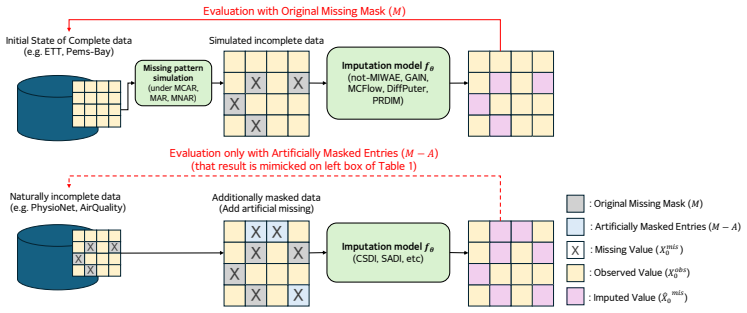
Missing Pattern Recognized Diffusion Imputation Model for Missing Not At Random
Pith reviewed 2026-06-29 23:05 UTC · model grok-4.3
The pith
PRDIM captures missing patterns explicitly via a recognizer and EM to impute MNAR data more accurately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
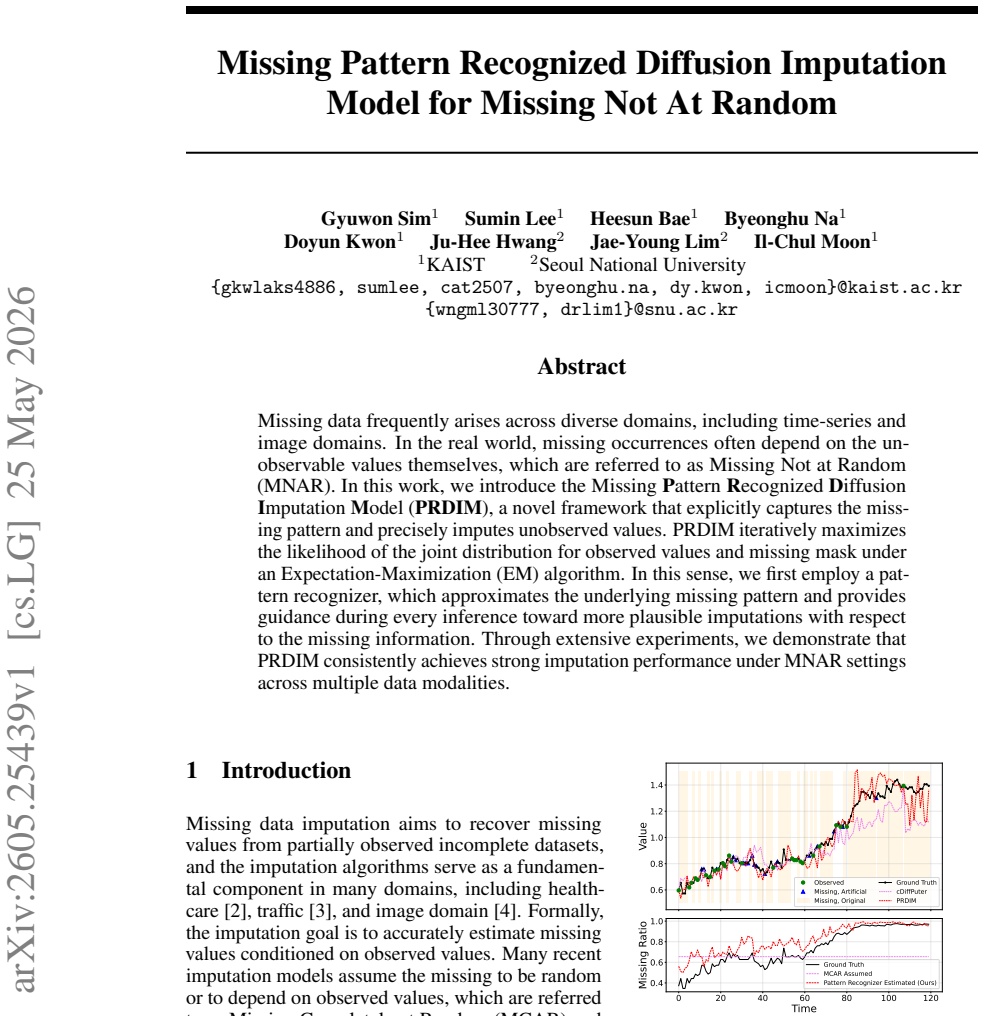
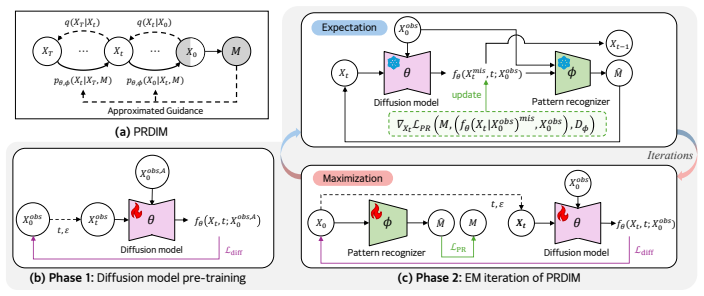
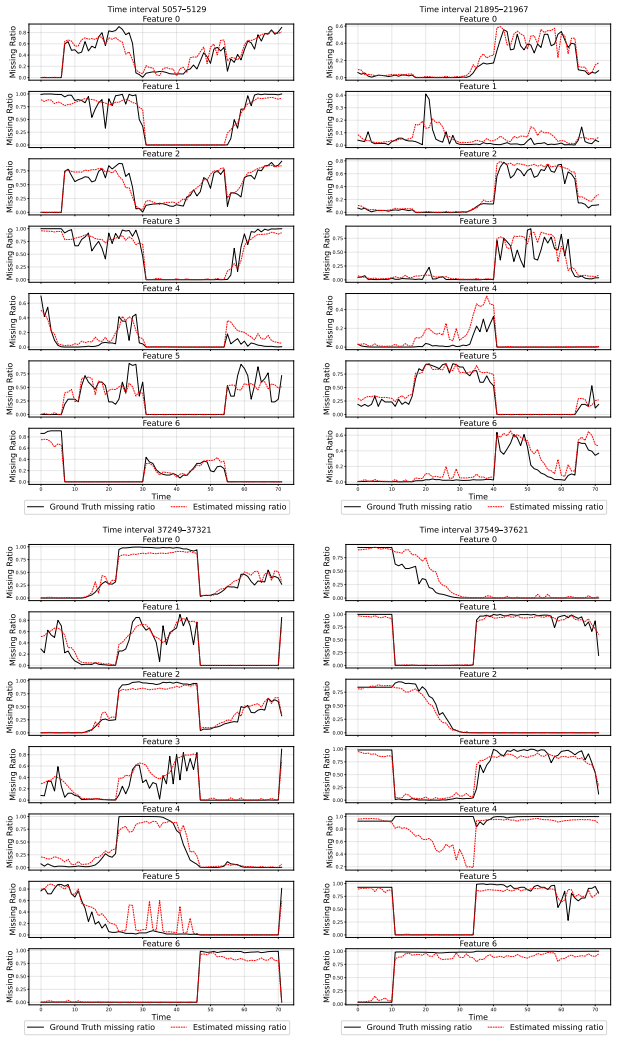
PRDIM iteratively maximizes the likelihood of the joint distribution for observed values and missing mask under an EM algorithm. In this sense, a pattern recognizer approximates the underlying missing pattern and provides guidance during every inference toward more plausible imputations with respect to the missing information.
What carries the argument
Pattern recognizer that approximates the missing pattern to guide diffusion inference within an EM loop maximizing the joint likelihood of data and mask.
If this is right
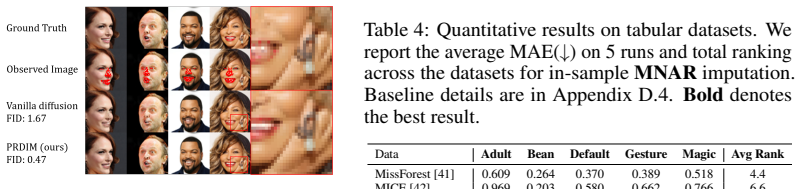
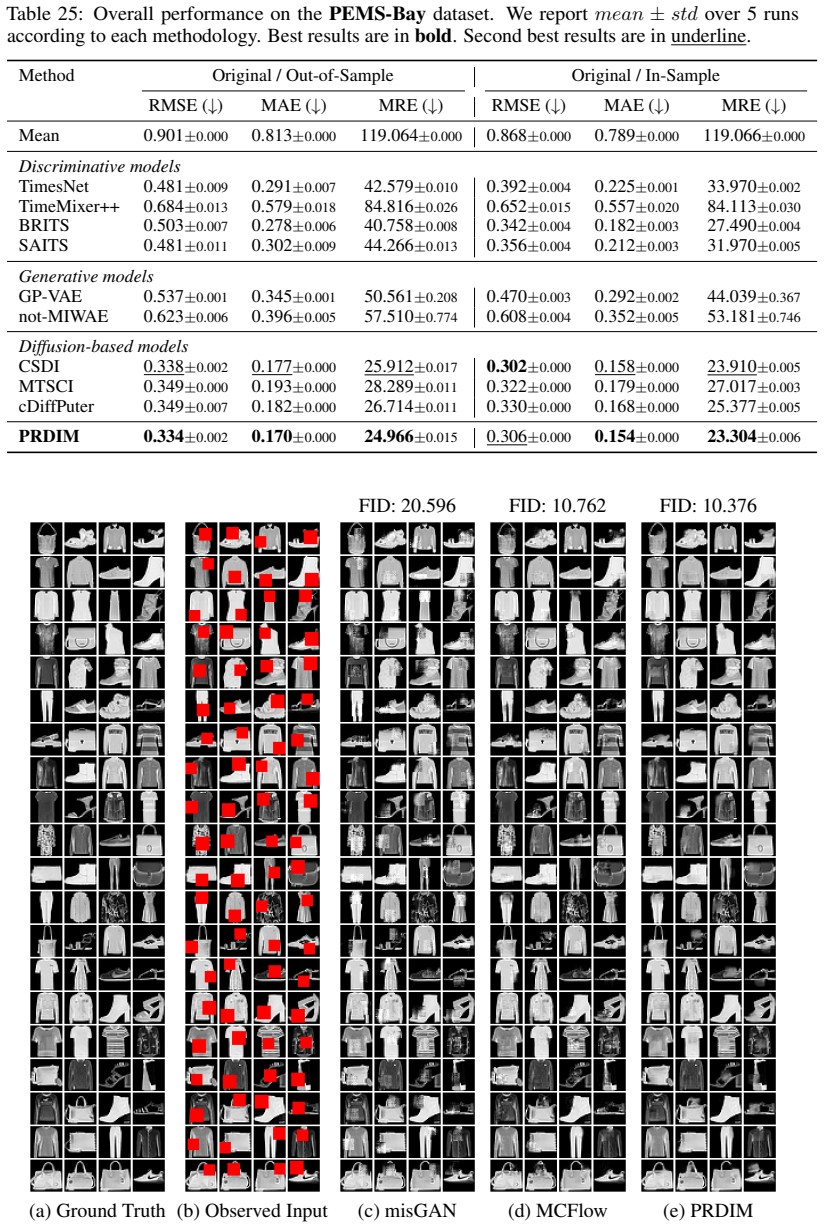
- Strong imputation performance under MNAR settings across time-series and image modalities.
- Explicit modeling of the missing pattern improves plausibility over methods that treat missingness as random.
- The EM procedure allows joint optimization of imputation and pattern estimation in each iteration.
Where Pith is reading between the lines
- The same pattern-recognition idea could be tested in other generative imputation frameworks such as score-based or flow models.
- Downstream tasks like forecasting or classification that use the imputed data may see reduced bias if the MNAR mechanism is better recovered.
- Real-world datasets with documented MNAR mechanisms, such as sensor failures dependent on extreme values, offer direct tests of the method.
Load-bearing premise
The pattern recognizer can sufficiently approximate the underlying missing pattern to provide useful guidance during inference for more plausible imputations.
What would settle it
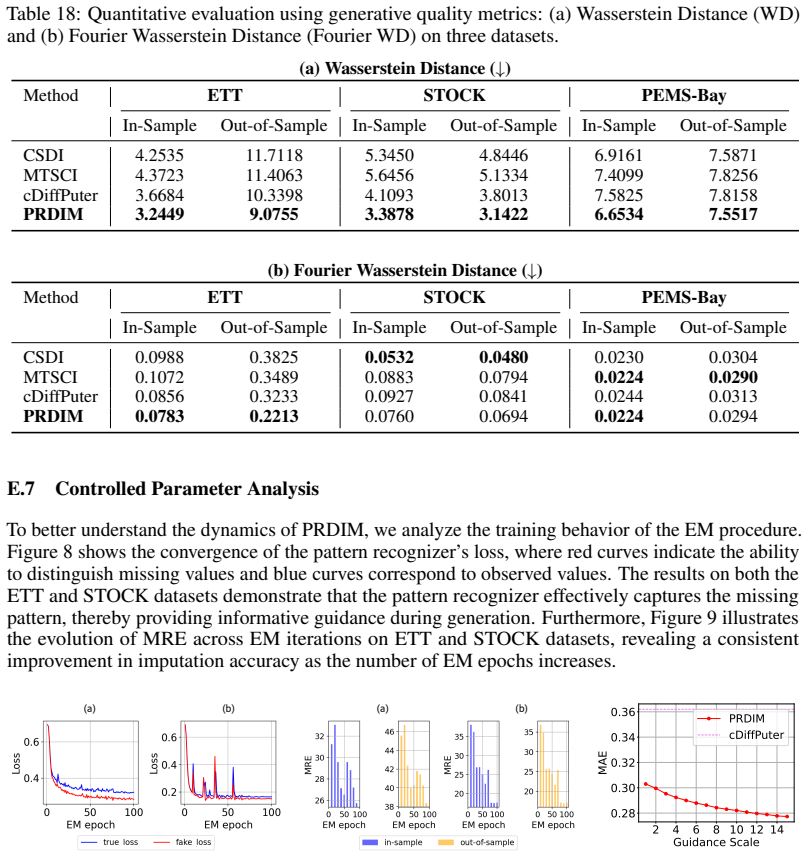
An ablation experiment on MNAR benchmarks where removing the pattern recognizer yields no gain or worse imputation error than a standard diffusion model would falsify the value of explicit pattern capture.
Figures



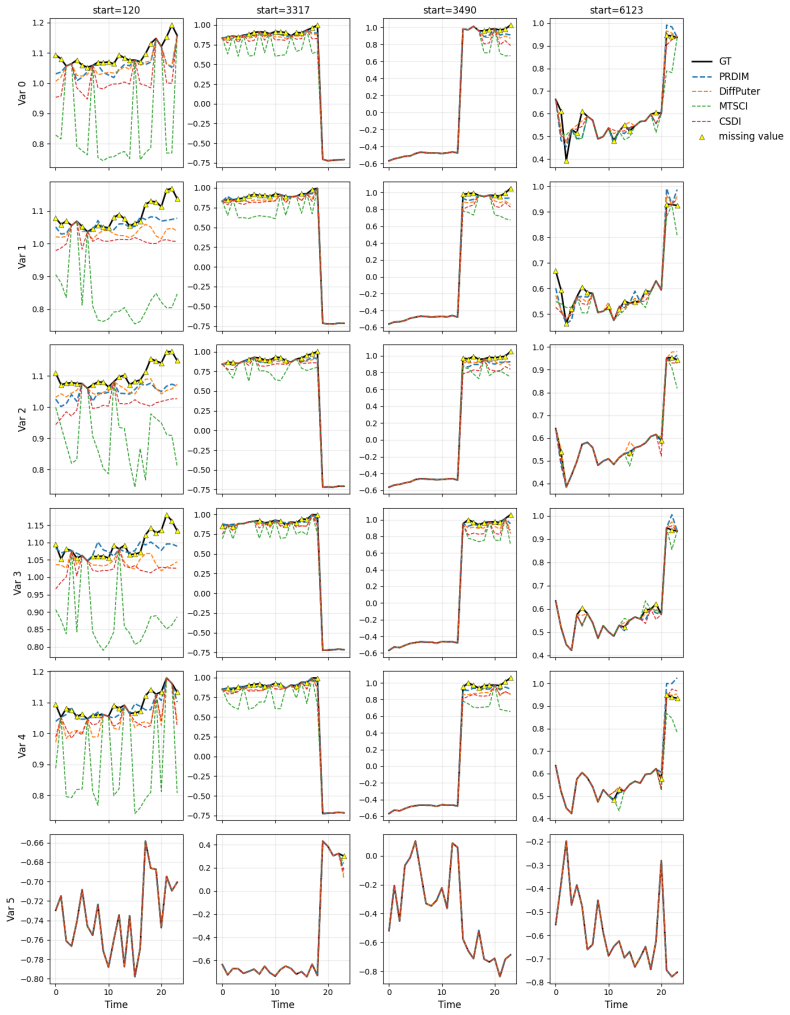
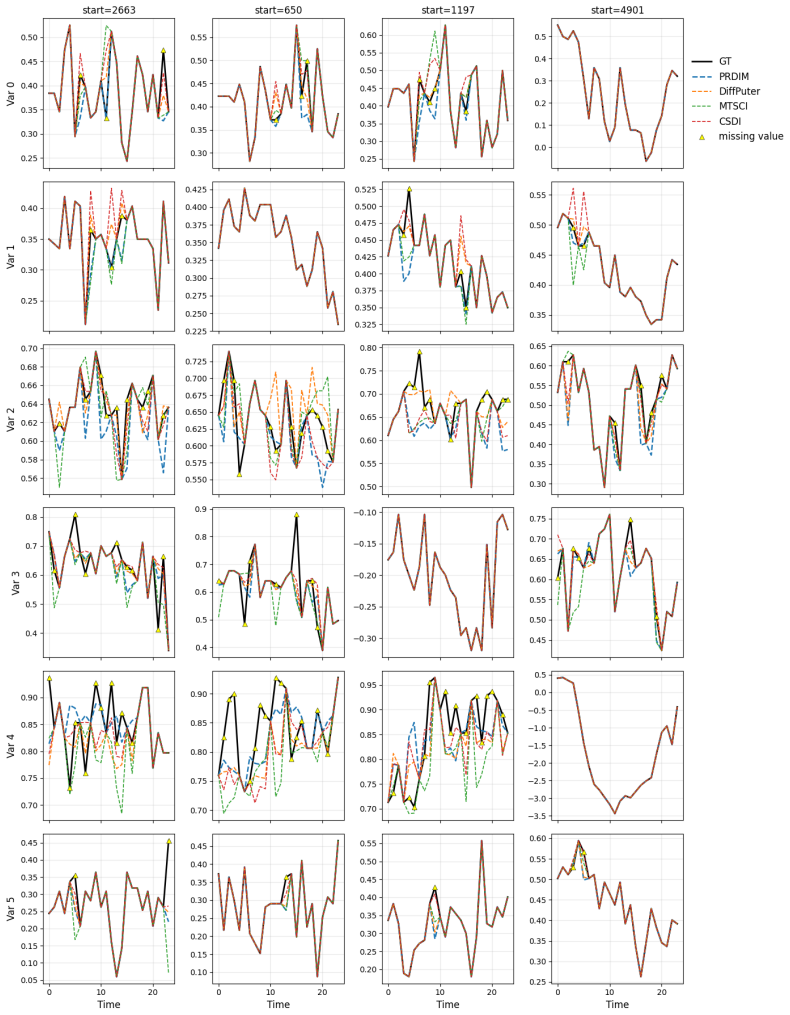
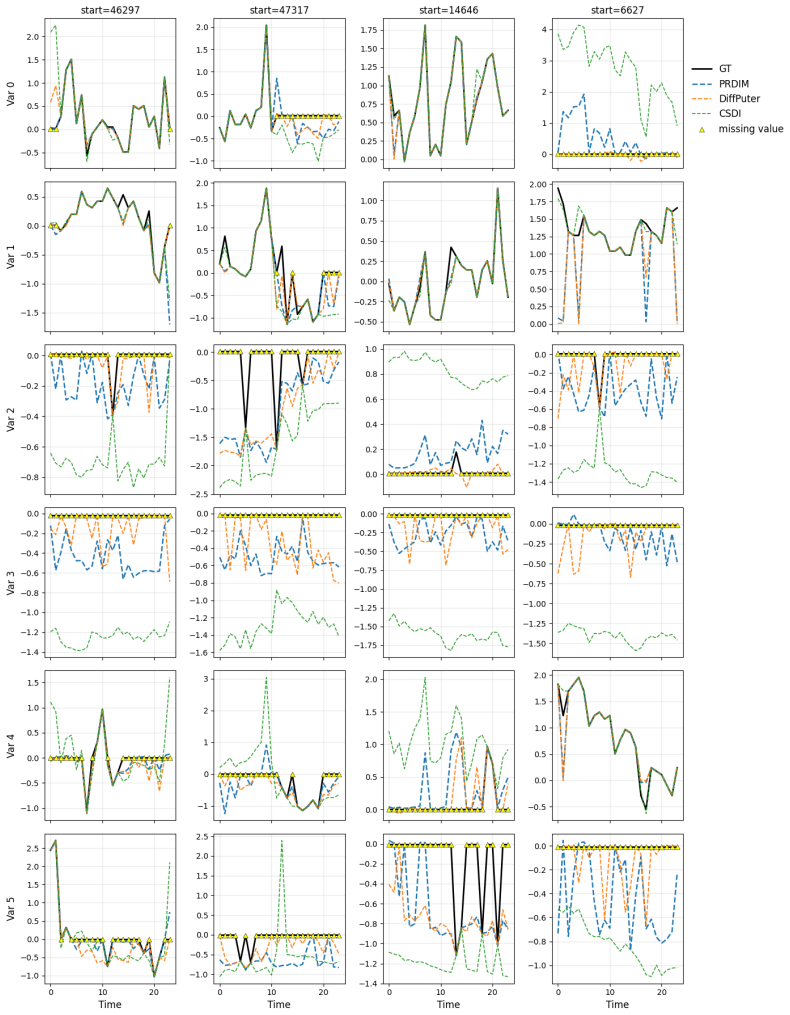
read the original abstract
Missing data frequently arises across diverse domains, including time-series and image domains. In the real world, missing occurrences often depend on the unobservable values themselves, which are referred to as Missing Not at Random (MNAR). In this work, we introduce the Missing Pattern Recognized Diffusion Imputation Model (PRDIM), a novel framework that explicitly captures the missing pattern and precisely imputes unobserved values. PRDIM iteratively maximizes the likelihood of the joint distribution for observed values and missing mask under an Expectation-Maximization (EM) algorithm. In this sense, we first employ a pattern recognizer, which approximates the underlying missing pattern and provides guidance during every inference toward more plausible imputations with respect to the missing information. Through extensive experiments, we demonstrate that PRDIM consistently achieves strong imputation performance under MNAR settings across multiple data modalities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Missing Pattern Recognized Diffusion Imputation Model (PRDIM) for MNAR missing data. It describes an EM procedure that jointly models observed values and the missing mask by embedding a pattern recognizer inside a diffusion imputation framework; the recognizer is said to approximate the missing pattern and guide inference toward plausible imputations. The abstract claims that extensive experiments demonstrate consistently strong imputation performance under MNAR settings across multiple data modalities.
Significance. A correctly specified and empirically validated version of this approach could address a recognized gap in MNAR imputation by making the missingness mechanism explicit within a generative diffusion model. The EM-plus-recognizer structure is a standard strategy for MNAR problems, so the contribution would lie in the concrete integration and any performance gains shown on standard benchmarks.
major comments (2)
- [Abstract] Abstract: the claim of 'strong imputation performance' and 'extensive experiments' is unsupported because the manuscript supplies no information on datasets, baselines, metrics, validation splits, or statistical significance tests, rendering the central empirical claim impossible to evaluate.
- [Methods] Methods (entire section): no equations, loss functions, or derivation details are given for the EM procedure, the pattern recognizer architecture, its integration with the diffusion model, or the imputation step, so it is impossible to verify whether the recognizer supplies independent guidance or merely reproduces quantities already defined by the fitted model.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive suggestions. We agree that both the abstract and methods section require substantial expansion to support the claims and enable verification. We will prepare a major revision that supplies the missing experimental details and technical derivations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'strong imputation performance' and 'extensive experiments' is unsupported because the manuscript supplies no information on datasets, baselines, metrics, validation splits, or statistical significance tests, rendering the central empirical claim impossible to evaluate.
Authors: We accept this criticism. The current abstract is overly terse and does not enumerate the concrete experimental protocol. In the revised manuscript we will replace the generic claim with a concise but specific statement that lists the datasets, baselines, metrics, train/validation/test splits, and any significance testing performed, thereby allowing readers to assess the strength of the reported results. revision: yes
-
Referee: [Methods] Methods (entire section): no equations, loss functions, or derivation details are given for the EM procedure, the pattern recognizer architecture, its integration with the diffusion model, or the imputation step, so it is impossible to verify whether the recognizer supplies independent guidance or merely reproduces quantities already defined by the fitted model.
Authors: We agree that the methods section as currently written lacks the necessary formalization. The revision will add (i) the complete EM objective and its derivation, (ii) the loss functions optimized by the pattern recognizer and the diffusion model, (iii) the architectural specification of the recognizer, (iv) the precise manner in which its output is injected into the diffusion sampling process, and (v) the imputation procedure. These additions will make explicit whether the recognizer contributes information beyond what is already captured by the fitted joint model. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript describes PRDIM as an EM procedure that jointly models observed data and missing mask via a pattern recognizer inside a diffusion imputation framework. This is presented as a standard strategy for MNAR problems at a high level, with no equations, derivations, or self-citations provided in the available text that reduce any claimed prediction or result to a fitted quantity or input by construction. The central claim of capturing missing patterns for imputation remains independent of the method's own outputs, and no load-bearing self-referential steps are identifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Diffputer: Empowering diffusion models for missing data imputation
Hengrui Zhang, Liancheng Fang, Qitian Wu, and Philip S Yu. Diffputer: Empowering diffusion models for missing data imputation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[2]
Physiobank, physiotoolkit, and physionet: components of a new research resource for complex physiologic signals.circulation, 101(23):e215–e220, 2000
Ary L Goldberger, Luis AN Amaral, Leon Glass, Jeffrey M Hausdorff, Plamen Ch Ivanov, Roger G Mark, Joseph E Mietus, George B Moody, Chung-Kang Peng, and H Eugene Stanley. Physiobank, physiotoolkit, and physionet: components of a new research resource for complex physiologic signals.circulation, 101(23):e215–e220, 2000
2000
-
[3]
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
Yaguang Li, Rose Yu, Cyrus Shahabi, and Yan Liu. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting.arXiv preprint arXiv:1707.01926, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Statistical analysis with missing data.New York: Wiley, 1987
Roderick JA Little and Donald B Rubin. Statistical analysis with missing data.New York: Wiley, 1987
1987
-
[6]
CRC press, 1997
Joseph L Schafer.Analysis of incomplete multivariate data. CRC press, 1997
1997
-
[7]
Missing not at random in end of life care studies: multiple imputation and sensitivity analysis on data from the action study.BMC medical research methodology, 21(1):13, 2021
Giulia Carreras, Guido Miccinesi, Andrew Wilcock, Nancy Preston, Daan Nieboer, Luc Deliens, Mogensm Groenvold, Urska Lunder, Agnes van der Heide, Michela Baccini, et al. Missing not at random in end of life care studies: multiple imputation and sensitivity analysis on data from the action study.BMC medical research methodology, 21(1):13, 2021
2021
-
[8]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[9]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
2021
-
[10]
Csdi: Conditional score-based diffusion models for probabilistic time series imputation.Advances in neural information processing systems, 34:24804–24816, 2021
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. Csdi: Conditional score-based diffusion models for probabilistic time series imputation.Advances in neural information processing systems, 34:24804–24816, 2021
2021
-
[11]
Mtsci: A conditional diffusion model for multivariate time series consistent imputation
Jianping Zhou, Junhao Li, Guanjie Zheng, Xinbing Wang, and Chenghu Zhou. Mtsci: A conditional diffusion model for multivariate time series consistent imputation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 3474–3483, 2024
2024
-
[12]
Miwae: Deep generative modelling and imputation of incomplete data sets
Pierre-Alexandre Mattei and Jes Frellsen. Miwae: Deep generative modelling and imputation of incomplete data sets. InInternational conference on machine learning, pages 4413–4423. PMLR, 2019
2019
-
[13]
Niels Bruun Ipsen, Pierre-Alexandre Mattei, and Jes Frellsen. not-miwae: Deep generative modelling with missing not at random data.arXiv preprint arXiv:2006.12871, 2020
-
[14]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[15]
Gain: Missing data imputation using generative adversarial nets
Jinsung Yoon, James Jordon, and Mihaela Schaar. Gain: Missing data imputation using generative adversarial nets. InInternational conference on machine learning, pages 5689–5698. PMLR, 2018
2018
-
[16]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[17]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024. 10
2024
-
[18]
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis.arXiv preprint arXiv:2009.09761, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[19]
Score-based generative modeling of graphs via the system of stochastic differential equations
Jaehyeong Jo, Seul Lee, and Sung Ju Hwang. Score-based generative modeling of graphs via the system of stochastic differential equations. InInternational conference on machine learning, pages 10362–10383. PMLR, 2022
2022
-
[20]
On the constrained time-series generation problem.Advances in Neural Information Processing Systems, 36:61048–61059, 2023
Andrea Coletta, Sriram Gopalakrishnan, Daniel Borrajo, and Svitlana Vyetrenko. On the constrained time-series generation problem.Advances in Neural Information Processing Systems, 36:61048–61059, 2023
2023
-
[21]
Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
2022
-
[22]
Saits: Self-attention-based imputation for time series
Wenjie Du, David Côté, and Yan Liu. Saits: Self-attention-based imputation for time series. Expert Systems with Applications, 219:119619, 2023
2023
-
[23]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[24]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[25]
Dongjun Kim, Yeongmin Kim, Se Jung Kwon, Wanmo Kang, and Il-Chul Moon. Refining generative process with discriminator guidance in score-based diffusion models.arXiv preprint arXiv:2211.17091, 2022
-
[26]
Unified expectation maximization
Rajhans Samdani, Ming-Wei Chang, and Dan Roth. Unified expectation maximization. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 688–698, 2012
2012
-
[27]
Maximum likelihood from incomplete data via the em algorithm.Journal of the royal statistical society: series B (methodological), 39(1):1–22, 1977
Arthur P Dempster, Nan M Laird, and Donald B Rubin. Maximum likelihood from incomplete data via the em algorithm.Journal of the royal statistical society: series B (methodological), 39(1):1–22, 1977
1977
-
[28]
Chapman & Hall/CRC, 2000
Bradley P Carlin, Thomas A Louis, et al.Bayes and empirical Bayes methods for data analysis. Chapman & Hall/CRC, 2000
2000
-
[29]
Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
Bradley Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
2011
-
[30]
Cautionary tales on air-quality improvement in beijing.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 473(2205):20170457, 2017
Shuyi Zhang, Bin Guo, Anlan Dong, Jing He, Ziping Xu, and Song Xi Chen. Cautionary tales on air-quality improvement in beijing.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 473(2205):20170457, 2017
2017
-
[31]
Juan Miguel Lopez Alcaraz and Nils Strodthoff. Diffusion-based time series imputation and forecasting with structured state space models.arXiv preprint arXiv:2208.09399, 2022
-
[32]
Self-supervision improves diffusion models for tabular data imputation
Yixin Liu, Thalaiyasingam Ajanthan, Hisham Husain, and Vu Nguyen. Self-supervision improves diffusion models for tabular data imputation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 1513–1522, 2024
2024
-
[33]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 11106–11115, 2021
2021
-
[34]
Maskgan: Towards diverse and interactive facial image manipulation
Cheng-Han Lee, Ziwei Liu, Lingyun Wu, and Ping Luo. Maskgan: Towards diverse and interactive facial image manipulation. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 11
2020
-
[35]
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. Times- net: Temporal 2d-variation modeling for general time series analysis.arXiv preprint arXiv:2210.02186, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Shiyu Wang, Jiawei Li, Xiaoming Shi, Zhou Ye, Baichuan Mo, Wenze Lin, Shengtong Ju, Zhixuan Chu, and Ming Jin. Timemixer++: A general time series pattern machine for universal predictive analysis.arXiv preprint arXiv:2410.16032, 2024
-
[37]
Brits: Bidirectional recurrent imputation for time series.Advances in neural information processing systems, 31, 2018
Wei Cao, Dong Wang, Jian Li, Hao Zhou, Lei Li, and Yitan Li. Brits: Bidirectional recurrent imputation for time series.Advances in neural information processing systems, 31, 2018
2018
-
[38]
Gp-vae: Deep probabilistic time series imputation
Vincent Fortuin, Dmitry Baranchuk, Gunnar Rätsch, and Stephan Mandt. Gp-vae: Deep probabilistic time series imputation. InInternational conference on artificial intelligence and statistics, pages 1651–1661. PMLR, 2020
2020
-
[39]
MisGAN: Learning from Incomplete Data with Generative Adversarial Networks
Steven Cheng-Xian Li, Bo Jiang, and Benjamin Marlin. Misgan: Learning from incomplete data with generative adversarial networks.arXiv preprint arXiv:1902.09599, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[40]
Mcflow: Monte carlo flow models for data imputation
Trevor W Richardson, Wencheng Wu, Lei Lin, Beilei Xu, and Edgar A Bernal. Mcflow: Monte carlo flow models for data imputation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14205–14214, 2020
2020
-
[41]
Missforest—non-parametric missing value imputation for mixed-type data.Bioinformatics, 28(1):112–118, 2012
Daniel J Stekhoven and Peter Bühlmann. Missforest—non-parametric missing value imputation for mixed-type data.Bioinformatics, 28(1):112–118, 2012
2012
-
[42]
mice: Multivariate imputation by chained equations in r.Journal of statistical software, 45:1–67, 2011
Stef Van Buuren and Karin Groothuis-Oudshoorn. mice: Multivariate imputation by chained equations in r.Journal of statistical software, 45:1–67, 2011
2011
-
[43]
Missing data imputation using optimal transport
Boris Muzellec, Julie Josse, Claire Boyer, and Marco Cuturi. Missing data imputation using optimal transport. InInternational Conference on Machine Learning, pages 7130–7140. PMLR, 2020
2020
-
[44]
Transformed distribution matching for missing value imputation
He Zhao, Ke Sun, Amir Dezfouli, and Edwin V Bonilla. Transformed distribution matching for missing value imputation. InInternational Conference on Machine Learning, pages 42159– 42186. PMLR, 2023
2023
-
[45]
Diffusion models for missing value imputation in tabular data.arXiv preprint arXiv:2210.17128, 2022
Shuhan Zheng and Nontawat Charoenphakdee. Diffusion models for missing value imputation in tabular data.arXiv preprint arXiv:2210.17128, 2022
-
[46]
Hyperimpute: Generalized iterative imputation with automatic model selection
Daniel Jarrett, Bogdan C Cebere, Tennison Liu, Alicia Curth, and Mihaela van der Schaar. Hyperimpute: Generalized iterative imputation with automatic model selection. InInternational Conference on Machine Learning, pages 9916–9937. PMLR, 2022
2022
-
[47]
Diffu- sion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael T McCann, Marc L Klasky, and Jong Chul Ye. Diffu- sion posterior sampling for general noisy inverse problems. In11th International Conference on Learning Representations, ICLR 2023, 2023
2023
-
[48]
Identifiable generative models for missing not at random data imputation.Advances in Neural Information Processing Systems, 34:27645–27658, 2021
Chao Ma and Cheng Zhang. Identifiable generative models for missing not at random data imputation.Advances in Neural Information Processing Systems, 34:27645–27658, 2021
2021
-
[49]
John Wiley & Sons, 2011
Mehmed Kantardzic.Data mining: concepts, models, methods, and algorithms. John Wiley & Sons, 2011
2011
-
[50]
Estimating missing data in temporal data streams using multi-directional recurrent neural networks.IEEE Transactions on Biomedical Engineering, 66(5):1477–1490, 2018
Jinsung Yoon, William R Zame, and Mihaela Van Der Schaar. Estimating missing data in temporal data streams using multi-directional recurrent neural networks.IEEE Transactions on Biomedical Engineering, 66(5):1477–1490, 2018
2018
-
[51]
Naomi: Non-autoregressive multiresolution sequence imputation.Advances in neural information processing systems, 32, 2019
Yukai Liu, Rose Yu, Stephan Zheng, Eric Zhan, and Yisong Yue. Naomi: Non-autoregressive multiresolution sequence imputation.Advances in neural information processing systems, 32, 2019
2019
-
[52]
Wenjie Du, Yiyuan Yang, Linglong Qian, Jun Wang, and Qingsong Wen. PyPOTS: A Python Toolkit for Machine Learning on Partially-Observed Time Series.arXiv preprint arXiv:2305.18811, 2023. 12
-
[53]
Autoregressive denois- ing diffusion models for multivariate probabilistic time series forecasting
Kashif Rasul, Calvin Seward, Ingmar Schuster, and Roland V ollgraf. Autoregressive denois- ing diffusion models for multivariate probabilistic time series forecasting. InInternational conference on machine learning, pages 8857–8868. PMLR, 2021
2021
-
[54]
Diffusion-ts: Interpretable diffusion for general time series genera- tion.CoRR, 2024
Xinyu Yuan and Yan Qiao. Diffusion-ts: Interpretable diffusion for general time series genera- tion.CoRR, 2024
2024
-
[55]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[56]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[57]
pytorch-fid: FID Score for PyTorch
Maximilian Seitzer. pytorch-fid: FID Score for PyTorch. https://github.com/mseitzer/ pytorch-fid, August 2020. Version 0.3.0
2020
-
[58]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[59]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022
2022
-
[60]
Wang Miao, Lan Liu, Eric Tchetgen Tchetgen, and Zhi Geng. Identification, doubly robust estimation, and semiparametric efficiency theory of nonignorable missing data with a shadow variable.arXiv preprint arXiv:1509.02556, 2015
-
[61]
Latent trait shared-parameter mixed models for missing ecological momentary assessment data.Statistics in Medicine, 38(4):660–673, 2019
John F Cursio, Robin J Mermelstein, and Donald Hedeker. Latent trait shared-parameter mixed models for missing ecological momentary assessment data.Statistics in Medicine, 38(4):660–673, 2019
2019
-
[62]
Jasmit S Shah, Shesh N Rai, Andrew P DeFilippis, Bradford G Hill, Aruni Bhatnagar, and Guy N Brock. Distribution based nearest neighbor imputation for truncated high dimensional data with applications to pre-clinical and clinical metabolomics studies.BMC bioinformatics, 18(1):114, 2017
2017
-
[63]
The wasserstein-fourier distance for stationary time series.IEEE Transactions on Signal Processing, 69:709–721, 2020
Elsa Cazelles, Arnaud Robert, and Felipe Tobar. The wasserstein-fourier distance for stationary time series.IEEE Transactions on Signal Processing, 69:709–721, 2020
2020
-
[64]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[65]
Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
2021
-
[66]
Argmax flows and multinomial diffusion: Learning categorical distributions.Advances in neural information processing systems, 34:12454–12465, 2021
Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Argmax flows and multinomial diffusion: Learning categorical distributions.Advances in neural information processing systems, 34:12454–12465, 2021
2021
-
[67]
Tabdiff: a unified diffusion model for multi-modal tabular data generation
Juntong Shi, Minkai Xu, Harper Hua, Hengrui Zhang, Stefano Ermon, and Jure Leskovec. Tabdiff: a unified diffusion model for multi-modal tabular data generation. InNeurIPS 2024 Third Table Representation Learning Workshop, 2024. 13 Appendix A Proofs 15 A.1 Proof of Proposition 3.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 A.2 Proof...
2024
-
[68]
addressed the MNAR scenario by explicitly optimizing a missing model within the ELBO objective, which can inference missing values by missing model weighted importance sampling. Although originally proposed for general imputation tasks, these frameworks have significantly influenced subsequent advances in time-series imputation by highlighting the value o...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.