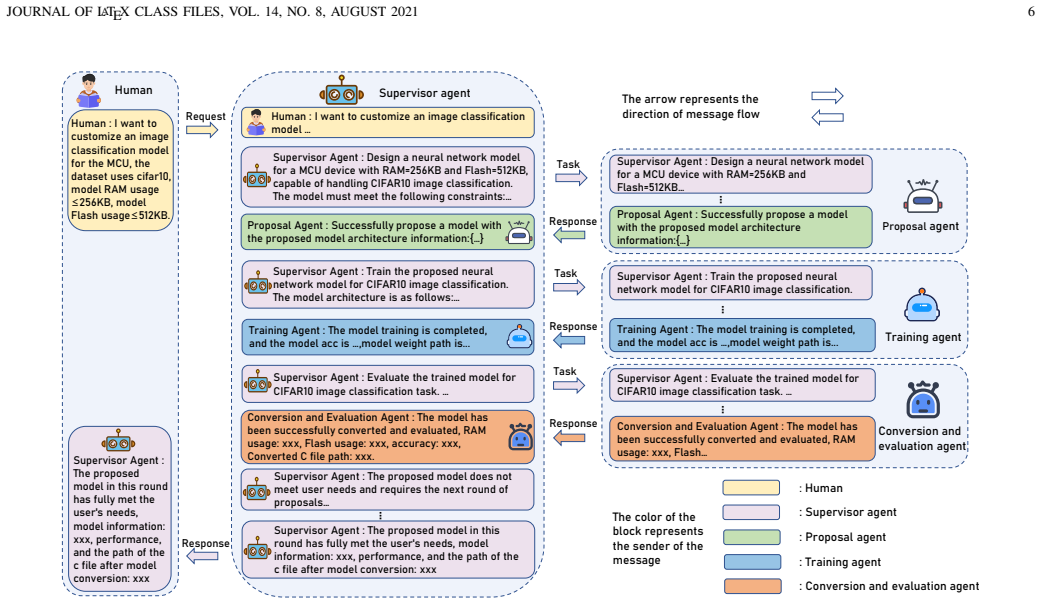

read the original abstract
Deploying neural networks on microcontroller units (MCUs) is critical for edge intelligence but remains challenging due to tight memory, storage, and computation constraints. Existing approaches, such as model compression and hardware-aware neural architecture search (HW-NAS), often depend on proxy metrics, incur high search cost, and do not fully bridge the gap between architecture design and verified deployment. This paper presents AutoMCU, a feasibility-first large language model (LLM)-based multi-agent system for automated neural network customization under MCU constraints. Given natural-language task requirements and hardware specifications, AutoMCU iteratively generates structured architecture candidates, filters infeasible designs through vendor toolchain feedback before training, evaluates feasible models under a controlled protocol, and verifies deployability through backend-grounded deployment analysis. AutoMCU includes two key mechanisms: 1) hardware-in-the-loop architecture generation for early elimination of undeployable candidates under RAM and Flash constraints, and 2) state-isolated multi-agent scheduling for stable coordination of proposal, training, evaluation, and deployment stages. Experiments on CIFAR-10 and CIFAR-100 under strict MCU constraints show that AutoMCU achieves competitive accuracy while reducing customization time to about 1--2 hours, compared with hundreds of GPU hours for representative MCU-oriented HW-NAS baselines. Comparisons with ColabNAS and the LLM-based NAS method GENIUS on NAS-Bench-201 further demonstrate the effectiveness and stability of AutoMCU. Real-device deployments on multiple STM32 microcontrollers validate its practical applicability to MCU-scale edge intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AutoMCU, an LLM-based multi-agent system for feasibility-first neural network customization on MCUs. Given natural-language task and hardware specs, it generates structured architecture candidates, applies vendor-toolchain feedback to filter infeasible designs under RAM/Flash constraints before any training, evaluates surviving models under a controlled protocol, and verifies deployability via backend-grounded analysis. Two mechanisms are highlighted: hardware-in-the-loop generation for early elimination and state-isolated multi-agent scheduling. Experiments on CIFAR-10 and CIFAR-100 under strict MCU constraints claim competitive accuracy with customization times of 1-2 hours versus hundreds of GPU hours for HW-NAS baselines; further comparisons on NAS-Bench-201 with ColabNAS and GENIUS, plus real STM32 deployments, are reported.
Significance. If the results hold, the work could meaningfully lower the cost of deploying neural networks on MCUs by replacing expensive HW-NAS with LLM-driven generation plus early, hardware-grounded filtering. The emphasis on pre-training feasibility checks and multi-agent coordination addresses a practical gap between architecture search and verified deployment. The approach is internally consistent on its own terms and offers a falsifiable prediction (time/accuracy trade-off under fixed MCU constraints) that can be tested by independent replication.
major comments (2)
- [Hardware-in-the-loop architecture generation and Experiments sections] The headline result (competitive CIFAR-10/100 accuracy in 1-2 h) rests on the assumption that vendor-toolchain feedback removes only undeployable nets without discarding higher-accuracy candidates that would fit after quantization or memory-layout adjustments. The manuscript does not report whether the toolchain feedback uses peak-RAM estimates before or after quantization, nor does it quantify how many high-potential architectures were pruned versus retained. This filtering step is load-bearing for the accuracy claim; without an ablation or sensitivity analysis on the feedback conservatism, the reported gap versus HW-NAS baselines could be an artifact of a restricted search space rather than superiority of the LLM-generated designs.
- [Experiments on CIFAR-10 and CIFAR-100] Table or figure reporting CIFAR-10/100 results: exact accuracy numbers, standard deviations across runs, precise baseline implementations (including whether the HW-NAS baselines also received the same post-filter training protocol), and details on how deployability was verified after training are not provided at the level needed to substantiate 'competitive accuracy.' The abstract states the outcome but the experimental section must supply these quantities for the central claim to be verifiable.
minor comments (2)
- [Abstract and Experiments] Clarify the exact definition of 'customization time' (wall-clock hours on what hardware, including or excluding training) and report variance across multiple LLM runs to support the 1-2 hour claim.
- [Comparisons with ColabNAS and GENIUS] The comparison with GENIUS on NAS-Bench-201 would benefit from an explicit table contrasting agent roles, filtering mechanisms, and stability metrics rather than narrative description alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify key aspects of our methodology and experiments. We address each major comment point by point below, proposing targeted revisions to strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Hardware-in-the-loop architecture generation and Experiments sections] The headline result (competitive CIFAR-10/100 accuracy in 1-2 h) rests on the assumption that vendor-toolchain feedback removes only undeployable nets without discarding higher-accuracy candidates that would fit after quantization or memory-layout adjustments. The manuscript does not report whether the toolchain feedback uses peak-RAM estimates before or after quantization, nor does it quantify how many high-potential architectures were pruned versus retained. This filtering step is load-bearing for the accuracy claim; without an ablation or sensitivity analysis on the feedback conservatism, the reported gap versus HW-NAS baselines could be an artifact of a restricted search space rather than superiority of the LLM-generated designs.
Authors: We appreciate this observation on the filtering mechanism. The hardware-in-the-loop generation applies vendor toolchain checks on RAM and Flash constraints before any training occurs, with the explicit goal of discarding only designs that violate hard MCU limits. To address the absence of quantification and potential conservatism concerns, we will revise the Hardware-in-the-loop section to specify the timing of memory estimates relative to quantization and report aggregate statistics on architectures generated, pruned, and retained across runs. We will also add a sensitivity analysis on filtering thresholds to show that the retained search space supports the observed accuracy levels, confirming the results are not artifacts of over-restriction. revision: yes
-
Referee: [Experiments on CIFAR-10 and CIFAR-100] Table or figure reporting CIFAR-10/100 results: exact accuracy numbers, standard deviations across runs, precise baseline implementations (including whether the HW-NAS baselines also received the same post-filter training protocol), and details on how deployability was verified after training are not provided at the level needed to substantiate 'competitive accuracy.' The abstract states the outcome but the experimental section must supply these quantities for the central claim to be verifiable.
Authors: We agree that the experimental reporting requires greater detail for full verifiability. In the revised manuscript, we will expand the Experiments section with a table containing exact accuracy figures, standard deviations over multiple independent runs for AutoMCU and all baselines on CIFAR-10 and CIFAR-100. We will explicitly describe the baseline implementations, including confirmation that HW-NAS methods followed an equivalent post-filter training and evaluation protocol, and add further specifics on post-training deployability verification via backend-grounded analysis on the target STM32 devices. These additions will directly substantiate the abstract claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an LLM-based multi-agent system (AutoMCU) for generating and filtering MCU neural architectures, with results presented as empirical experimental outcomes on CIFAR-10/100 (competitive accuracy, 1-2 hour customization time vs. hundreds of GPU hours for HW-NAS baselines). No equations, fitted parameters, self-definitional loops, or load-bearing self-citations appear in the abstract or described method. The feasibility filtering and multi-agent scheduling are procedural components whose performance is measured externally rather than derived by construction from the inputs themselves. The derivation chain is self-contained against experimental benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hardware-in-the-loop architecture generation... filters infeasible designs through vendor toolchain feedback before training
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Lspnet: A 2d localization-oriented spacecraft pose estimation neural network,
A. Garcia, M. A. Musallam, V . Gaudilliere, E. Ghorbel, K. Al Ismaeil, M. Perez, and D. Aouada, “Lspnet: A 2d localization-oriented spacecraft pose estimation neural network,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2021, pp. 2048–2056
work page 2021
-
[2]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2016, pp. 770–778
work page 2016
-
[3]
Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,
W. Chan, N. Jaitly, Q. Le, and O. Vinyals, “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2016, pp. 4960–4964
work page 2016
-
[4]
Attention-based models for speech recognition,
J. K. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y . Bengio, “Attention-based models for speech recognition,” Advances in Neural Information Processing Systems , vol. 28, 2015
work page 2015
-
[5]
Neural Machine Translation by Jointly Learning to Align and Translate
D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine translation by jointly learning to align and translate,” arXiv preprint arXiv:1409.0473 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[6]
Tensorflow lite micro: Embedded machine learning for tinyml systems,
R. David, J. Duke, A. Jain, V . Janapa Reddi, N. Jeffries, J. Li, N. Kreeger, I. Nappier, M. Natraj, T. Wang et al., “Tensorflow lite micro: Embedded machine learning for tinyml systems,” Proceedings of Machine Learning and Systems , vol. 3, pp. 800–811, 2021
work page 2021
-
[7]
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” arXiv preprint arXiv:1510.00149 , 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
Quantization and training of neural networks for efficient integer-arithmetic-only inference,
B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard, H. Adam, and D. Kalenichenko, “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2018, pp. 2704–2713
work page 2018
-
[9]
Haq: Hardware-aware automated quantization with mixed precision,
K. Wang, Z. Liu, Y . Lin, J. Lin, and S. Han, “Haq: Hardware-aware automated quantization with mixed precision,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2019, pp. 8612–8620
work page 2019
-
[10]
Model compression and hardware acceleration for neural networks: A comprehensive survey,
L. Deng, G. Li, S. Han, L. Shi, and Y . Xie, “Model compression and hardware acceleration for neural networks: A comprehensive survey,” Proceedings of the IEEE , vol. 108, no. 4, pp. 485–532, 2020
work page 2020
-
[11]
Neural architecture search with reinforcement learning,
B. Zoph and Q. Le, “Neural architecture search with reinforcement learning,” in International Conference on Learning Representations , 2017
work page 2017
-
[12]
Large-scale evolution of image classifiers,
E. Real, S. Moore, A. Selle, S. Saxena, Y . L. Suematsu, J. Tan, Q. V . Le, and A. Kurakin, “Large-scale evolution of image classifiers,” in International Conference on Machine Learning . PMLR, 2017, pp. 2902–2911
work page 2017
-
[13]
Efficient neural architecture search via parameters sharing,
H. Pham, M. Guan, B. Zoph, Q. Le, and J. Dean, “Efficient neural architecture search via parameters sharing,” in International Conference on Machine Learning . PMLR, 2018, pp. 4095–4104
work page 2018
-
[14]
Single path one-shot neural architecture search with uniform sampling,
Z. Guo, X. Zhang, H. Mu, W. Heng, Z. Liu, Y . Wei, and J. Sun, “Single path one-shot neural architecture search with uniform sampling,” in European Conference on Computer Vision . Springer, 2020, pp. 544– 560
work page 2020
-
[15]
Automl: A survey of the state-of-the-art,
X. He, K. Zhao, and X. Chu, “Automl: A survey of the state-of-the-art,” Knowledge-based Systems, vol. 212, p. 106622, 2021
work page 2021
-
[16]
Mcunet: Tiny deep learning on iot devices,
J. Lin, W.-M. Chen, Y . Lin, C. Gan, S. Han et al. , “Mcunet: Tiny deep learning on iot devices,” Advances in Neural Information Processing Systems, vol. 33, pp. 11 711–11 722, 2020
work page 2020
-
[17]
Mnasnet: Platform-aware neural architecture search for mobile,
M. Tan, B. Chen, R. Pang, V . Vasudevan, M. Sandler, A. Howard, and Q. V . Le, “Mnasnet: Platform-aware neural architecture search for mobile,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2019, pp. 2820–2828
work page 2019
-
[18]
Fairnas: Rethinking evaluation fairness of weight sharing neural architecture search,
X. Chu, B. Zhang, and R. Xu, “Fairnas: Rethinking evaluation fairness of weight sharing neural architecture search,” in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2021, pp. 12 239–12 248
work page 2021
-
[19]
Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search,
B. Wu, X. Dai, P . Zhang, Y . Wang, F. Sun, Y . Wu, Y . Tian, P . Vajda, Y . Jia, and K. Keutzer, “Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2019, pp. 10 734–10 742
work page 2019
-
[20]
𝜇nas: Constrained neural architecture search for microcontrollers,
E. Liberis, Ł. Dudziak, and N. D. Lane, “ 𝜇nas: Constrained neural architecture search for microcontrollers,” in Proceedings of the 1st Workshop on Machine Learning and Systems , 2021, pp. 70–79
work page 2021
-
[21]
Can GPT -4 Perform Neural Architecture Search ?, August 2023
M. Zheng, X. Su, S. Y ou, F. Wang, C. Qian, C. Xu, and S. Al- banie, “Can gpt-4 perform neural architecture search?” arXiv preprint arXiv:2304.10970, 2023
-
[22]
A. M. Garavagno, D. Leonardis, and A. Frisoli, “Colabnas: Obtain- ing lightweight task-specific convolutional neural networks following occam’s razor,” Future Generation Computer Systems, vol. 152, pp. 152– 159, 2024
work page 2024
-
[23]
Mo- bilenetv2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mo- bilenetv2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2018, pp. 4510–4520
work page 2018
-
[24]
Shufflenet v2: Practical guidelines for efficient cnn architecture design,
N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “Shufflenet v2: Practical guidelines for efficient cnn architecture design,” in Proceedings of the European Conference on Computer Vision (ECCV) , 2018, pp. 116–131
work page 2018
-
[25]
J. Liang, L. Zhang, C. Han, C. Bu, H. Wu, and A. Song, “A collaborative compression scheme for fast activity recognition on mobile devices via global compression ratio decision,” IEEE Transactions on Mobile Computing, vol. 23, no. 4, pp. 3259–3273, 2023
work page 2023
-
[26]
S. Liu, J. Du, K. Nan, Z. Zhou, H. Liu, Z. Wang, and Y . Lin, “Adadeep: A usage-driven, automated deep model compression framework for enabling ubiquitous intelligent mobiles,” IEEE Transactions on Mobile Computing, vol. 20, no. 12, pp. 3282–3297, 2020. JOURNAL OF L ATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
work page 2020
-
[27]
Learning both weights and con- nections for efficient neural network,
S. Han, J. Pool, J. Tran, and W. Dally, “Learning both weights and con- nections for efficient neural network,” Advances in Neural Information Processing Systems, vol. 28, 2015
work page 2015
-
[28]
Thinet: A filter level pruning method for deep neural network compression,
J.-H. Luo, J. Wu, and W. Lin, “Thinet: A filter level pruning method for deep neural network compression,” in Proceedings of the IEEE international Conference on Computer Vision , 2017, pp. 5058–5066
work page 2017
-
[29]
Channel pruning for accelerating very deep neural networks,
Y . He, X. Zhang, and J. Sun, “Channel pruning for accelerating very deep neural networks,” in Proceedings of the IEEE International Conference on Computer Vision , 2017, pp. 1389–1397
work page 2017
-
[30]
Target-aware neural network execution via compiler-guided pruning,
J. Cha, T. Kim, J. Lee, S. Ha, and Y . Kwon, “Target-aware neural network execution via compiler-guided pruning,” IEEE Transactions on Mobile Computing , 2025
work page 2025
-
[31]
Nestquant: Post-training integer-nesting quantization for on-device dnn,
J. Xie, C. Ding, X. Li, S. Ren, Y . Li, and Z. Lu, “Nestquant: Post-training integer-nesting quantization for on-device dnn,” IEEE Transactions on Mobile Computing , vol. 24, no. 11, pp. 12 088–12 102, 2025
work page 2025
-
[32]
Evolving neural architecture using one shot model,
N. Sinha and K.-W . Chen, “Evolving neural architecture using one shot model,” in Proceedings of the Genetic and Evolutionary Computation Conference, 2021, pp. 910–918
work page 2021
-
[33]
Chamnet: Towards efficient network design through platform-aware model adaptation,
X. Dai, P . Zhang, B. Wu, H. Yin, F. Sun, Y . Wang, M. Dukhan, Y . Hu, Y . Wu, Y . Jia et al., “Chamnet: Towards efficient network design through platform-aware model adaptation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2019, pp. 11 398–11 407
work page 2019
-
[34]
Learning transferable architectures for scalable image recognition,
B. Zoph, V . Vasudevan, J. Shlens, and Q. V . Le, “Learning transferable architectures for scalable image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2018, pp. 8697–8710
work page 2018
-
[35]
Once for all: Train one network and specialize it for efficient deployment,
H. Cai, C. Gan, T. Wang, Z. Zhang, and S. Han, “Once for all: Train one network and specialize it for efficient deployment,” in International Conference on Learning Representations , 2020. [Online]. Available: https://arxiv.org/pdf/1908.09791.pdf
-
[36]
DARTS: Differentiable Architecture Search
H. Liu, K. Simonyan, and Y . Y ang, “Darts: Differentiable architecture search,” arXiv preprint arXiv:1806.09055 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Pc-darts: Partial channel connections for memory-efficient architecture search,
Y . Xu, L. Xie, X. Zhang, X. Chen, G.-J. Qi, Q. Tian, and H. Xiong, “Pc-darts: Partial channel connections for memory-efficient architecture search,” arXiv preprint arXiv:1907.05737 , 2019
-
[38]
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
H. Cai, L. Zhu, and S. Han, “Proxylessnas: Direct neural architecture search on target task and hardware,” arXiv preprint arXiv:1812.00332 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Zero-shot neural architecture search: Challenges, solutions, and opportunities,
G. Li, D. Hoang, K. Bhardwaj, M. Lin, Z. Wang, and R. Mar- culescu, “Zero-shot neural architecture search: Challenges, solutions, and opportunities,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 7618–7635, 2024
work page 2024
-
[40]
Epe-nas: Efficient performance estimation without training for neural architecture search,
V . Lopes, S. Alirezazadeh, and L. A. Alexandre, “Epe-nas: Efficient performance estimation without training for neural architecture search,” in International Conference on Artificial Neural Networks . Springer, 2021, pp. 552–563
work page 2021
-
[41]
Zen-nas: A zero-shot nas for high-performance image recognition,
M. Lin, P . Wang, Z. Sun, H. Chen, X. Sun, Q. Qian, H. Li, and R. Jin, “Zen-nas: A zero-shot nas for high-performance image recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 347–356
work page 2021
-
[42]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong et al. , “Deepseek-v3. 2: Pushing the frontier of open large language models,” arXiv preprint arXiv:2512.02556 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” University of Toronto, Technical Report, 2009
work page 2009
-
[44]
Mimo-v2-flash technical report,
L.-C. Xiaomi, “Mimo-v2-flash technical report,” 2025. [Online]. Available: https://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/ paper.pdf
work page 2025
-
[45]
A. Y ang, B. Y ang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Y ang, J. Tu, J. Zhang, J. Y ang, J. Y ang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Y ang, L. Yu, M. Li, M. Xue, P . Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, and Z. Qiu,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, “Squeezenet: Alexnet-level accuracy with 50x fewer parameters and< 0.5 mb model size,” arXiv preprint arXiv:1602.07360 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[47]
Gradient-based learning applied to document recognition,
Y . Lecun, L. Bottou, Y . Bengio, and P . Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE , vol. 86, pp. 2278 – 2324, 12 1998
work page 1998
-
[48]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,” arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Nas-bench-201: Extending the scope of reproducible neural architecture search,
X. Dong and Y . Y ang, “Nas-bench-201: Extending the scope of reproducible neural architecture search,” in International Conference on Learning Representations (ICLR) , 2020. [Online]. Available: https://openreview.net/forum?id=HJxyZkBKDr Penglin Dai (S’15-M’17) received the B.S. degree in mathematics and applied mathematics and the Ph.D. degree in comput...
work page 2020
-
[50]
Lixin Duan ((Member, IEEE) received the B.E
His research interests include artificial intelligence, computer vision, multimedia information retrieval, and image/video computing. Lixin Duan ((Member, IEEE) received the B.E. degree from the University of Science and Tech- nology of China, Hefei, China, in 2008, and the Ph.D. degree from Nanyang Technological Univer- sity, Singapore, in 2012. He is cu...
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.