Provably Communication-Efficient and Privacy-Preserving Federated Graph Neural Networks
Pith reviewed 2026-06-29 23:02 UTC · model grok-4.3
The pith
CE-FedGNN converges to a stationary point at O(1/√T) with O(T^{3/4}) communication by infrequently exchanging moving-average node representations under metric differential privacy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By avoiding per-round embedding exchanges and instead infrequently sharing aggregated node representations tracked by a moving-average estimator, CE-FedGNN handles cross-client dependency and staleness while achieving convergence to a stationary point at rate O(1/√T) with O(T^{3/4}) communication complexity and (ε,δ)-metric-DP guarantees derived from Rényi differential privacy composition under a public-cohort threat model.
What carries the argument
Moving-average estimator that continuously tracks node representations to enable their stable reuse across rounds.
If this is right
- The method supports learning over coupled graphs without raw-data sharing or per-round embedding exchanges.
- Metric differential privacy supplies practical guarantees at noise levels that would be overly conservative under standard differential privacy.
- The O(1/√T) rate and O(T^{3/4}) communication bound hold under the public-cohort threat model.
- Performance remains competitive with centralized training on interbank anti-money-laundering graphs and citation networks even after privacy noise is added.
Where Pith is reading between the lines
- Similar infrequent-exchange techniques could be tested on other relational or temporal federated tasks where full synchronization is costly.
- The public-cohort model might be relaxed or strengthened to cover additional threat scenarios common in distributed graph learning.
- If the estimator remains stable, the same reuse pattern could reduce communication in non-graph federated settings that suffer from client drift.
Load-bearing premise
The moving-average estimator continuously tracks node representations and enables their stable reuse across rounds to handle cross-client dependency and staleness.
What would settle it
An experiment in which the moving-average estimator fails to track representations accurately enough, causing the federated algorithm either to diverge or to produce accuracy no better than a method that ignores cross-client links.
Figures
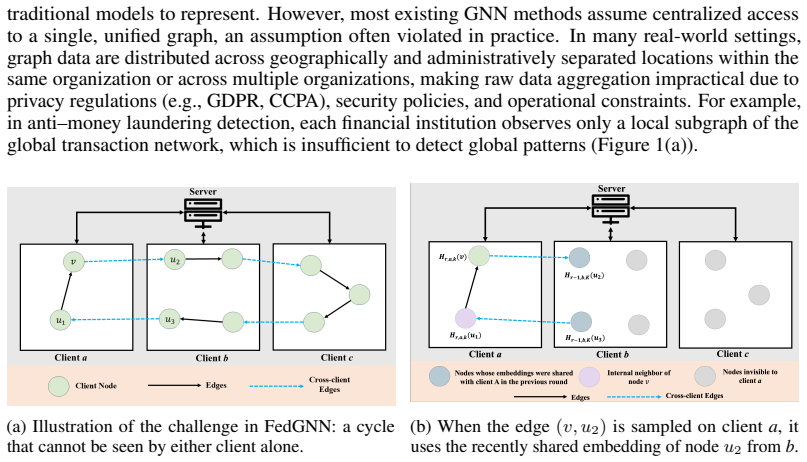


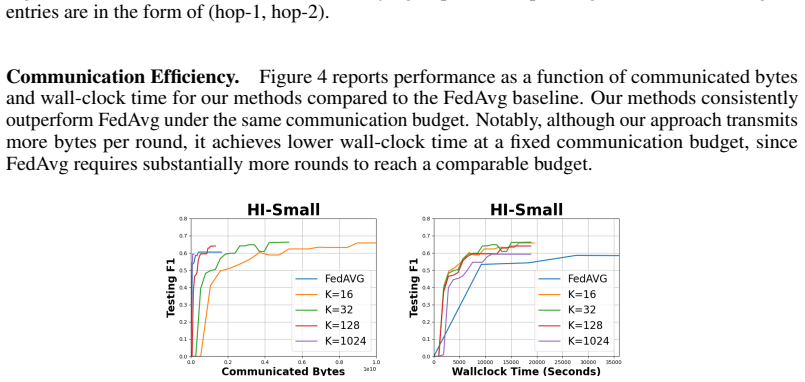
read the original abstract
Graph neural networks (GNNs) achieve strong performance on relational data, but real-world graphs are often distributed across organizations that cannot share raw data due to privacy and policy constraints. Existing federated GNN methods either ignore cross-client links, leading to degraded accuracy, or require frequent embedding exchanges, incurring substantial communication and privacy costs. We propose CE-FedGNN, a communication-efficient and privacy-preserving federated GNN framework for learning over such coupled graphs. Our approach avoids sharing raw data or per-round embeddings by infrequently exchanging aggregated node representations. To handle cross-client dependency and staleness, we introduce a moving-average estimator that continuously tracks node representations and enables their stable reuse across rounds. To provide formal privacy guarantees for the released representations, we adopt the metric differential privacy (metric-DP) framework, which measures privacy with respect to distances in the learned embedding space rather than worst-case input perturbations. This yields meaningful guarantees at noise levels where standard differential privacy becomes overly conservative. We establish convergence to a stationary point at a rate of $O(1/\sqrt{T})$ with $O(T^{3/4})$ communication complexity. In addition, we derive $(\varepsilon,\delta)$-metric-DP guarantees via R\'enyi differential privacy composition under a public-cohort threat model. Experiments on synthetic interbank anti-money laundering benchmarks and citation networks demonstrate that CE-FedGNN achieves strong performance while significantly reducing communication and maintaining robustness under privacy-preserving noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CE-FedGNN, a federated GNN method for graphs distributed across clients with cross-client edges. It replaces per-round embedding exchanges with a moving-average estimator that reuses stale node representations, adopts metric differential privacy on the released aggregates, and claims convergence to a stationary point at rate O(1/√T) together with O(T^{3/4}) communication complexity. It further derives (ε,δ)-metric-DP guarantees via Rényi DP composition under a public-cohort threat model. Experiments on synthetic interbank AML data and citation networks are reported to show competitive accuracy at reduced communication and noise levels.
Significance. If the error analysis for the moving-average estimator can be completed with explicit, summable bounds, the result would constitute a meaningful advance for communication-efficient, privacy-preserving federated GNNs on coupled graphs. The metric-DP framing is a constructive choice that can yield usable noise levels where standard DP is overly conservative.
major comments (1)
- [Abstract / convergence analysis] Abstract and convergence analysis: the claimed O(1/√T) rate under the O(T^{3/4}) communication schedule rests on the moving-average estimator producing an approximation error whose contribution to gradient bias and variance remains o(1/√T) after scaling. No explicit bound on this tracking error is supplied in terms of the number of cross-client edges, client degree, or the communication interval; without such a bound the rate does not follow from standard non-convex stochastic analysis.
minor comments (1)
- [Experiments] The abstract states that experiments demonstrate strong performance, but does not list the concrete baselines, datasets statistics, or privacy-utility trade-off curves; these details belong in the main text or an appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the positive remarks on the metric-DP approach. The single major comment identifies a genuine gap in the convergence analysis, which we address below.
read point-by-point responses
-
Referee: [Abstract / convergence analysis] Abstract and convergence analysis: the claimed O(1/√T) rate under the O(T^{3/4}) communication schedule rests on the moving-average estimator producing an approximation error whose contribution to gradient bias and variance remains o(1/√T) after scaling. No explicit bound on this tracking error is supplied in terms of the number of cross-client edges, client degree, or the communication interval; without such a bound the rate does not follow from standard non-convex stochastic analysis.
Authors: We agree that the manuscript does not currently supply an explicit bound on the tracking error of the moving-average estimator. In the revision we will add a dedicated lemma that bounds this error in terms of the communication interval, the fraction of cross-client edges, and maximum client degree. Under the stated O(T^{3/4}) communication schedule the resulting bias and variance contributions are shown to be o(1/√T), so that the standard non-convex analysis continues to yield the claimed O(1/√T) rate. The new analysis will be placed in the appendix with a clear statement of all assumptions. revision: yes
Circularity Check
No significant circularity; convergence and privacy claims rest on standard analysis plus composition.
full rationale
The abstract states that convergence at O(1/√T) with O(T^{3/4}) communication is established and that (ε,δ)-metric-DP follows from Rényi DP composition. No equation or definition in the provided text reduces the claimed rate or privacy bound to a fitted parameter, a self-referential estimator, or a self-citation chain. The moving-average estimator is introduced as a modeling choice to control staleness; its error contribution is not shown to be defined in terms of the target rate. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- noise levels in metric-DP
axioms (2)
- domain assumption Cross-client links create dependencies that must be handled without raw data sharing
- domain assumption Moving-average estimator can stably track and reuse node representations across rounds
Reference graph
Works this paper leans on
-
[1]
Abadi, A
M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC conference on computer and communications security, pages 308–318, 2016
2016
-
[2]
J. Aliakbari, J. Östman, A. Panahi, et al. Subgraph federated learning via spectral methods. arXiv preprint arXiv:2510.25657, 2025
-
[3]
Allen-Zhu, Y
Z. Allen-Zhu, Y . Li, and Z. Song. A convergence theory for deep learning via over- parameterization. InInternational conference on machine learning, pages 242–252. PMLR, 2019
2019
-
[4]
Altman, J
E. Altman, J. Blanuša, L. V on Niederhäusern, B. Egressy, A. Anghel, and K. Atasu. Real- istic synthetic financial transactions for anti-money laundering models.Advances in Neural Information Processing Systems, 36:29851–29874, 2023
2023
-
[5]
Awasthi, A
P. Awasthi, A. Das, and S. Gollapudi. A convergence analysis of gradient descent on graph neural networks.Advances in Neural Information Processing Systems, 34:20385–20397, 2021
2021
-
[6]
Badrinath, A
A. Badrinath, A. Yang, K. Rajesh, P. Agarwal, J. Yang, H. Chen, J. Xu, and C. Rosenberg. Om- nisage: Large scale, multi-entity heterogeneous graph representation learning. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 4261–4272, 2025
2025
-
[7]
J. Baek, W. Jeong, J. Jin, J. Yoon, and S. J. Hwang. Personalized subgraph federated learning. InInternational conference on machine learning, pages 1396–1415. PMLR, 2023
2023
-
[8]
Bevilacqua, K
B. Bevilacqua, K. Nikiforou, B. Ibarz, I. Bica, M. Paganini, C. Blundell, J. Mitrovic, and P. Veliˇckovi´c. Neural algorithmic reasoning with causal regularisation. InInternational Conference on Machine Learning, pages 2272–2288. PMLR, 2023
2023
-
[9]
Bollegala, S
D. Bollegala, S. Otake, T. Machide, and K.-i. Kawarabayashi. A metric differential privacy mechanism for sentence embeddings.ACM Transactions on Privacy and Security, 28(2):1–34, 2025
2025
-
[10]
Bonawitz, V
K. Bonawitz, V . Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pages 1175–1191, 2017
2017
-
[11]
Bongini, M
P. Bongini, M. Bianchini, and F. Scarselli. Molecular generative graph neural networks for drug discovery.Neurocomputing, 450:242–252, 2021. 10
2021
-
[12]
C. L. Canonne, G. Kamath, and T. Steinke. The discrete gaussian for differential privacy. Advances in Neural Information Processing Systems, 33:15676–15688, 2020
2020
-
[13]
Cardoso, P
M. Cardoso, P. Saleiro, and P. Bizarro. Laundrograph: Self-supervised graph representation learning for anti-money laundering. InProceedings of the third ACM international conference on AI in finance, pages 130–138, 2022
2022
-
[14]
Chatzikokolakis, M
K. Chatzikokolakis, M. E. Andrés, N. E. Bordenabe, and C. Palamidessi. Broadening the scope of differential privacy using metrics. InInternational Symposium on Privacy Enhancing Technologies Symposium, pages 82–102. Springer, 2013
2013
-
[15]
Corso, L
G. Corso, L. Cavalleri, D. Beaini, P. Liò, and P. Veliˇckovi´c. Principal neighbourhood aggregation for graph nets.Advances in neural information processing systems, 33:13260–13271, 2020
2020
-
[16]
A. Daigavane, G. Madan, A. Sinha, A. G. Thakurta, G. Aggarwal, and P. Jain. Node-level differentially private graph neural networks.arXiv preprint arXiv:2111.15521, 2021
-
[17]
Deng and M
Y . Deng and M. Mahdavi. Local stochastic gradient descent ascent: Convergence analysis and communication efficiency. InInternational Conference on Artificial Intelligence and Statistics, pages 1387–1395. PMLR, 2021
2021
-
[18]
Y . Deng, M. M. Kamani, and M. Mahdavi. Distributionally robust federated averaging.Advances in Neural Information Processing Systems, 33:15111–15122, 2020
2020
-
[19]
Derrow-Pinion, J
A. Derrow-Pinion, J. She, D. Wong, O. Lange, T. Hester, L. Perez, M. Nunkesser, S. Lee, X. Guo, B. Wiltshire, et al. Eta prediction with graph neural networks in google maps. InProceedings of the 30th ACM international conference on information & knowledge management, pages 3767–3776, 2021
2021
-
[20]
H. Du, M. Shen, R. Sun, J. Jia, L. Zhu, and Y . Zhai. Malicious transaction identification in digital currency via federated graph deep learning. InIEEE INFOCOM 2022-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), pages 1–6. IEEE, 2022
2022
-
[21]
Duddu, A
V . Duddu, A. Boutet, and V . Shejwalkar. Quantifying privacy leakage in graph embedding. InMobiQuitous 2020-17th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, pages 76–85, 2020
2020
-
[22]
A. J. Dudzik and P. Veliˇckovi´c. Graph neural networks are dynamic programmers.Advances in neural information processing systems, 35:20635–20647, 2022
2022
-
[23]
Dwork and A
C. Dwork and A. Roth. The algorithmic foundations of differential privacy.Foundations and trends® in theoretical computer science, 9(3-4):211–487, 2014
2014
-
[24]
Egressy, L
B. Egressy, L. V on Niederhäusern, J. Blanuša, E. Altman, R. Wattenhofer, and K. Atasu. Provably powerful graph neural networks for directed multigraphs. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 11838–11846, 2024
2024
-
[25]
Erlingsson, V
Ú. Erlingsson, V . Feldman, I. Mironov, A. Raghunathan, K. Talwar, and A. Thakurta. Amplifi- cation by shuffling: From local to central differential privacy via anonymity. InProceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 2468–2479. SIAM, 2019
2019
-
[26]
M. Fey, J. E. Lenssen, F. Weichert, and J. Leskovec. Gnnautoscale: Scalable and expressive graph neural networks via historical embeddings. InInternational conference on machine learning, pages 3294–3304. PMLR, 2021
2021
-
[27]
Feyisetan, B
O. Feyisetan, B. Balle, T. Drake, and T. Diethe. Privacy-and utility-preserving textual analysis via calibrated multivariate perturbations. InProceedings of the 13th international conference on web search and data mining, pages 178–186, 2020
2020
-
[28]
H. Gao, J. Li, and H. Huang. On the convergence of local stochastic compositional gradient descent with momentum. InInternational Conference on Machine Learning, pages 7017–7035. PMLR, 2022. 11
2022
-
[29]
Z. Guo, M. Liu, Z. Yuan, L. Shen, W. Liu, and T. Yang. Communication-efficient distributed stochastic auc maximization with deep neural networks. InInternational Conference on Machine Learning, pages 3864–3874. PMLR, 2020
2020
-
[30]
Z. Guo, R. Jin, J. Luo, and T. Yang. Fedxl: provable federated learning for deep x-risk optimization. InInternational Conference on Machine Learning, pages 11934–11966. PMLR, 2023
2023
-
[31]
Haddadpour, M
F. Haddadpour, M. M. Kamani, M. Mahdavi, and V . Cadambe. Local sgd with periodic averaging: Tighter analysis and adaptive synchronization.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[32]
Hamilton, Z
W. Hamilton, Z. Ying, and J. Leskovec. Inductive representation learning on large graphs. Advances in neural information processing systems, 30, 2017
2017
-
[33]
S. Han, S. Park, F. Wu, S. Kim, C. Wu, X. Xie, and M. Cha. Fedx: Unsupervised federated learning with cross knowledge distillation, 2022. URL https://arxiv.org/abs/2207. 09158
2022
- [34]
-
[35]
Hou, W.-T
J. Hou, W.-T. Lin, A. Dharawat, J. Qu, Q. Wang, S. Xiao, X. Zhang, and W. Li. Optimize visual shopping journey with embedding-based retrieval in pinterest closeup. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 4329–4334, 2025
2025
-
[36]
K. Hu, J. Wu, Y . Li, M. Lu, L. Weng, and M. Xia. Fedgcn: Federated learning-based graph convolutional networks for non-euclidean spatial data.Mathematics, 10(6):1000, 2022
2022
- [37]
-
[38]
A. Jain, E. Haghighat, and S. Nelaturi. Latticegraphnet: A two-scale graph neural operator for simulating lattice structures.Engineering with Computers, 41(2):829–844, 2025
2025
-
[39]
G. Jaume, A.-p. Nguyen, M. R. Martínez, J.-P. Thiran, and M. Gabrani. edgnn: a simple and powerful gnn for directed labeled graphs.arXiv preprint arXiv:1904.08745, 2019
-
[40]
Kairouz, H
P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings, et al. Advances and open problems in federated learning. Foundations and Trends® in Machine Learning, 14(1–2):1–210, 2021
2021
-
[41]
H. Kanezashi, T. Suzumura, X. Liu, and T. Hirofuchi. Ethereum fraud detection with heteroge- neous graph neural networks.arXiv preprint arXiv:2203.12363, 2022
-
[42]
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh. Scaffold: Stochastic controlled averaging for federated learning. InInternational Conference on Machine Learning, pages 5132–5143. PMLR, 2020
2020
-
[43]
Khaled, K
A. Khaled, K. Mishchenko, and P. Richtárik. Tighter theory for local sgd on identical and heterogeneous data. InInternational Conference on Artificial Intelligence and Statistics, pages 4519–4529. PMLR, 2020
2020
-
[44]
T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[45]
Federated Optimization: Distributed Machine Learning for On-Device Intelligence
J. Koneˇcn`y, H. B. McMahan, D. Ramage, and P. Richtárik. Federated optimization: Distributed machine learning for on-device intelligence.arXiv preprint arXiv:1610.02527, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [46]
-
[47]
J. Li, J. Pei, and H. Huang. Communication-efficient robust federated learning with noisy labels. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 914–924, 2022
2022
-
[48]
K. Li, G. Luo, Y . Ye, W. Li, S. Ji, and Z. Cai. Adversarial privacy-preserving graph embedding against inference attack.IEEE Internet of Things Journal, 8(8):6904–6915, 2020
2020
-
[49]
J. Lin, X. Guo, Y . Zhu, S. Mitchell, E. Altman, and J. Shun. Fraudgt: a simple, effective, and efficient graph transformer for financial fraud detection. InProceedings of the 5th ACM International Conference on AI in Finance, pages 292–300, 2024
2024
-
[50]
M. Liu, W. Zhang, Y . Mroueh, X. Cui, J. Ross, T. Yang, and P. Das. A decentralized parallel algorithm for training generative adversarial nets.Advances in Neural Information Processing Systems, 33:11056–11070, 2020
2020
-
[51]
W. W. Lo, S. Layeghy, M. Sarhan, M. Gallagher, and M. Portmann. E-graphsage: A graph neural network based intrusion detection system for iot. InNOMS 2022-2022 IEEE/iFIP network operations and management symposium, pages 1–9. IEEE, 2022
2022
-
[52]
McMahan, E
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. PMLR, 2017
2017
-
[53]
H. B. McMahan, D. Ramage, K. Talwar, and L. Zhang. Learning differentially private recurrent language models. InInternational Conference on Learning Representations, 2018
2018
-
[54]
I. Mironov. Rényi differential privacy. In2017 IEEE 30th computer security foundations symposium (CSF), pages 263–275. IEEE, 2017
2017
-
[55]
I. Mironov, K. Talwar, and L. Zhang. R \’enyi differential privacy of the sampled gaussian mechanism.arXiv preprint arXiv:1908.10530, 2019
-
[56]
Namata, B
G. Namata, B. London, L. Getoor, B. Huang, and U. Edu. Query-driven active surveying for collective classification. In10th international workshop on mining and learning with graphs, volume 8, page 1, 2012
2012
-
[57]
Nicholls, A
J. Nicholls, A. Kuppa, and N.-A. Le-Khac. Financial cybercrime: A comprehensive survey of deep learning approaches to tackle the evolving financial crime landscape.Ieee Access, 9: 163965–163986, 2021
2021
-
[58]
H. Peng, Y . Zhang, H. Sun, X. Bai, Y . Li, and S. Wang. Domain-aware federated social bot detection with multi-relational graph neural networks. In2022 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2022
2022
-
[59]
P. Qiu, Z. Luo, J. Liu, and N. Shroff. Swift-fedgnn: Federated graph learning with low communication and sample complexities
-
[60]
Sajadmanesh, A
S. Sajadmanesh, A. S. Shamsabadi, A. Bellet, and D. Gatica-Perez. GAP: Differentially private graph neural networks with aggregation perturbation. In32nd USENIX Security Symposium, 2023
2023
-
[61]
Sanchez-Gonzalez, J
A. Sanchez-Gonzalez, J. Godwin, T. Pfaff, R. Ying, J. Leskovec, and P. Battaglia. Learning to simulate complex physics with graph networks. In H. D. III and A. Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 8459–8468. PMLR, 13–18 Jul 2020. URL https:// proce...
2020
-
[62]
R. Sato, M. Yamada, and H. Kashima. Approximation ratios of graph neural networks for combinatorial problems.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[63]
Scardapane, I
S. Scardapane, I. Spinelli, and P. Di Lorenzo. Distributed training of graph convolutional networks.IEEE Transactions on Signal and Information Processing over Networks, 7:87–100, 2020. 13
2020
-
[64]
P. Sen, G. Namata, M. Bilgic, L. Getoor, B. Galligher, and T. Eliassi-Rad. Collective classifica- tion in network data.AI magazine, 29(3):93–93, 2008
2008
-
[65]
Sharma, R
P. Sharma, R. Panda, G. Joshi, and P. Varshney. Federated minimax optimization: Improved convergence analyses and algorithms. InInternational Conference on Machine Learning, pages 19683–19730. PMLR, 2022
2022
-
[66]
Pitfalls of Graph Neural Network Evaluation
O. Shchur, M. Mumme, A. Bojchevski, and S. Günnemann. Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[67]
K. Shu, S. Wang, and H. Liu. Beyond news contents: The role of social context for fake news detection. InProceedings of the twelfth ACM international conference on web search and data mining, pages 312–320, 2019
2019
-
[68]
S. U. Stich. Local sgd converges fast and communicates little. InInternational Conference on Learning Representations, 2018
2018
-
[69]
D. A. Tarzanagh, M. Li, C. Thrampoulidis, and S. Oymak. FedNest: Federated bilevel, minimax, and compositional optimization. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 21146–21179. PMLR, 17–23 Jul 2022
2022
-
[70]
Truex, L
S. Truex, L. Liu, K.-H. Chow, M. E. Gursoy, and W. Wei. Ldp-fed: Federated learning with local differential privacy. InProceedings of the third ACM international workshop on edge systems, analytics and networking, pages 61–66, 2020
2020
-
[71]
van Erven and P
T. van Erven and P. Harremos. Rényi divergence and kullback-leibler divergence.IEEE Transactions on Information Theory, 60(7):3797–3820, 2014
2014
-
[72]
Wang and M
X. Wang and M. Zhang. How powerful are spectral graph neural networks. InInternational conference on machine learning, pages 23341–23362. PMLR, 2022
2022
-
[73]
Scalable Graph Learning for Anti-Money Laundering: A First Look
M. Weber, J. Chen, T. Suzumura, A. Pareja, T. Ma, H. Kanezashi, T. Kaler, C. E. Leiserson, and T. B. Schardl. Scalable graph learning for anti-money laundering: A first look.arXiv preprint arXiv:1812.00076, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [74]
-
[75]
K. Wei, J. Li, M. Ding, C. Ma, H. H. Yang, F. Farokhi, S. Jin, T. Q. Quek, and H. V . Poor. Federated learning with differential privacy: Algorithms and performance analysis.IEEE transactions on information forensics and security, 15:3454–3469, 2020
2020
-
[76]
Woodworth, K
B. Woodworth, K. K. Patel, S. Stich, Z. Dai, B. Bullins, B. Mcmahan, O. Shamir, and N. Srebro. Is local sgd better than minibatch sgd? InInternational Conference on Machine Learning, pages 10334–10343. PMLR, 2020
2020
-
[77]
B. E. Woodworth, K. K. Patel, and N. Srebro. Minibatch vs local sgd for heterogeneous distributed learning.Advances in Neural Information Processing Systems, 33:6281–6292, 2020
2020
- [78]
-
[79]
C. Wu, F. Wu, L. Lyu, T. Qi, Y . Huang, and X. Xie. A federated graph neural network framework for privacy-preserving personalization.Nature Communications, 13(1):3091, 2022
2022
-
[80]
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and P. S. Yu. A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.