Localization then Neutralization: Gradient-guided Token Suppression against Visual Prompt Injection Attack
Pith reviewed 2026-06-30 12:16 UTC · model grok-4.3
The pith
Masking a few gradient-identified image tokens neutralizes visual prompt injection attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Successful adversarial attacks on multimodal models depend on a small subset of critical image tokens. Gradient Token Masking attributes influence to tokens via the Hidden-State Gradient Norm score under adversarial inputs, proves this score's ranking matches the full adversarial loss gradient, and neutralizes the attack by masking the top-scoring tokens.
What carries the argument
Gradient Token Masking (GTM) using the Hidden-State Gradient Norm score, which ranks tokens by their influence on generation and enables masking after one forward-backward pass.
If this is right
- Defense requires only one forward-backward pass with no model retraining.
- Attack success rates drop to near zero on both prompt injection and multimodal jailbreak cases.
- Clean input performance is preserved with negligible overhead.
- The same localization principle applies across different attack types tested in the work.
Where Pith is reading between the lines
- Attack paths in vision-language models appear sparse enough that gradient ranking can isolate them without full loss computation.
- The masking threshold or token count could be set dynamically from the gradient score distribution rather than fixed in advance.
- Similar single-pass gradient attribution might extend to localizing vulnerabilities in other input modalities.
Load-bearing premise
That attacks always concentrate on a small number of tokens whose masking stops the attack while leaving clean inputs unaffected.
What would settle it
An experiment in which the top-ranked tokens by hidden-state gradient norm are masked yet the attack success rate remains high on the same adversarial inputs.
Figures






read the original abstract
Adversarial images pose a severe security threat to multimodal large language models through prompt injection. Existing defenses largely lack a principled understanding of the underlying mechanisms and struggle to balance efficiency and defense utility. In this work, we show that successful adversarial attacks do not rely on the entire image uniformly but instead depend on a small subset of critical image tokens. Based on this insight, we propose Gradient Token Masking (GTM), which localizes these tokens via gradient analysis and neutralizes them through masking. We find that attribution based on the first generated token's output probability fails when attacks preserve the predicted token. To overcome this, GTM utilizes the Hidden-State Gradient Norm score for generation-influence attribution under adversarial inputs. We prove that its ranking is consistent with that of the full adversarial loss gradient, providing a theoretical guarantee for accurate localization. Our method requires only a single forward-backward pass to identify and zero out a small number of high-scoring tokens, effectively disrupting the adversarial attack path. Extensive experiments on prompt injection and multimodal jailbreak attacks demonstrate that our approach reduces attack success rates (ASR) to near zero while preserving model utility with negligible computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Gradient Token Masking (GTM) to defend multimodal LLMs against visual prompt injection and jailbreak attacks. It claims that successful attacks depend on only a small subset of critical image tokens; these are localized via the Hidden-State Gradient Norm score, whose ranking is proved consistent with the full adversarial loss gradient. Masking a small number of high-scoring tokens in a single forward-backward pass is asserted to reduce attack success rate to near zero while preserving clean utility and incurring negligible overhead.
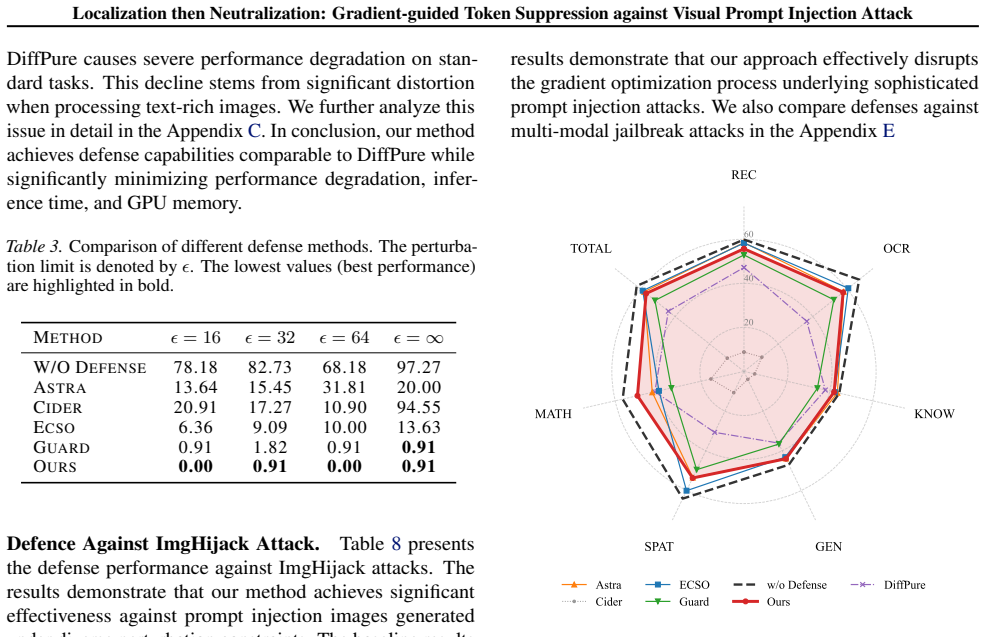
Significance. If the ranking-consistency proof and the empirical neutralization results hold under the stated assumptions, the work would supply an efficient, single-pass defense with a theoretical localization guarantee. This addresses the efficiency-utility trade-off noted for prior defenses and supplies a concrete, falsifiable mechanism (gradient-norm ranking plus masking) that could be tested on additional attack types.
major comments (2)
- [Abstract] Abstract and Method: the proof that the Hidden-State Gradient Norm ranking is consistent with the full adversarial loss gradient is asserted but no derivation, assumptions, or intermediate steps are supplied in the available text. This is load-bearing for the central claim of a 'theoretical guarantee for accurate localization.'
- [Abstract] Abstract and Method: the number of tokens k to mask (explicitly listed as a free parameter) has no selection rule, fixed value, adaptive criterion, or ablation study described. Because neutralization success and clean-accuracy preservation both depend on this choice, the claimed 'near-zero ASR with negligible overhead' cannot be shown to follow from the ranking consistency alone.
minor comments (1)
- [Abstract] Abstract: the phrase 'first generated token's output probability fails when attacks preserve the predicted token' is stated without a concrete counter-example or reference to the failure mode.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments identify load-bearing elements of the central claims. We will revise the manuscript to supply the missing derivation and to address the choice of k with additional analysis and experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract and Method: the proof that the Hidden-State Gradient Norm ranking is consistent with the full adversarial loss gradient is asserted but no derivation, assumptions, or intermediate steps are supplied in the available text. This is load-bearing for the central claim of a 'theoretical guarantee for accurate localization.'
Authors: We agree that the proof is central and that its absence from the submitted text weakens the claim. The full manuscript contains a brief statement of the result but omits the derivation. In the revision we will insert a dedicated subsection (or appendix) that states the assumptions, provides the intermediate steps, and shows why the ranking of the Hidden-State Gradient Norm is consistent with the ranking induced by the full adversarial loss gradient. revision: yes
-
Referee: [Abstract] Abstract and Method: the number of tokens k to mask (explicitly listed as a free parameter) has no selection rule, fixed value, adaptive criterion, or ablation study described. Because neutralization success and clean-accuracy preservation both depend on this choice, the claimed 'near-zero ASR with negligible overhead' cannot be shown to follow from the ranking consistency alone.
Authors: We acknowledge that k is treated as a hyper-parameter without an explicit selection procedure or supporting ablation in the current version. In the revision we will add (i) an ablation study over a range of k values on both attack success rate and clean accuracy, (ii) a simple heuristic rule (e.g., mask the top 1–2 % of tokens or until the gradient-norm score drops below a threshold), and (iii) discussion of how this choice trades off defense strength against utility. These additions will make the empirical claims traceable to concrete choices of k. revision: yes
Circularity Check
No circularity: derivation relies on independent gradient ranking proof
full rationale
The paper's core derivation is a claimed mathematical proof that the Hidden-State Gradient Norm produces a ranking consistent with the full adversarial loss gradient; this is presented as a theoretical guarantee independent of any fitted parameters or self-referential definitions. The neutralization step (zeroing a small number of tokens) is described as following from this ranking without evidence in the abstract that the token count k or threshold is chosen via fitting that would make the ASR reduction tautological. No self-citations, ansatzes smuggled via prior work, or uniqueness theorems from the same authors are invoked in the provided text. The method is self-contained against external benchmarks via the single forward-backward pass and empirical ASR/utility results.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of tokens to mask (k)
axioms (1)
- domain assumption Hidden-state gradient norm ranking is consistent with full adversarial loss gradient ranking
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
URLhttps://arxiv.org/abs/2404.14219. Bagdasaryan, E., Hsieh, T.-Y ., Nassi, B., and Shmatikov, V . Abusing images and sounds for indirect instruc- tion injection in multi-modal llms.arXiv preprint arXiv:2307.10490,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Vpi-bench: Visual prompt injection attacks for computer-use agents.arXiv preprint arXiv:2506.02456,
Cao, T., Lim, B., Liu, Y ., Sui, Y ., Li, Y ., Deng, S., Lu, L., Oo, N., Yan, S., and Hooi, B. Vpi-bench: Visual prompt injection attacks for computer-use agents.arXiv preprint arXiv:2506.02456,
-
[3]
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
Chen, B., Lyu, X., Yuan, S., Song, J., Shen, H. T., and Gao, L. SafePTR: Token-level jailbreak defense in multimodal LLMs via prune-then-restore mechanism. InThe Thirty-ninth Annual Conference on Neural In- formation Processing Systems, 2025a. URL https: //openreview.net/forum?id=MNSiBGNAvx. Chen, J., Zhu, D., Shen, X., Li, X., Liu, Z., Zhang, P., Krish- ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
A survey of attacks on large vision-language models: Resources, advances, and future trends, 2024a
Liu, D., Yang, M., Qu, X., Zhou, P., Cheng, Y ., and Hu, W. A survey of attacks on large vision-language models: Resources, advances, and future trends, 2024a. URL https://arxiv.org/abs/2407.07403. Liu, H., Li, C., Wu, Q., and Lee, Y . J. Visual instruction tun- ing.Advances in neural information processing systems, 36:34892–34916,
-
[5]
Ma, F., Zhang, C., Ren, L., Wang, J., Wang, Q., Wu, W., Quan, X., and Song, D
URL https://openreview.net/forum? id=nc5GgFAvtk. Ma, F., Zhang, C., Ren, L., Wang, J., Wang, Q., Wu, W., Quan, X., and Song, D. Xprompt: Exploring the extreme of prompt tuning. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11033–11047, 2022a. Ma, K., Xu, Q., Zeng, J., Li, G., Cao, X., and Huang, Q. A tale of...
-
[6]
Pei, G., Lyu, S., Chen, G., Ma, K., Xu, Q., Sun, Y ., and Huang, Q. Divide and conquer: Heterogeneous noise integration for diffusion-based adversarial purification. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 29268–29277, 2025a. doi: 10.1109/CVPR52734.2025.02725. Pei, G., Ma, K., Sun, Y ., Xu, Q., and Huang, Q. Diffu...
-
[7]
URL https://openreview. net/forum?id=wvFnqVVUhN. Shi, T., Zhu, K., Wang, Z., Jia, Y ., Cai, W., Liang, W., Wang, H., Alzahrani, H., Lu, J., Kawaguchi, K., et al. Promp- tarmor: Simple yet effective prompt injection defenses. arXiv preprint arXiv:2507.15219,
-
[8]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Simonyan, K., Vedaldi, A., and Zisserman, A. Deep in- side convolutional networks: Visualising image clas- sification models and saliency maps.arXiv preprint arXiv:1312.6034,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Wang, H., Wang, G., and Zhang, H. Steering away from harm: An adaptive approach to defending vision language model against jailbreaks. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 29947–29957, 2025a. doi: 10.1109/CVPR52734.2025. 02787. Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J.,...
-
[10]
Yu, W., Yang, Z., Li, L., Wang, J., Lin, K., Liu, Z., Wang, X., and Wang, L
URL https://arxiv.org/ abs/2406.04031. Yu, W., Yang, Z., Li, L., Wang, J., Lin, K., Liu, Z., Wang, X., and Wang, L. Mm-vet: evaluating large multimodal models for integrated capabilities. InProceedings of the 41st International Conference on Machine Learning, pp. 57730–57754,
-
[11]
Universal and Transferable Adversarial Attacks on Aligned Language Models
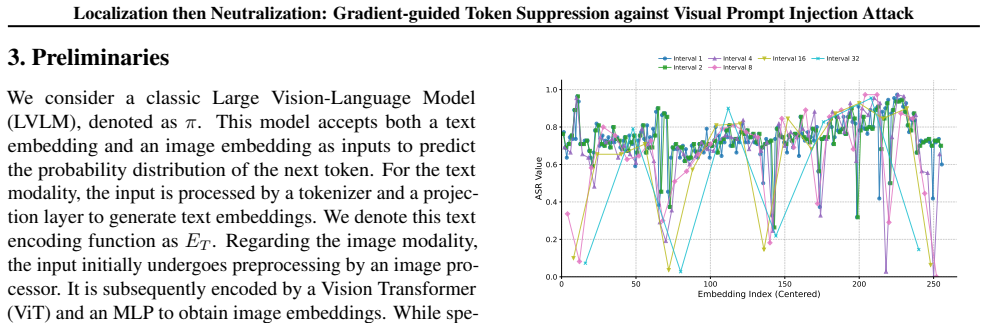
URL https: //arxiv.org/abs/2307.15043. 11 Localization then Neutralization: Gradient-guided Token Suppression against Visual Prompt Injection Attack A. Extended Sliding-Window Masking Experiments 0 50 100 150 200 250 Embedding Index (Centered) 0.0 0.2 0.4 0.6 0.8 1.0ASR Value Interval 1 Interval 2 Interval 4 Interval 8 Interval 16 Interval 32 Figure 5.Res...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.