Do Deep Ensembles Actually Capture Uncertainty in Graph Neural Networks?
Pith reviewed 2026-05-22 07:03 UTC · model grok-4.3
The pith
Deep ensembles provide only marginal gains over single graph neural networks because independently trained models converge to overly similar predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
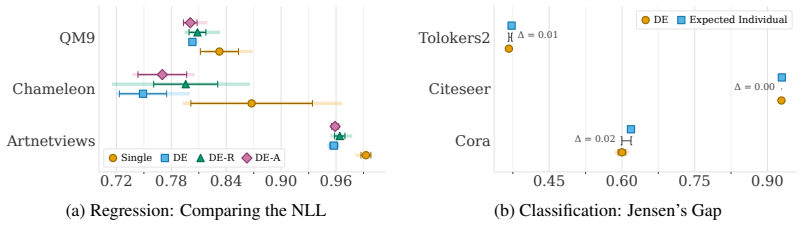
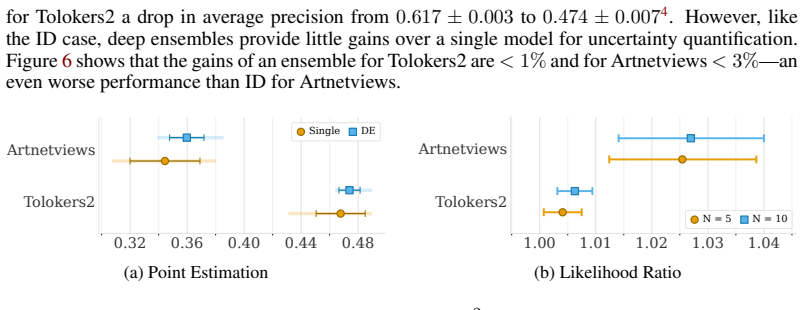
Standard deep ensembles do not transfer their uncertainty-quantification success from other domains to message-passing graph neural networks. Across seven datasets the ensembles deliver only modest improvements over a lone model, and those gains arise chiefly from averaging optimization noise rather than from genuinely richer uncertainty estimates. The root cause is epistemic collapse: independently trained networks consistently produce nearly identical predictions because distinct parameter vectors map to almost the same function, a consequence of functional rather than weight-space convexity.
What carries the argument
Epistemic collapse, the convergence of independently trained networks to nearly identical predictions on graph data despite different parameters, which eliminates the disagreement needed for epistemic uncertainty.
If this is right
- Ensembles cannot be treated as a default reliable method for epistemic uncertainty in graph neural networks.
- Any observed performance lift from ensembles is explained by reduced training noise rather than better uncertainty.
- New uncertainty methods tailored to the functional geometry of graph models are required.
- The transfer of ensemble techniques from vision or tabular data to graphs must be re-examined rather than assumed.
Where Pith is reading between the lines
- The same collapse may appear in other structured prediction settings where the input graph imposes strong functional constraints.
- Single-model uncertainty techniques or explicit diversity-promoting regularizers could be tested as direct remedies.
- If functional convexity is the driver, then architectural changes that increase the expressivity of the message-passing layers might restore ensemble diversity.
Load-bearing premise
The lack of prediction diversity is caused by functional convexity in the solution space and occurs generally for message-passing graph neural networks rather than only in the specific architectures and seven datasets examined.
What would settle it
Observing substantially higher prediction disagreement and correspondingly stronger uncertainty calibration from ensembles on a new collection of graph datasets or architectures would falsify the central claim.
Figures







read the original abstract
While deep ensembles are widely considered to be the default method for uncertainty quantification in deep learning, their effectiveness for graph-structured data is often simply assumed based on successes in domains like computer vision. We investigate standard deep ensembles specifically for message-passing graph neural networks. Benchmarking across seven datasets representing varied tasks and complexities, we reveal that ensembles provide surprisingly little improvement over a single model. Instead, the observed marginal gains stem primarily from stabilizing optimization noise in point predictions rather than yielding meaningfully better uncertainty estimates. Through an aleatoric-epistemic decomposition, we identify epistemic collapse: independently trained networks consistently converge to overly similar predictions. Because disagreement is the fundamental mechanism through which ensembles capture epistemic uncertainty, this lack of diversity neutralizes their key advantage. Analyzing this phenomenon further, we suggest this collapse is driven by functional rather than weight-space convexity, where distinct parameter solutions induce almost identical behavior. Our results suggest that deep ensemble success does not seamlessly transfer to graph machine learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks deep ensembles as an uncertainty quantification method for message-passing graph neural networks. Across seven datasets, it reports that ensembles yield only marginal gains over single models, which arise mainly from stabilizing optimization noise in point predictions rather than from meaningfully improved uncertainty estimates. Using an aleatoric-epistemic decomposition, the authors identify epistemic collapse: independently trained networks converge to overly similar predictions. They attribute this to functional (rather than weight-space) convexity and conclude that deep-ensemble success does not transfer to graph machine learning.
Significance. If the central empirical findings hold, the work usefully challenges the default transfer of deep-ensemble uncertainty methods to GNNs and motivates GNN-specific alternatives. The aleatoric-epistemic decomposition and the explicit link between prediction similarity and the failure of disagreement-based epistemic uncertainty constitute a clear, falsifiable analysis. The paper's strength lies in its reproducible benchmarking protocol and the introduction of the epistemic-collapse observation as a concrete phenomenon to be explained or mitigated.
major comments (2)
- [§4] §4 (Experimental results): The claim that epistemic collapse is characteristic of message-passing GNNs in general rests on the seven chosen datasets and standard GCN/GIN architectures. Without ablations on alternative layers (GAT, GraphSAGE), heterophilic graphs, or larger-scale datasets, it remains possible that the observed prediction similarity is an artifact of the specific inductive biases, optimization settings, or dataset homophily rather than a general property; this directly affects the load-bearing conclusion that ensembles cannot capture epistemic uncertainty in GNNs.
- [§3.3] §3.3 (Aleatoric-epistemic decomposition): The decomposition treats disagreement across ensemble members as the primary source of epistemic uncertainty. The manuscript should explicitly verify that the chosen diversity metric remains valid under graph-structured dependencies (e.g., message-passing correlations) and report sensitivity to the number of ensemble members and training seeds; otherwise the quantitative attribution of marginal gains to optimization stabilization rather than uncertainty improvement is not fully isolated.
minor comments (2)
- [Abstract] Abstract and §1: The seven datasets are described only as 'representing varied tasks and complexities'; listing their names, sizes, and task types (node classification, graph classification, etc.) would allow readers to assess coverage immediately.
- [§4] Figure captions and §4: Ensure all figures reporting ensemble vs. single-model metrics include error bars over multiple random seeds and clearly label the uncertainty decomposition components.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments help clarify the scope and robustness of our findings on epistemic collapse in deep ensembles for message-passing GNNs. We address each major comment point-by-point below, indicating revisions made to the manuscript where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (Experimental results): The claim that epistemic collapse is characteristic of message-passing GNNs in general rests on the seven chosen datasets and standard GCN/GIN architectures. Without ablations on alternative layers (GAT, GraphSAGE), heterophilic graphs, or larger-scale datasets, it remains possible that the observed prediction similarity is an artifact of the specific inductive biases, optimization settings, or dataset homophily rather than a general property; this directly affects the load-bearing conclusion that ensembles cannot capture epistemic uncertainty in GNNs.
Authors: We appreciate the referee's emphasis on generalizability. Our experiments deliberately focused on canonical message-passing architectures (GCN and GIN) across seven datasets chosen to span different scales, tasks, and homophily levels, as these represent the most common inductive biases in the literature. We attribute epistemic collapse to functional convexity arising from the shared message-passing update rule rather than specific layer details. To address the concern, we have added new ablations in the revised Section 4 using GAT and GraphSAGE on both a homophilic dataset and a heterophilic one (Chameleon). These confirm similar levels of prediction similarity across ensemble members. For larger-scale datasets, we acknowledge practical compute limits prevented full replication but have expanded the discussion of scalability and potential limitations in the revised text. We believe these additions support the conclusion for standard message-passing GNNs while noting that future work could explore even broader settings. revision: yes
-
Referee: [§3.3] §3.3 (Aleatoric-epistemic decomposition): The decomposition treats disagreement across ensemble members as the primary source of epistemic uncertainty. The manuscript should explicitly verify that the chosen diversity metric remains valid under graph-structured dependencies (e.g., message-passing correlations) and report sensitivity to the number of ensemble members and training seeds; otherwise the quantitative attribution of marginal gains to optimization stabilization rather than uncertainty improvement is not fully isolated.
Authors: Thank you for this methodological suggestion. The diversity metric (prediction variance across members) is computed on the final node or graph outputs after message passing, so graph-induced correlations are already reflected in the forward passes of each network. To explicitly verify robustness, we have added sensitivity analyses in the revised Section 3.3 and a new appendix subsection. These vary ensemble size (3 to 10 members) and training seeds, showing that the observed low disagreement and attribution of gains to optimization stabilization remain consistent. We also include a brief check correlating the metric with an alternative epistemic uncertainty proxy on a controlled synthetic graph task. These revisions better isolate the effects and strengthen the aleatoric-epistemic decomposition. revision: yes
Circularity Check
No circularity: empirical observations on prediction similarity
full rationale
The paper is an empirical benchmarking study across seven datasets that directly measures prediction agreement among independently trained message-passing GNNs and reports marginal ensemble gains. No derivation chain, fitted-parameter prediction, or self-referential equation is present; the central observation of epistemic collapse follows from explicit experimental comparisons rather than reducing to inputs by construction. Self-citations, if any, are not load-bearing for the reported results, which remain falsifiable via the stated benchmarks and decomposition procedure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Disagreement among ensemble members is the primary mechanism for capturing epistemic uncertainty
invented entities (1)
-
epistemic collapse
no independent evidence
Reference graph
Works this paper leans on
-
[1]
T. Abe, E. K. Buchanan, G. Pleiss, R. Zemel, and J. P. Cunningham. Deep ensembles work, but are they necessary? InAdvances in Neural Information Processing Systems, 2022. Cited on page 7
work page 2022
-
[2]
S. Ainsworth, J. Hayase, and S. Srinivasa. Git Re-Basin: Merging Models modulo Permuta- tion Symmetries. InInternational Conference on Learning Representations, 2023. Cited on page 9
work page 2023
-
[3]
G. Bazhenov, S. Ivanov, M. Panov, A. Zaytsev, and E. Burnaev. Towards OOD De- tection in Graph Classification from Uncertainty Estimation Perspective.arXiv preprint arXiv:2206.10691, 2022. Cited on page 3
-
[4]
G. Bazhenov, D. Kuznedelev, A. Malinin, A. Babenko, and L. Prokhorenkova. Evaluating Robustness and Uncertainty of Graph Models Under Structural Distributional Shifts. InAd- vances in Neural Information Processing Systems, 2023. Cited on pages 3, 13
work page 2023
-
[5]
G. Bazhenov, O. Platonov, and L. Prokhorenkova. GraphLand: Evaluating Graph Machine Learning Models on Diverse Industrial Data. InThe Thirty-ninth Annual Conference on Neu- ral Information Processing Systems Datasets and Benchmarks Track, 2025. Cited on pages 4, 5, 14, 15
work page 2025
-
[6]
C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra. Weight uncertainty in neural networks. InInternational Conference on International Conference on Machine Learning,
-
[7]
V . Borovitskiy. PeMS Regression: A Benchmark Suite for Node Regression with Uncertainty, 2025.URL:https://github.com/vabor112/pems- regression. Cited on pages 2–4, 13
work page 2025
-
[8]
V . Borovitskiy, I. Azangulov, A. Terenin, P. Mostowsky, M. Deisenroth, and N. Durrande. Mat´ern Gaussian processes on graphs. InInternational Conference on Artificial Intelligence and Statistics, 2021. Cited on pages 3, 4
work page 2021
- [9]
-
[10]
J. Busk, P. Bjørn Jørgensen, A. Bhowmik, M. N. Schmidt, O. Winther, and T. Vegge. Cal- ibrated uncertainty for molecular property prediction using ensembles of message passing neural networks.Machine Learning: Science and Technology, 3, 2021. Cited on page 3
work page 2021
-
[11]
S. Depeweg, J.-M. Hernandez-Lobato, F. Doshi-Velez, and S. Udluft. Decomposition of Un- certainty in Bayesian Deep Learning for Efficient and Risk-sensitive Learning. InInterna- tional Conference on Machine Learning, 2018. Cited on page 3
work page 2018
-
[12]
T. G. Dietterich. Ensemble Methods in Machine Learning. InMultiple Classifier Systems,
- [13]
-
[14]
R. Entezari, H. Sedghi, O. Saukh, and B. Neyshabur. The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks. InInternational Conference on Learning Representations, 2022. Cited on page 9
work page 2022
-
[15]
M. Fellaji and F. Pennerath. The Epistemic Uncertainty Hole: an issue of Bayesian Neural Networks, 2024. Cited on page 7
work page 2024
- [16]
-
[17]
V . Fung, J. Zhang, E. Juarez, and B. G. Sumpter. Benchmarking graph neural networks for materials chemistry.npj Computational Materials, 7(1):84, 2021. Cited on page 5
work page 2021
-
[18]
R. Garnett.Bayesian optimization. Cambridge University Press, 2023. Cited on page 1. 10
work page 2023
- [19]
-
[20]
X. Glorot and Y . Bengio. Understanding the difficulty of training deep feedforward neural networks. InInternational Conference on Artificial Intelligence and Statistics, 2010. Cited on page 13
work page 2010
-
[21]
A. Graves. Practical Variational Inference for Neural Networks. InAdvances in Neural Infor- mation Processing Systems, 2011. Cited on page 13
work page 2011
-
[22]
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger. On calibration of modern neural networks. InInternational Conference on Machine Learning, 2017. Cited on page 5
work page 2017
-
[23]
L. Hirschfeld, K. Swanson, K. Yang, R. Barzilay, and C. W. Coley. Uncertainty Quantification Using Neural Networks for Molecular Property Prediction.Journal of Chemical Information and Modeling, 60, 2020. Cited on page 3
work page 2020
-
[24]
A. Kendall and Y . Gal. What uncertainties do we need in Bayesian deep learning for computer vision? InAdvances in Neural Information Processing Systems, 2017. Cited on pages 2, 7
work page 2017
-
[25]
T. N. Kipf and M. Welling. Semi-Supervised Classification with Graph Convolutional Net- works. InInternational Conference on Learning Representations, 2017. Cited on pages 1, 2, 5
work page 2017
-
[26]
A. Kirsch. (Implicit) Ensembles of Ensembles: Epistemic Uncertainty Collapse in Large Models.Transactions on Machine Learning Research, 2025. Cited on page 7
work page 2025
- [27]
-
[28]
B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and Scalable Predictive Uncer- tainty Estimation using Deep Ensembles. InAdvances in Neural Information Processing Sys- tems, 2017. Cited on pages 1–5, 7
work page 2017
-
[29]
Q. Lin, S. Yu, K. Sun, W. Zhao, O. Alfarraj, A. Tolba, and F. Xia. Robust Graph Neural Networks via Ensemble Learning.Mathematics, 10, 2022. Cited on page 3
work page 2022
-
[30]
J. Z. Liu, Z. Lin, S. Padhy, D. Tran, T. Bedrax-Weiss, and B. Lakshminarayanan. Simple and principled uncertainty estimation with deterministic deep learning via distance awareness. In Advances in Neural Information Processing Systems, 2020. Cited on page 5
work page 2020
-
[31]
C. Louizos and M. Welling. Multiplicative normalizing flows for variational Bayesian neural networks. InInternational Conference on Machine Learning, 2017. Cited on pages 4, 13
work page 2017
-
[32]
C. Louizos and M. Welling. Structured and efficient variational deep learning with matrix Gaussian posteriors. InInternational Conference on International Conference on Machine Learning, 2016. Cited on page 13
work page 2016
- [33]
-
[34]
H. Manh Bui and A. Liu. Density-Regression: Efficient and Distance-aware Deep Regressor for Uncertainty Estimation under Distribution Shifts. InInternational Conference on Artificial Intelligence and Statistics, 2024. Cited on page 5
work page 2024
-
[35]
P. Mostowsky, V . Dutordoir, I. Azangulov, N. Jaquier, M. J. Hutchinson, A. Ravuri, L. Rozo, A. Terenin, and V . Borovitskiy. The GeometricKernels Package: Heat and Mat ´ern Kernels for Geometric Learning on Manifolds, Meshes, and Graphs.Journal of Machine Learning Research, 2025. Cited on page 2
work page 2025
- [36]
-
[37]
J. Ojha, O. Presacan, P. G. Lind, E. Monteiro, and A. Yazidi. Navigating Uncertainty: A User- Perspective Survey of Trustworthiness of AI in Healthcare.ACM Trans. Comput. Healthcare, 6, 2025. Cited on page 1
work page 2025
-
[38]
Y . Ovadia, E. Fertig, J. Ren, Z. Nado, D. Sculley, S. Nowozin, J. Dillon, B. Lakshmi- narayanan, and J. Snoek. Can you trust your model’s uncertainty? Evaluating predictive un- certainty under dataset shift. InAdvances in Neural Information Processing Systems, 2019. Cited on pages 1, 3, 8, 13. 11
work page 2019
-
[39]
C. M. A. Rahman, G. Bhandari, N. M. Nasrabadi, A. H. Romero, and P. K. Gyawali. Enhanc- ing material property prediction with ensemble deep graph convolutional networks.Frontiers in Materials, 11, 2024. Cited on page 3
work page 2024
-
[40]
L. Ramp ´aˇsek, M. Galkin, V . P. Dwivedi, A. T. Luu, G. Wolf, and D. Beaini. Recipe for a general, powerful, scalable graph transformer. InAdvances in Neural Information Processing Systems, 2022. Cited on page 1
work page 2022
-
[41]
B. Rozemberczki, C. Allen, and R. Sarkar. Multi-Scale attributed node embedding.Journal of Complex Networks, 9, 2021. Cited on page 4
work page 2021
- [42]
- [43]
-
[44]
K. Tran, W. Neiswanger, J. Yoon, Q. Zhang, E. Xing, and Z. W. Ulissi. Methods for comparing uncertainty quantifications for material property predictions.Machine Learning: Science and Technology, 1, 2020. Cited on pages 1, 5
work page 2020
-
[45]
D. Varivoda, R. Dong, S. S. Omee, and J. Hu. Materials Property Prediction with Uncertainty Quantification: A Benchmark Study.arXiv preprint arXiv:2211.02235, 2022. Cited on page 3
-
[46]
P. Veli ˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Li`o, and Y . Bengio. Graph Attention Networks. InInternational Conference on Learning Representations, 2018. Cited on pages 1, 2
work page 2018
-
[47]
T. Vinchurkar, K. Abdelmaqsoud, and J. R. Kitchin. Uncertainty quantification in graph neu- ral networks with shallow ensembles.Machine Learning: Science and Technology, 6, 2025. Cited on page 3
work page 2025
-
[48]
F. Wang, Y . Liu, K. Liu, Y . Wang, S. Medya, and P. S. Yu. Uncertainty in Graph Neural Networks: A Survey.Transactions on Machine Learning Research, 2024. Cited on page 1
work page 2024
-
[49]
Y . Wen, P. Vicol, J. Ba, D. Tran, and R. Grosse. Flipout: Efficient Pseudo-Independent Weight Perturbations on Mini-Batches.arXiv preprint arXiv:1803.04386, 2018. Cited on pages 4, 13
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [50]
-
[51]
M. Wortsman, G. Ilharco, S. Y . Gadre, R. Roelofs, R. Gontijo-Lopes, A. S. Morcos, H. Namkoong, A. Farhadi, Y . Carmon, S. Kornblith, and L. Schmidt. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. InInternational Conference on Machine Learning, 2022. Cited on pages 8, 14
work page 2022
-
[52]
F. Wu, A. Souza, T. Zhang, C. Fifty, T. Yu, and K. Weinberger. Simplifying Graph Convolu- tional Networks. InInternational Conference on Machine Learning, 2019. Cited on page 8
work page 2019
-
[53]
Z. Wu, B. Ramsundar, E. N. Feinberg, J. Gomes, C. Geniesse, A. S. Pappu, K. Leswing, and V . Pande. MoleculeNet: a benchmark for molecular machine learning.Chemical Science, 9,
-
[54]
K. Xu, W. Hu, J. Leskovec, and S. Jegelka. How Powerful are Graph Neural Networks? In International Conference on Learning Representations, 2019. Cited on page 1
work page 2019
-
[55]
Z. Yang, W. W. Cohen, and R. Salakhutdinov. Revisiting semi-supervised learning with graph embeddings. InInternational Conference on International Conference on Machine Learning,
-
[56]
Q. Zhu, W. Li, H. Kim, Y . Xiang, K. Wardega, Z. Wang, Y . Wang, H. Liang, C. Huang, J. Fan, and H. Choi. Know the unknowns: addressing disturbances and uncertainties in autonomous systems. InInternational Conference on Computer-Aided Design, 2020. Cited on page 1. 12 A Extra Details on the Experiments Conducted Like in the main text each experiment is re...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.