Separate Aggregation of Split Network for Personalized Federated Learning
Pith reviewed 2026-06-29 18:54 UTC · model grok-4.3
The pith
PGFedSplit uses a split network with adaptive aggregation and synthetic representations to improve both personalization and global generalization in federated learning under severe client data heterogeneity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
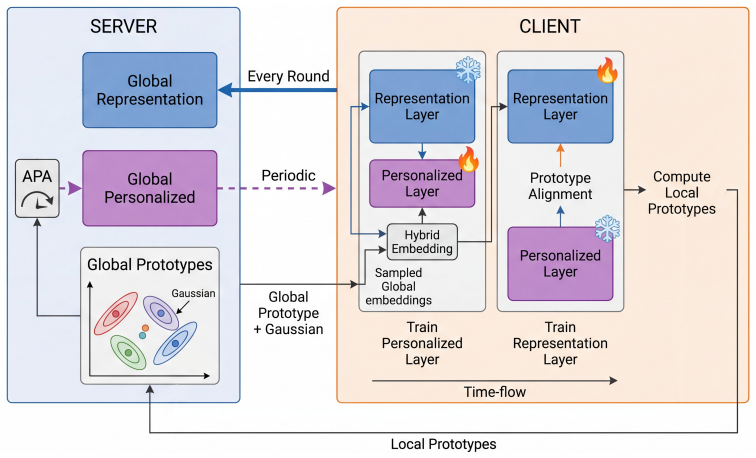
PGFedSplit adopts a split architecture and performs adaptive aggregation scheduling tailored to the roles of different model components, enabling stable knowledge sharing while maintaining client specific adaptation. Each client further leverages a mixture of locally extracted representations and synthetic representations generated from server side Gaussian statistics, improving robustness under label imbalance and missing class conditions.
What carries the argument
Split architecture with adaptive aggregation scheduling for model components plus mixture of locally extracted representations and synthetic representations from server-side Gaussian statistics.
If this is right
- The method simultaneously raises client-specific accuracy and global model quality without forcing a tradeoff between them.
- Separate scheduling for different model parts allows stable sharing of early layers while preserving adaptation in later layers.
- Mixing local and server-generated synthetic representations reduces sensitivity to missing classes and label skew at each client.
- The approach yields consistent gains on Fashion-MNIST, CIFAR-10, CIFAR-100 and Tiny-ImageNet under controlled heterogeneity.
Where Pith is reading between the lines
- The same split-and-schedule pattern could be applied to other distributed training tasks where different layers have different privacy or stability requirements.
- Generating synthetic features from summary statistics at the server may reduce communication cost compared with sharing raw data or full models.
- If the Gaussian assumption holds only for image data, the technique might need different summary statistics when applied to text or tabular client data.
Load-bearing premise
Server-side Gaussian statistics can generate synthetic representations that reliably improve robustness under label imbalance and missing-class conditions without introducing new biases or harming convergence.
What would settle it
Remove the synthetic-representation step and rerun the experiments on the same highly imbalanced datasets; if the reported gains in personalization and robustness disappear or reverse, the central mechanism does not hold.
Figures

read the original abstract
Federated learning enables collaborative model training without sharing raw data, but its performance can degrade substantially under heterogeneous client data distributions. A single global model often cannot satisfy diverse client requirements, so personalized federated learning has therefore been explored to improve client specific performance while preserving global generalization. Existing PFL methods often face a fundamental tradeoff in which stronger global sharing can undermine local specialization, whereas stronger local adaptation can lead to overfitting under limited data, label imbalance, and missing class scenarios. In this work, we propose PGFedSplit, a personalized federated learning framework that improves both personalization and global generalization under severe client heterogeneity. PGFedSplit adopts a split architecture and performs adaptive aggregation scheduling tailored to the roles of different model components, enabling stable knowledge sharing while maintaining client specific adaptation. Each client further leverages a mixture of locally extracted representations and synthetic representations generated from server side Gaussian statistics, improving robustness under label imbalance and missing class conditions. Extensive experiments on Fashion MNIST, CIFAR 10, CIFAR 100, and Tiny ImageNet demonstrate consistent improvements over state of the art PFL methods, with stable convergence and superior personalization in highly heterogeneous settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PGFedSplit, a personalized federated learning framework using a split network architecture with adaptive aggregation scheduling tailored to model component roles, combined with a mixture of locally extracted representations and synthetic representations generated from server-side Gaussian statistics, to improve both personalization and global generalization under severe client heterogeneity including label imbalance and missing classes. It claims consistent improvements and stable convergence over state-of-the-art PFL methods on Fashion MNIST, CIFAR-10, CIFAR-100, and Tiny ImageNet.
Significance. If the empirical claims hold with proper validation, the split-architecture approach with role-specific aggregation and Gaussian synthetic augmentation could offer a useful mechanism for mitigating the personalization-globalization tradeoff in non-IID federated settings, particularly where clients have incomplete class sets.
major comments (2)
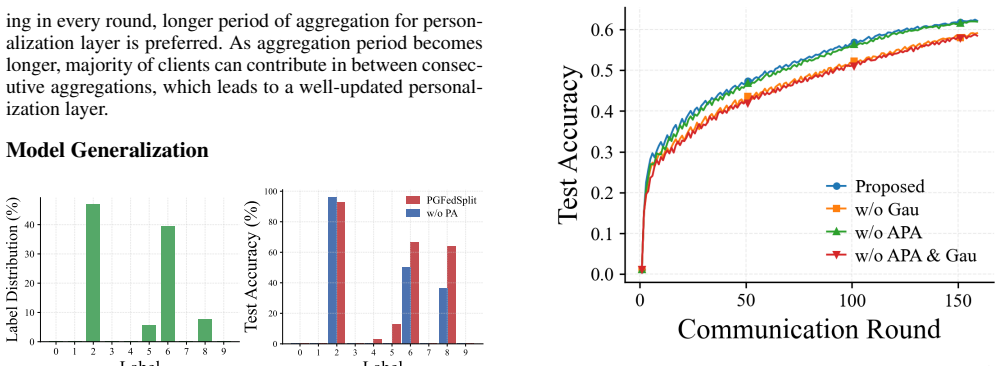
- [Abstract, §3] Abstract and method description (§3 implied): The central claim that mixing local representations with synthetic ones drawn from server-side Gaussian statistics reliably improves robustness under missing-class conditions is load-bearing, yet no ablation, statistical test of Gaussianity, or isolation of the synthetic component's effect is provided; this leaves the weakest assumption unexamined.
- [Abstract] Abstract: The assertions of 'consistent improvements' and 'stable convergence' are presented without any quantitative results, tables, figures, error bars, or statistical tests, so the empirical support for the central claim cannot be evaluated from the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and method description (§3 implied): The central claim that mixing local representations with synthetic ones drawn from server-side Gaussian statistics reliably improves robustness under missing-class conditions is load-bearing, yet no ablation, statistical test of Gaussianity, or isolation of the synthetic component's effect is provided; this leaves the weakest assumption unexamined.
Authors: We acknowledge that the current manuscript lacks an explicit ablation isolating the synthetic representation component and does not include a statistical assessment of the Gaussianity assumption. In the revised version we will add an ablation study that compares the full mixture against a local-only baseline under controlled missing-class settings on at least two datasets. We will also insert a short justification for the Gaussian model (based on the central-limit behavior of aggregated client statistics) together with a brief empirical check of feature-distribution normality on the server-side aggregates. These additions directly address the concern that the assumption remains unexamined. revision: yes
-
Referee: [Abstract] Abstract: The assertions of 'consistent improvements' and 'stable convergence' are presented without any quantitative results, tables, figures, error bars, or statistical tests, so the empirical support for the central claim cannot be evaluated from the manuscript.
Authors: Abstracts are deliberately concise and conventionally omit numerical tables or figures. The full manuscript already contains the supporting evidence: Section 4 reports accuracy tables with standard deviations across multiple random seeds, convergence plots, and comparative results against state-of-the-art PFL baselines on all four datasets. To improve clarity we will append a single sentence to the abstract that explicitly directs readers to Section 4 for the quantitative evaluation, without altering the abstract's length constraints. revision: partial
Circularity Check
No circularity detected; framework is a self-contained empirical proposal
full rationale
The paper introduces PGFedSplit as a split-network PFL method with adaptive aggregation and Gaussian synthetic representations, supported by experiments on Fashion-MNIST, CIFAR-10/100 and Tiny-ImageNet. No equations, derivations, or predictions are shown that reduce by construction to fitted inputs, self-citations, or renamed known results. The central claims rest on the described architecture and empirical results rather than any load-bearing self-referential step, satisfying the criteria for a non-circular derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InInternational Conference on Computer Vision, 345–354
Network Dissection: Quantifying Interpretability of Deep Visual Representations. InInternational Conference on Computer Vision, 345–354. IEEE. Bengio, Y .; Courville, A.; and Vincent, P. 2013. Represen- tation learning: A review and new perspectives.IEEE trans- actions on pattern analysis and machine intelligence, 35(8): 1798–1828. Collins, L.; Hassani, H...
2013
-
[2]
InInternational conference on machine learning, 2089–2099
Exploiting shared representations for personalized federated learning. InInternational conference on machine learning, 2089–2099. PMLR. Dai, Y .; Chen, Z.; Li, J.; Heinecke, S.; Sun, L.; and Xu, R
2089
-
[3]
arXiv preprint arXiv:2003.13461 , year=
Tackling Data Heterogeneity in Federated Learning with Class Prototypes. InProceedings of the AAAI Confer- ence on Artificial Intelligence, volume 37, 7314–7322. Deng, Y .; Kamani, M.; and Mahdavi, M. 2020. Adap- tive Personalized Federated Learning.arXiv preprint arXiv:2003.13461. Dorszewski, T.; Tˇetkov´a, L.; Jenssen, R.; Hansen, L. K.; and Wickstrøm, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.