Pretrained Approximators for Low-Thrust Trajectory Cost and Reachability
Pith reviewed 2026-06-29 19:36 UTC · model grok-4.3
The pith
Neural networks accurately approximate low-thrust trajectory fuel costs and transfer times while generalizing across orbits via self-similar transforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
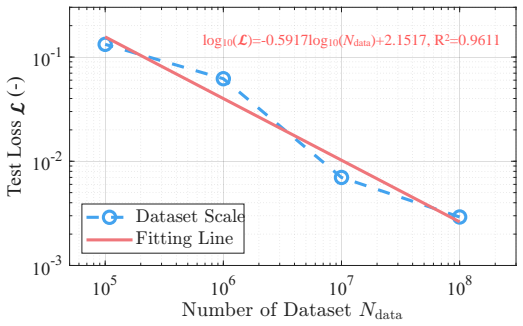
Low-thrust trajectory optimization follows a scaling law in which approximation accuracy for optimal fuel consumption and minimum transfer time rises linearly with the log of dataset size and model capacity; a self-similar transformation applied to homotopy-ray data enables the identical neural model to generalize to new semi-major axes, inclinations, and central bodies without retraining.
What carries the argument
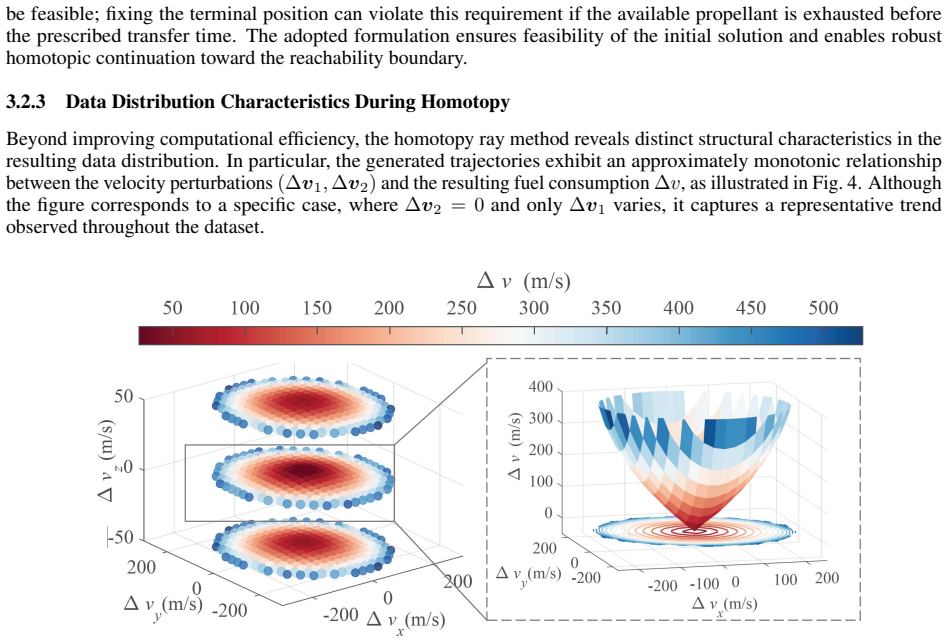
The self-similar transformation that normalizes the homotopy-ray dataset so a single network can generalize across varying semi-major axes, inclinations, and central bodies.
If this is right
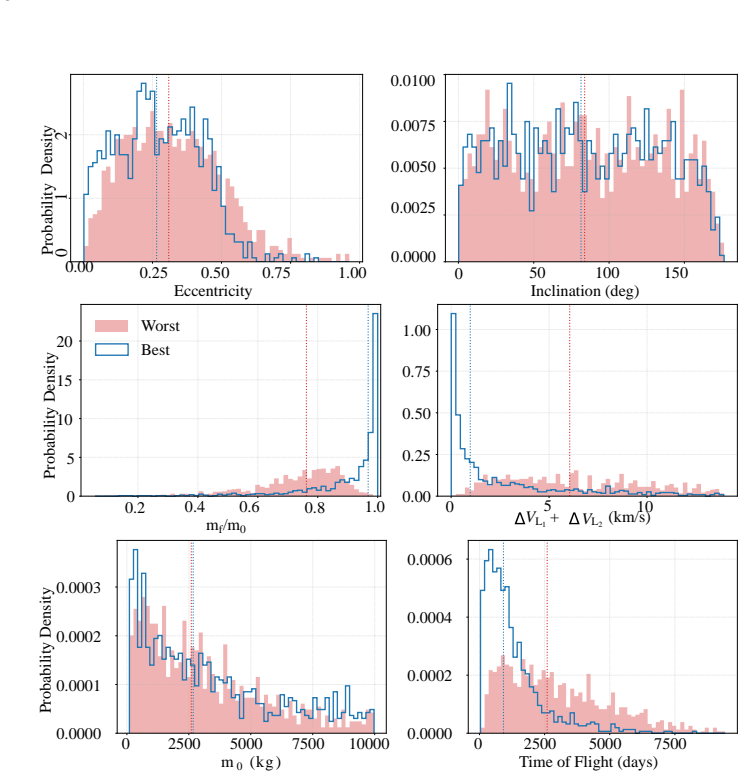
- The same pretrained model predicts costs for both single- and multi-revolution transfers in asteroid flyby and rendezvous missions.
- Accuracy continues to rise with additional data and larger networks inside the explored regime.
- One model serves multiple mission classes and central bodies without retraining.
- Open release of models and datasets enables direct use in existing trajectory design pipelines.
Where Pith is reading between the lines
- Embedding these surrogates inside iterative optimizers would cut the cost of repeated trajectory evaluations by orders of magnitude.
- The scaling behavior suggests that further gains remain available simply by increasing compute rather than redesigning the architecture.
- Analogous surrogate-plus-scaling approaches could be tested on other optimal-control problems that currently rely on repeated expensive solves.
Load-bearing premise
The homotopy-ray strategy produces training examples whose coverage is broad enough for the observed scaling law to continue and for generalization to hold on unseen orbital parameters and central bodies.
What would settle it
Measuring whether approximation error stops decreasing or begins to rise when the training set is enlarged by another factor of ten or when the model is tested on transfers around a central body absent from the training distribution.
Figures










read the original abstract
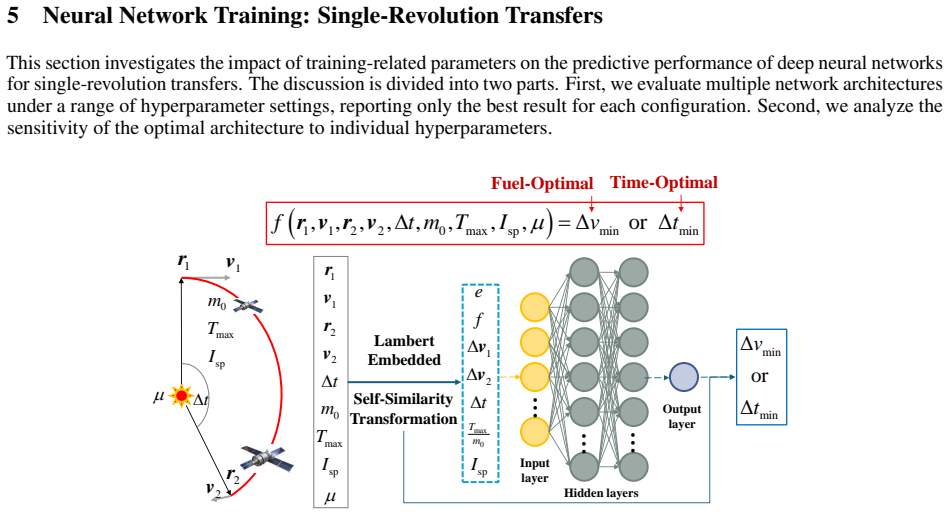
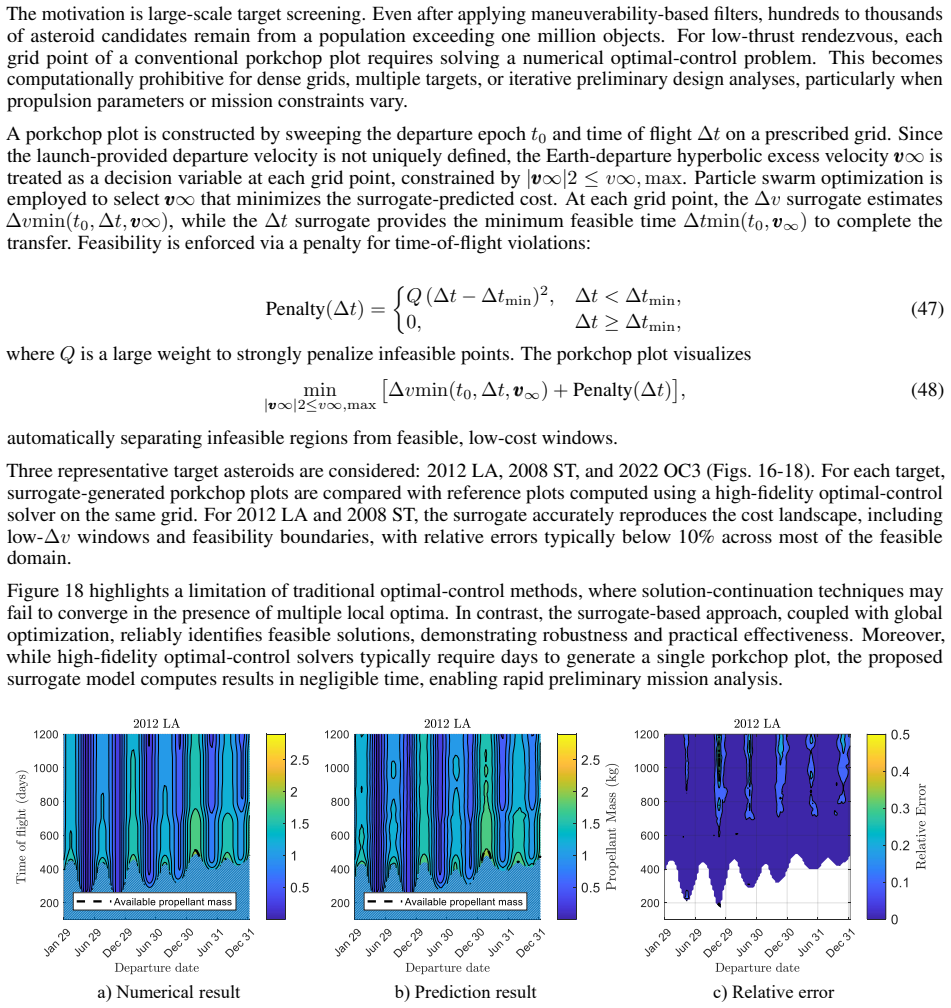
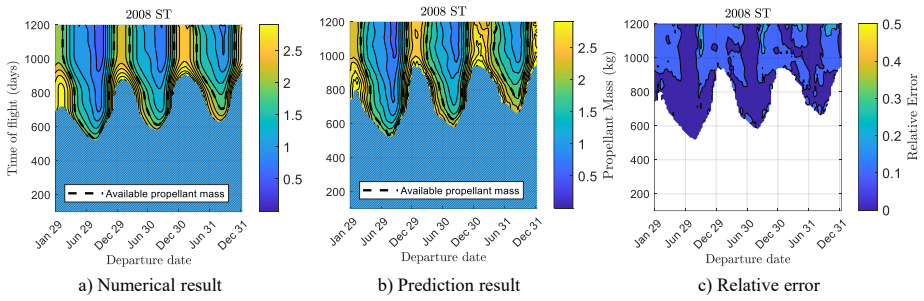
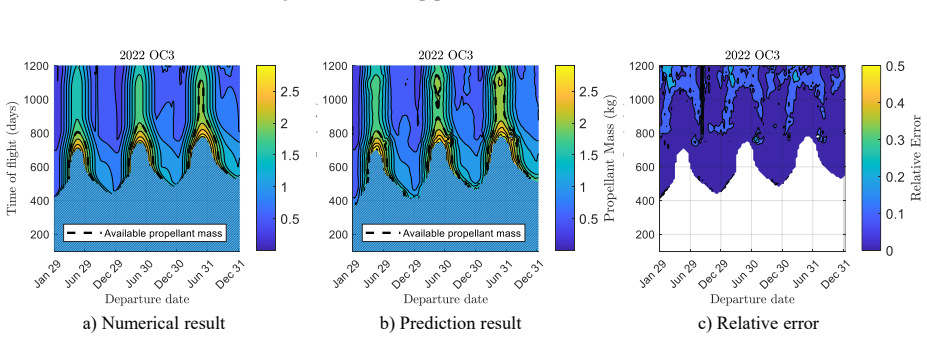
Low-thrust trajectory design relies heavily on repeated evaluations of fuel consumption and transfer feasibility, which require expensive optimal control solutions. In this work, we show these quantities can be accurately approximated by machine learning surrogates, enabling fast and scalable evaluation across a wide range of scenarios. By increasing both dataset size and model capacity, we observe that low-thrust trajectory optimization follows a scaling law, with performance improving linearly with the logarithm of training data and network parameters, and no evidence of saturation within the explored regime. Guided by this observation, we construct a large-scale dataset using the proposed homotopy-ray strategy tailored to mission design requirements. A key is the introduction of a self-similar transformation, which allows generalization across semi-major axes, inclinations, and central bodies avoiding retraining. As a result, the same neural approximator can be applied to diverse orbital environments and mission classes. The proposed models accurately predict optimal fuel consumption and minimum transfer time for single- and multi-revolution transfers. Their performance and generalization are demonstrated on a public dataset, a multi-asteroid flyby problem from the Global Trajectory Optimization Competition, and an asteroid rendezvous mission design. The models and datasets are released as open-source to support the space community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that neural network surrogates can accurately approximate optimal fuel consumption and minimum transfer time for low-thrust single- and multi-revolution trajectories. A homotopy-ray dataset generation strategy combined with a self-similar transformation is introduced to enable generalization across semi-major axes, inclinations, and central bodies without retraining. The authors report an empirical scaling law in which approximation performance improves linearly with the logarithm of training set size and network parameters, with no saturation observed in the explored regime. Results are demonstrated on a public dataset, a GTOC multi-asteroid flyby problem, and an asteroid rendezvous mission, with models and datasets released as open source.
Significance. If the reported accuracy and scaling behavior prove robust, the work could enable substantially faster evaluation of low-thrust costs and reachability in mission design loops. The open-source release of models and datasets is a concrete strength that supports reproducibility and community follow-on work.
major comments (2)
- [Abstract] Abstract: the headline claim of linear scaling with log(training data) and log(network parameters) and the generalization claim both rest on the assumption that the homotopy-ray dataset plus self-similar mapping provides sufficient coverage; the abstract supplies no quantitative error distributions, validation splits, ablation on the sampling strategy, or coverage metrics (e.g., convex-hull volume or KS distances to test distributions) to substantiate this.
- [Results] The central empirical results are fits to a generated dataset; without reported validation splits or ablation studies on the homotopy-ray procedure, it is not possible to determine whether the observed scaling and zero-shot generalization to arbitrary inclinations and revolutions are load-bearing or artifacts of interpolation within the training distribution.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback on the abstract and empirical validation. We agree that additional quantitative details on validation, coverage, and ablations would strengthen the presentation of the scaling law and generalization claims. We will revise the manuscript accordingly while maintaining that the self-similar transformation and out-of-distribution tests on GTOC and rendezvous missions provide substantive support beyond pure interpolation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of linear scaling with log(training data) and log(network parameters) and the generalization claim both rest on the assumption that the homotopy-ray dataset plus self-similar mapping provides sufficient coverage; the abstract supplies no quantitative error distributions, validation splits, ablation on the sampling strategy, or coverage metrics (e.g., convex-hull volume or KS distances to test distributions) to substantiate this.
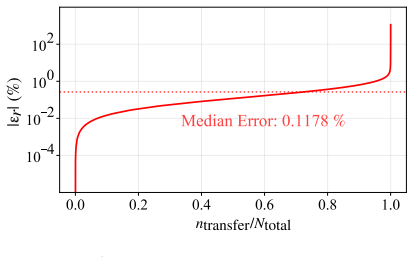
Authors: We acknowledge the abstract is concise and omits these specifics. The full paper reports mean relative errors below 1% on held-out test points from the public dataset, plus successful zero-shot application to GTOC multi-asteroid and rendezvous cases with different inclinations and revolution counts. We will revise the abstract to include key quantitative error statistics, mention the train/test split used for scaling experiments, and note that coverage is ensured by the homotopy-ray sampling density and self-similar normalization. Revision will be made. revision: yes
-
Referee: [Results] The central empirical results are fits to a generated dataset; without reported validation splits or ablation studies on the homotopy-ray procedure, it is not possible to determine whether the observed scaling and zero-shot generalization to arbitrary inclinations and revolutions are load-bearing or artifacts of interpolation within the training distribution.
Authors: The results are generated via the homotopy-ray procedure, but the paper already demonstrates generalization on two external mission scenarios (GTOC flyby and asteroid rendezvous) whose inclination and revolution distributions differ from the training set. The self-similar transformation is derived from orbital mechanics and enables the observed zero-shot behavior. We agree that explicit validation splits (e.g., 80/20) and ablations on ray density and homotopy parameters were not reported and will add them in revision. We maintain the scaling law and generalization are not artifacts, as performance continues to improve with scale and transfers to dissimilar problems succeed. revision: partial
Circularity Check
No circularity: empirical ML fits on generated data with independent test evaluation
full rationale
The paper generates a dataset via homotopy-ray sampling plus self-similar transform, trains neural approximators, and reports empirical accuracy plus log-linear scaling on held-out public datasets, GTOC instances, and asteroid rendezvous cases. No equation, prediction, or central claim reduces to a fitted parameter or self-citation by construction; the reported performance is measured against external benchmarks rather than being forced by the training procedure itself. Self-citation, if present, is not load-bearing for the scaling or generalization results.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights and biases
axioms (1)
- domain assumption The self-similar transformation maps the optimal-control problem identically across different semi-major axes, inclinations, and central bodies.
Forward citations
Cited by 1 Pith paper
-
The Maximum Initial Mass
Introduces maximum-initial-mass optimal control problem for low-thrust transfers, establishes correspondence to minimum-time extremals, and applies it to recover global solutions for a GTO-to-GEO benchmark.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.