Localizing Memorized Regions in Diffusion Models via Coordinate-Wise Curvature Differences
Pith reviewed 2026-06-29 19:54 UTC · model grok-4.3
The pith
Curvature differences with an underfitted baseline localize memorized regions in diffusion model generations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
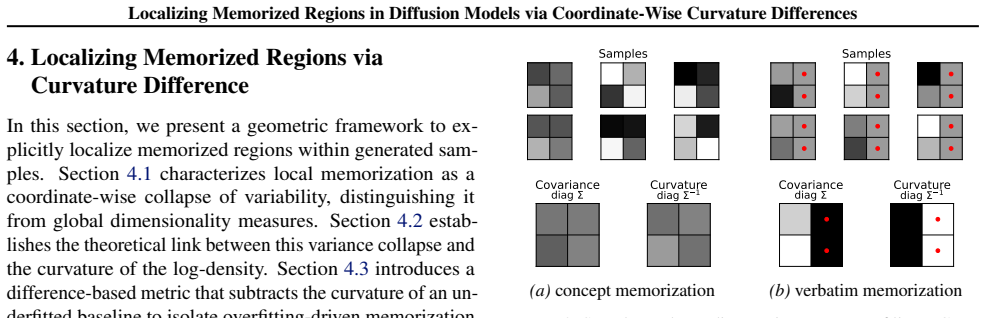
Local memorization in diffusion models manifests as coordinate-wise variance collapse that can be isolated from data-intrinsic effects by computing curvature differences relative to an underfitted baseline, either the unconditional model or a less-trained checkpoint.
What carries the argument
Coordinate-wise curvature differences, obtained by subtracting the curvature computed on an underfitted baseline from that of the trained model, to highlight overfitting-induced memorization.
If this is right
- The method supplies a per-coordinate map of memorized content within an image.
- It offers a geometric rationale for the effectiveness of score-difference detection.
- Localization performance exceeds that of attention-map methods on Stable Diffusion.
- Applicable to privacy audits by revealing which parts of outputs are memorized.
Where Pith is reading between the lines
- If the baseline truly underfits, the method could generalize to detect memorization in other generative architectures.
- Choosing different baselines might change which regions are flagged as memorized versus data-constrained.
- Curvature-based signals could be combined with other geometric measures for more robust detection.
Load-bearing premise
Subtracting curvature from an underfitted baseline isolates overfitting-driven memorization rather than intrinsic data constraints.
What would settle it
If curvature-difference maps fail to align with ground-truth memorization masks on Stable Diffusion more closely than the attention baseline, the localization advantage would not hold.
Figures




read the original abstract
Diffusion models can unintentionally memorize training samples, raising concerns about privacy and copyright. While recent methods can detect memorization, they often rely on global or model-specific signals and provide limited insight into where memorization appears within a generated image. We provide a geometric characterization of local memorization as a coordinate-wise variance collapse. However, such collapse can also arise from intrinsic data constraints rather than overfitting. To isolate overfitting-driven memorization, we propose curvature-difference methods that subtract the curvature of an underfitted baseline, either the unconditional model or a less-trained version of itself. We further derive a score-difference proxy that provides a geometric explanation for the widely used score-difference-based detection metric. Experiments on Stable Diffusion, evaluated against ground-truth memorization masks, show that our method outperforms the prior attention-based localization method. Code is available at https://github.com/Gwangho99/mem-curv-diff.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that local memorization in diffusion models can be characterized geometrically as coordinate-wise variance collapse. To isolate overfitting-driven memorization from intrinsic data constraints, it proposes curvature-difference methods that subtract curvature computed on an underfitted baseline (unconditional model or less-trained checkpoint). It further derives a score-difference proxy that geometrically explains an existing detection metric. Experiments on Stable Diffusion, evaluated against ground-truth memorization masks, are reported to show outperformance over a prior attention-based localization method. Code is released.
Significance. If the experimental results hold and the baseline-subtraction premise is independently validated, the work supplies a geometric account of memorization localization together with a practical improvement over attention baselines. Reproducibility is aided by the public code release. The contribution would be relevant to privacy and copyright concerns in generative modeling.
major comments (2)
- [Abstract] Abstract: the claim that curvature subtraction from an underfitted baseline isolates overfitting-driven memorization (rather than intrinsic data-driven collapse) is load-bearing for the reported outperformance against attention baselines, yet the manuscript provides no verification that the chosen baselines lack comparable coordinate-wise variance reduction on the same coordinates.
- [Abstract] Abstract: the derived score-difference proxy is asserted to furnish a geometric explanation of the widely used score-difference metric, but the text does not clarify whether the proxy is independent or reduces to the original metric by construction; this circularity risk directly affects the claimed explanatory value.
minor comments (1)
- [Abstract] Abstract: quantitative results, error bars, baseline implementation details, and ground-truth mask construction procedure are absent, preventing assessment of effect sizes and experimental robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below, agreeing where clarification or additional evidence is needed and outlining the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that curvature subtraction from an underfitted baseline isolates overfitting-driven memorization (rather than intrinsic data-driven collapse) is load-bearing for the reported outperformance against attention baselines, yet the manuscript provides no verification that the chosen baselines lack comparable coordinate-wise variance reduction on the same coordinates.
Authors: We agree this verification is important for the isolation claim. The manuscript currently relies on the underfitting design of the baselines (unconditional model or earlier checkpoints) without direct empirical checks on the memorized coordinates. In the revision we will add quantitative comparisons of coordinate-wise curvature and variance collapse between the trained model and both baselines on the ground-truth memorization masks, confirming that the baselines do not exhibit comparable reduction. revision: yes
-
Referee: [Abstract] Abstract: the derived score-difference proxy is asserted to furnish a geometric explanation of the widely used score-difference metric, but the text does not clarify whether the proxy is independent or reduces to the original metric by construction; this circularity risk directly affects the claimed explanatory value.
Authors: The proxy is obtained by algebraic rearrangement of the curvature-difference expression and is shown to approximate the score-difference metric; the derivation is independent and supplies the geometric reason the metric succeeds. It is not identical by construction. We will revise the relevant section to present the full derivation steps explicitly and state the independence of the proxy from the original metric. revision: yes
Circularity Check
No significant circularity; derivation and proxy remain independent of inputs
full rationale
The abstract presents a geometric characterization of memorization as coordinate-wise variance collapse, proposes curvature subtraction from underfitted baselines, and derives a score-difference proxy as an explanation for an existing detection metric. No equations, self-citations, or definitions are supplied that reduce the proxy or difference map to the input metric by construction. The experimental comparison against ground-truth memorization masks supplies independent falsifiable grounding outside any fitted parameters or prior author results, keeping the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Curvature can be meaningfully computed coordinate-wise on diffusion model outputs and baselines.
Reference graph
Works this paper leans on
-
[1]
Karras, T., Aittala, M., Kynk ¨a¨anniemi, T., Lehtinen, J., Aila, T., and Laine, S
URL https://openreview.net/forum? id=ANvmVS2Yr0. Karras, T., Aittala, M., Kynk ¨a¨anniemi, T., Lehtinen, J., Aila, T., and Laine, S. Guiding a diffusion model with a bad version of itself.Advances in Neural Information Processing Systems, 37:52996–53021, 2024. Kong, X., Liu, O., Li, H., Yogatama, D., and Steeg, G. V . Interpretable diffusion via informati...
-
[2]
URL https://openreview.net/forum? id=fV0t65OBUu. Pizzi, E., Roy, S. D., Ravindra, S. N., Goyal, P., and Douze, M. A self-supervised descriptor for image copy detection. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pp. 14532–14542, 2022. Ren, J., Li, Y ., Zeng, S., Xu, H., Lyu, L., Xing, Y ., and Tang, J. Unveiling...
-
[3]
Along the manifold direction, the marginal distribution pt(x) approximates a convolution of the data distributionN(0, σ 2 data) and the diffusion noise kernel N(0, σ 2 t )
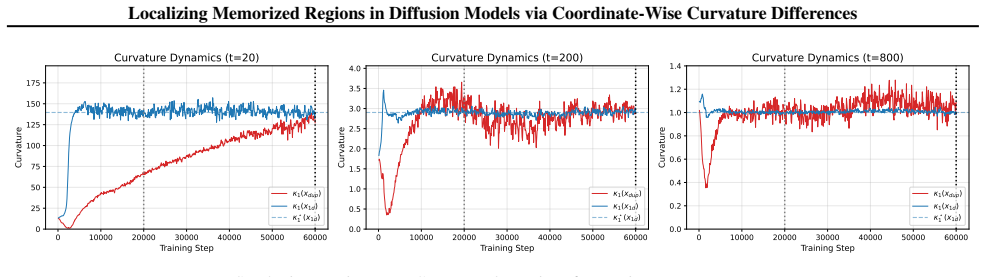
DD-Mem saturates early:General data manifolds typically possess intrinsic noise ( σdata >0 ) even if the data lies on a low-dimensional manifold (Fefferman et al., 2016). Along the manifold direction, the marginal distribution pt(x) approximates a convolution of the data distributionN(0, σ 2 data) and the diffusion noise kernel N(0, σ 2 t ). Consequently,...
2016
-
[4]
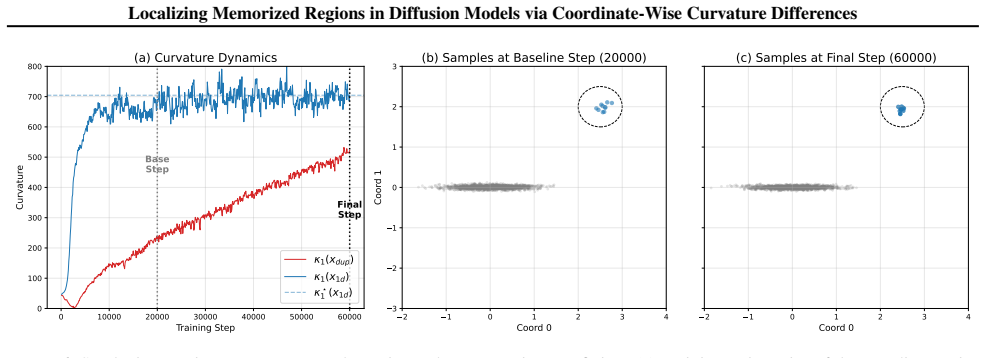
OD-Mem continues to sharpen:As shown in Figure 6, the model successfully generates samples from the outlier mode as early as the baseline checkpoint (20,000 steps). However, crucially, the curvatureκ1 at this mode does not stop increasing; it continues to rise significantly as training proceeds to the final step (60,000 steps). This indicates that memoriz...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.